
Arm全面计算战略重磅升级!Armv9架构CPU一键三连

作者|包永刚
雷锋网消息,今年三月,Arm推出了面向未来十年的新一代架构Armv9。今天,Arm发布新一代CPU、GPU产品和互联技术,Arm要用全新的全面计算产品组合,应对智能手机、高性能PC、可穿戴等众多应用的计算需求和设计挑战。
全新的CPU内核包括高性能核心Cortex-X1的升级版Cortex-X2,Cortex-A78的继任者Cortex-A710,时隔四年后升级Cortex-A55的全新小核心Cortex-A510。
三款全新的CPU核心都基于今年三月份推出的Armv9架构,可谓一键三连,因此在改进性能和效率的同时,也将拥有扩展的SVE(可伸缩矢量扩展)、机密计算架构、内存标签扩展特性。
Arm新一代Mali GPU产品包括高端系列Mali-G78的继任者Mali-G710,中端系列Mail-G57的后继产品Mali-G510,以及高能效产品Mali-G310。
全新的GPU系列依旧采用2019年发布的Valhall架构,这一架构2019年被Mali-G77首次使用,去年发布的Mali-G78进行了小幅升级,麒麟9000、Exynos 2100以及MediaTek天玑都使用了Mali-G78。
Arm高级副总裁兼终端设备事业部总经理 Paul Williamson告诉雷锋网,“之所以引入新的产品命名规则,主要是因为引入了Armv9架构,希望用新的命名表示这个新架构将会给市场带来的变化。”
除了全新CPU和GPU,Arm还发布了CoreLink CI-700 一致性互连技术和 CoreLink NI-700片上网络互连技术与Arm CPU、GPU和NPU IP搭配,可跨SoC解决方案增强系统性能。
1
Armv9架构三款全新CPU,性能
平均提升超30%
2023年完成向64位应用程序过渡
雷锋网此前文章指出,Armv9架构有三个系列,分别是针对通用计算的A系列,实时处理器的R系列,微控制器的M系列,预计未来两代移动基础设施CPU的性能提升将超过30%。首款基于Armv9架构CPU的移动处理器最快将在今年底问世,可能来自MediaTek。
全新Cortex核心首先需要关注的是兼容性问题。自谷歌2019年宣布Google Play商店要求开发者上传64位应用程序之后,业界就开始向64位应用程序过渡,并且,谷歌表示将在今年夏天晚些时候停止64位设备对32位应用程序的兼容。
Arm则表示,为了支持生态系统对于性能的需求, 2023 年将仅提供 64 位的移动应用大核和小核。因为在Armv9架构的全新三款CPU中,Cortex-X2和Cortex-A510只支持AArch64微体系结构,它们不再能够执行AArch32代码,而Cortex-A710仍将支持AArch32。

Arm解释称这主要是为了满足中国市场需求,由于中国移动应用市场缺乏像Google Play商店的同类生态系统,中国的供应商以及应用程序需要更多时间过渡到64位应用程序。
这意味着,在采用Arm全新Cortex内核的SoC上如果要运行32位的应用程序,只能运行在Cortex-A710核心。
