
搞懂I/O多路复用及其技术
点击上方「蓝字」关注我们

前言
高性能是每个程序员的追求,无论写一行代码还是做一个系统,都希望能够达到高性能的效果。高性能架构设计主要集中在两方面:
尽量提升单服务器的性能,将单服务器的性能发挥到极致
如果单服务器无法支撑性能,设计服务器集群方案
单服务器高性能的关键之一就是服务器采取的网络编程模型。服务器如何管理连接,如何处理请求等。这两个设计点最终都和操作系统的I/O模型及进程模型相关。
I/O模型:阻塞、非阻塞、同步、异步
进程模型:单进程、多进程、多线程。
我们所说的I/O模型是指网络I/O模型,就是服务端如何管理连接,如何请求连接的措施,是用一个进程管理一个连接(PPC),还是一个线程管理一个连接(TPC),亦或者一个进程管理多个连接(Reactor)。
因此IO多路复用中多路就是多个TCP连接(或多个Channel),复用就是指复用一个或少量线程,理解起来就是多个网路IO复用一个或少量线程来处理这些连接。
常见I/O模型
同步阻塞IO(Blocking IO):即传统IO模型
同步非阻塞IO(Non-blocking IO):默认常见的socket都是阻塞的,非阻塞IO要求socket被设置成NONBLOCK
IO多路复用(IO Multiplexing):即经典的Reactor设计模式,也被称为异步阻塞IO,Java中的selector和linux中的epoll都是这种模型
异步IO(Asychronous IO):即Proactor设计模式,也被称为异步非阻塞IO
同步和异步的概念描述的是用户线程与内核的交互方式,这里所说的用户进程/线程和内核是以传输层为分割线的,传输层以上是指用户进程,传输层以下(包括传输层)是指内核(处理所有通信细节,发送数据,等待确认,给无序到达的数据排序等,这四层是操作系统内核的一部分)。同步是指用户线程发起IO请求后需要等待或者轮询内核IO操作,完成后才能继续执行。异步是指用户线程发起IO请求后仍继续执行,当内核IO操作完成后回通知用户线程,或者调用用户线程注册的回调函数。
阻塞和非阻塞的概念描述的是用户线程调用内核IO操作的方式,阻塞时指IO操作需要彻底完成后才能返回用户空间,非阻塞时指IO操作被调用后立即返回给用户一个状态值,无需等待IO操作彻底完成。
同步阻塞IO
同步阻塞IO是最简单的IO模型,用户线程在内核进行IO操作时被阻塞。用户线程通过调用系统调用read发起IO读操作,由用户空间转到内核空间。内核等到数据包到达后,然后将接受的数据拷贝到用户空间,完成read操作。整个IO请求过程,用户线程都是被阻塞的,对CPU利用率不够

