
深入讲解java多线程与高并发:线程池ThreadPool
前言
今天这节课呢,我们通过一道面试把前面讲的哪些基础复习一下,然后再开始线程池这部分的内容,我们一点一点来看。
这道面试题呢实际上是华为的一道面试题,其实它里面是一道填空题,后来就很多的开始考这道题,这个面试题是两个线程,第一个线程是从1到26,第二个线程是从A到一直到Z,然后要让这两个线程做到同时运行,交替输出,顺序打印。那么这道题目的解法有非常多。
用LockSupport其实是最简单的。你让一个线程输出完了之后停止,然后让另外一个线程继续运行就完了。我们定义了两个数组,两个线程,第一个线程拿出数组里面的每一个数字来,然后打印,打印完叫醒t2,然后让自己阻塞。另外一个线程上来之后自己先park,打印完叫醒线程t1。两个线程就这么交替来交替去,就搞定了。
package com.mashibing.juc.c_026_00_interview.A1B2C3;public class T01_00_Question {public static void main(String[] args) {//要求用线程顺序打印A1B2C3....Z26}
}package com.mashibing.juc.c_026_00_interview.A1B2C3;import java.util.concurrent.locks.LockSupport;//Locksupport park 当前线程阻塞(停止)//unpark(Thread t)public class T02_00_LockSupport {static Thread t1 = null, t2 = null;public static void main(String[] args) throws Exception {char[] aI = "1234567".toCharArray();char[] aC = "ABCDEFG".toCharArray();
t1 = new Thread(() -> {for(char c : aI) {
System.out.print(c);
LockSupport.unpark(t2); //叫醒T2LockSupport.park(); //T1阻塞}
}, "t1");
t2 = new Thread(() -> {for(char c : aC) {
LockSupport.park(); //t2阻塞System.out.print(c);
LockSupport.unpark(t1); //叫醒t1}
}, "t2");
t1.start();
t2.start();}
}当时出这道题的时候是想考察wait、notify和notifyAll,主要是synchronized、wait、notify。
来解释一下,首先第一个我先调用wait、notify的时候,wait线程阻塞,notify叫醒其他线程,调用这个两个方法的时候必须要进行synchronized锁定的,如果没有synchronized这个线程你是锁定不了的,他是离开不锁的,因此我们定义一个锁的对象new Object(),两个数组,第一线程上来先锁定Object对象 o,锁定完对象之后,我们开始输出,输出第一个数字,输出完之后叫醒第二个,然后自己wait。还是这个思路,其实这个就和LookSupport的park、unpark是非常类似的,这里面最容易出错的一个地方就是把整个数组都打印完了要记得notify,为什么要notify啊,因为这两个线程里面终归有一个线程wait的,是阻塞在这停止不动的。
package com.mashibing.juc.c_026_00_interview.A1B2C3;public class T06_00_sync_wait_notify {public static void main(String[] args) {final Object o = new Object();char[] aI = "1234567".toCharArray();char[] aC = "ABCDEFG".toCharArray();new Thread(()->{synchronized (o) {for(char c : aI) {
System.out.print(c);try {
o.notify();
o.wait(); //让出锁} catch (InterruptedException e) {
e.printStackTrace();
}
}
o.notify(); //必须,否则无法停止程序}
}, "t1").start();new Thread(()->{synchronized (o) {for(char c : aC) {
System.out.print(c);try {
o.notify();
o.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
o.notify();
}
}, "t2").start();
}
}//如果我想保证t2在t1之前打印,也就是说保证首先输出的是A而不是1,这个时候该如何做?