仍要看到的是,全新的Armv9架构的产品X2和A710总体保持着X1和A78的目标,X系列愿意在合理的范围内折衷功率,通过微体系结构提高性能。A710则更着重于PPA(性能、功耗、面积)的平衡,通过更智能的设计提高性能和效率。小核A510是四年来的首次更新,是一种全新的小巧设计。

Cortex-X2性能优势进一步扩大
Cortex-X2进一步扩大了与Cortex-A710的性能和功耗的差距,Arm称X2除了可以用于智能手机SoC,也可以用于大屏幕计算设备和笔记本电脑等对性能要求更高的终端。基于Armv9架构,X2核心从前端分支预测改进、调度优化到后端的管道等都进行了诸多改进。
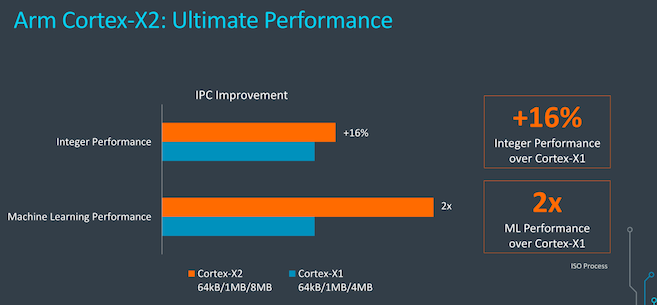
就单核性能而言,在SPECint2006测试中,在相同工艺制程和频率下,X2相比X1的集成性能提升了16%,机器学习性能提升高达2倍。但由于Arm是将8MB L3缓存设计与4MB L3设计进行比较,6%的性能提升到底是较大缓存还是核心性能提升暂不清楚。
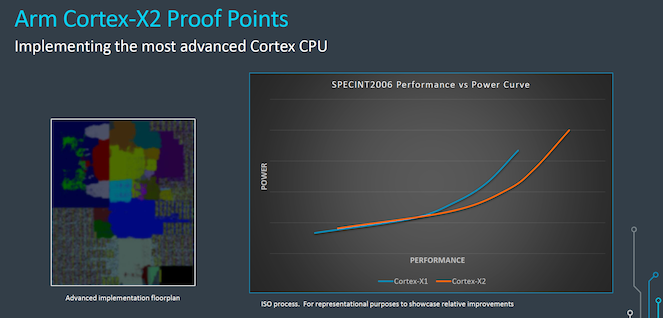
性能和功耗曲线来看,想要实现16%的性能提升需要付出更高的功耗,这将给三星和高通等手机SoC设计公司带来更大挑战。
Cortex-A710能效提升30%
由于同样采用了最新的Armv9架构,因此Cortex-A710同样从核心的前端到后端也进行了改进,不同的是A710还支持AArch32。
经过优化的结果是,Cortex-A710相比Cortex-A78实现了最多10%的性能提升和30%的能效提升。同样,10%的性能提升也是在8MB L3缓存设计与4MB L3缓存设计的比较。由于Cortex-A710可用于中端或低端SoC,这就意味着会使用较小缓存,10%的性能提升可能不容易实现。
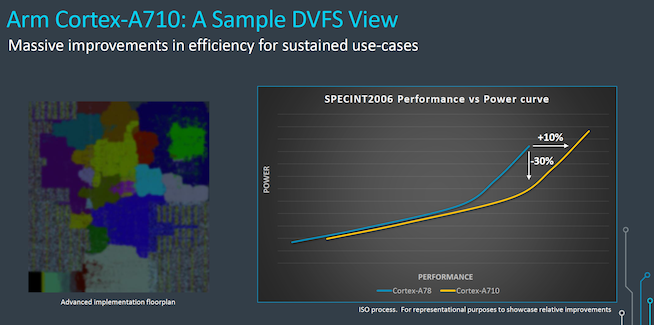
相比性能提升,稍微降低频率可以带来很大的功耗降低。Arm称,在性能相同的情况下,A710的功耗比Cortex-A78少30%。这将有利于适中频率的Cortex-A710 “中间”核心实现持续的性能和电源效率。
总体看来,X2和A710的性能和功率指标都很适中,提升也是近几年来最少的。Arm解释称,由于向Armv9的迁移而进行了较大的体系结构更改,因此对通常的效率和性能改进产生了影响。
X2和A710都是该奥斯汀微体系结构家族的第四代产品,因此我们正面临着不断减少的收益和成熟的设计壁垒。
四年来首次更新Cortex小核
小核心是时隔四年终于迎来更新,因为上一代小核心Cortex-A55早在2017年就发布。全新的Cortex-A510来自Arm剑桥团队,使用了很多已经在较大核中使用的技术。Arm称Cortex-A510新内核与此前的旗舰内核Cortex-A73的单核性能和频率非常相似,但功耗却低很多。
据悉,Arm采用了一个被称为“合并内核”的设计方法,这是一种非常复杂的方法,最多两个核心对,它们共享L2缓存系统以及它们之间的FP / NEON / SVE管道。