同步非阻塞IO
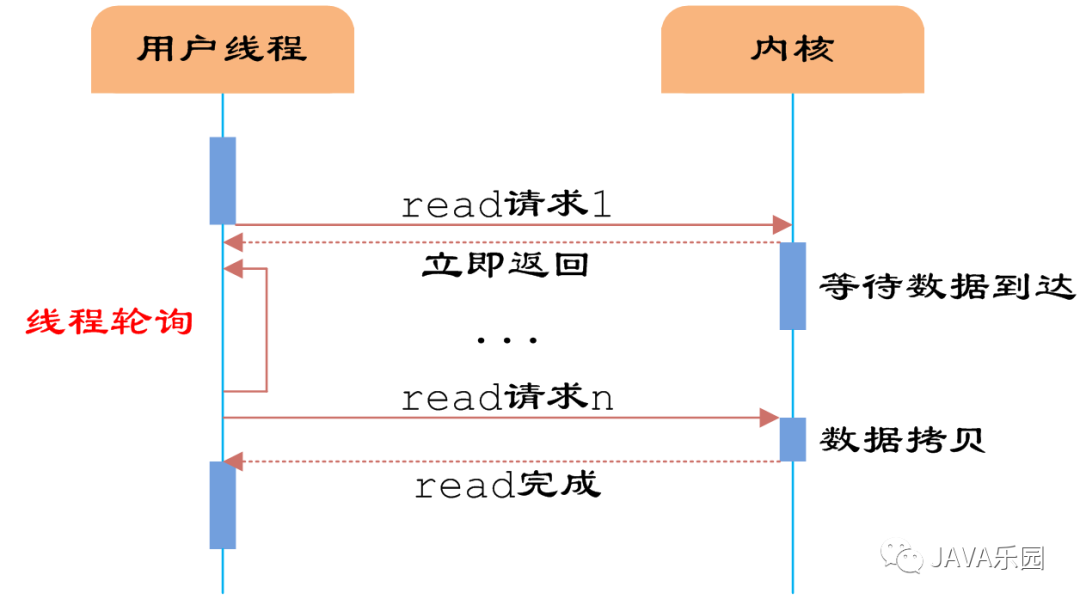
在同步基础上,将socket设置为NONBLOCK,这样用户线程可以在发起IO请求后立即返回。虽说可以立即返回,但并未读到任何数据,用户线程需要不断的发起IO请求,直到数据到达后才能真正读到数据,然后去处理。
整个IO请求中,虽然可以立即返回,但是因为是同步的,为了等到数据,需要不断的轮询、重复请求,消耗了大量的CPU资源。因此,这种模型很少使用,实际用处不大。
IO多路复用
不管是同步阻塞还是同步非阻塞,对系统性能的提升都是很小的。而通过复用可以使一个或一组线程(线程池)处理多个TCP连接。IO多路复用使用两个系统调用(select/poll/epoll和recvfrom),blocking IO只调用了recvfrom。select/poll/epoll核心是可以同时处理多个connection,而不是更快,所以连接数不高的话,性能不一定比多线程+阻塞IO好。
select是内核提供的多路分离函数,使用它可以避免同步非阻塞IO中轮询等待问题。
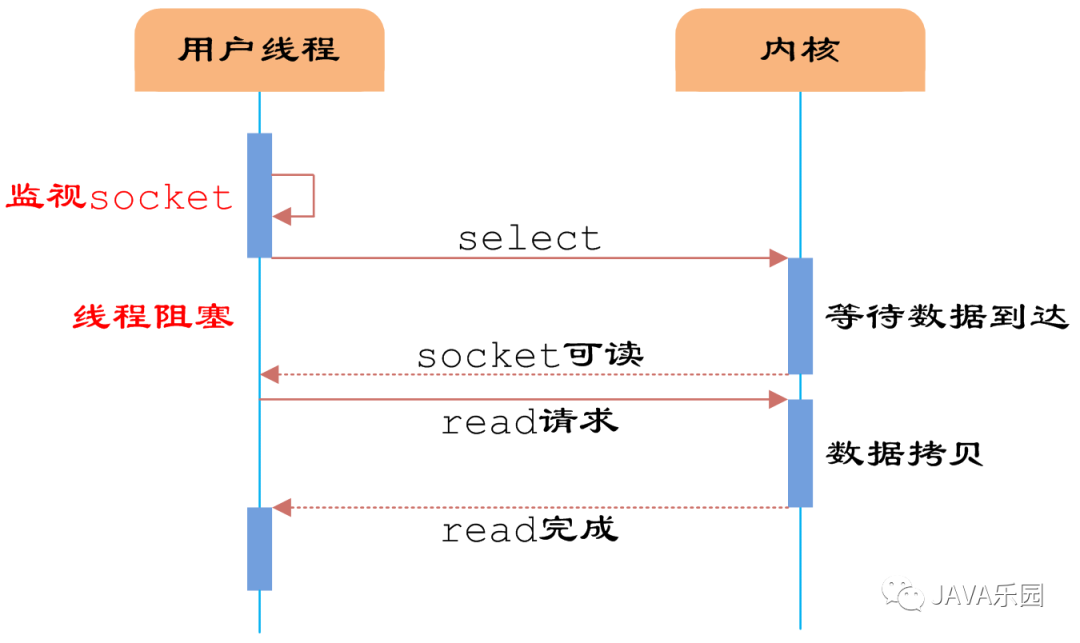
用户首先将需要进行IO操作的socket添加到select中,然后阻塞等待select系统调用返回。当数据到达时,socket被激活,select函数返回,用户线程正式发起read请求,读取数据并继续执行。
这么一看,这种方式和同步阻塞IO并没有太大区别,甚至还多了添加监视socket以及调用select函数的额外操作,效率更差。但是使用select以后,用户可以在一个线程内同时处理多个socket的IO请求,这就是它的最大优势。用户可以注册多个socket,然后不断调用select读取被激活的socket,即可达到同一个线程同时处理多个IO请求的目的。而在同步阻塞模型中,必须通过多线程方式才能达到这个目的。所以IO多路复用设计目的其实不是为了快,而是为了解决线程/进程数量过多对服务器开销造成的压力。
select(socket); #向select注册socket
while(true){
sockets = select(); #获取被激活的socket
for(socket in sockets){
if(can_read(socket)){ #socket可读,调用read读取数据
read(socket,buffer);
process(buffer);
}
}
}
