
CVPR 2022:字节跳动多项竞赛夺冠,发力无障碍技术创新

新智元报道
新智元报道
【新智元导读】在今年的CVPR上,字节跳动斩获了多项竞赛冠军。
帮助视障人士精准「识图」,视觉问答竞赛高精度技术方案夺冠


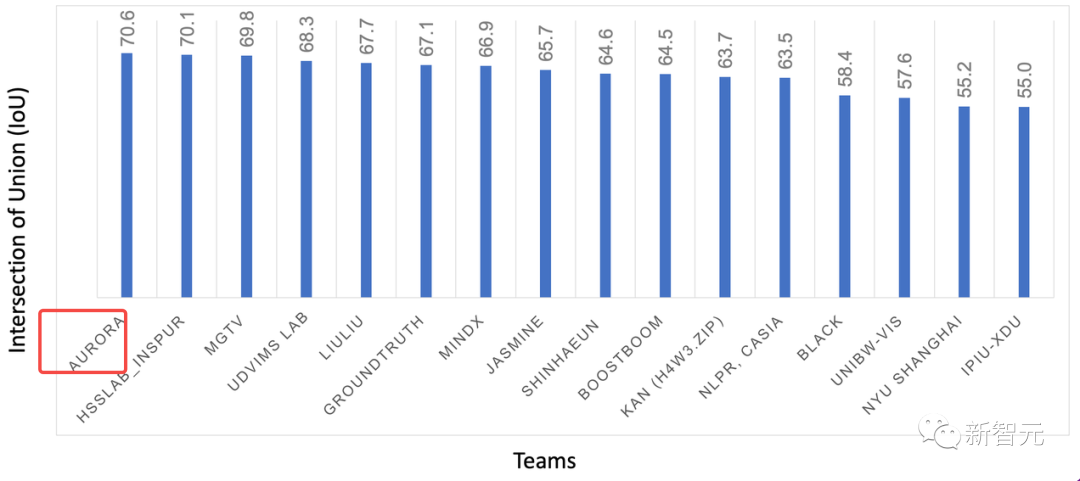
