
没错!cxuan 对汇编下手了
汇编代码是计算机的一种低级表示,它是一种低级语言,可以从字面角度去理解它,包括处理数据、管理内存、读写存储设备上的数据,以及利用网络通信等。编译器生成机器码经过了一系列的转换,这些转换遵循编程语言、目标机器的指令集 和操作系统。
指令集
指令集就是指挥计算机工作的指令,因为程序就是按照一定执行顺序排列的指令。因为计算机的执行控制权由 CPU 操作,所以指令集就是 CPU 中用来计算和控制计算机的一系列指令的集合。每个 CPU 在产出时都规定了与硬件电路相互配合工作的指令集。
指令集有不少分类,但是一般分为两种,一种是精简指令集,一种是复杂指令集。具体描述如下
精简指令集
精简指令的英文是 reduced instruction set computer, RISC,原意是精简指令集计算,简称为精简指令集,是 CPU 的一种 设计模式,可以把 CPU 想象成一家流水线工厂,对指令数目和寻址方式都做了精简,使其实现更容易,指令并行执行程度更好,编译器的效率更高。
常见的精简指令集处理器包括 ARM、AVR、MIPS、PARISC、RISC-V 和 SPARC。
所以你就能理解

这本书是讲啥的了。
它主要是基于 MIPS 体系结构把冯诺依曼体系的五大组件进行了逐一的硬件实现 + 软件设计介绍,更为重要的是引入了诸多并行计算的内容,这是大部分教材中忽略或者内容较少的,会根据这个思路把并行相关的内容,结合 OpenMP, CUDA 和 Hadoop/Spark 整体融入到新书中,毕竟这是未来发展的趋势
还有这本书

这本书又是讲啥的。
这本书是讲 RISC-V 指令集的,因为指令集的不同也区分了三个版本,三个版本???嗯,还有下面这个