保证第一个线程先运行,办法也是非常的多的,看下面,使用自旋的方式,设置一个boolean类型的变量,t2刚开始不是static。如果说t2没有static的话,我这个t1线程就wait,要求t2必须先static才能执行我的业务逻辑。还有一种写法就是t2上来二话不说先wait,然后t1呢上来二话不说先输出,输出完了之后notify;还有一种写法用CountDownLatch也可以;
package com.mashibing.juc.c_026_00_interview.A1B2C3;public class T07_00_sync_wait_notify {private static volatile boolean t2Started = false;//private static CountDownLatch latch = new C(1);public static void main(String[] args) {final Object o = new Object();char[] aI = "1234567".toCharArray();char[] aC = "ABCDEFG".toCharArray();new Thread(()->{//latch.await();synchronized (o) {while(!t2Started) {try {
o.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}//for(char c : aI) {
System.out.print(c);try {
o.notify();
o.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
o.notify();
}
}, "t1").start();new Thread(()->{synchronized (o) {for(char c : aC) {
System.out.print(c);//latch.countDown()t2Started = true;try {
o.notify();
o.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}o.notify();
}
}, "t2").start();
}
}这两种最重要的方法,一个是LockSupport,一个是synchronized、wait、notify。这两种面试的时候你要是能写出来问题就不大,但是,你如果能用新的lock的接口,就不再用synchronized,用这种自旋的,也可以。严格来讲这个lock和synchronized本质是一样的。不过他也有好用的地方,下面我们来看看写法。
严格来讲这个lock和synchronized本质是一样的,不过还是有它好用的地方,我们来看看它的第一种写法我用一个ReentrantLock,然后调用newCondition,上来之后先lock相当于synchronized了,打印,打印完之后signal叫醒另一个当前的等待,最后condition.signal()相当于notify(),然后之后另外一个也类似就完了,这种写法相当于synchronized的一个变种。
package com.mashibing.juc.c_026_00_interview.A1B2C3;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;public class T08_00_lock_condition {public static void main(String[] args) {char[] aI = "1234567".toCharArray();char[] aC = "ABCDEFG".toCharArray();
Lock lock = new ReentrantLock();
Condition condition = lock.newCondition();new Thread(()->{try {lock.lock();for(char c : aI) {
System.out.print(c);
condition.signal();
condition.await();
}
condition.signal();
} catch (Exception e) {
e.printStackTrace();
} finally {lock.unlock();
}
}, "t1").start();new Thread(()->{try {lock.lock();for(char c : aC) {
System.out.print(c);
condition.signal();
condition.await();
}condition.signal();
} catch (Exception e) {
e.printStackTrace();
} finally {lock.unlock();
}
}, "t2").start();
}
}但是如果你能写出两个Condition的情况就会好很多。大家知道,在一个一把锁,这个锁的等待队列里有好多线程,假如我要notify的话他实际上要找出一个让它运行,如果说我要调用的是一个notifyAll的话,是让所有线程都醒过来去争用这把锁看谁能抢的到,谁抢到了就让这个线程运行。那好,在这里面呢,我不能去要求那一类或者那一个线程去醒过来,这个回想原来讲过的生产者消费者的问题,既然我们有两个线程,那完全可以模仿生产者和消费者我干脆来两种的Condition,同学们也回顾一下,给大家讲Condition的时候说过这个问题,Condition它本质上是一个等待队列 ,就是两个等待队列,其中一个线程在这个等待队列上,另一个线程在另外一个等待队列上。
所以呢,如果说我用两个Condition的话就可以精确的指定那个等待队列里的线程醒过来去执行任务。
所以这个写法就是这样来写的,第一线程呢conditionT2.signal(),叫醒第二个那个里面的线程,然后我第一个线程让它等待,第二个就是我叫醒第一个线程,第二个让它等待放到这个等待队列里,相当于我放了两个等待队列,t1在这个等待队列里,t2在另一个等待队列里,在t1完成了之后呢叫醒t2是指定你这个队列的线程醒过来,所以永远都是t2。其实对于两个线程来讲区别不大,因为你叫醒的时候当前线程肯定是醒着的,叫醒的也就只有是你这个线程 ,不过对于写代码来说,写到这个样子面试官肯定是会高看你一眼。
/*
Condition本质是锁资源上不同的等待队列
*/package com.mashibing.juc.c_026_00_interview.A1B2C3;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;public class T09_00_lock_condition {public static void main(String[] args) {char[] aI = "1234567".toCharArray();char[] aC = "ABCDEFG".toCharArray();
Lock lock = new ReentrantLock();
Condition conditionT1 = lock.newCondition();
Condition conditionT2 = lock.newCondition();new Thread(()->{try {lock.lock();for(char c : aI) {
System.out.print(c);
conditionT2.signal();
conditionT1.await();
}conditionT2.signal();
} catch (Exception e) {
e.printStackTrace();
} finally {lock.unlock();
}
}, "t1").start();new Thread(()->{try {lock.lock();for(char c : aC) {
System.out.print(c);
conditionT1.signal();
conditionT2.await();
}
conditionT1.signal();
} catch (Exception e) {
e.printStackTrace();
} finally {lock.unlock();
}
