
盘点8个数据分析相关的Python库(实例+代码)
导读:Python中常会用到一些专门的库,如NumPy、SciPy、Pandas和Matplotlib。数据处理常用到NumPy、SciPy和Pandas,数据分析常用到Pandas和Scikit-Learn,数据可视化常用到Matplotlib,而对大规模数据进行分布式挖掘时则可以使用Pyspark来调用Spark集群的资源。
从一定程度上来说,学习Python数据分析主要就是学习使用这些分析库。
作者:刘鹏 高中强 王一凡 等
来源:大数据DT(ID:hzdashuju)

01 NumPy
关于NumPy,本节主要介绍ndarray多维数组对象和数组属性。
1. ndarray 多维数组对象
NumPy库中的ndarray是一个多维数组对象,由两部分组成:实际的数据值和描述这些值的元数据。大部分的数组操作仅仅涉及修改元数据的部分,并不改变底层的实际数据。
数组中的所有元素类型必须是一致的,所以如果知道其中一个元素的类型,就很容易确定该数组需要的存储空间。可以用array()函数创建数组,并通过dtype获取其数据类型。
import numpy as np
a = np.array(6)
a.dtype
output: dtype('int64')上例中,数组a的数据类型为int64,如果使用的是32位Python,则得到的数据类型可能是int32。
2. 数组属性
NumPy数组有一个重要的属性——维度(dimension),它的维度被称作秩(rank)。以二维数组为例,一个二维数组相当于两个一维数组。只看最外面一层,它相当于一个一维数组,该一维数组中的每个元素也是一维数组。那么,这个一维数组即二维数组的轴。
了解了以上概念,接着来看NumPy数组中比较重要的ndarray对象的属性:
ndarray.ndim:秩,即轴的数量或维度的数量
ndarray.shape:数组的维度,如果存的是矩阵,如n×m矩阵则输出为n行m列
ndarray.size:数组元素的总个数,相当于.shape中n×m的值
ndarray.dtype:ndarray对象的元素类型
ndarray.itemsize:ndarray对象中每个元素的大小,以字节为单位
ndarray.flags:ndarray对象的内存信息
ndarray.real:ndarray元素的实部
ndarray.imag:ndarray元素的虚部
ndarray.data:包含实际数组元素的缓冲区,由于一般通过数组的索引获取元素,所以通常不需要使用这个属性
02 Matplotlib
Matplotlib是Python数据分析中常用的一个绘图库,常用来绘制各种数据的可视化效果图。其中,matplotlib.pyplot包含了简单的绘图功能。
1. 实战:绘制多项式函数
为了说明绘图的原理,下面来绘制多项式函数的图像。使用NumPy的多项式函数poly1d()来创建多项式。
# 引入所需要的库
import numpy as np
import matplotlib.pyplot as plt
# 使用 polyld() 函数创建多项式 func=1x3+2x2+3x+4
func = np.poly1d(np.array([1,2,3,4]).astype(f?loat))
# 使用 NumPy 的 linspace() 函数在 -10 和 10 之间产生 30 个均匀分布的值,作为函数 x 轴的取值
x = np.linspace(-10, 10 , 30)
# 将 x 的值代入 func() 函数,计算得到 y 值
y=func(x)