这本书是讲 ARM 指令集的。
所以一般在看 CASPP 的时候并发的看看这本书是非常不错的选择。
精简指令集一般具有如下特征
统一的指令编码 通用的寄存器,一般会区分整数和浮点数 简单的寻址模式,复杂寻址模式被简单指令序列来取代 支持很少偏门的类型,例如 RISC 支持字节字符串类型。
复杂指令集
复杂指令集的英文是 Complex Instruction Set Computing, CISC,是一种微处理器指令集架构,也被译为复杂指令集。
复杂指令集包括 System/360、VAX、x86 等。
复杂指令集可以说是在精简指令集之上作出的改变。
复杂指令集的特点是指令数目多而复杂,每条指令字长并不相等,计算机必须加以判读,并为此付出了性能的代价。
一般来说,提升 CPU 性能的方法有如下这几种
增加寄存器的大小 增进内部的并行性 增加高速缓存的大小 增加核心时脉的速度 加入其他功能,例如 IO 和计时器 加入向量处理器 硬件多线程技术
比较抽象,我们后面会组织成文章具体介绍一下。
C 编译器会接收其他操作并把其转换为汇编语言输出,汇编语言是机器级别的代码表示。我们之前介绍过,C 语言程序的执行过程分为下面这几步
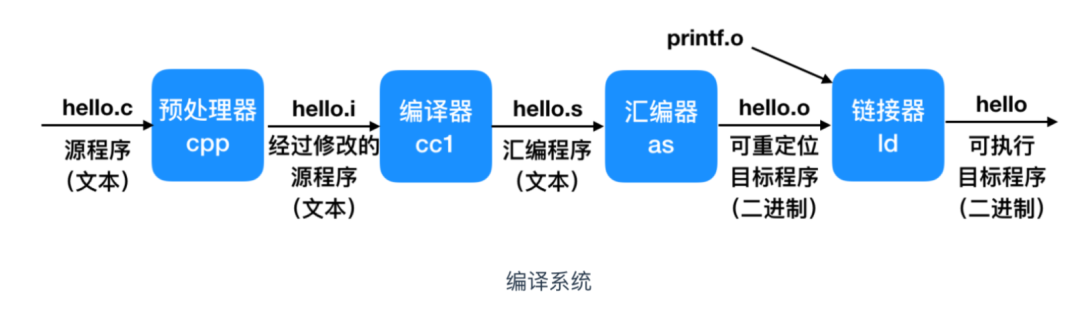
下面我们更多的讨论都是基于汇编代码来讨论。
我们日常所接触的高级语言,都是经过了层层封装的结果,所以我们平常是接触不到汇编语言的,更不会用汇编语言来进行编程,这就和你不知道操作系统的存在一样,但其实你每个操作,甚至你双击一个图标都和操作系统有关系。
高级语言的抽象级别很高,但是经过了层层抽象之后,高级语言的执行效率肯定没有汇编语言高,也没有汇编语言可靠。