}, "t2").start();
}
}在这里,用一个自旋式的写法,就是我们没有锁,相当于自己写了一个自旋锁。cas的写法,这个写法用了enum,到底哪个线程要运行他只能取两个值,T1和T2,然后定义了一个ReadyToRun的变量,刚开始的时候是T1,这个意思呢就相当于是我有一个信号灯,这个信号灯要么就是T1要么就是T2,只能取这个两个值,不能取别的,当一开始的时候我在这个信号灯上显示的是T1,T1你可以走一步。看程序,第一上来判断是不是T1啊,如果不是就占用cpu在这循环等待,如果一看是T1就打印,然后把r值变成T2进行下一次循环,下一次循环上来之后这个r是不是T1,不是T1就有在这转圈玩儿,而第二个线程发现它变成T2了,变成T2了下面的线程就会打印A,打印完了之后有把这个r变成了T1,就这么交替交替,就是这个一种玩法,写volatile是保证线程的可见性。为什么要用enum类型,就是防止它取别的值,用一个int类型或者布尔也都可以。
package com.mashibing.juc.c_026_00_interview.A1B2C3;public class T03_00_cas {enum ReadyToRun {T1, T2}static volatile ReadyToRun r = ReadyToRun.T1; //思考为什么必须volatilepublic static void main(String[] args) {char[] aI = "1234567".toCharArray();char[] aC = "ABCDEFG".toCharArray();new Thread(() -> {for (char c : aI) {while (r != ReadyToRun.T1) {}
System.out.print(c);
r = ReadyToRun.T2;
}
}, "t1").start();new Thread(() -> {for (char c : aC) {while (r != ReadyToRun.T2) {}
System.out.print(c);
r = ReadyToRun.T1;
}
}, "t2").start();
}
}在来看一个BlockingQueue的玩法,上节课呢讲了BlockingQueue了,它有一个特点,
BlockingQueue可以支持多线程的阻塞操作,他有两个操作一个是put,一个take。put的时候满了他就会阻塞住,take的时候如果没有,他就会阻塞住在这儿等着,我们利用这个特点来了两个BlockingQueue,这两个BlockingQueue都是ArrayBlockingQueue数组实现的,但是数组的长度是1,相当于我用了两个容器,这两个容器里头放两个值,这两个值比如说我第一个线程打印出1来了我就在这边放一个,我这边OK了,该你了,而另外一个线程盯着这个事,他take,这个take里面没有值的时候他是要在这里阻塞等待的,take不到的时候他就等着,等什么时候这边打印完了,take到了他就打印这个A,打印完了A之后他就往第二个里面放一个OK,第一个线程也去take第二个容器里面的OK,什么时候take到了他就接着往下打印,大概是这么一种玩儿法。
package com.mashibing.juc.c_026_00_interview.A1B2C3;import java.util.concurrent.ArrayBlockingQueue;import java.util.concurrent.BlockingQueue;import java.util.concurrent.locks.LockSupport;public class T04_00_BlockingQueue {static BlockingQueue q1 = new ArrayBlockingQueue(1);static BlockingQueue q2 = new ArrayBlockingQueue(1);public static void main(String[] args) throws Exception {char[] aI = "1234567".toCharArray();char[] aC = "ABCDEFG".toCharArray();new Thread(() -> {for(char c : aI) {
System.out.print(c);try {
q1.put("ok");
q2.take();
} catch (InterruptedException e) {
e.printStackTrace();
}}
}, "t1").start();new Thread(() -> {for(char c : aC) {try {
q1.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.print(c);try {
q2.put("ok");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "t2").start();
}
} 这个效率非常低,它里面有各种的同步,我们了解一下就可以了,基本上面试也问不到这个。这里要把两个线程连接起来要求的步骤比较多,要求建立一个PipedInputStream和一个PipedOutputStream。
就相当于两个线程通信,第一个这边就得有一个OutputStream,对应第二个线程这边就得有一个InputStream,同样的第二个要往第一个写的话,第一个也得有一个InputStream,第二个也还得有一个OutputStream。最后要求你的第一个线程的input1和你第二个线程的output2连接connect起来,互相之间的扔消息玩儿,这边搞定了告诉另一边儿,另一边儿搞定了告诉这边,回合制。
package com.mashibing.juc.c_026_00_interview.A1B2C3;import java.io.IOException;import java.io.PipedInputStream;import java.io.PipedOutputStream;public class T10_00_PipedStream {public static void main(String[] args) throws Exception {char[] aI = "1234567".toCharArray();char[] aC = "ABCDEFG".toCharArray();
PipedInputStream input1 = new PipedInputStream();
PipedInputStream input2 = new PipedInputStream();
PipedOutputStream output1 = new PipedOutputStream();
PipedOutputStream output2 = new PipedOutputStream();
input1.connect(output2);
input2.connect(output1);
String msg = "Your Turn";new Thread(() -> {byte[] buffer = new byte[9];try {for(char c : aI) {input1.read(buffer);if(new String(buffer).equals(msg)) {
System.out.print(c);
}
output1.write(msg.getBytes());
}
} catch (IOException e) {
e.printStackTrace();
}
}, "t1").start();new Thread(() -> {byte[] buffer = new byte[9];try {for(char c : aC) {
System.out.print(c);
output2.write(msg.getBytes());
input2.read(buffer);if(new String(buffer).equals(msg)) {continue;
}
}
} catch (IOException e) {
e.printStackTrace();
}
}, "t2").start();
}
}试了一下,使用Semaphore与Exchanger是解决不了这个问题的。(思考为什么?)
