
我用Python采集了6万多家火锅店数据,好吃的火锅在哪里!
大家好,我是菜鸟哥,最近太冷太冷了,取暖基本靠抖,通讯基本靠吼!不过天冷了,可以涮火锅吃羊肉,补一补!反正菜鸟哥很喜欢吃火锅,可以开始搞起来!那么,今天我们就用Python爬取某点评网站的火锅数据,一起找找好吃的火锅在哪里吧~~
目录:
1.说明
2.北京火锅店基础数据
3.北京火锅店评分数据
4.评价数及人均消费
5.都有哪些连锁店
6.爬虫过程
7.其他
接下来,我们来看看北京好吃的火锅都在哪里吧~
1.说明
环境
!! 环境
Windows:Windows-10
Python版本:3.7.9
IDE:Spyder 4.1.5
绘图库:matplotlib
数据
!! 数据
数据来源:大众点评-美食-北京-火锅
表单字段:['地区', '火锅类型', 'id', '商家名称', '商家评分', '评价数', '人均消费', '口味', '环境', '服务', '地址', '推荐菜']
表单数量:6416条有效数据(另有4000余条无评价等的店铺数据,记为无效数据,已删除)
2.北京火锅店基础数据
In [1]: df.id.nunique() #有效火锅店铺数:店铺id非重复计数
Out[1]: 5319
北京一共有5319家有评分的有效火锅店铺。
2.1. 火锅分类
算不上吃货的我,只知道两种火锅:火锅和铜锅。仔细一看,发现有接近小30种火锅种类,咱中国人真讲究。
在北京品类最多的有老北京火锅高达1020家,其次是川味麻辣火锅、羊蝎子火锅及串串香等。
