
【大数据哔哔集】Spark面试题灵魂40问
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多惊喜












1.rdd的属性
2.算子分为哪几类(RDD支持哪几种类型的操作)
3.创建rdd的几种方式
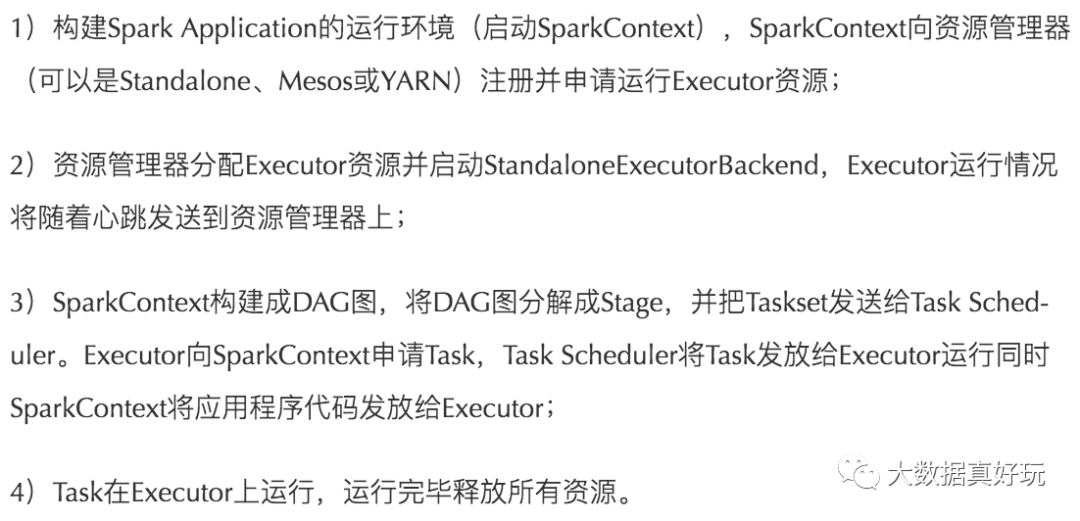
4.spark运行流程
5.Spark中coalesce与repartition的区别
6.sortBy 和 sortByKey的区别
7.map和mapPartitions的区别
8.数据存入Redis 优先使用map mapPartitions foreach foreachPartions哪个
9.reduceByKey和groupBykey的区别
10.cache和checkPoint的比较
11.spark streaming流式统计单词数量代码
12.简述map和flatMap的区别和应用场景
13.计算曝光数和点击数
14.分别列出几个常用的transformation和action算子
15.按照需求使用spark编写以下程序,要求使用scala语言
16.spark应用程序的执行命令是什么?
17.Spark应用执行有哪些模式,其中哪几种是集群模式
18.请说明spark中广播变量的用途
19.以下代码会报错吗?如果会怎么解决 val arr = new ArrayList[String]; arr.foreach(println)
20.写出你用过的spark中的算子,其中哪些会产生shuffle过程
21.Spark中rdd与partition的区别
22.请写出创建Dateset的几种方式
23.描述一下RDD,DataFrame,DataSet的区别?
24.描述一下Spark中stage是如何划分的?描述一下shuffle的概念
25.Spark 在yarn上运行需要做哪些关键的配置工作?如何kill -个Spark在yarn运行中Application
26.通常来说,Spark与MapReduce相比,Spark运行效率更高。请说明效率更高来源于Spark内置的哪些机制?请列举常见spark的运行模式?
27.RDD中的数据在哪?
28.如果对RDD进行cache操作后,数据在哪里?
29.Spark中Partition的数量由什么决定
30.Scala里面的函数和方法有什么区别
31.SparkStreaming怎么进行监控?
32.Spark判断Shuffle的依据?
33.Scala有没有多继承?可以实现多继承么?
34.Sparkstreaming和flink做实时处理的区别
35.Sparkcontext的作用
36.Sparkstreaming读取kafka数据为什么选择直连方式
37.离线分析什么时候用sparkcore和sparksql
38.Sparkstreaming实时的数据不丢失的问题
39.简述宽依赖和窄依赖概念,groupByKey,reduceByKey,map,filter,union五种操作哪些会导致宽依赖,哪些会导致窄依赖
40.数据倾斜可能会导致哪些问题,如何监控和排查,在设计之初,要考虑哪些来避免
41.有一千万条短信,有重复,以文本文件的形式保存,一行一条数据,请用五分钟时间,找出重复出现最多的前10条
42.现有一文件,格式如下,请用spark统计每个单词出现的次数
43.共享变量和累加器
44.当 Spark 涉及到数据库的操作时,如何减少 Spark 运行中的数据库连接数?
45.特别大的数据,怎么发送到excutor中?
46.spark调优都做过哪些方面?
47.spark任务为什么会被yarn kill掉?
48.Spark on Yarn作业执行流程?yarn-client和yarn-cluster有什么区别?
49.Flatmap底层编码实现?
50.spark_1.X与spark_2.X区别
51.说说spark与flink
52.spark streaming如何保证7*24小时运行机制?
53.spark streaming是Exactly-Once吗?

【大数据哔哔集20210118】Spark数据倾斜调优七大方案
【大数据哔哔集20210117】Hive大表关联小表到底该怎么做
【大数据哔哔集20210116】Spark Trouble Shooting
评论