Arm指出,共享管道对硬件是完全透明的,并且还使用了细粒度的硬件调度。在同时使用两个内核的实际多线程工作负载中,与为每个内核专用的管道相比,性能影响和不足仅占百分之几。
乍一看,Arm的做法与AMD十年前在其Bulldozer内核中对CMT(集群多线程)所做的改进有一些非常相似,但是在某些重要方面却有很大不同。
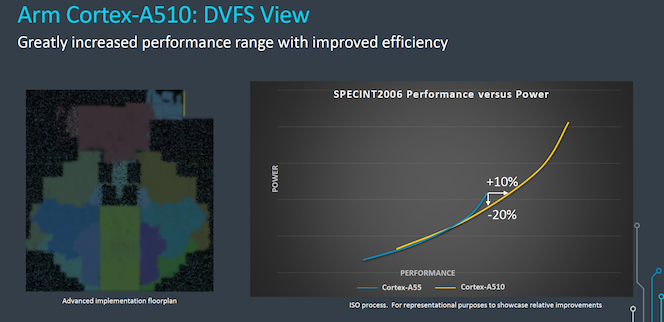
从性能指标看,将Cortex-A55与32KB L1、128KB L2和4MB L3与具有32KB L1、256KB L2和8MB L3的Cortex-A510比较。在核心频率相同的情况下,SPECint2006性能提升35%,SPECfp2006性能提升50%,提升非常显著,但从年均复合增长率的角度看,提升并不那么令人印象深刻。
比较IOS功率和性能,Cortex-A510性能提升10%,功耗可以降低20%。
值得注意的是,A510与A55的曲线在较低工作点几乎重叠。尽管A510总体上具有更好的性能,但这似乎主要是将效率曲线扩展到更高的功率水平的结果。实际上要在任何结构化的基准测试中重现这些更真实的工作负载是极其困难的。
需要注意,Armv9-A CPU群集(cluster)的支柱是新款的动态共享单元( DynamIQ Shared Unit)DSU-110,DSU-110 具备可扩展性、可支持最多八Cortex-X2 内核配置,同时确保效率表现。
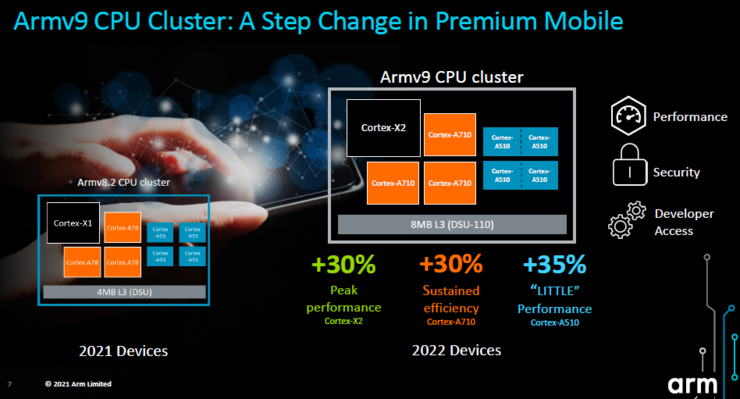
Paul Williamson称:“通过共享系统级缓存最多可以降低15%的能耗。”
2
旗舰Mali-G710 GPU是关注重点,
中低端GPU性能大跃升
新的GPU系列延续采用Valhall 架构,旗舰产品Mali-G710是Mali-G78的继承者,目标是相对简单的代际演进,这是Arm的架构师在Mali GPU中实现的最高性能。
Mali-G610对于Mali GPU的品牌有积极意义,G610继承了 Mali-G710 的所有功能,微体系结构相同,但价格更低。G610配置低于7个内核,可以帮助合作伙伴更好地区分旗舰产品与“高端”产品。
AnandTech指出,新的G710微体系结构看起来非常有趣,尤其是要解决与Arm的Mali GPU的API开销相关的一些弱点。如何发挥作用还有待观察,但从性能和功耗的提升来看,这似乎是一个稳健的进步,即便这不足以改变移动市场的竞争格局。
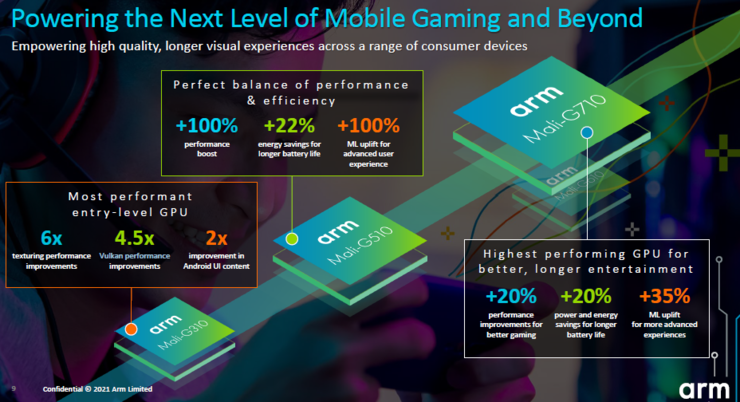
总的来说,对于大部分消费者而言,此次Arm升级的三款GPU关注的重点仍然是旗舰GPU Mali-G710。作为Valhall GPU架构的延续,新款G710执行引擎的与上一代Mali-G77和Mali-G78大致相同。与前一代Mali-G78 GPU相比,Arm承诺的改进是性能提高约20%,功耗有望降低20%,机器学习性能提升35%。