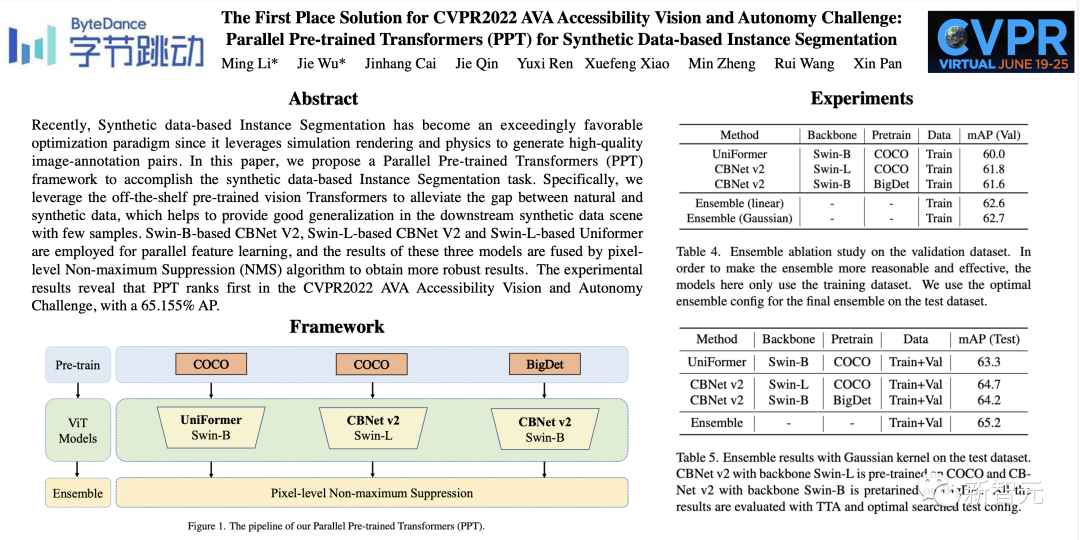
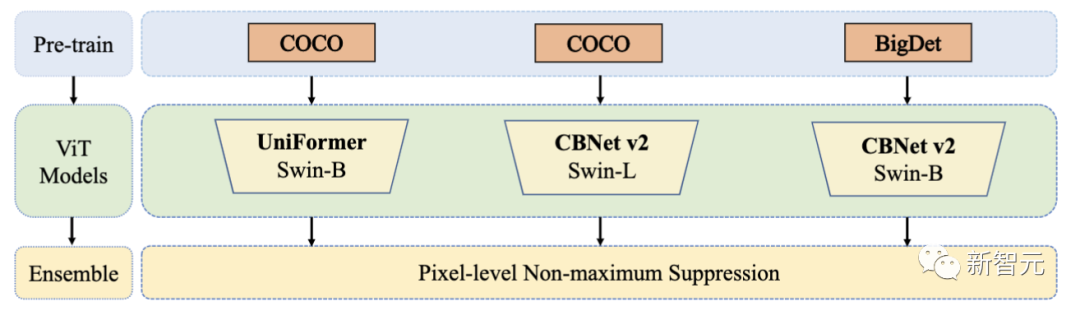
无障碍出行更安全!AVA比赛夺冠

模拟人脑感知,长视频理解挑战双料冠军
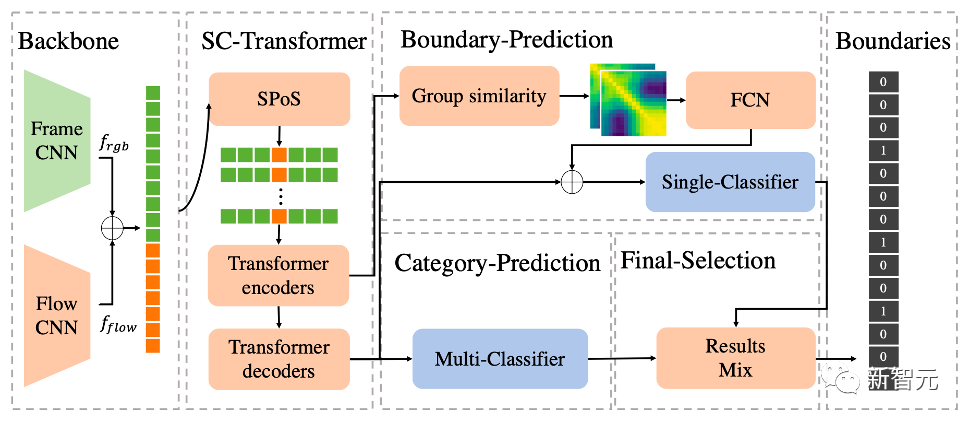
