
头条面试官:NIO 是不是就是I/O多路复用?我:不是
似乎从互联网起源,BIO、NIO 的话题就从未间断,无论是平时还是面试。那么他们到底是什么?希望你看完这个文章彻底理解这些概念,同时这边文章也使用 Java 代码实现一个 I/O 多路复用的实例,最后到 I/O 原理。
IO 是什么?
首先要了解什么是 I/O,一次网络请求、一次磁盘读取都是I/O,所以可以泛泛的理解,数据需要通过媒介进行读取和写入都是IO。
下面是一次网络内容读取的 I/O 示意图,数据从外设(网卡)到内核空间,到用户空间(JVM)最后到应用程序的一个过程,那么阻塞和非阻塞指的是哪里呢?
我们换一个调用链路图说明一下阻塞的位置,第一张图解释的是 BIO,也就是同步阻塞 IO,Java 最早期的版本的 IO 就是这样实现的。当程序调用到读取IO的时候,同步阻塞住程序,直到数据从网卡写入内核空间,再写入用户空间才返回数据,程序才可以继续运行。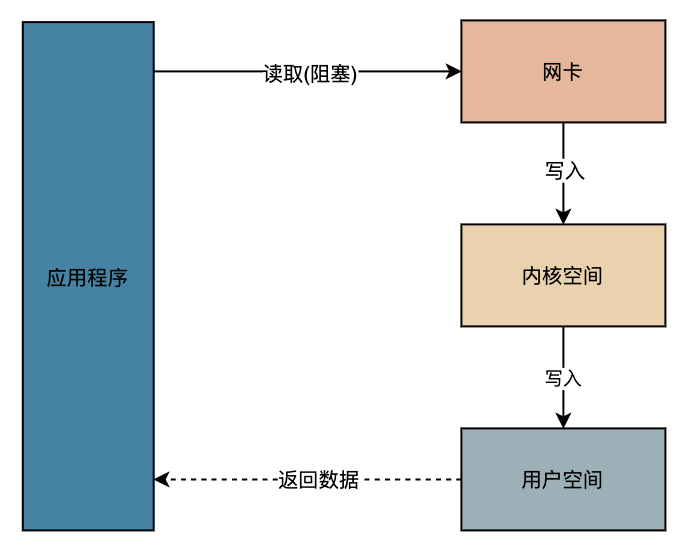 等到 Java 1.4 版本以后就支持了 NIO,其实 NIO 解决的地方是从网卡到内核空间部分的阻塞,也就是说应用程序发送一个读取 IO 的请求,如果数据还没有从网卡写入内核空间,直接返回未就绪,这样就做到了不需要程序死等到结果。等到写入内核空间以后,程序继续读取数据,这时候才会阻塞程序,如下图。
等到 Java 1.4 版本以后就支持了 NIO,其实 NIO 解决的地方是从网卡到内核空间部分的阻塞,也就是说应用程序发送一个读取 IO 的请求,如果数据还没有从网卡写入内核空间,直接返回未就绪,这样就做到了不需要程序死等到结果。等到写入内核空间以后,程序继续读取数据,这时候才会阻塞程序,如下图。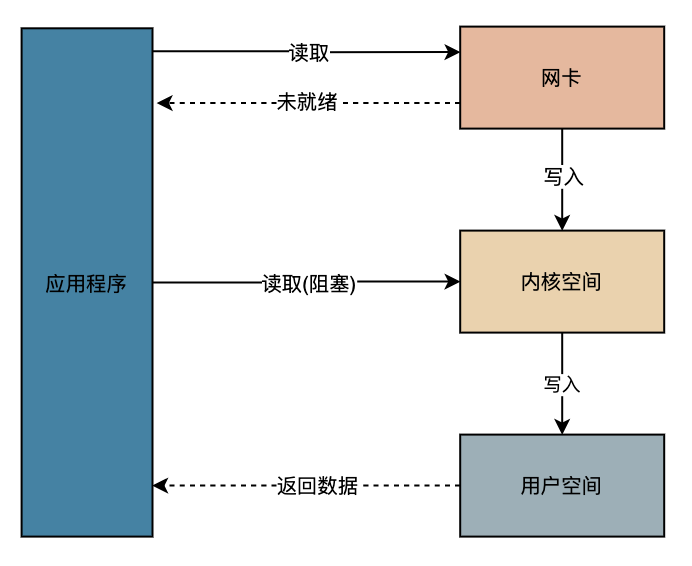 关于 *IO 如果还是不理解的话,可以看下这篇文章,讲解的还是比较生动。《第一次听人用男女关系讲 NIO,虽然有点污,但很好理解》。
关于 *IO 如果还是不理解的话,可以看下这篇文章,讲解的还是比较生动。《第一次听人用男女关系讲 NIO,虽然有点污,但很好理解》。
IO 多路复用
基本的 IO 了解了,那我们开始进入 IO 多路复用的理解。假设我们要实现一个在线聊天系统,一共有 100 人同时聊天,我们先不管“路”多不多,需要同时支持 100 人我们需要怎么做?
