本文来源:AI 云原生
/ 导读 /
今天,我们来了解一下谷歌的自动驾驶汽车Waymo是怎么做的。
Waymo在超过25个城市的公共道路上行驶了超过2000万英里。他们还在模拟环境中行驶了数百亿英里(文章后面会介绍)。此外,Waymo正在美国经营出租车服务,真正地在没有司机的情况下运送乘客。
由于Waymo的快速增长,下午将深入介绍Waymo的技术,以便您了解这个巨头背后的实际情况。
与其他自动驾驶汽车一样,Waymo通过4个主要步骤来实施:感知(perception)、定位(localization)、规划(planning)和控制(control)。
这篇文章中,不讨论控制相关的内容。对于Waymo来说,预测(这是规划的一部分)是另一个核心支柱,文中将单独介绍。
我们首先从感知开始。

感知
大多数机器人系统的核心组件是感知任务。在Waymo的案例中,感知包括对障碍物的估计和自动驾驶汽车的定位。
传感器和任务
Waymo的感知系统使用了摄像头、激光雷达和雷达的组合。由于Waymo的大部分工作都是使用4个LiDAR完成的,可以将其视为与特斯拉完全相反的系统。
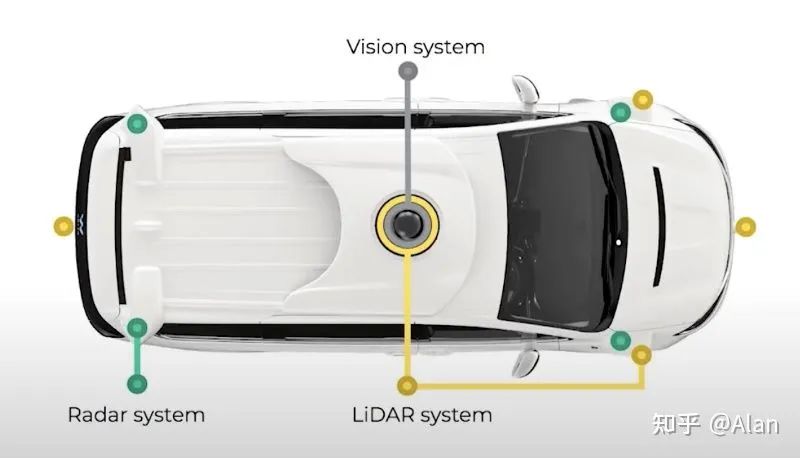
以下是Waymo自动驾驶复杂任务的视图——只是为了让您了解其计算机视觉系统需要感知的所有事物。
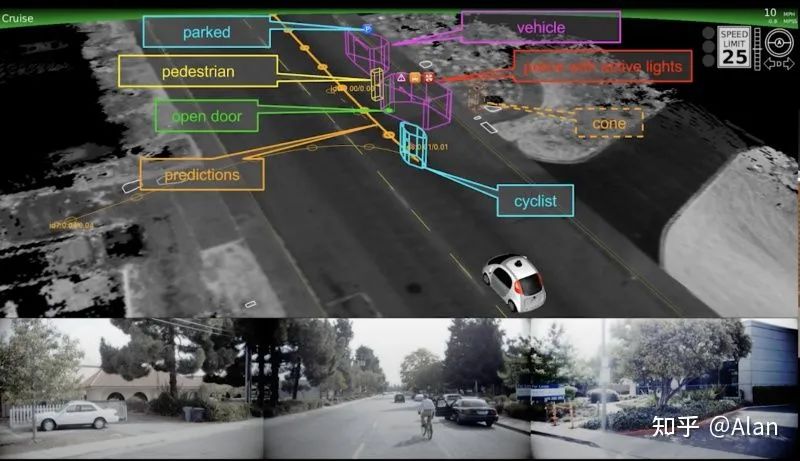
如您所见,对障碍物的信息水平要求非常高:
- 汽车被分类为常规汽车、警车、救护车、消防车和校车。
- 如果遇到特种车辆,系统可以观察警报器和灯光并根据此进行操作。
如您所见,感知系统会考虑“状态”并将其提供给预测系统。然而,这种感知系统很快就会遇到一些特别棘手的情况。下面是一个例子: 上面的反射问题远不是唯一的棘手问题。再如:人们可以伪装,躺在卡车车顶上,带着STOP标志走路 等。我们可能会想象出更多的边缘情况,我们应该了解系统可能遇到的问题。
上面的反射问题远不是唯一的棘手问题。再如:人们可以伪装,躺在卡车车顶上,带着STOP标志走路 等。我们可能会想象出更多的边缘情况,我们应该了解系统可能遇到的问题。
架构