但是高级语言有更大的优点是其编译后能够在不同的机器上运行,汇编语言针对不同的指令集有不同的表示。并且高级语言学习来更加通俗易懂,降低计算机门槛,让内卷更加严重(当然这是开个玩笑,冒犯到请别当真)。
话不多说,了解底层必须了解汇编语言。否则一个 synchronized 底层实现就能够让你头疼不已。而且,天天飘着也不好,迟早要落地。
了解汇编代码也有助于我们优化程序代码,分析代码中隐含的低效率,并且这种优化方法一旦优化成功,将是量级的提高,而不是改改 if...else ,使用一个新特性所能比的。
机器级代码
计算机系统使用了多种不同形式的抽象,可以通过一个简单的抽象模型来隐藏实现细节。对于机器级别的程序来说,有两点非常重要。
首先第一点,定义机器级别程序的格式和行为被称为 指令集体系结构或指令集架构(instruction set architecture), ISA。ISA 定义了进程状态、指令的格式和每一个指令对状态的影响。大部分的指令集架构包括 ISA 用来描述进程的行为就好像是顺序执行的,一条指令执行结束后,另外一条指令再开始。处理器硬件的描述要更复杂,它可以同时并行执行许多指令,但是它采用了安全措施来确保整体行为与 ISA 规定的顺序一致。
第二点,机器级别对内存地址的描述就是 虚拟地址(virtual address),它提供了一个内存模型来表示一个巨大的字节数组。
编译器在整个编译的过程中起到了至关重要的作用,把 C 语言转换为处理器执行的基本指令。汇编代码非常接近于机器代码,只不过与二进制机器代码相比,汇编代码的可读性更强,所以理解汇编是理解机器工作的第一步。
一些进程状态对机器可见,但是 C 语言程序员却看不到这些,包括
程序计数器(Program counter),它存储下一条指令的地址,在 x86-64 架构中用%rip来表示。