我们需要为每一个请求用户创建一个新的线程,才能同时支持多个用户同时使用,然鹅,随着用户越来越多,需要创建的线程也越来越多,频繁的上下文切换和线程的创建和销毁,对于系统性能影响非常大,具体的链路可以通过下面的图理解下。
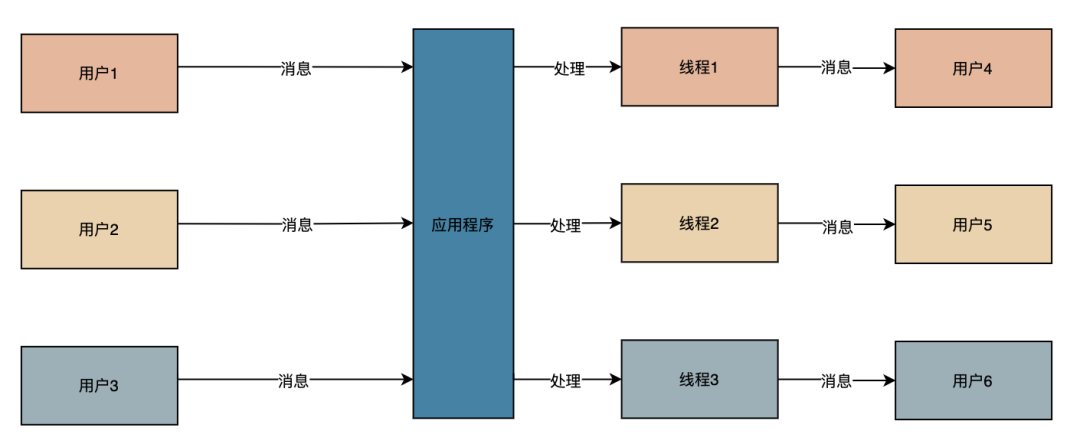
那么是不是可以去掉多线程环节,使用一个线程处理 N 个 IO 请求,没有上下文切换和线程的创建和销毁,程序是不是反而更快呢?这就是 IO 多路复用的思路。
首先我们从字面上理解一下,多路复用的英文是 multiplexing,中文翻译为“复用”,其实简单的理解就是使用单个线程通过记录跟踪每一个流(I/O)的状态来同时管理多个I/O,以此来减少线程的创建和切换的开销,进而提高服务器的吞吐能力。那么这么解释下来就更容易理解了,看图一目了然。
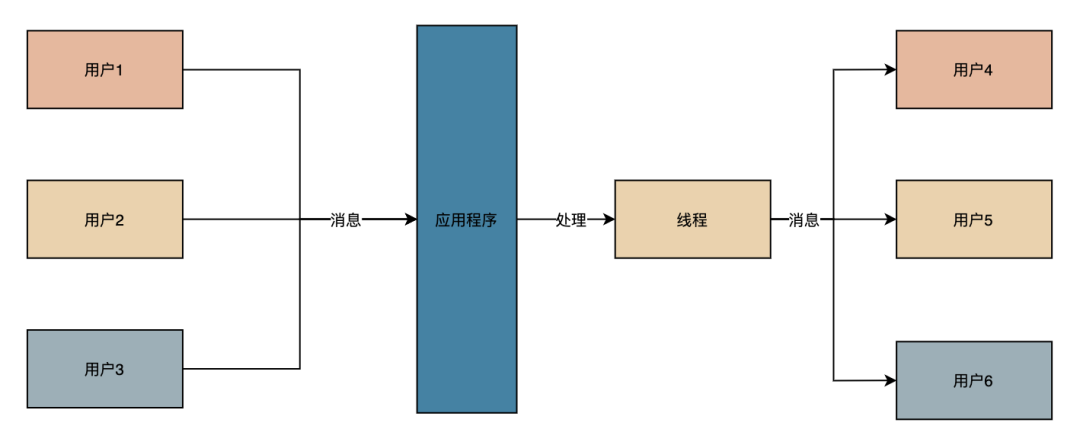
既然使用单线程解决多个 IO 的切换问题,那么必须不能阻塞,如果阻塞了还是需要串行的读取 IO,阻塞程序的,切换就没有意义了,所以 NIO 并完全等于IO多路复用,而是解决多路复用的必要条件“非阻塞“,这也回答了标题的问题。
自己实现 IO 多路复用
上文了解了什么是 IO 多路复用自己也就可以实现了,下面就是我用 Java 写的 IO 多路复用的代码,代码只是表达意思,有问题可以互相讨论。
public void start() throws IOException {
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.bind(new InetSocketAddress(6789));
serverSocketChannel.configureBlocking(false);
while (true) {
SocketChannel channel = serverSocketChannel.accept();
register(channel);
Set<SocketChannel> selectionKeys = selectedKeys();
if (selectionKeys.size() != 0) {
for (SocketChannel socketChannel : selectionKeys) {
handle(socketChannel);
}
}
}
}
private void register(SocketChannel channel) {
if (channel != null) {
publicKeys.add(channel);
}
}
private Set<SocketChannel> publicKeys = new HashSet<>();
private Set<SocketChannel> selectedKeys() {
Set<SocketChannel> publicSelectedKeys = new HashSet<>();
for (SocketChannel fd : publicKeys) {
if ((fd.validOps() & OP_READ) != 0) {
publicSelectedKeys.add(fd);
}
}
return publicSelectedKeys;
}
private void handle(SocketChannel socketChannel) throws IOException {
ByteBuffer byteBuffer = ByteBuffer.allocate(512);
StringBuilder sb = new StringBuilder();