最近在讨论Tesla计算机视觉架构时,我探索了HydraNet 架构。它是一种旨在同时运行多个神经网络的架构。“Hydra”这个词意味着一个有多个头的系统。Waymo没有谈论HydraNets,但有一些关于其视觉系统的事情。第一件可能会让你感到惊讶的事是,Waymo的架构并不是固定的,而是估计的。 这是类似于ResNet的大型神经网络中的构建块。这种想法已经在AutoML中采用了。AutoML的思想是神经网络架构必须由算法估计。
这是类似于ResNet的大型神经网络中的构建块。这种想法已经在AutoML中采用了。AutoML的思想是神经网络架构必须由算法估计。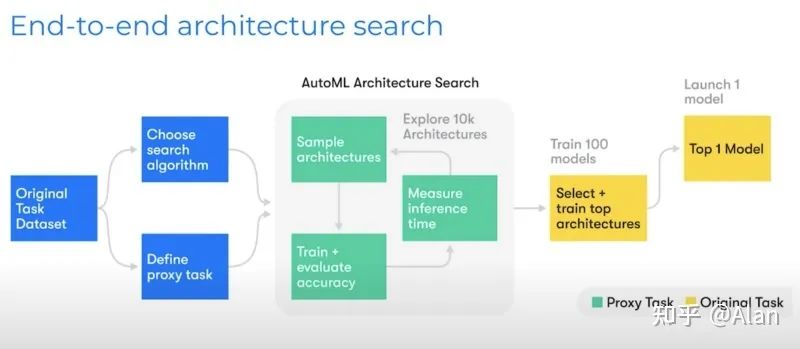 测试10,000个架构,预选100个模型,然后选出1个最终获胜者。获胜的标准是准确性和推理成本。
测试10,000个架构,预选100个模型,然后选出1个最终获胜者。获胜的标准是准确性和推理成本。数据集和模型
Waymo使用主动学习来训练模型,利用TPU(Tensor Processing Units)和谷歌的深度学习框架TensorFlow。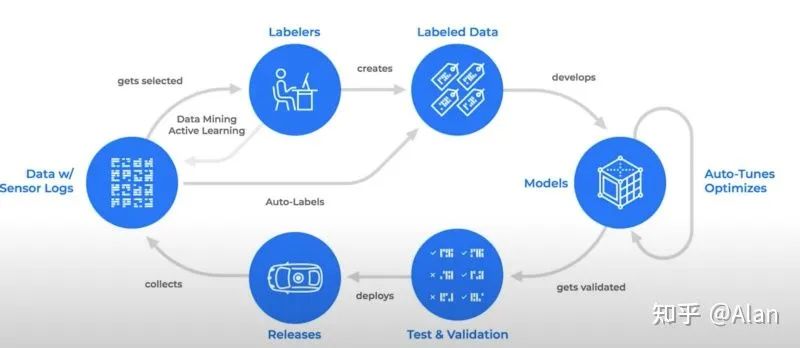 图中的描述已经比较清晰;从底部的“Releases”开始,然后向左移动。
图中的描述已经比较清晰;从底部的“Releases”开始,然后向左移动。- 然后标注过的数据集被发送到AutoML架构搜索,评估最佳模型。
这些用于感知的机器学习模型的目标是准确估计3D世界。
定位
定位意思是得到车辆在1-3厘米精度内的位置。一些公司使用了GPS,有些又添加了摄像头和激光雷达信息,但是……Waymo使用了地图、激光雷达和GPS来定位车辆。Google还利用了从Google地图获得的经验。多年来,谷歌地图团队一直致力于使用激光雷达、摄像头和GPS进行高精地图绘制。这些是用于自动驾驶汽车的精确传感器。虽然Waze和Google Maps都没有参与Waymo及其定位模块,但在地图上积累的经验非常有益。 谷歌几乎已经绘制了整个世界的地图。如果从相对位置检测到您看到了2号街道,就可以准确地知道您在哪里。这就是他们过去二十年一直在努力的事情。
谷歌几乎已经绘制了整个世界的地图。如果从相对位置检测到您看到了2号街道,就可以准确地知道您在哪里。这就是他们过去二十年一直在努力的事情。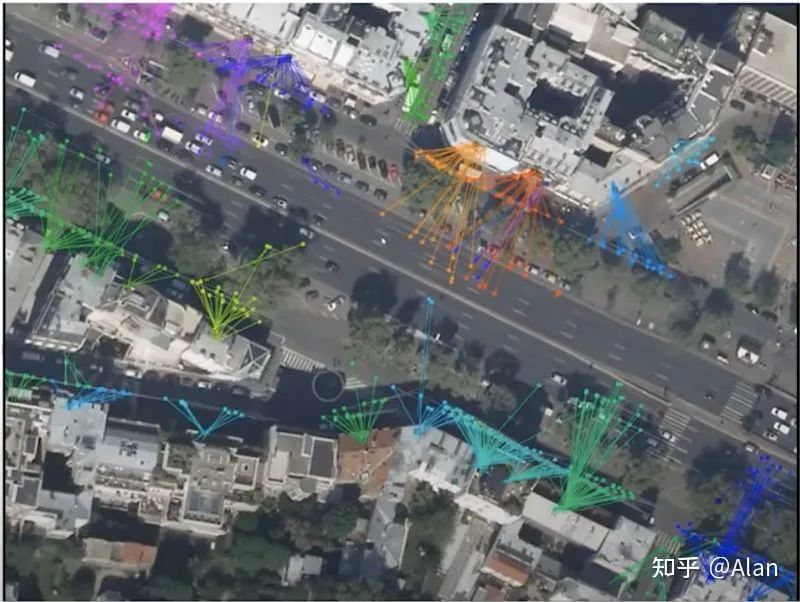 Waymo的定位模块由地图、摄像头、GPS和算法组成,可在全世界范围内准确定位车辆。Waymo还在其模块中使用了大量冗余,以使其更加健壮和可靠。