那么TransferQueue是一种什么样的队列呢,就是我一个线程往里头生产,生产者线程往里头生产的时候,我生产了之后扔在这的时候我这个线程是阻塞的不动的,什么时候有另外一个线程把这个拿走了,拿走了之后这个线程才返回继续运行。
我这个写法是这样的,我用了一个TransferQueue,我第一个线程上来二话不说先take,相当于第一个线程做了一个消费者,就在这个Queue等着,看看有没有人往里扔。第二个线程二话不说上来经过transfer,就把这个字母扔进去了,扔进去了一个A,第一个线程发现很好,来了一个,我就把这个拿出来打印,打印完之后我又进行transfer,进去了一个1。然后,第二个线程它去里面take,把这个1take出来打印。这个写法很好玩儿,相当于我们自己每个人都把自己的一个数字或者是字母交到一个队列里让对方去打印。
package com.mashibing.juc.c_026_00_interview.A1B2C3;import java.util.concurrent.LinkedTransferQueue;import java.util.concurrent.TransferQueue;public class T13_TransferQueue {public static void main(String[] args) {char[] aI = "1234567".toCharArray();char[] aC = "ABCDEFG".toCharArray();
TransferQueue queue = new LinkedTransferQueue();new Thread(()->{try {for (char c : aI) {
System.out.print(queue.take());queue.transfer(c);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "t1").start();new Thread(()->{try {for (char c : aC) {queue.transfer(c);
System.out.print(queue.take());
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "t2").start();
}
} 我们接下来讲高并发这个部分的理论知识的一部分,线程池。
线程池首先有几个接口先了解第一个是Executor,第二个是ExecutorService,在后面才是线程池的一个使用ThreadPoolExecutor。
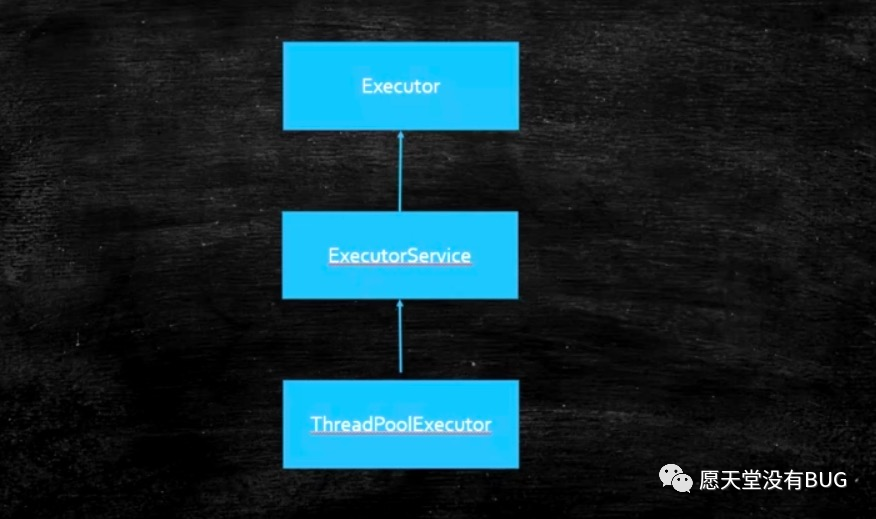
Executor看它的名字也能理解,执行者,所以他有一个方法叫执行,那么执行的东西是Runnable,所以这个Executor有了之后呢由于它是一个借口,他可以有好多实现,因此我们说,有了Executor之后呢,我们现场就是一个任务的定义,比如Runnable起了一个命令的意思,他的定义和运行就可以分开了,不像我们以前定义一个Thread,new一个Thread然后去重写它的Run方法.start才可以运行,或者以前就是你写了一个Runnable你也必须得new一个Thread出来,以前的这种定义和运行是固定的,是写死的就是你new一个Thread让他出来运行。有的同学他还是new一个Thread但是他有了各种各样新的玩法,不用你亲自去指定每一个Thread,他的运行的方式你可以自己去定义了,所以至于是怎么去定义的就看你怎么实现Executor的接口了,这里是定义和运行分开这么一个含义,所以这个接口体现的是这个意思,所以这个接口就比较简单,至于你是直接调用run还是new一个Thread那是你自己的事儿。
* The {@code Executor} implementations provided in this package* implement {@link ExecutorService}, which is a more extensive
* interface. The {@link ThreadPoolExecutor} class provides an* extensible thread pool implementation. The {@link Executors} class* provides convenient factory methods for these Executors.