程序执行时,PC 的初始值为程序第一条指令的地址,在顺序执行程序时, CPU 首先按程序计数器所指出的指令地址从内存中取出一条指令,然后分析和执行该指令,同时将 PC 的值加 1 并指向下一条要执行的指令。
比如下面一个例子。
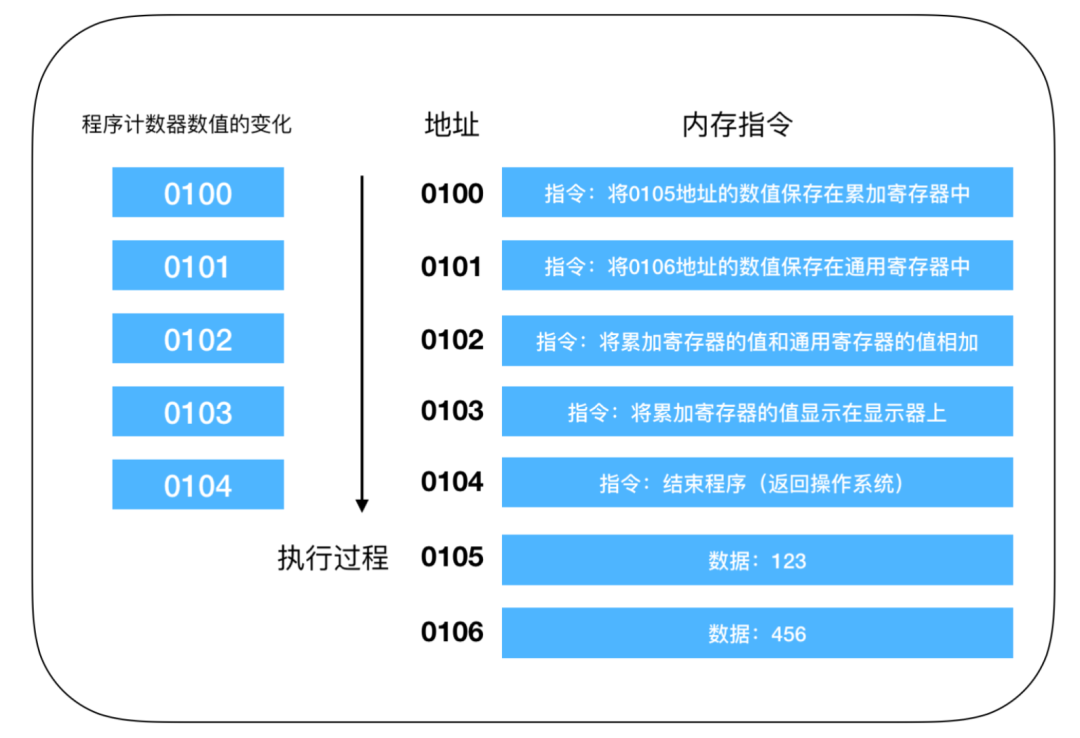
这是一段数值进行相加的操作,程序启动,在经过编译解析后会由操作系统把硬盘中的程序复制到内存中,示例中的程序是将 123 和 456 执行相加操作,并将结果输出到显示器上。由于使用机器语言难以描述,所以这是经过翻译后的结果,实际上每个指令和数据都可能分布在不同的地址上,但为了方便说明,把组成一条指令的内存和数据放在了一个内存地址上。
整数 寄存器文件(register file)包含 16 个命名的位置,用来存储 64 位的值。这些寄存器可以存储地址和整型数据。有些寄存器用于跟踪程序状态,而另一些寄存器用于保存临时数据,例如过程的参数和局部变量,以及函数要返回的值。这个文件是和磁盘文件无关的,它只是 CPU 内部的一块高速存储单元。有专用的寄存器,也有通用的寄存器用来存储操作数。条件码寄存器用来保存有关最近执行的算术或逻辑指令的状态信息。这些用于实现控件或数据流中的条件更改,例如实现 if 和 while 语句所需的条件更改。我们都学过高级语言,高级语言中的条件控制流程主要分为三种:顺序执行、条件分支、循环判断三种,顺序执行是按照地址的内容顺序的执行指令。条件分支是根据条件执行任意地址的指令。循环是重复执行同一地址的指令。顺序执行的情况比较简单,每执行一条指令程序计数器的值就是 + 1。 条件和循环分支会使程序计数器的值指向任意的地址,这样一来,程序便可以返回到上一个地址来重复执行同一个指令,或者跳转到任意指令。