Waymo的定位模块由地图、摄像头、GPS和算法组成,可在全世界范围内准确定位车辆。Waymo还在其模块中使用了大量冗余,以使其更加健壮和可靠。
预测
行为预测
Waymo自动驾驶汽车最重要的特点是行为预测。谷歌无法像特斯拉那样利用车队的力量。特斯拉利用其客户数十万辆汽车收集数据。Waymo无法做到这一点;然而,他们拥有自己的车队,近年来可能会增长很多。在自动驾驶汽车中,最终想要的是了解人类行为并预测它们。这就是所谓的行为预测。这些行为预测是使用循环神经网络进行的:它们使用过去的信息来预测未来的行为。因此,可以确切地知道要做什么,并且可以衡量预测的置信度。- 如果车辆观察到有行人注视着它,则发生事故的风险很低。
Waymo的系统知道这一点。怎么做到的呢?在其模型中输入专家偏见。其预测系统是一个混合体:结合了机器学习和人类知识。人类知识还包括交通法规和不可能的事情(如:人类行走或者跑步的速度不可能达到50公里/小时)。仿真
Waymo驾驶了很多,但也模拟了很多。Waymo构建了一个模拟器,该模拟器将真实世界数据作为输入并输出新场景。以现实生活中发生的情况为例。现在,使用模拟器修改它。想象一下有一辆车超过了人类司机的情景,再想象一下没有超过人类司机。这类似于电影《Next》,其中尼古拉斯·凯奇 (Nicolas Cage) 有能力想象每一种可能的场景并选择他能幸存的场景。 Waymo可以实时前后回放,还可以模拟行为。可以构建完整的小说,并查看算法是如何表现的。模拟器可以发挥真正的力量。事实上,Waymo平均每天 24*7小时运行25,000辆虚拟汽车,并且在这些模拟中每天行驶10,000,000英里。
Waymo可以实时前后回放,还可以模拟行为。可以构建完整的小说,并查看算法是如何表现的。模拟器可以发挥真正的力量。事实上,Waymo平均每天 24*7小时运行25,000辆虚拟汽车,并且在这些模拟中每天行驶10,000,000英里。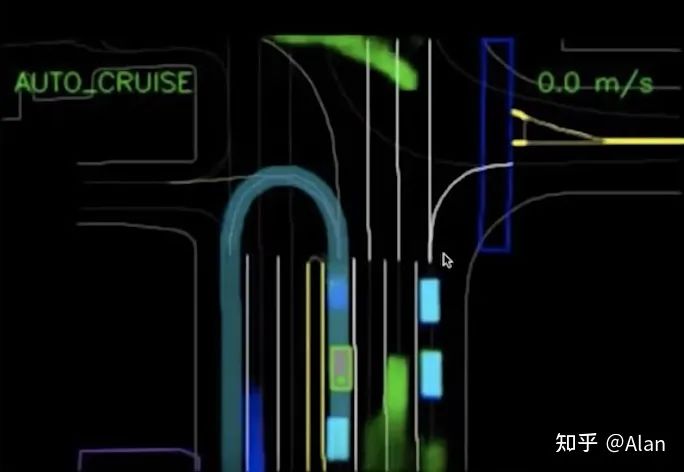 这不是Dominic Toretto和Brian O'Connor的告别。这两条线是对车辆可能做的事情的预测。对这辆车的信息掌握的越多,预测就越准确和自信。直到剩下一个……为了模拟更多场景,Waymo正在使用DeepMind和深度强化学习来创建代理和驾驶策略。在强化学习中,策略是一种行为。Waymo可以模拟一个愤怒的司机试图在某人面前危险地切入,或者一个粗心的踏板车司机。每次,他们都会查看算法的行为和正确性。当对驾驶员进行了准确且训练有素的预测,就可以生成要采取的轨迹。这也称为决策和轨迹生成。Waymo的驾驶模型称为ChauffeurNet。