*
* Memory consistency effects: Actions in a thread prior to
* submitting a {@code Runnable} object to an {@code Executor}
* "package-summary.html#MemoryVisibility">happen-before
* its execution begins, perhaps in another thread.
*
* @since 1.5* @author Doug Lea
*/public interface Executor {/**
* Executes the given command at some time in the future. The command
* may execute in a new thread, in a pooled thread, or in the calling
* thread, at the discretion of the {@code Executor} implementation.
*
* @param command the runnable task
* @throws RejectedExecutionException if this task cannot be
* accepted for execution
* @throws NullPointerException if command is null
*/void execute(Runnable command);
}
ExecutorService又是什么意思呢,他是从Executor继承,另外,他除了去实现Executor可以去执行一个任务之外,他还完善了整个任务执行器的一个生命周期,就拿线程池来举例子,一个线程池里面一堆的线程就是一堆的工人,执行完一个任务之后我这个线程怎么结束啊,线程池定义了这样一些个方法:
void shutdown();//结束List shutdownNow() ;//马上结束boolean isShutdown();//是否结束了boolean isTerminated();//是不是整体都执行完了boolean awaitTermination(long timeout, TimeUnit unit)throws InterruptedException;//等着结束,等多长时间,时间到了还不结束的话他就返回false等等,所以这里面呢,他是实现了一些个线程的线程池的生命周期的东西,扩展了Executor的接口,真正的线程池的现实是在ExecutorService的这个基础上来实现的。当我们看到这个ExecutorService的时候你会发现他除了Executor执行任务之外还有submit提交任务,执行任务是直接拿过来马上运行,而submit是扔给这个线程池,什么时候运行由这个线程池来决定,相当于是异步的,我只要往里面一扔就不管了。
那好,如果不管的话什么时候他有结果啊,这里面就涉及了比较新的类:比如说Future、RunnableFuture、FutureTask所以在这个里面我要给大家拓展一些线程的基础的概念,大家以前学线程的时候定义一个线程的任务只能去实现Runnable接口,那在1.5之后他就增加了Callable这个接口。
下面代码我们看一下Callable这个文档,他说这个接口和java.lang.Runnable类似,所以这两个类设计出来都是想潜在的另外一个线程去运行他,所以通过这点你会知道Callable和Runnable一样他也可以是一个线程来运行他,那好,为什么有了Runnable还要有Callable,很简单看代码Callable有一个返回值,call这个方法相当与Runnable里面的run方法,而Runnable里的方法返回值是空值,而这里是可以有一个返回值的,给你一个计算的任务,最后你得给我一个结果啊,这个叫做Callable,那么由于他可以返回一个结果,我就可以把这个结果给存储起来,等什么时候您老人家计算完了通知我就可以了,我就不需要像原来线程池里面我调用他的run在这等着了。
所以有了这个Callable之后就有了很多种新鲜的玩法,Callable是什么,他类似于Runnable,不过Callable可以有返回值。
package java.util.concurrent;/**
* A task that returns a result and may throw an exception.
* Implementors define a single method with no arguments called
* {@code call}.
*
* The {@code Callable} interface is similar to {@link* java.lang.Runnable}, in that both are designed for classes whose
* instances are potentially executed by another thread. A
* {@code Runnable}, however, does not return a result and cannot
* throw a checked exception.
*
*
The {@link Executors} class contains utility methods to
* convert from other common forms to {@code Callable} classes.
*
* @see Executor
* @since 1.5
* @author Doug Lea
* @param the result type of method {@code call}
*/
@FunctionalInterfacepublic interface Callable<V> {/**
* Computes a result, or throws an exception if unable to do so.