以下是绘图代码:
# 获取数量前10的火锅类型
df_type = df.groupby('火锅类型')['id'].nunique().to_frame('数量').reset_index().sort_values('数量',ascending=False)
df_type.reset_index(drop=True,inplace=True)
df_type.head(10)
df_type10 = df_type.head(10) #前10
# 绘制柱状图
fig = df_type10.plot(kind='barh',x='火锅类型',y='数量',title="各类火锅店铺数量",
color='orange',figsize=(18,9),fontsize=16,
)
fig.axes.title.set_size(22) #设置标题字体大小
fig.legend(fontsize=16) #设置图例字体大小
fig.set_ylabel('火锅类型',fontdict={'fontsize':20}) #设置y轴名称及字体大小
for index, num in enumerate(df_type10['数量']): #添加数据标签
fig.text(num, index,s = num, ha = 'left', fontsize = 16)
2.2. 各地区火锅分类
以才哥在的海淀区为例,火锅类型最多的是川味麻辣,其次是老北京火锅、串串香和重庆火锅。不得不说,这些都是我爱吃的。
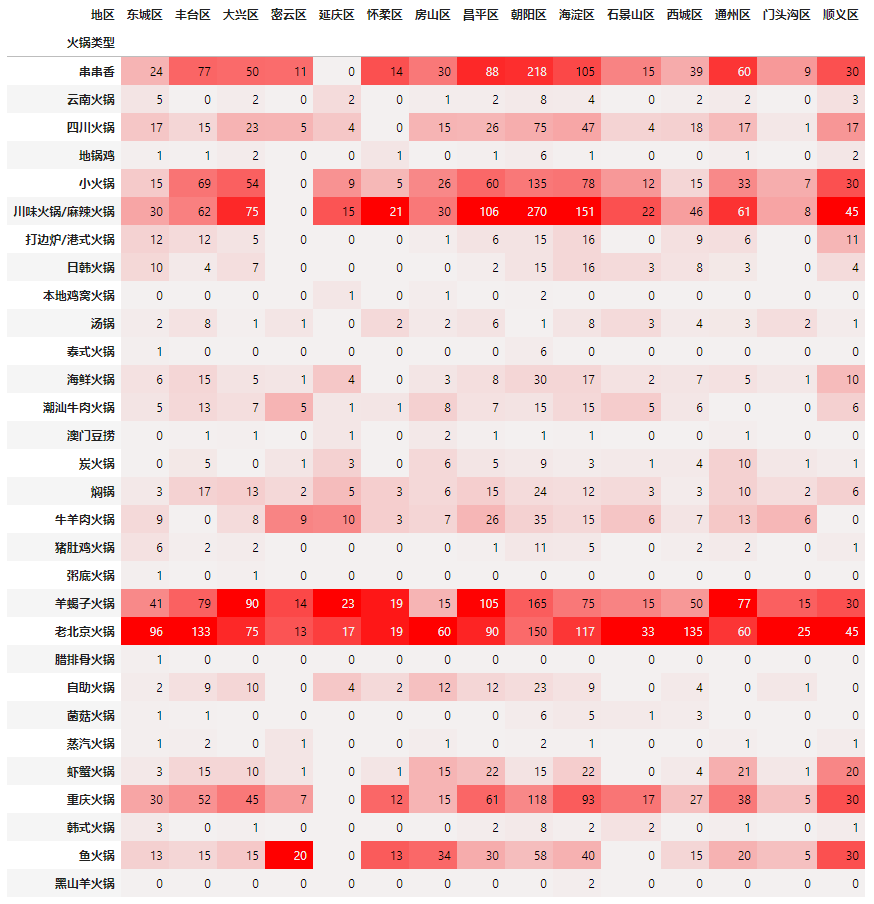
以下是制作代码:
df_loc_type = pd.pivot_table(df, values='id', index='火锅类型', columns='地区', aggfunc=pd.Series.nunique)
cm =sns.light_palette("red", as_cmap=True)
df_loc_type.fillna(0).astype(int).style.background_gradient(cmap=cm) #创建热力图背景(列)
2.3. 各地区火锅店数量
不得不说朝阳区也太牛了,接近1200家店,占总店的20%+。其次是咱们海淀、昌平这种打工人聚集的地方~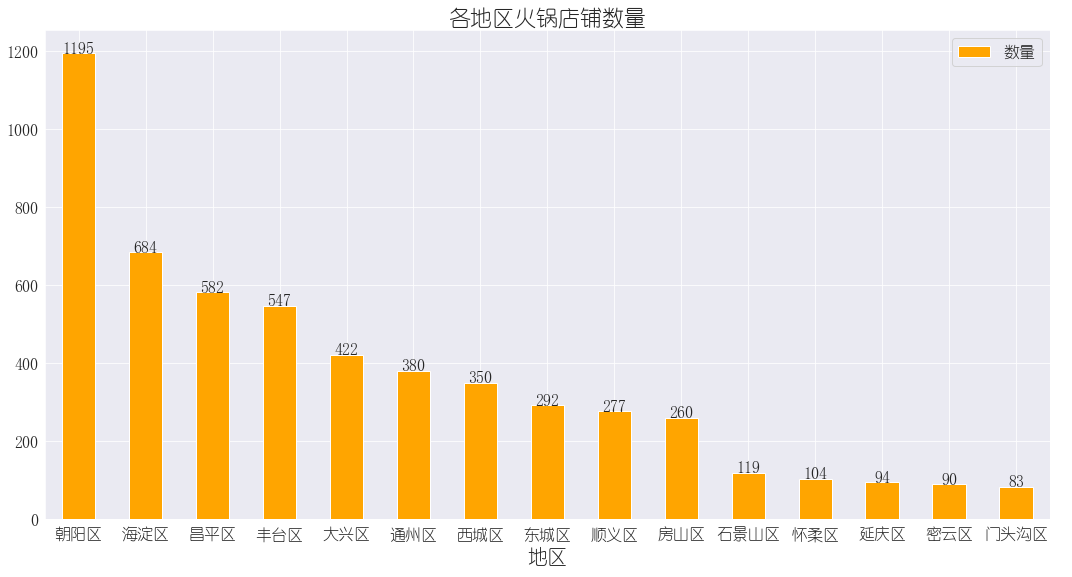
3.北京火锅店评分数据
从大众点评上爬取的店铺数据中,我们可以看到评分相关的数据指标有 商家评分(4.97)、口味、环境和服务评分共5类。
3.1. 评分直方图
组合四类评分绘制叠加直方图,可以看见基本上各项评分的分布基本一致,大部分分布在4分以下或者4.5分以上,两级分化比较明显。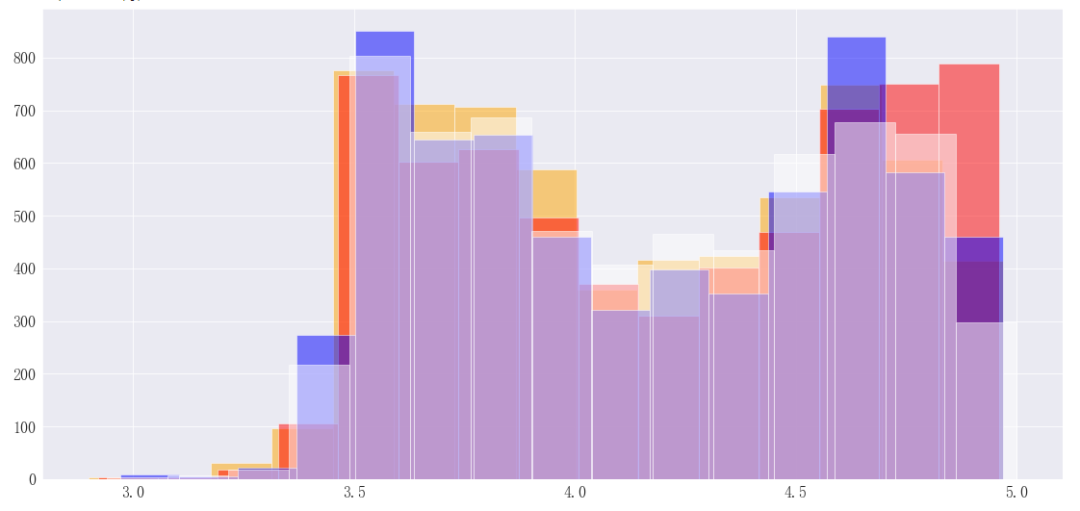 以下是绘图代码:
以下是绘图代码:
# 叠加直方图
plt.figure(figsize=(16,9))