这不是Dominic Toretto和Brian O'Connor的告别。这两条线是对车辆可能做的事情的预测。对这辆车的信息掌握的越多,预测就越准确和自信。直到剩下一个……为了模拟更多场景,Waymo正在使用DeepMind和深度强化学习来创建代理和驾驶策略。在强化学习中,策略是一种行为。Waymo可以模拟一个愤怒的司机试图在某人面前危险地切入,或者一个粗心的踏板车司机。每次,他们都会查看算法的行为和正确性。当对驾驶员进行了准确且训练有素的预测,就可以生成要采取的轨迹。这也称为决策和轨迹生成。Waymo的驾驶模型称为ChauffeurNet。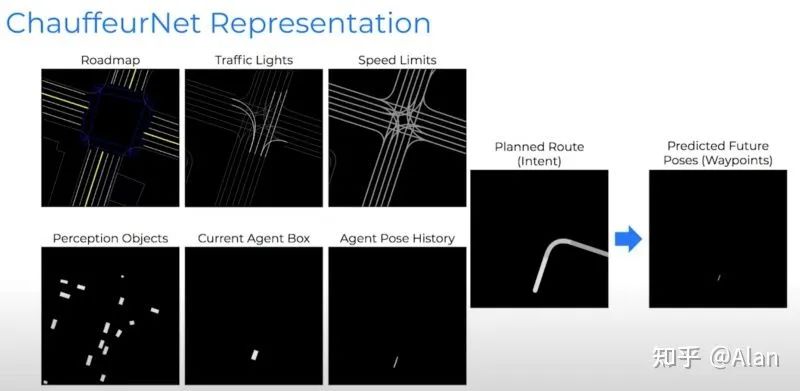 规划模块的目标是生成在安全性、速度和可行性方面误差最低的轨迹。
规划模块的目标是生成在安全性、速度和可行性方面误差最低的轨迹。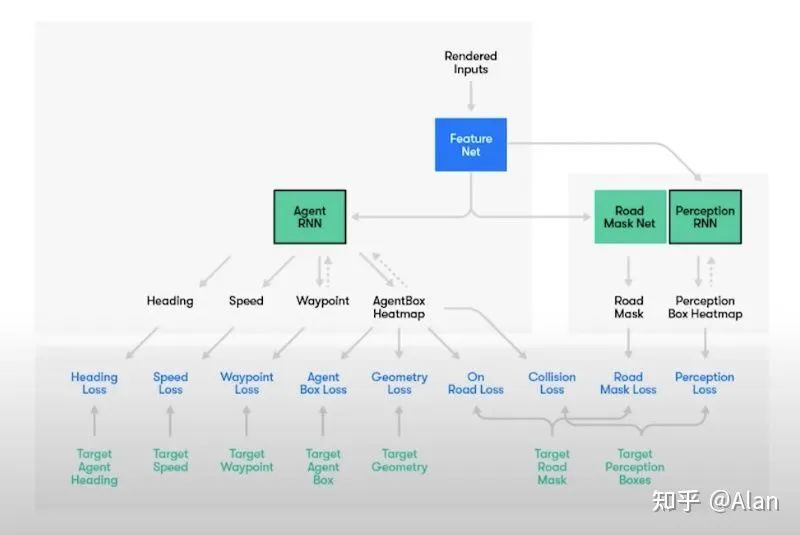 这可能看起来很复杂,但别担心,这就是我写这篇文章的原因!让我们从顶部开始,将“特征网络”视为感知、定位和预测的输出。
这可能看起来很复杂,但别担心,这就是我写这篇文章的原因!让我们从顶部开始,将“特征网络”视为感知、定位和预测的输出。在左侧,可以看到“Agent RNN”。这实际上是一个为自主车辆生成轨迹的网络。这些轨迹将考虑航向(可行性)、速度(交通规则)、航路点(长度)和代理(可行性、几何形状等)。Agent RNN 的目标是模拟一个可行的、现实的轨迹。
然后在右侧,可以看到 Road Mask Net。这是一个网络,如果它生成的轨迹不在路上,就会受到很高的惩罚。Waymo 通过这种方式确保我们不在人行道上开车。
最后,在最右侧,是 Perception RNN。这是一个惩罚与其他车辆的碰撞和互动的网络。例如,当我们距离车辆 1 米的损失会高于距离 1.5 米时的损失。