*
* @return computed result
* @throws Exception if unable to compute a result
*/V call() throws Exception;
}有了这个Callable之后呢,我们在来看一个接口:Future,这个Future代表的是什么呢,这个Future代表的是那个Callable被执行完了之后我怎么才能拿到那个结果啊,它会封装到一个Future里面。Future将来,未来。未来你执行完之后可以把这个结果放到这个未来有可能执行完的结果里头,所以Future代表的是未来执行完的一个结果。
由于Callable基本上就是为了线程池而设计的,所以你要是不用线程池的接口想去写Callable的一些个小程序还是比较麻烦,所以这里面是要用到一些线程池的直接的用法,比较简单,我们先用,用完后再给大家解释什么意思。我们来看Future是怎么用的,在我们读这个ExecutorService的时候你会发现他里面有submit方法,这个submit是异步的提交任务,提交完了任务之后原线程该怎么运行怎么运行,运行完了之后他会出一个结果,这个结果出在哪儿 ,他的返回值是一个Future,所以你只能去提交一个Callable,必须有返回值,把Callable的任务扔给线程池,线程池执行完了,异步的,就是把任务交给线程池之后我主线程该干嘛干嘛,调用get方法直到有结果之
后get会返回。Callable一般是配合线程池和Future来用的。其实更灵活的一个用法是FutureTask,即是一个Future同时又是一个Task,原来这Callable只能一个Task只能是一个任务但是他不能作为一个Future来用。这个FutureTask相当于是我自己可以作为一个任务来用,同时这个任务完成之后的结果也存在于这个对象里,为什么他能做到这一点,因为FutureTask他实现了RunnableFuture,而RunnableFuture即实现了Runnable又实现了Future,所以他即是一个任务又是一个Future。所以这个FutureTask是更好用的一个类。大家记住这个类,后面还会有WorkStealingPool、ForkJoinPool这些个基本上是会用到FutureTask类的。
package com.mashibing.juc.c_026_01_ThreadPool;import java.util.concurrent.*;public class T06_00_Future {public static void main(String[] args) throws InterruptedException,
ExecutionException {
FutureTask task = new FutureTask<>(()->{
TimeUnit.MILLISECONDS.sleep(500);return 1000;
}); //new Callable () { Integer call();}new Thread(task).start();
System.out.println(task.get()); //阻塞}
} 我们拓展了几个类,大家把这几个小类理解一下
Callable 类似与 Runnable,但是有返回值。
了解了Future,是用来存储执行的将来才会产生的结果。
FutureTask,他是Future加上Runnable,既可以执行又可以存结果。
CompletableFuture,管理多个Future的结果。
那么有了这些之后那,我们可以介绍一个CompletableFuture。他底层特别复杂,但是用法特别灵活,如果你们感兴趣可以去拓展的了解一下,用一下。CompletableFuture他的底层用的是ForkJoinPool。
我们先来看他的用法,这里有一个小例子,有这样一个情景可以用到这个CompletableFuture,这个CompletableFuture非常的灵活,它内部有好多关于各种结果的一个组合,这个CompletableFuture是可以组合各种各样的不同的任务,然后等这个任务执行完产生一个结果进行一个组合。我们直接看代码,假如你自己写了一个网站,这个网站都卖格力空调,同一个类型,然后很多人买东西都会进行一个价格比较,而你提供的这个服务就是我到淘宝上去查到这个格力空调买多少钱,然后我另启动一个线程去京东上找格力空调卖多少钱,在启动一个线程去拼多多上找,最后,我给你汇总一下这三个地方各售卖多少钱,然后你自己再来选去哪里买。
下面代码,模拟了一个去别的地方取价格的一个方法,首先你去别的地方访问会花好长时间,因此我写了一个delay() 让他去随机的睡一段时间,表示我们要联网,我们要爬虫爬结果执行这个时间,然后打印了一下睡了多少时间之后才拿到结果的,如拿到天猫上的结果是1块钱,淘宝上结果是2块钱,京东上结果是3块钱,总而言之是经过网络爬虫爬过来的数据分析出来的多少钱。
然后我们需要模拟一下怎么拿到怎么汇总,第一种写法就是我注释的这种写法,就是挨着牌的写,假设跑天猫跑了10秒,跑淘宝拍了10秒,跑京东跑了5秒,一共历时25秒才总出来。但是如果我用不同的线程呢,一个一个的线程他们是并行的执行他们计算的结果是只有10秒。
但是用线程你写起来会有各种各样的麻烦事儿,比如说在去淘宝的过程中网络报错了该怎么办,你去京东的过程中正好赶上那天他活动,并发访问特别慢你又该怎么办,你必须得等所有的线程都拿到之后才能产生一个结果,如果想要做这件事儿的话与其是要你每一个都要写一个自己的线程,需要考虑到各种各样的延迟的问题,各种各样的异常的问题这个时候有一个简单的写法,用一个CompletableFuture,
首先第一点CompletableFuture他是一个Future,所以他会存一个将来有可能产生的结果值,结果值是一个Double,它会运行一个任务,然后这个任务最后产生一个结果,这个结果会存在CompletableFuture里面,结果的类型是Double。