plt.hist(x =df['商家评分'], color='orange', bins= 15, alpha=0.5) #橙色
plt.hist(x =df['口味'], color='red', bins= 15, alpha=0.5) # 红色
plt.hist(x =df['环境'], color='blue', bins= 15, alpha=0.5) # 蓝色
plt.hist(x =df['服务'], color='white', bins= 15, alpha=0.5) # 白色
plt.xticks(fontsize=20)
plt.yticks(fontsize=20)
3.2. 各地区商家评分箱线图
如图我们可以发现,东城区、朝阳区、西城区和海淀区是商家评分较高普遍较高,而密云和延庆等郊区除了个别火锅店评分较高之外整体普通较低。当然,这个其实是地理位置影响优质店铺选址,从而呈现这种表现。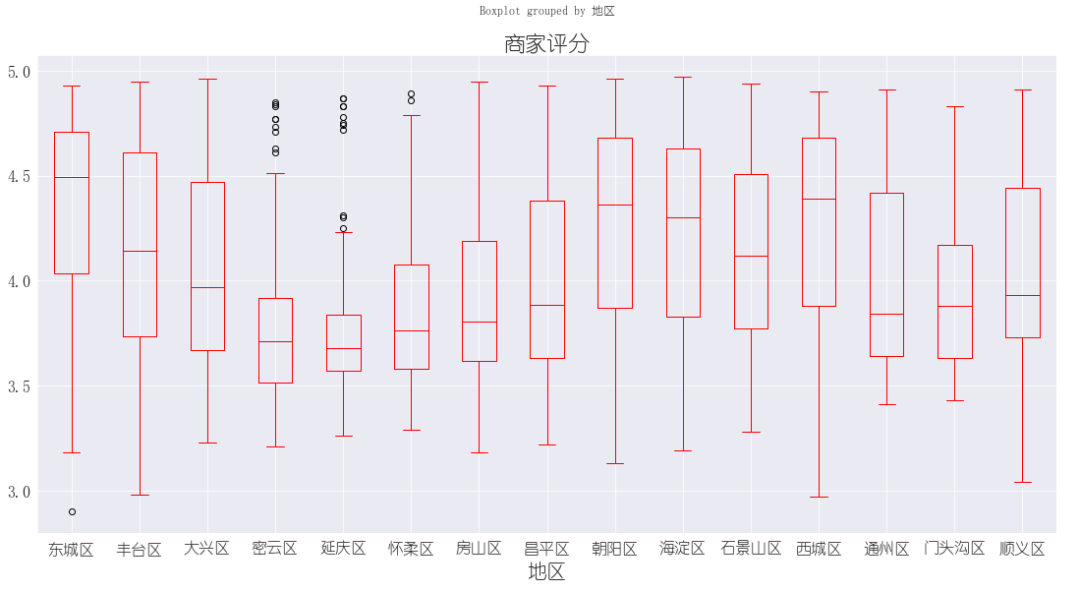 以下是绘图代码:
以下是绘图代码:
# 箱线图-商家评分
fig = df.boxplot(column='商家评分',by='地区', figsize=(18,9), color ='red',fontsize = 16)
fig.axes.title.set_size(22) #设置标题字体大小
fig.set_xlabel('地区',fontdict={'fontsize':20}) #设置y轴名称及字体大小