# 调用 pyplot 的 plot 函数 (),绘制函数图像
plt.plot(x, y)
# 使用 xlable() 函数添加 x 轴标签
plt.xlabel('x')
# 使用 ylabel() 函数添加 y 轴标签
plt.ylabel('y(x)')
# 调用 show() 函数显示函数图像
plt.show()多项式函数的绘制结果如图2-13所示。
▲图2-13 多项式函数绘制
2. 实战:绘制正弦和余弦值
为了明显看到两个效果图的区别,可以将两个效果图放到一张图中显示。Matplotlib中的subplot()函数允许在一张图中显示多张子图。subplot()常用的3个整型参数分别为子图的行数、子图的列数以及子图的索引。
下面的实例将绘制正弦和余弦两个函数的图像。
# 导入相关包
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.pyplot import f?igure
f?igure(num=None, f?igsize=(12, 8), dpi=80, facecolor='w', edgecolor='k')
# 计算正弦和余弦曲线上点的 x 和 y 坐标
x = np.arange(0, 3 * np.pi, 0.1)
y_sin = np.sin(x)
y_cos = np.cos(x)
# subplot的3个参数,2、1、1 ,表示绘制2行1列图像中的第一个子图
plt.subplot(2, 1, 1)# 绘制第一个子图
# 绘制第一个图像
plt.plot(x, y_sin)
plt.title('Sin')
plt.subplot(2, 1, 2)# 绘制2行1 列图像中的第二个子图
plt.plot(x, y_cos)
plt.title('Cos')
plt.show()# 显示图像正弦和余弦函数的绘制结果如图2-14所示。
▲图2-14 正弦和余弦函数绘制
03 PySpark
在大数据应用场景中,当我们面对海量的数据和复杂模型巨大的计算需求时,单机的环境已经难以承载,需要用到分布式计算环境来完成机器学习任务。
Apache Spark是一个快速而强大的框架,可以对弹性数据集执行大规模分布式处理。通过图2-15所示的Apache Spark架构图可以非常清晰地看到它的组成。
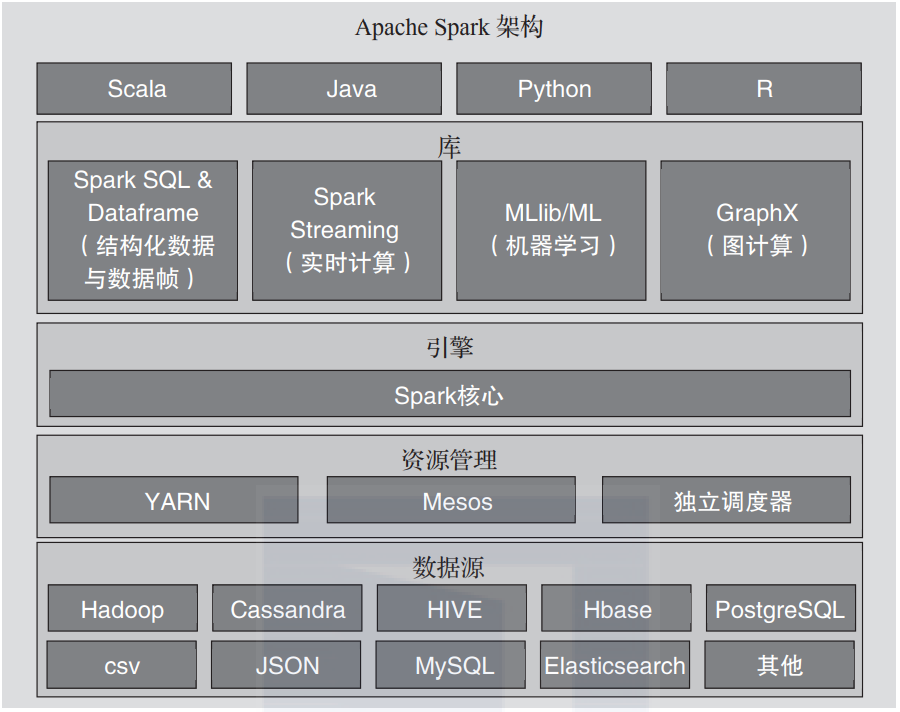
▲图2-15 Apache Spark架构图
Spark支持丰富的数据源,可以契合绝大部分大数据应用场景,同时,通过Spark核心对计算资源统一调度,由于计算的数据都在内存中存储,使得计算效率大大提高。Spark原生支持的语言是Scala,但为了丰富应用场景和满足各研发人员的语言偏好,Spark同时支持Java、Python与R。
PySpark是Spark社区发布的在Spark框架中支持Python的工具包,它的计算速度和能力与Scala相似。通过PySpark调用Spark的API,配合MLlib与ML库,可以轻松进行分布式数据挖掘。
MLlib库是Spark传统的机器学习库,目前支持4种常见的机器学习问题:分类、回归、聚类和协同过滤。MLlib的所有算法皆基于Spark特有的RDD(Resilient Distributed Dataset,弹性分布式数据集)数据结构进行运算。由于RDD并不能很好地满足更为复杂的建模需求,ML库应运而生。
ML库相较MLlib库更新,它全面采用基于数据帧(Data Frame)的API进行操作,能够提供更为全面的机器学习算法,且支持静态类型分析,可以在编程过程中及时发现错误,而不需要等代码运行。