在这里我就定义了三个Future,分别代表了淘宝、京东、天猫,用了CompletableFuture的一个方法叫supplyAsync产生了一个异步的任务,这个异步的任务去天猫那边去给我拉数据去。你可以想象在一个线程池里面扔给他一个任务让他去执行,什么时候执行完了之后他的结果会返回到这个futureTM里面。但是总体的要求就是这些个所有的future都得结束才可以,才能展示我最后的结果。
往下走还有这么一直写法,就是我把这三个future都可以扔给一个CompletableFuture让他去管理,他管理的时候可以调用allOf方法相当于这里面的所有的任务全部完成之后,最后join,你才能够继续往下运行。所以CompletableFuture除了提供了比较好用的对任务的管理之外,还提供了对于任务堆的管理,用于对一堆任务的管理。CompletableFuture还提供了很多的写法,比如下面Lambda表达式的写法。
CompletableFuture是什么东西呢?他是各种任务的一种管理类,总而言之呢CompletableFuture是一个更高级的类,它能够在很高的一个层面上来帮助你管理一些个你想要的各种各样的任务,比如说你可以对任务进行各种各样的组合 ,所有任务完成之后你要执行一个什么样的结果,以及任何一个任务完成之后你要执行一个什么样的结果,还有他可以提供一个链式的处理方式Lambda的一些写法,拿到任务之后结果进行一个怎样的处理。
/**
* 假设你能够提供一个服务
* 这个服务查询各大电商网站同一类产品的价格并汇总展示
* @author 马士兵 http://mashibing.com
*/package com.mashibing.juc.c_026_01_ThreadPool;import java.io.IOException;import java.util.Random;import java.util.concurrent.CompletableFuture;import java.util.concurrent.ExecutionException;import java.util.concurrent.TimeUnit;public class T06_01_CompletableFuture {public static void main(String[] args) throws ExecutionException,
InterruptedException {long start, end;/*start = System.currentTimeMillis();
priceOfTM();
priceOfTB();
priceOfJD();
end = System.currentTimeMillis();
System.out.println("use serial method call! " + (end - start));*/start = System.currentTimeMillis();
CompletableFuture futureTM = CompletableFuture.supplyAsync(()-
>priceOfTM());
CompletableFuture futureTB = CompletableFuture.supplyAsync(()-
>priceOfTB());CompletableFuture futureJD = CompletableFuture.supplyAsync(()-
>priceOfJD());
CompletableFuture.allOf(futureTM, futureTB, futureJD).join();
CompletableFuture.supplyAsync(()->priceOfTM())
.thenApply(String::valueOf)
.thenApply(str-> "price " + str)
.thenAccept(System.out::println);
end = System.currentTimeMillis();
System.out.println("use completable future! " + (end - start));try {
System.in.read();
} catch (IOException e) {
e.printStackTrace();
}
}private static double priceOfTM() {
delay();return 1.00;
}private static double priceOfTB() {
delay();return 2.00;
}private static double priceOfJD() {
delay();return 3.00;
}/*private static double priceOfAmazon() {
delay();
throw new RuntimeException("product not exist!");
}*/private static void delay() {int time = new Random().nextInt(500);try {
TimeUnit.MILLISECONDS.sleep(time);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.printf("After %s sleep!\n", time);
}
} 我们再来了解一下线程池,线程池呢从目前JDK提供的有两种类型,第一种就是普通的线程池
ThreadPoolExecutor,第二种是ForkJoinPool,这两种是不同类型的线程池,能干的事儿不太一样,大家先把结论记住。Fork分叉,分叉完再分叉,最后的结果汇总这叫join。给大家讲一个故事,在我上大学的时候NASA美国航天局他们有很多的数据,计算机的计算力不行,就想了办法,他把哪些要计算的气象或者宇宙中产生各种各样的数据进行一个分片,一大块儿数据分成一小片一小片的,然后自己的计算机确实算不过来,太多了,他就向全球发出请求,你们愿不愿意在计算机空余的时间来帮我做一些这样的饿计算,他是干过这样的一个事情的,我在上大学的时候是收到过NASA这样一个申请的。