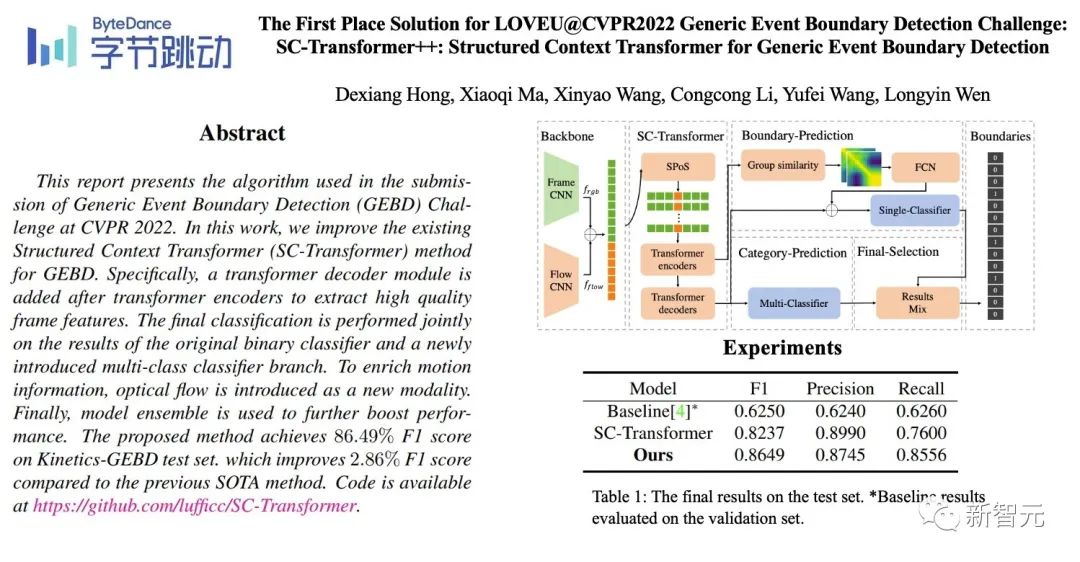
通用事件边界检测(Generic Event Boundary Detection,GEBD)赛道

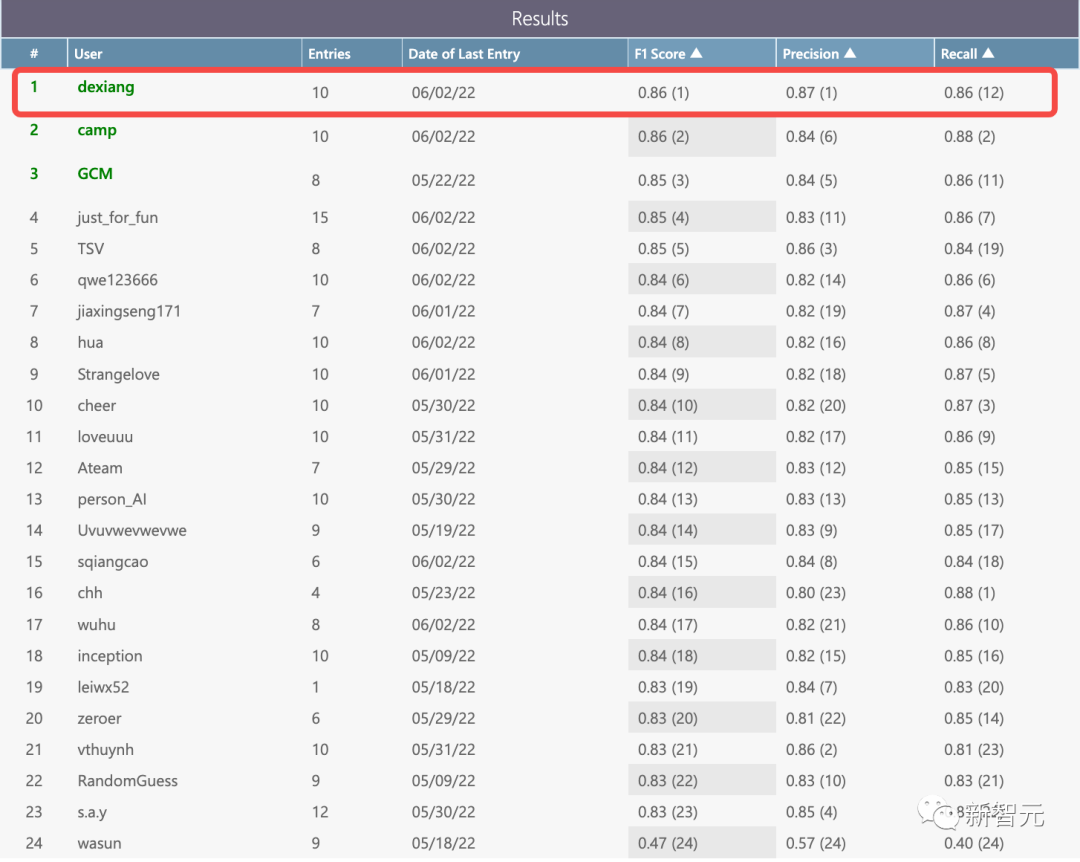