总之,网络生成了一条可行的轨迹,保持在路上,避免碰撞。最后,轨迹还考虑了排斥器和吸引器。我们想留在车道的中心,并且想避开路障并跟随中心。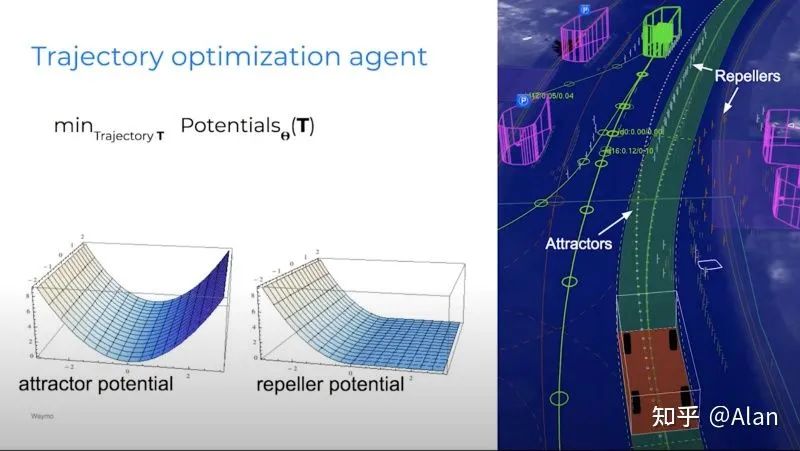 生成适当轨迹的过程还使用了一种称为逆强化学习的技术。在逆强化学习中,我们尝试着眼于真实的人类轨迹(真实值),并确定是什么使这条轨迹成为一个好的轨迹。这改进了生成的轨迹并使其更逼真。
生成适当轨迹的过程还使用了一种称为逆强化学习的技术。在逆强化学习中,我们尝试着眼于真实的人类轨迹(真实值),并确定是什么使这条轨迹成为一个好的轨迹。这改进了生成的轨迹并使其更逼真。总结
感知是检测障碍物、交通灯和道路的。Waymo 使用主动学习收集数据,使用 AutoML 生成架构并选择更高效的架构(准确性和推理时间)。
定位主要是找到您所在位置的感知任务。Waymo 利用谷歌地图的知识来做到这一点。
预测是在模拟器中使用循环神经网络和强化学习来训练他们的代理来很好地估计轨迹。
规划是根据可行性生成轨迹,保持在路上,避免碰撞。这些车辆还向人工标注员学习,以生成更逼真的轨迹。
Waymo的系统是在自动驾驶汽车上11年研究和实验的成果。在自动驾驶技术世界中,他们制造汽车的方式有一些阻碍,因为人们表达了对特斯拉系统的偏好,并意识到路上的经验非常宝贵。不管你的意见是什么,都不可否认谷歌和Waymo在他们的自动驾驶汽车方面投入了疯狂的工作和技术。Waymo还有很长的路要走。。。
Waymo的主要问题之一是其使用地图的方式:Waymo不能没有地图就开车。可以更精确地绘制整个世界,但对规模化来说这是一个巨大的挑战。Waymo的主要视觉系统由激光雷达组成,实际上这也是一个很大的问题,激光雷达在雪、雨或雾中完全失明。因此,Waymo经常在亚利桑那州的凤凰城或加利福尼亚州的旧金山等地方行驶,那里的条件永远干燥且阳光充足。最近,Waymo开始在非常潮湿的密歇根州、暴风雨的迈阿密和多雨的华盛顿州行驶。 如果你看看特斯拉,其已经在纽约市中心和巴黎开过自动驾驶汽车。由于特斯拉的司机们,其已经了解了这些地方。规模化可能要容易得多,毕竟依赖激光雷达可能是一个问题。Waymo是特斯拉在L5级自动驾驶竞赛中的直接竞争对手!
如果你看看特斯拉,其已经在纽约市中心和巴黎开过自动驾驶汽车。由于特斯拉的司机们,其已经了解了这些地方。规模化可能要容易得多,毕竟依赖激光雷达可能是一个问题。Waymo是特斯拉在L5级自动驾驶竞赛中的直接竞争对手!
本文仅做学术分享,如有侵权,请联系删文。