商家评分最高前5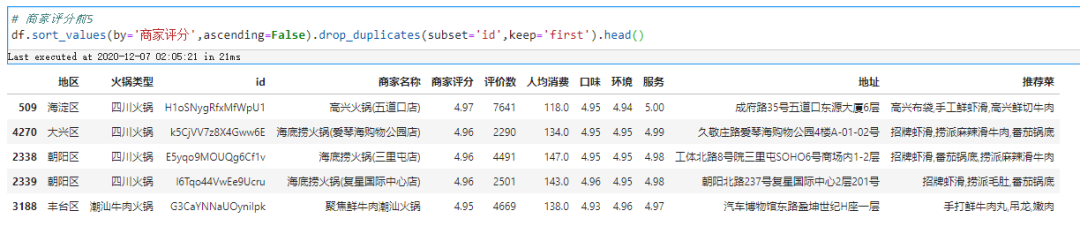
3.3. 各地区口味评分箱线图
对比商家评分的箱线图,我们发现东城区火锅店的口味评分有超过一半以上的店面超过了4.5分,基本上口味好的火锅店也都在北京的中心城区。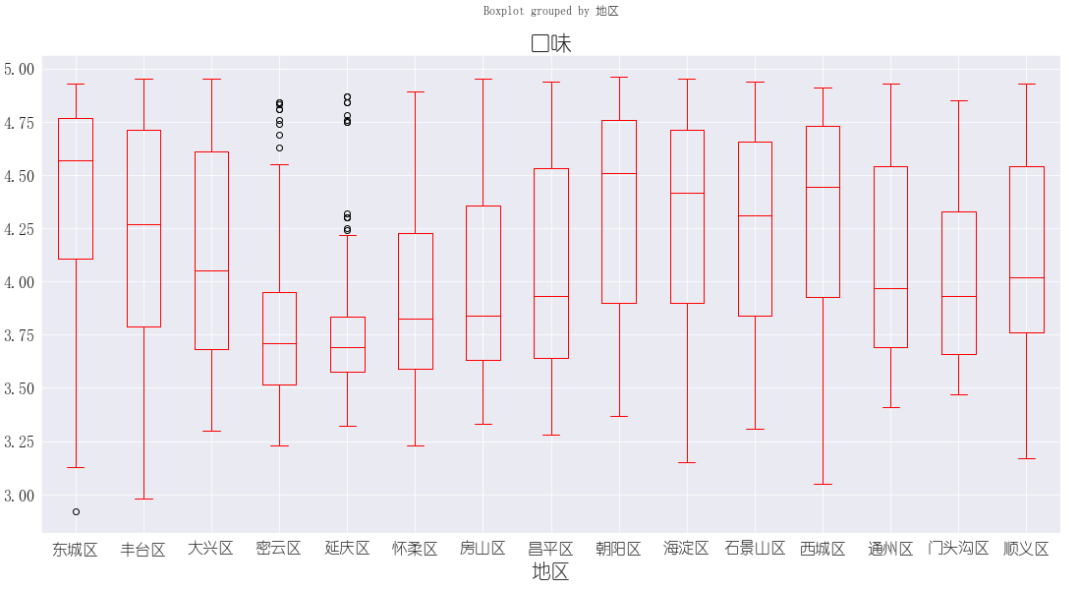 口味评分最高前5
口味评分最高前5
3.4. 各地区环境评分箱线图
环境评分整体较好的在东城区和朝阳区 环境评分最高前5
环境评分最高前5
3.5. 各地区服务评分箱线图
服务评分整体较好的也是在东城区和朝阳区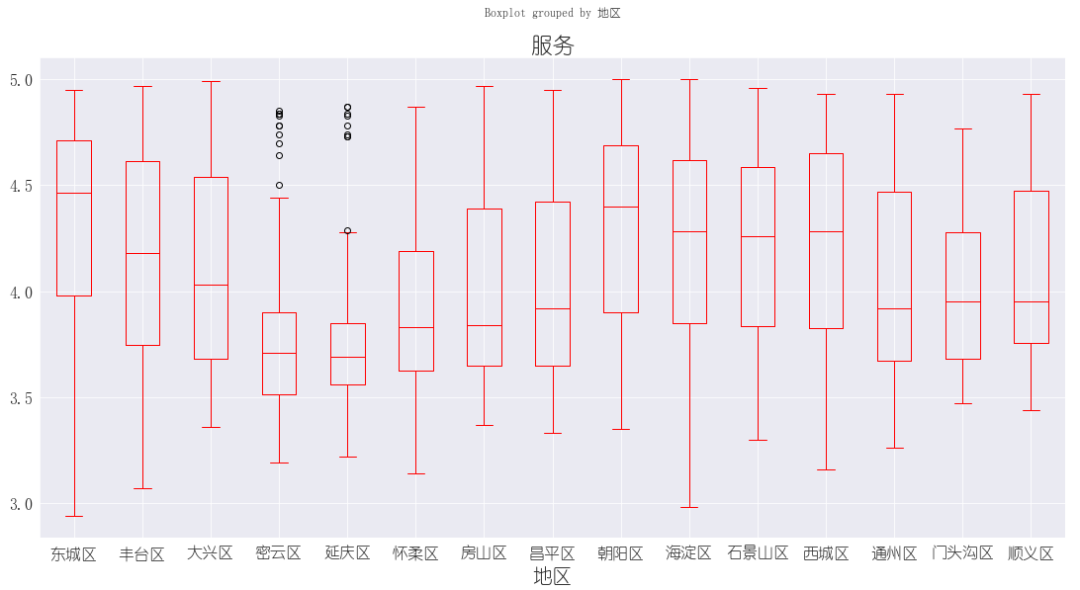 服务评分最高前5
服务评分最高前5
3.6. 各地区各项评分
我们查看四项评分之间的散点图矩阵,各地区的火锅店,商家评分和口味,环境与服务关联更强。口味好的一般评分应该不会太差,环境好的服务也一般不错。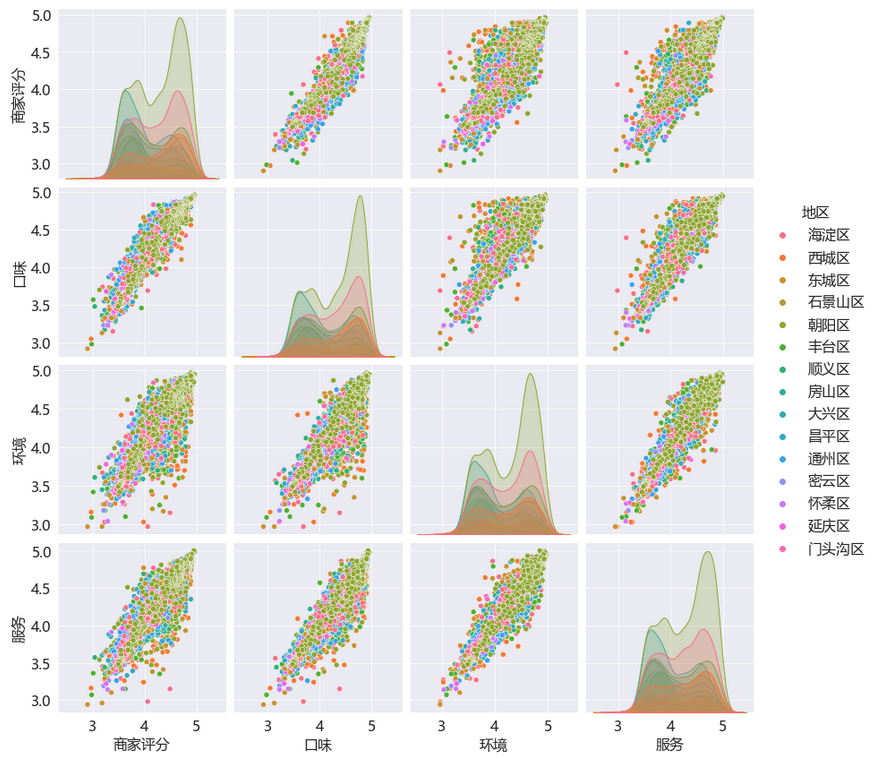
以下是绘图代码:
# 散点图矩阵
plt.rcParams["axes.labelsize"] = 16 # 设置全局轴标签字体大小
score = df[['商家评分','口味','环境','服务','地区']]
sns.pairplot(score, hue='地区',height=3)
4.评价数及人均消费