while (socketChannel.read(byteBuffer) > 0) {
byteBuffer.flip();
sb.append(StandardCharsets.UTF_8.decode(byteBuffer));
}
if (sb.length() > 0) {
System.out.println("服务端收到消息:" + sb.toString());
}
}
逻辑相对还是比较简单,直接介绍几个关键的信息。
定义 register方法,当有新的连接进来直接添加到publicKeysset 集合里面,这样就有了一个地方可以存放所有的 socket 连接。定义 selectedKeys方法,用于获取所有ready状态的 socket,原理是使用(fd.validOps() & OP_READ) != 0遍历所有的在publicKeys里面的 socket判断是否可以读取了,然后添加到selectedKeys结果集里面,因为fd.validOps()这个判断是非阻塞的,所以可以继续运营程序。外层 while (true)循环获取可以读取的socket从而实现 IO 多路复用逻辑。
是不是逻辑很清晰?然后写一个超级简单的 Client 就可以测试验证了。
public void start() throws IOException {
SocketChannel socketChannel = SocketChannel.open(new InetSocketAddress(6789));
socketChannel.configureBlocking(false);
Scanner scanner = new Scanner(System.in);
while (scanner.hasNextLine()) {
String request = scanner.nextLine();
if (request != null && request.length() > 0) {
socketChannel.write(StandardCharsets.UTF_8.encode(request));
}
}
}
系统实现
好了,那么问题来了,自己实现的 IO 多路复用不就可以了吗?为啥网上不停的吹嘘 select、poll、epoll 啥的?到这里我们一起看下 select 的源码你就懂了。
int select(
int nfds,
fd_set *readfds,
fd_set *writefds,
fd_set *exceptfds,
struct timeval *timeout);
我们简单的对这些参数讲解下
nfds: 监控的文件描述符集里最大文件描述符加1,简单理解为需要循环遍历的文件数 readfds/writefds/exceptfds:读/写/异常事件的监听描述符集合。 timeout:阻塞的超时时间
如果你想更深入研究下源码,可以直接到 https://www.kernel.org/ 下载源码,找到 fs/select.c 文件即可。
话题回到最初,通过上面的参数我们了解到,系统层面的 select 的实现其实是更底层的实现了刚才我们写的循环遍历查找思路,只是直接在系统层面性能更高。
那么 poll、epoll 又是什么呢?poll 也是操作系统提供的系统调用函数,它和 select 的主要区别就是,去掉了 select 只能监听 1024 个文件描述符的限制。epoll 则是最后的升级版本,程序调用 epoll 的时候不需要全量传递了,支持变化传递,同时不需要循环遍历,而是通过异步 IO 事件唤醒程序。
所以到这里你明白了,其实无论是系统或者是直接自己写代码都是在解决单线程复用的问题,也就是我们文章说的 IO 多路复用。