所以这个就是ForkJoinPool的一个概念。这是两种不同类型的线程池,我们说线程池的时候一般是说的第一种线程池,严格来讲这两种是不一样的,今天我先来对ThreadPoolExecutor进行一个入门,后面我们再来讲ForkJoinPool。
ThreadPoolExecutor他的父类是从AbstractExecutorService,而AbstractExecutorService的父类是ExecutorService,再ExecutorService的父类是Executo,所以ThreadPoolExecutor就相当于线程池的执行器,就是大家伙儿可以向这个池子里面扔任务,让这个线程池去运行。另外在阿里巴巴的手册里面要求线程池是要自定义的,还有不少同学会被问这个线程池是怎么自定义。
我们来看怎么样手动定义一个线程池,手动定义线程池他有很多构造方法,我们找这个最常见的理解了就行了。大家看下面这里代码,我定义了一个任务Task,这个任务是实现Runnable接口,就是一个普通的任务了,每一个任务里有一个编号i,然后打印这个编号,主要干这个事儿,打印完后阻塞System.in.read(),每个任务都是阻塞的,toString方法就不说了,定义一个线程池最长的有七个参数,首先我们来理解什么叫线程池,线程池他维护这两个集合,第一个是线程的集合,里面是一个一个的线程。第二个是任务的集合,里面是一个一个的任务这叫一个完整的线程池。
我怎么定义这一个线程池,这里面的七个参数,
第一个参数corePoolSoze核心线程数,最开始的时候是有这个线程池里面是有一定的核心线程数的;
第二个叫maximumPoolSize最大线程数,线程数不够了,能扩展到最大线程是多少;
第三个keepAliveTime生存时间,意思是这个线程有很长时间没干活了请你把它归还给操作系统;
第四个TimeUnit.SECONDS生存时间的单位到底是毫秒纳秒还是秒自己去定义;
第五个是任务队列,就是我们上节课讲的BlockingQueue,各种各样的BlockingQueue你都可以往里面扔,我们这用的是ArrayBlockingQueue,参数最多可以装四个任务;
第六个是线程工厂defaultThreadFactory,他返回的是一个enw DefaultThreadFactory,它要去你去实现ThreadFactory的接口,这个接口只有一个方法叫newThread,所以就是产生线程的,可以通过这种方式产生自定义的线程,默认产生的是defaultThreadFactory,而defaultThreadFactory产生线程的时候有几个特点:new出来的时候指定了group制定了线程名字,然后指定的这个线程绝对不是守护线程,设定好你线程的优先级。自己可以定义产生的到底是什么样的线程,指定线程名叫什么(为什么要指定线程名称,有什么意义,就是可以方便出错是回溯);
第七个叫拒绝策略,指的是线程池忙,而且任务队列满这种情况下我们就要执行各种各样的拒绝策略,jdk默认提供了四种拒绝策略,也是可以自定义的。
1:Abort:抛异常
2:Discard:扔掉,不抛异常
3:DiscardOldest:扔掉排队时间最久的
4:CallerRuns:调用者处理服务
一般情况这四种我们会自定义策略,去实现这个拒绝策略的接口,处理的方式是一般我们的消息需要保存下来,要是订单的话那就更需要保存了,保存到kafka,保存到redis或者是存到数据库随便你然后做好日志。
package com.mashibing.juc.c_026_01_ThreadPool;import java.io.IOException;import java.util.concurrent.*;public class T05_00_HelloThreadPool {static class Task implements Runnable {private int i;public Task(int i) {this.i = i;
}@Overridepublic void run() {
System.out.println(Thread.currentThread().getName() + " Task " + i);try {
System.in.read();
} catch (IOException e) {
e.printStackTrace();
}
}@Overridepublic String toString() {return "Task{" +"i=" + i +'}';
}
}public static void main(String[] args) {
ThreadPoolExecutor tpe = new ThreadPoolExecutor(2, 4,60, TimeUnit.SECONDS,new ArrayBlockingQueue(4),
Executors.defaultThreadFactory(),new ThreadPoolExecutor.CallerRunsPolicy());for (int i = 0; i < 8; i++) {
tpe.execute(new Task(i));
}
System.out.println(tpe.getQueue());
tpe.execute(new Task(100));
System.out.println(tpe.getQueue());
tpe.shutdown();
}
} 今天讲的东西很多,复习的时候你就把一个一个小程序从头到尾看完,看懂意思之后自己去敲,前面呢我们通过一道面试题来复习了之前学的一些方法,重点是LockSupport以及synchronized_wait_notify。然后我们讲了ThreadPool的一个入门,讲ThreadPool的时候我们给大家扩展了Callable和Runnable的不同,Future用来存储执行的将来才会产生的结果、FutureTask,他是Future加上Runnable,既可以执行又可以存结果、CompletableFuture,管理各种各样的Future的结果。
本篇内容讲解的是线程池的内容,喜欢的朋友可以转发关注一下小编~~
本文就是愿天堂没有BUG给大家分享的内容,大家有收获的话可以分享下,想学习更多的话可以到微信公众号里找我,我等你哦。