虽然这种方式允许单线程内处理多个IO请求,但是每个IO请求的过程还是阻塞的(在select函数上阻塞),平均时间甚至比同步阻塞IO模型还要长。如果用户线程只注册自己感兴趣的socket,然后去做自己的事情,等到数据到来时在进行处理,则可以提高CPU利用率。
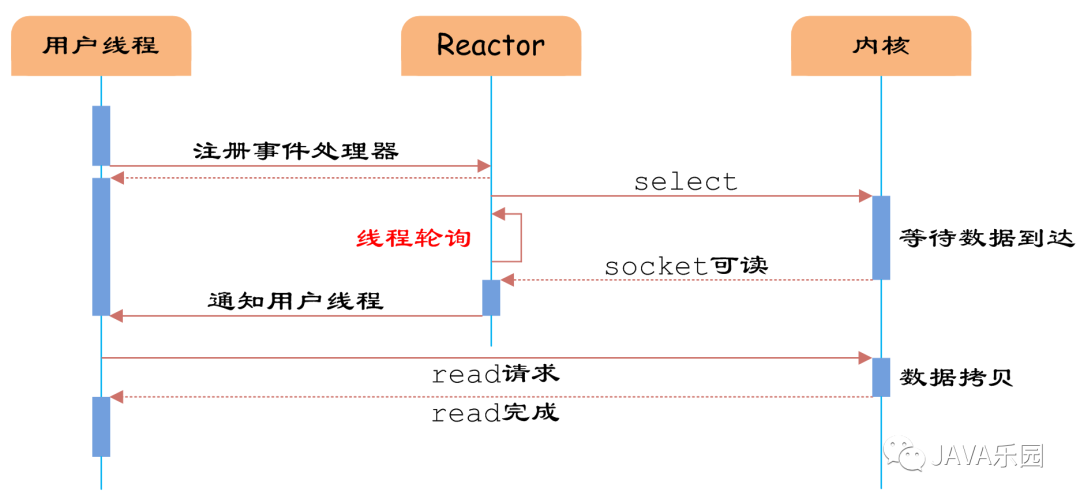
通过Reactor方式,用户线程轮询IO操作状态的工作统一交给handle_events事件循环处理。用户线程注册事件处理器之后可以继续执行做其他的工作(异步),而Reactor线程负责调用内核的select函数检查socket状态。当有socket被激活时,则通知相应的用户线程(或执行用户线程的回调函数),执行handel_envent进行数据的读取、处理工作。
由于select函数是阻塞的,因此多路IO复用模型就被称为异步阻塞IO模型,这里阻塞不是指socket。因为使用IO多路复用时,socket都设置NONBLOCK,不过不影响,因为用户发起IO请求时,数据已经到达了,用户线程一定不会被阻塞。
IO多路复用是最常用的IO模型,但其异步程度还不彻底,因为它使用了回阻塞线程的select系统调用。因此IO多路复用只能称为异步阻塞IO,而非真正的异步IO。
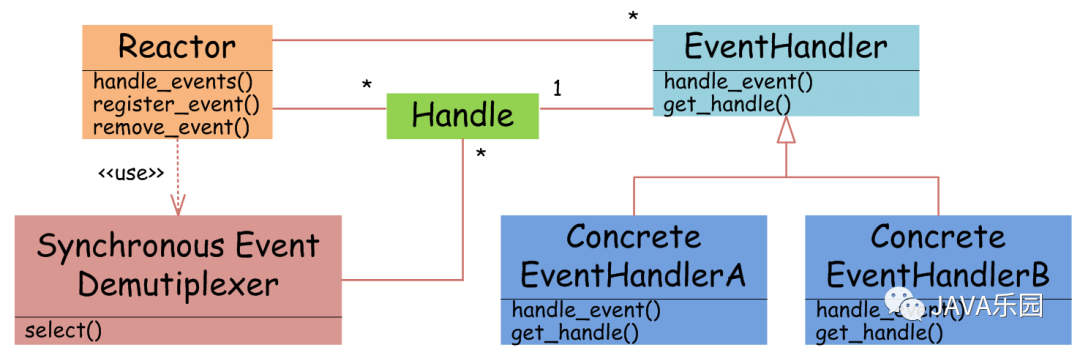
附:Reactor设计模式
异步非阻塞IO
在IO多路复用模型中,事件循环文件句柄的状态事件通知给用户线程,由用户线程自行读取数据、处理数据。而异步IO中,当用户线程收到通知时候,数据已经被内核读取完毕,并放在了用户线程指定的缓冲区内,内核在IO完成后通知用户线程直接使用就行了。因此这种模型需要操作系统更强的支持,把read操作从用户线程转移到了内核。
相比于IO多路复用模型,异步IO并不十分常用,不少高性能并发服务程序使用IO多路复用+多线程任务处理的架构基本可以满足需求。不过最主要原因还是操作系统对异步IO的支持并非特别完善,更多的采用IO多路复用模拟异步IO方式(IO事件触发时不直接通知用户线程,而是将数据读写完毕后放到用户指定的缓冲区)。
select、poll、epoll详解
select,poll,epoll都是IO多路复用的机制。I/O多路复用就是通过一种机制,一个进程可以监视多个描述符(socket),一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。虽说IO多路复用被称为异步阻塞IO,但select,poll,epoll本质上都是同步IO,因为它们都需要在续写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而真正意义上的异步IO无需自己负责进行读写。