下面以条件分支为例来说明程序的执行过程(循环也很相似)
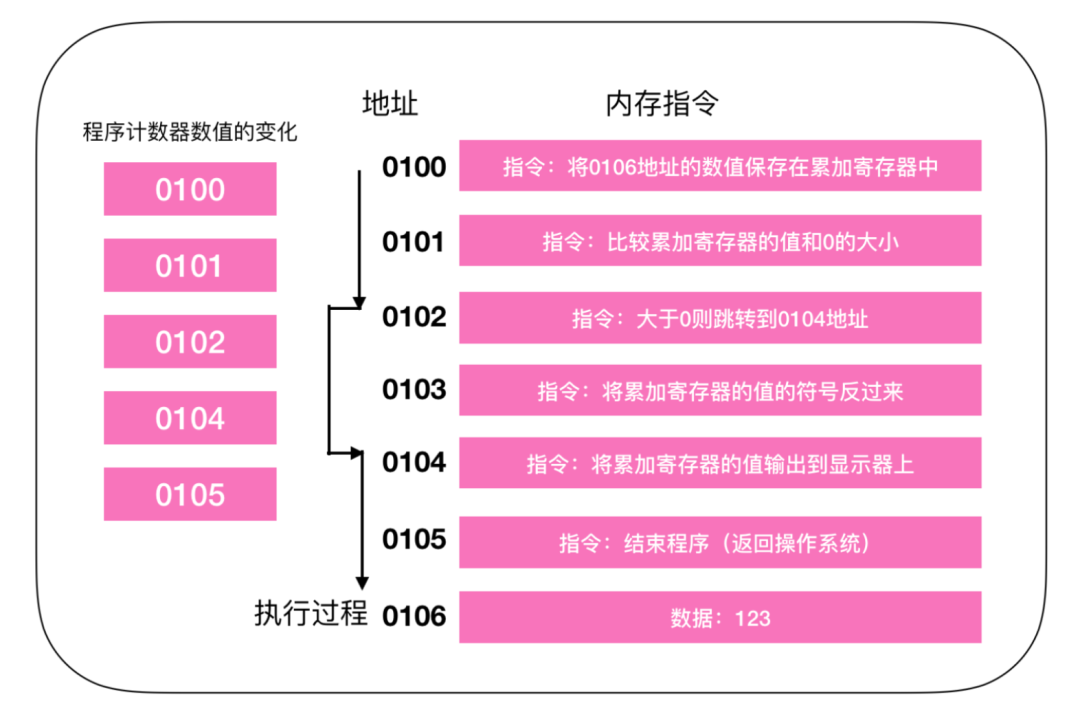
程序的开始过程和顺序流程是一样的,CPU 从 0100 处开始执行命令,在 0100 和 0101 都是顺序执行,PC 的值顺序+1,执行到 0102 地址的指令时,判断 0106 寄存器的数值大于 0,跳转(jump)到 0104 地址的指令,将数值输出到显示器中,然后结束程序,0103 的指令被跳过了,这就和我们程序中的 if() 判断是一样的,在不满足条件的情况下,指令会直接跳过。所以 PC 的执行过程也就没有直接+1,而是下一条指令的地址。
一组 向量寄存器用来存储一个或者多个整数或者浮点数值,向量寄存器是对一维数据上进行操作。
机器指令只会执行非常简单的操作,例如将存放在寄存器的两个数进行相加,把数据从内存转移到寄存器中或者是条件分支转移到新的指令地址。编译器必须生成此类指令的序列,以实现程序构造,例如算术表达式求值,循环或过程调用和返回
认识汇编
我相信各位应该都知道汇编语言的出现背景吧,那就是二进制表示数据,太复杂太庞大了,为了解决这个问题,出现了汇编语言,汇编语言和机器指令的区别就在于表示方法上,汇编使用操作数来表示,机器指令使用二进制来表示,我之前多次提到机器码就是汇编,你也不能说我错,但是不准确。
但是汇编适合二进制代码存在转换关系的。
汇编代码需要经过 汇编器 编译后才产生二进制代码,这个二进制代码就是目标代码,然后由链接器将其连接起来运行。
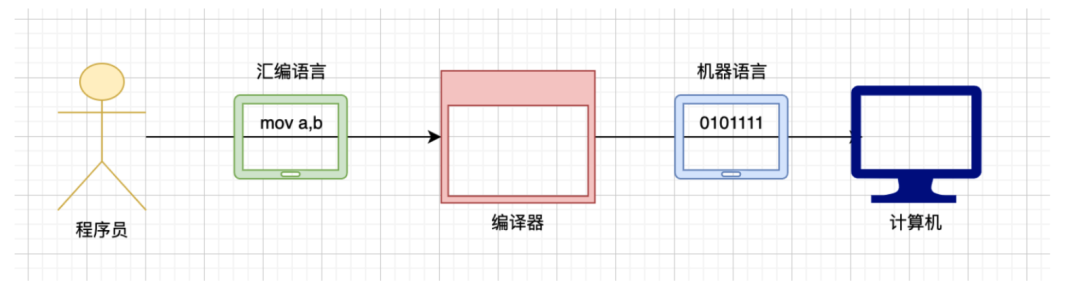
汇编语言主要分为以下三类