我在大众点评找店子的时候,除了看评分之外,评价数和人均消费也是极其重要的考量。当看到评价数极高的时候,内心会不由的表示惊叹“哇塞,这么多人写评价啊”;当看到人均消费极高的时候,也会想着啥时候我也要去吃一次,哈哈~
4.1. 整体评价数分布
先用描述统计看,发现评价数最多的有3.2万个,最少的仅1个,75%的火锅店评价在900以下,更有25%的火锅店评价不到23个。
In [1]:df.评价数.describe()
Out[1]:
count 6416.000000
mean 831.874065
std 1846.721435
min 1.000000
25% 23.000000
50% 211.000000
75% 881.000000
max 32099.000000
Name: 评价数, dtype: float64
一定程度上,评价数能反应一家店在广大吃货中的火爆度,我们发现最火的前5家有3家来自西城区,海淀区和东城区各1家。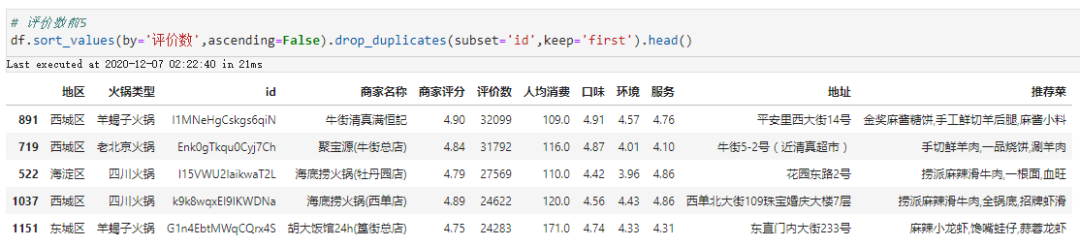
以下是2家评价数破3万的热门火锅店~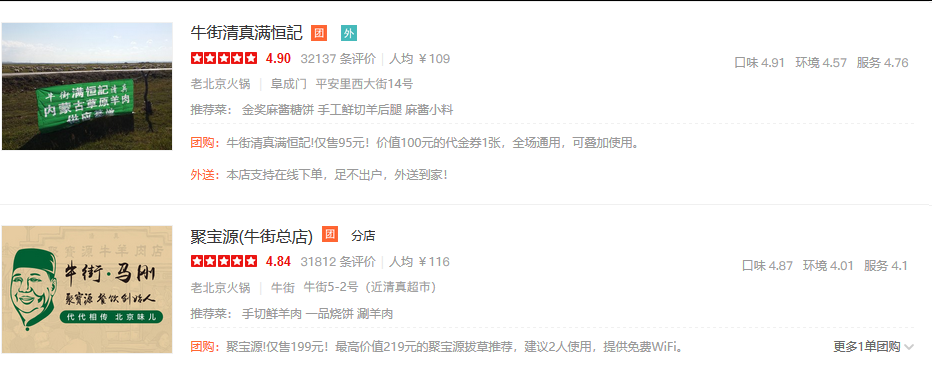
4.2.人均消费情况
一共有人均消费数据的店铺4129家,其中均值100元,中位数也是95元,最高的是1220元(我的天,这是啥火锅?)。
4.2.1.人均消费最贵的都有谁
人均消费最贵第1名是一家日韩火锅,推荐菜基本都是日料类。其次,人均消费较高的都是海鲜火锅一类,你看那些推荐菜都是帝王蟹、澳龙啥的,想吃了,哈哈!!