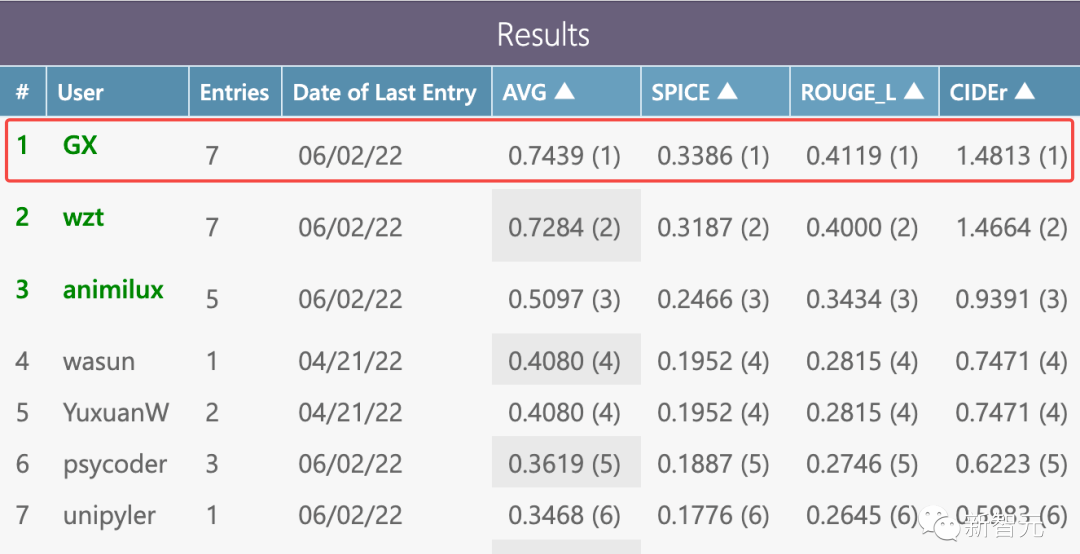
通用事件边界描述赛道(Generic Event Boundary Captioning Challenge,GEBC)

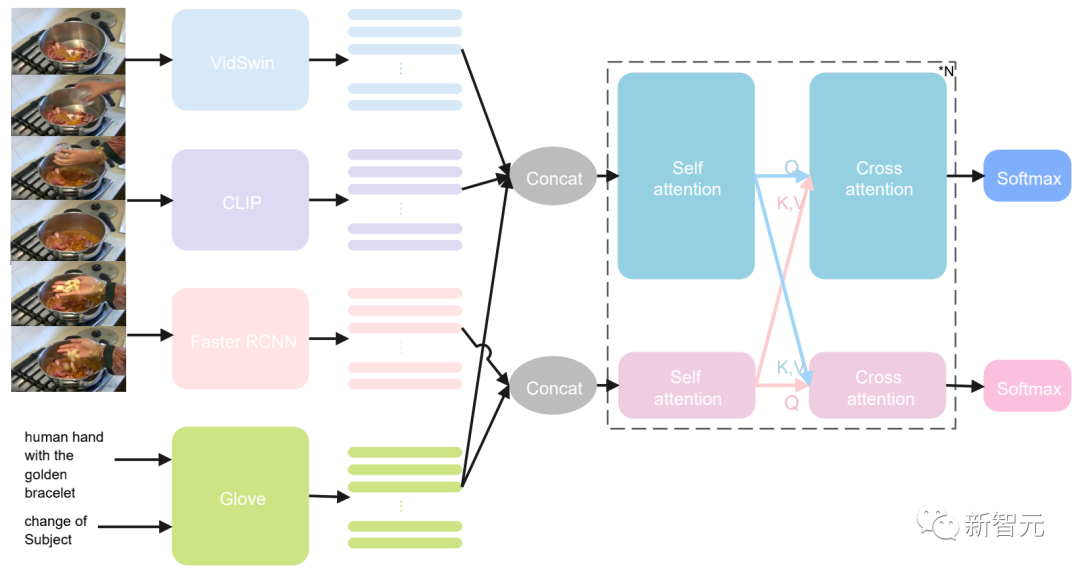
多模态特征提取模块
多模态特征融合编码模块