汇编指令:它是一种机器码的 助记符,它有对应的机器码伪指令:没有对应的机器码,由编译器执行,计算机并不执行 其他符号,比如 +、-、*、/ 等,由编译器识别,没有对应的机器码
汇编语言的核心是汇编指令,而我们对汇编的探讨也是基于汇编指令展开的。
与汇编有关的硬件和概念
CPU
CPU 是计算机的大脑,它也是整个计算机的核心,它也是执行汇编语言的硬件,CPU 的内部包含有寄存器,而寄存器是用于存储指令和数据的,汇编语言的本质也就是 CPU 内部操作数所执行的一系列计算。
内存
没有内存,计算机就像是一个没有记忆的人类,只会永无休止的重复性劳动。CPU 所需的指令和数据都由内存来提供,CPU 指令经由内存提供,经过一系列计算后再输出到内存。
磁盘
磁盘也是一种存储设备,它和内存的最大区别在于永久存储,程序需要在内存装载后才能运行,而提供给内存的程序都是由磁盘存储的。
总线
一般来说,内存内部会划分多个存储单元,存储单元用来存储指令和数据,就像是房子一样,存储单元就是房子的门牌号。而 CPU 与内存之间的交互是通过地址总线来进行的,总线从逻辑上分为三种
地址线 数据线 控制线
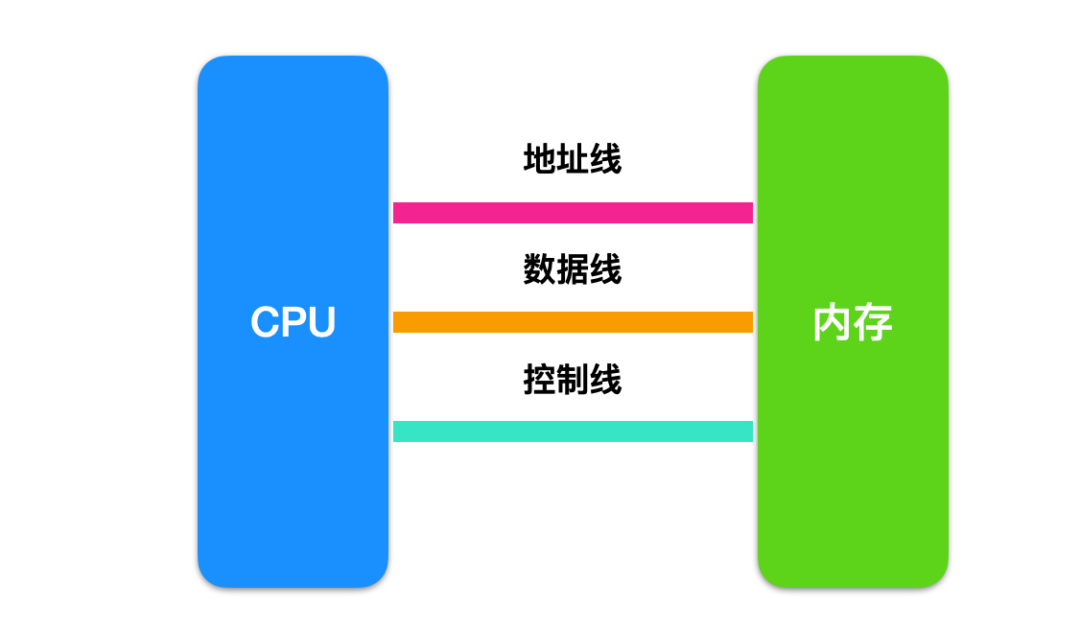
CPU 与存储器之间的读写主要经过以下几步
读操作步骤
CPU 通过地址线发出需要读取指令的位置 CPU 通过控制线发出读指令 内存把数据放在数据线上返回给 CPU
写操作步骤
CPU 通过地址线发出需要写出指令的位置 CPU 通过控制线发出写指令 CPU 把数据通过数据线写入内存
下面我们就来具体了解一下这三类总线
地址总线
通过我们上面的探讨,我们知道 CPU 通过地址总线来指定存储位置的,地址总线上能传送多少不同的信息,CPU 就可以对多少个存储单元进行寻址。