以下是2家人均消费破千的火锅店~
4.2.2.人均消费分布
大部分的火锅店人均消费低于100元,其次是100-150元区间。极少数在200+,虽然能吃的主很容易吃出200+的其实!! 以下是绘图代码:
以下是绘图代码:
plt.figure(figsize = (12,12))#将画布设定为正方形,绘制的饼图是正圆
plt.rcParams['font.size']=16 #设置字体大小为16
label = df_cost.index.tolist()#定义饼图的标签
explode = [0.01,0.01,0.01,0.01,0.01]#设定各项距离圆心n个半径
values = df_cost.数量.tolist()
plt.pie(values,explode = explode,labels = label,autopct = '%1.1f%%')#饼图
plt.title('人均消费分布',fontdict={'fontsize':20})#标题
我们经常听的海底捞火锅店的人均消费大概在130左右。
5.都有哪些连锁店
一共有349家品牌火锅有分店。
5.1.火锅分店前10品牌
果然是哪都有的呷哺呷哺(找了半天发音)以多大289家分店稳居第一!看着这些品牌,基本都是比较常见熟悉的,基本上都吃过来着。
5.2.火锅分店前10品牌人均消费
海底捞 人均消费 基本都在120以上,玩儿串串是一家什么店呀,人均基本都低于40,其次就是开了快300家店的呷哺呷哺也是人均消费比较合适。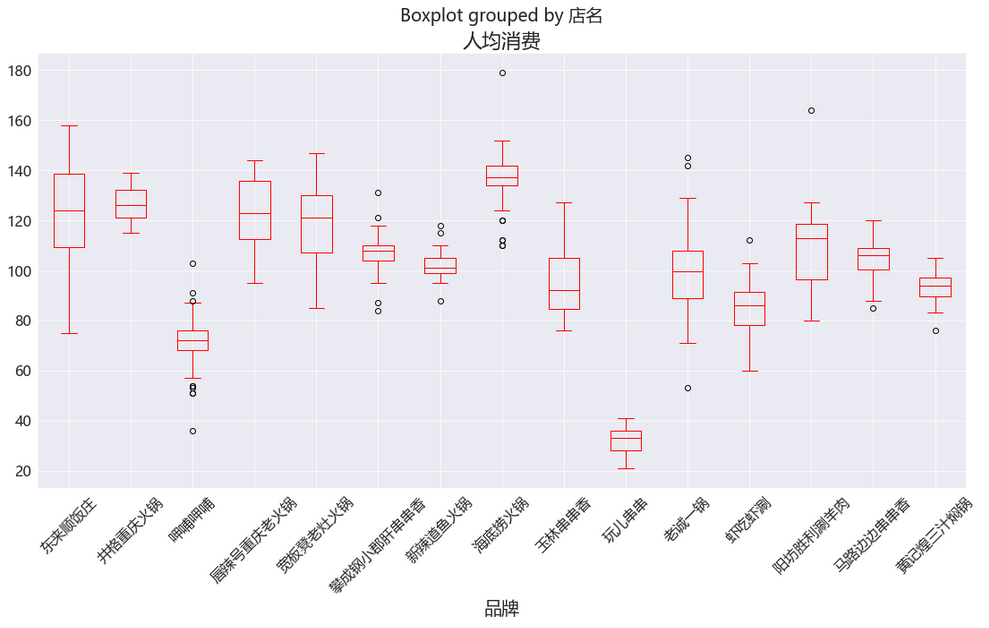
5.3.火锅分店前10品牌商家评分
好吧,又是海底捞 评分表现最佳,可恶的海底捞。不过各家品牌大部分评分还是都不错,在4.25分以上。玩儿串串作为小吃摊位放在这群雄里显得有点格格不入了,哈哈!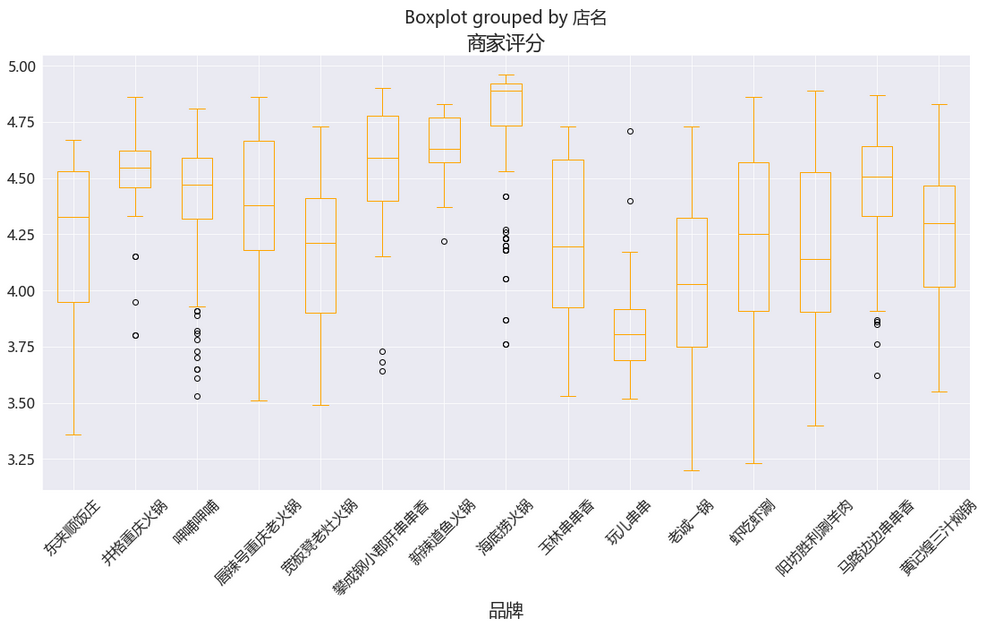
玩儿串串原来是这种,在购物中心的美食中心里的偏快餐式的串串儿~
6.爬虫过程
这里不介绍详细的爬虫过程,详细的见后续推送哈(主要是篇幅有限 写不完)。
咱们简单说说在爬虫过程中遇到的一些问题及解决方案。
FAQ
①大众点评的搜索结果最多只显示50页,如果获取全部数据?
解:搜索有多级选择,以北京火锅为例就是 子分类+地区,我们看到一页15家店铺最多50页就有750家,加上诸多级选择基本可以覆盖全部店铺。
②未登录情况下无法查看下一页获取地址规律
解:直接登录账号然后点击下一页查看地址变化规律呗。
③爬着爬着很快就被封ip了
解:嗯,而且不是说爬慢点就行,我就被封了2个ip貌似都是封1天以上,最后买了1000个ip代理,被封了就自动换解决。
④部分店铺信息对应字典为方框无法解析
解:网上有很多这种css字体加密解密的文章,边看边学吧(反正作为菜鸟的我是这么来的)
以下代码为简单的解析 北京火锅 子分类的脚本
import re
import requests