Python中除了包含上面介绍的库,还有其他一些常用库。下面分别进行介绍。
04 SciPy
SciPy是一个开源算法库和数学工具包,它基于NumPy构建,并扩展了NumPy的功能。SciPy包含线性代数、积分、插值、特殊函数、快速傅里叶变换等常用函数,功能与软件MATLAB、Scilab和GNU Octave类似。Scipy常常结合Numpy使用,可以说Python的大多数机器学习库都依赖于这两个模块。
05 Pandas
Pandas提供了强大的数据读写功能、高级的数据结构和各种分析工具。该库的一大特点是能用一两个命令完成复杂的数据操作。
Pandas中最基础的数据结构是Series,用于表示一行数据,可以理解为一维的数组。另一个关键的数据结构为DataFrame,用于表示二维数组,作用和R语言里的data.frame很像。
Pandas内置了很多函数,用于分组、过滤和组合数据,这些函数的执行速度都很快。Pandas对于时间序列数据有一套独特的分析机制,可对时间数据做灵活的分析与管理。
06 Scikit-Learn
Scikit-Learn是一个基于NumPy、SciPy、Matplotlib的开源机器学习工具包,功能强大,使用简单,是Kaggle选手经常使用的学习库。它主要涵盖分类、回归和聚类算法,例如SVM、逻辑回归、朴素贝叶斯、随机森林、K均值以及数据降维处理算法等,官方文档齐全,更新及时。
Scikit-Learn基于Numpy和SciPy等Python数值计算库,提供了高效的算法实现,并针对所有算法提供了一致的接口调用规则,包括KNN、K均值、PCA等,接口易用。
07 TensorFlow
TensorFlow是谷歌开源的数值计算框架,也是目前最为流行的神经网络分析系统。它采用数据流图的方式,可灵活搭建多种机器学习和深度学习模型。
08 Keras
Keras是一个用于处理神经网络的高级库,可以运行在TensorFlow和Theano上,现在发布的新版本可以使用CNTK或MxNet作为后端。Keras简化了很多特定任务,并大大减少了样板代码数,目前主要用于深度学习领域。
关于作者:刘鹏,教授,清华大学博士,云计算、大数据和人工智能领域的知名专家,南京云创大数据科技股份有限公司总裁、中国大数据应用联盟人工智能专家委员会主任。中国电子学会云计算专家委员会云存储组组长、工业和信息化部云计算研究中心专家。
高中强,人工智能与大数据领域技术专家,有非常深厚的积累,擅长机器学习和自然语言处理,尤其是深度学习,熟悉Tensorflow、PyTorch等深度学习开发框架。曾获“2019年全国大学生数学建模优秀命题人奖”。参与钟南山院士指导新型冠状病毒人工智能预测系统研发项目,与钟南山院士团队共同发表学术论文。
本文摘编自《Python金融数据挖掘与分析实战》,经出版方授权发布。(ISBN:9787111696506)

《Python金融数据挖掘与分析实战》
点击上图了解及购买
转载请联系微信:DoctorData
推荐语:云创大数据(上市公司)总裁撰写,零基础学会金融数据挖掘,配有案例、视频、代码、数据、习题及答案。

划重点👇
干货直达👇
更多精彩👇
在公众号对话框输入以下关键词
查看更多优质内容!
读书 | 书单 | 干货 | 讲明白 | 神操作 | 手把手
大数据 | 云计算 | 数据库 | Python | 爬虫 | 可视化
AI | 人工智能 | 机器学习 | 深度学习 | NLP
5G | 中台 | 用户画像 | 数学 | 算法 | 数字孪生
据统计,99%的大咖都关注了这个公众号
👇
评论