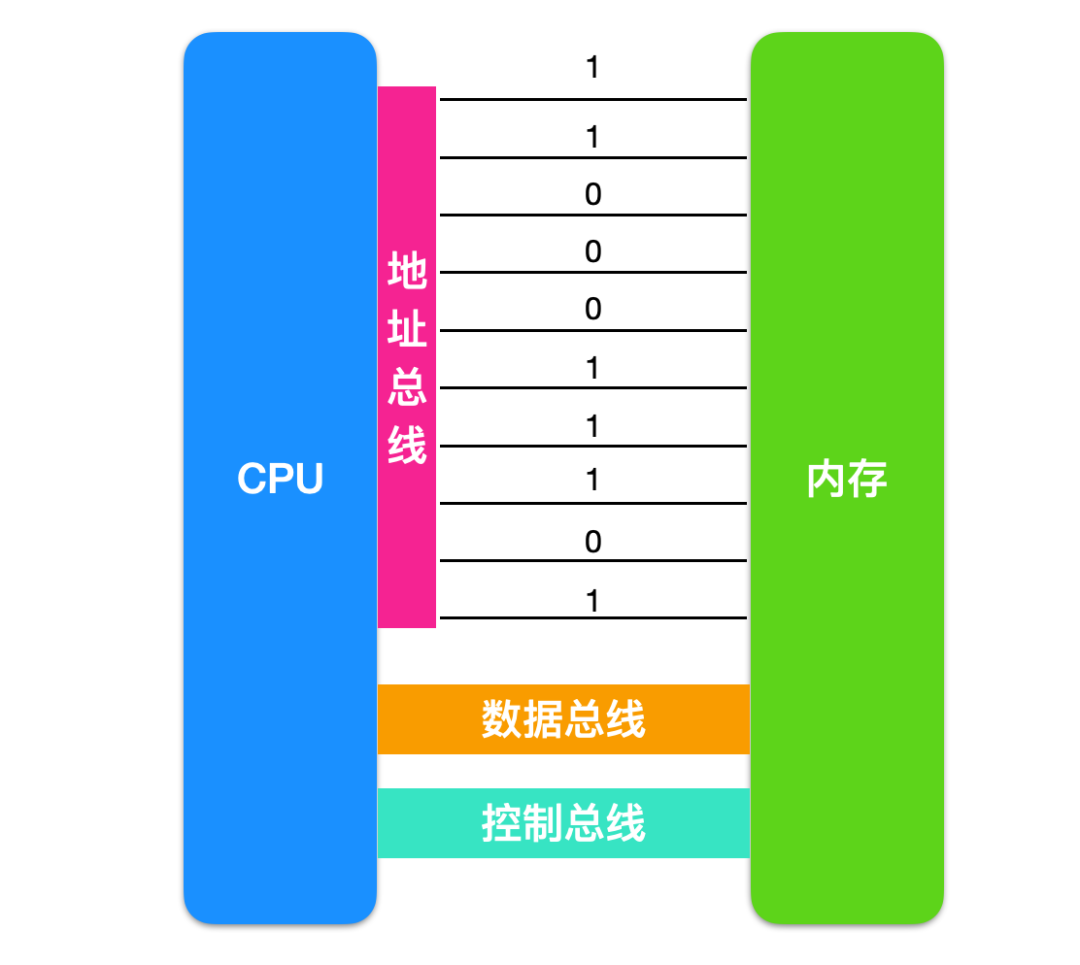
上图中 CPU 和内存中间信息交换通过了 10 条地址总线,每一条线能够传递的数据都是 0 或 1 ,所以上图一次 CPU 和内存传递的数据是 2 的十次方。
所以,如果 CPU 有 N 条地址总线,那么可以说这个地址总线的宽度是 N 。这样 CPU 可以寻找 2 的 N 次方个内存单元。
数据总线
CPU 与内存或其他部件之间的数据传送是由数据总线来完成的。数据总线的宽度决定了 CPU 和外界的数据传输速度。8 根数据总线可以一次传送一个 8 位二进制数据(即一个字节)。16 根数据总线一次可以传输两个字节,32 根数据总线可以一次传输四个字节。。。。。。
控制总线
CPU 与其他部件之间的控制是通过 控制总线 来完成的。有多少根控制总线,就意味着 CPU 提供了对外部器件的多少种控制。所以,控制总线的宽度决定了 CPU 对外部部件的控制能力。
一次内存的读取过程
内存结构
内存 IC 是一个完整的结构,它内部也有电源、地址信号、数据信号、控制信号和用于寻址的 IC 引脚来进行数据的读写。下面是一个虚拟的 IC 引脚示意图
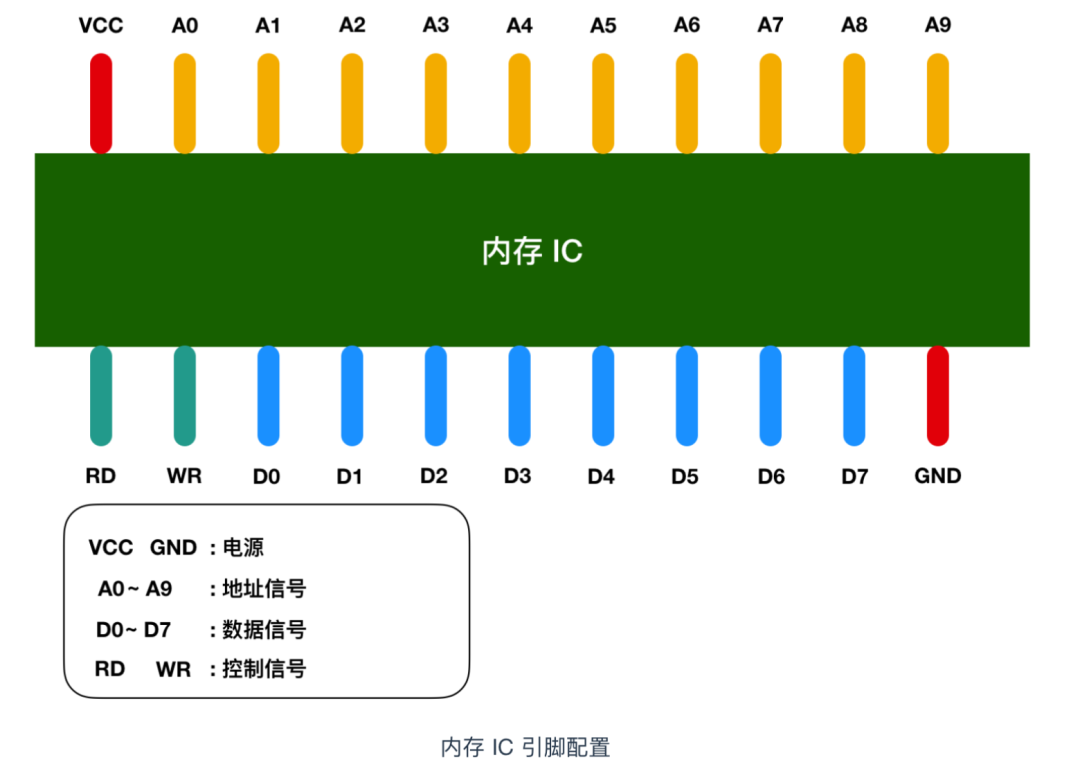
图中 VCC 和 GND 表示电源,A0 - A9 是地址信号的引脚,D0 - D7 表示的是控制信号、RD 和 WR 都是好控制信号,我用不同的颜色进行了区分,将电源连接到 VCC 和 GND 后,就可以对其他引脚传递 0 和 1 的信号,大多数情况下,+5V 表示1,0V 表示 0。