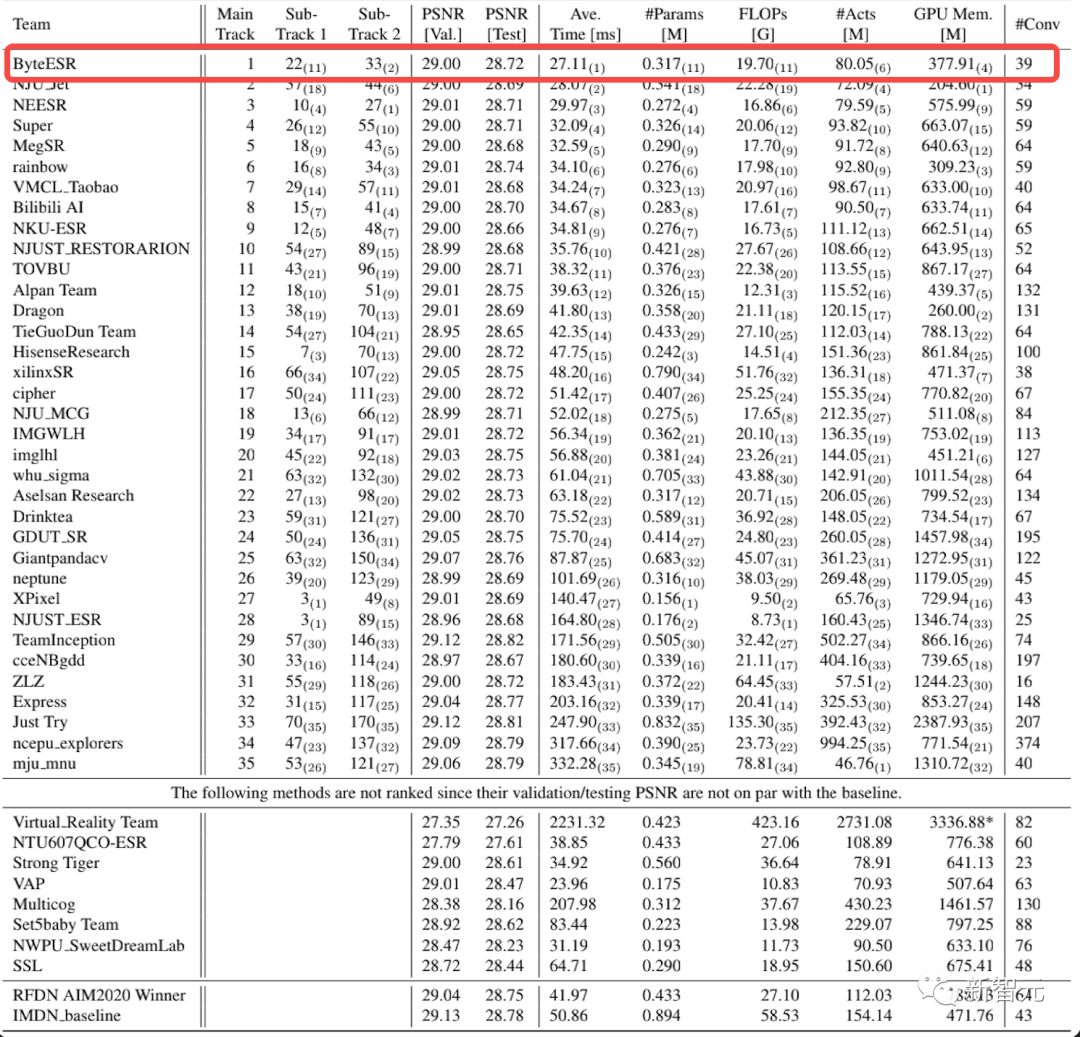
图片恢复技术哪家强,NTIRE ESR挑战赛主赛道夺冠

基于深度学习的图像压缩大赛 :高、低码率双赛道夺冠
(Challenge on Learned Image Compression ,CLIC)


评论