header = {
"Accept-Encoding": "Gzip", # 使用gzip压缩传输数据让访问更快
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:83.0) Gecko/20100101 Firefox/83.0",
}
url_beijing = 'http://www.dianping.com/beijing/ch10' #北京菜系
rep_beijing = requests.get(url_beijing, headers= header)
html_beijing = rep_beijing.text
location_html = re.findall('([\s\S]*?) location_name = re.findall('data-click-title="(.*?)"', location_html) #获取地区名称列表
location_id = re.findall('
dic_location = dict(zip(location_name,location_id)) #组合成字典备用
url_huoguo = 'http://www.dianping.com/beijing/ch10/g110' #火锅
rep_huoguo = requests.get(url_huoguo, headers= header)
html_huoguo = rep_huoguo.text
type_html = re.findall('
type_name = re.findall('(.*?)', type_html) #获取火锅类型名称列表
type_name = type_name[1:] #第一个是不限,需要去掉
type_id = re.findall('data-cat-id="(.*?)"',type_html) #获取火锅类型id
dic_type = dict(zip(type_name,type_id)) #组合成字典备用
7.如何获取代码
免责声明: 那个,咱们爬虫仅用于简单交流,切勿用做任何商业用途
推荐阅读:
入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径
量化: 定投基金到底能赚多少钱? | 我用Python对去年800只基金的数据分析
干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影
趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!
AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影
小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|

年度爆款文案
点阅读原文,看Python全套!