我们都知道内存是用来存储数据,那么这个内存 IC 中能存储多少数据呢?D0 - D7 表示的是数据信号,也就是说,一次可以输入输出 8 bit = 1 byte 的数据。A0 - A9 是地址信号共十个,表示可以指定 00000 00000 - 11111 11111 共 2 的 10次方 = 1024个地址。每个地址都会存放 1 byte 的数据,因此我们可以得出内存 IC 的容量就是 1 KB。
如果我们使用的是 512 MB 的内存,这就相当于是 512000(512 * 1000) 个内存 IC。当然,一台计算机不太可能有这么多个内存 IC ,然而,通常情况下,一个内存 IC 会有更多的引脚,也就能存储更多数据。
内存读取过程
下面是一次内存的读取过程。
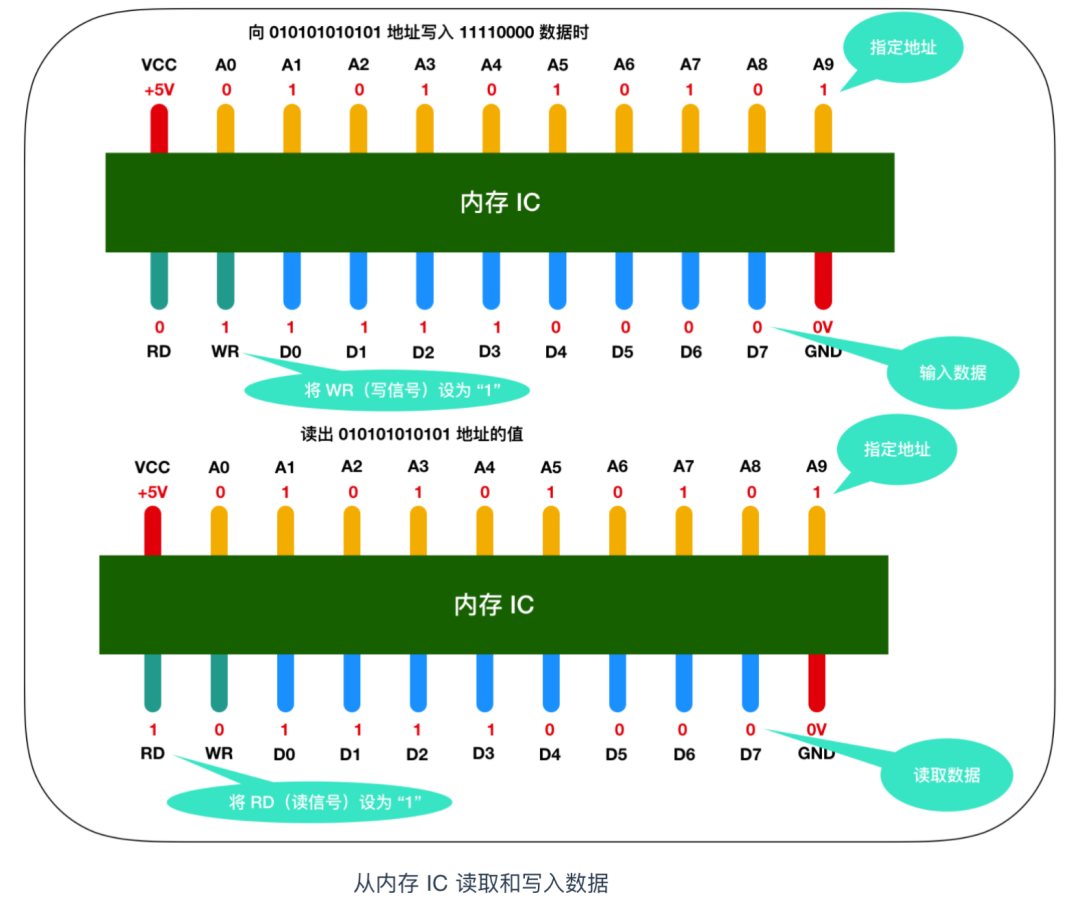
来详细描述一下这个过程,假设我们要向内存 IC 中写入 1byte 的数据的话,它的过程是这样的:
首先给 VCC 接通 +5V 的电源,给 GND 接通 0V 的电源,使用 A0 - A9来指定数据的存储场所,然后再把数据的值输入给D0 - D7的数据信号,并把WR(write)的值置为 1,执行完这些操作后,即可以向内存 IC 写入数据读出数据时,只需要通过 A0 - A9 的地址信号指定数据的存储场所,然后再将 RD 的值置为 1 即可。 图中的 RD 和 WR 又被称为控制信号。其中当WR 和 RD 都为 0 时,无法进行写入和读取操作。
总结
此篇文章我们主要探讨了指令集、指令集的分类,与汇编有关的硬件,总线都有哪些,分别的作用都是什么,然后我们以一次内存读取过程来连接一下 CPU 和内存的交互过程。
原创不易,如有帮助还请各位读者四连(点在、在看、分享、留言),感谢各位大佬
完
往期推荐
🔗