select
int select(int n, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);
select函数监视的文件描述符有三类,readfds,writefds,exceptfds。调用后函数会阻塞,直到有描述符就绪(有数据读、写、或者有except),或者超时(timeout指定时间,如果立即返回设置null),函数返回。当select函数返回后,可以通过便利fdset,来找到就绪的描述符。
优点:良好的跨平台性。
缺点:单个进程能够监视的文件描述符的数量存在最大限制,在Linux上为1024,可以通过修改宏定义甚至重新编译内核的方式提升这一限制,但这样会造成效率的降低。
poll
int poll(struct poll *fds, unsigned int nfds, int timeout);
struct pollfd{
int fd;
short events;
short revents;
};与select使用三个位图来表示fdset,poll使用一个pollfd的指针实现。pollfd结构包含了要监视的event和发生的event,不在使用select参数传值的方式。同时pollfd并没有最大数量的限制(但数量过大性能也会下降)。和select一样,poll返回后,需要轮询pollfd来或许就绪的描述符。
epoll
epoll是select和poll的增强版本,相比于前两者,它更加的灵活,没有描述符的限制。epoll使用一个文件描述符管理多个描述符,将用户关系的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需要一次。
参考链接:
https://blog.csdn.net/sehanlingfeng/article/details/78920423
https://www.cnblogs.com/wlwl/p/10293057.html
https://www.cnblogs.com/natian-ws/p/10785649.html
https://segmentfault.com/a/1190000003063859
《架构修炼之道》《从零开始学架构》source:https://www.cnblogs.com/yrxing/p/14143644.html

扫码二维码
获取更多精彩
Java乐园