Mali-G510和Mali-G310是在前代G57和G31产品的基础上迭代升级。Mali-G510是Arm中端产品组合的重大升级,G510可从2核扩展到6核,可以在端智能手机、旗舰智能电视和机顶盒上实现 100%的性能提升以及22%的节能优化,延长了电池续航。
新的Mali-G310是基于Valhall的新低端产品,瞄准的是以低面积效率为重点的市场,包括数千亿的低成本设备和其他嵌入式市场,例如入门级智能手机、AR 设备和可穿戴设备。G310一个关键的价值是代表了Mali GPU架构从Bifrost架构到新的Valhall设计的重大转变。
这些新设计代表了微体系结构中新的重大突破,让Arm的中端和低端产品实现了显著的性能提升。G510相比G54性能提升了1倍,能效提升22%,机器学习性能提升了1倍。G310相比G31图形变形性能提升4.5倍,Vulkan性能提升4.5倍,Android UI性能提升2倍。
有意思的是,Anandtech认为由于缺少更大的幅度变化或步进功能升级,Arm的高端GPU前景看起来并不十分理想,三星已经确认在下一代Exynos GPU中采用AMD RDNA GPU,海思麒麟SoC被按下了暂停键。联发科成为最后一个会采用Mali高端GPU的公司,但他们至今还未推出真正的旗舰级SoC,所以有可能看不到高端Mali-G710产品。
Arm Mali GPU设计哲学一直是一把双刃剑,特别是它们正试图通过非常相似的微体系结构来满足如此广阔的市场。高端市场看起来有些暗淡,但中端和低端产品看起来非常有前途。
Arm表示,到2020年,他们已经出货了超过10亿个Mali GPU, DTV市场份额为80%,智能手机市场份额超过50%。
3
全面计算时代系统性能更加重要
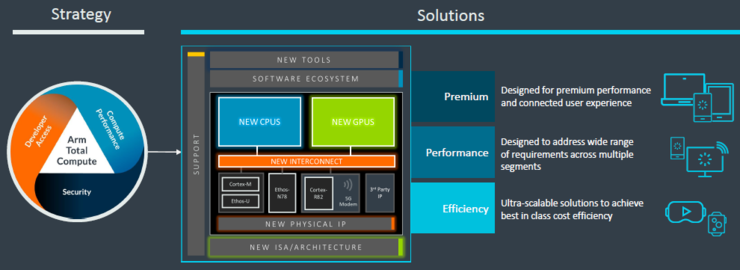
Arm在2019年首次提出全面计算战略,随着全新架构产品的发布,Arm的全面计算战略也进一步升级。Arm认为全面计算设计战略的三大关键原则是——计算性能、开发者可及性和安全性。要同时满足这三大关键原则,需要提供出色的性能、安全性、可扩展性和效率。
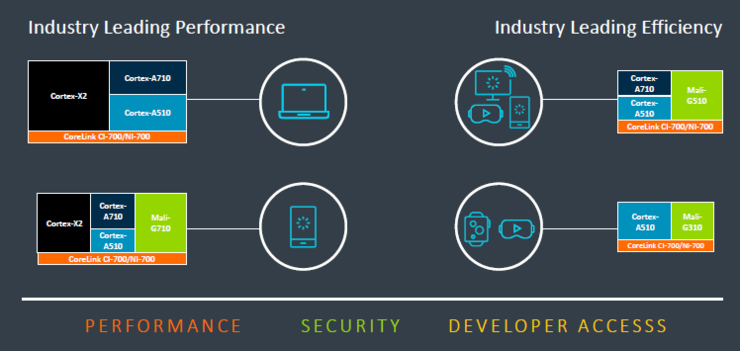
“我们正致力于将 Armv9 技术引入到各个领域,以系统级设计最大程度地提高性能。基于 Arm 架构的计算技术正在构建超越智能手机市场以外的领导地位,借助移动生态系统带来的巨大规模优势,在笔记本电脑、台式机、云等应用领域打造领先的解决方案。这些灵活的解决方案将被应用于Arm 合作伙伴的各种应用中,开启新一代沉浸式的交互体验。”Paul Williamson表示。
全面计算对于移动设备、有丰富功能的AI产品都非常重要。因此,既需要Arm的Cortex CPU和Mali GPU,还需要全新的互联技术,这对于提高系统性能至关重要。
Arm今天推出的CoreLink CI-700 和 CoreLink NI-700 对新的 Armv9-A 功能提供硬件级支持,如内存标签扩展(Memory Tagging Extension),并支持更高的安全性、改进的带宽和延迟。
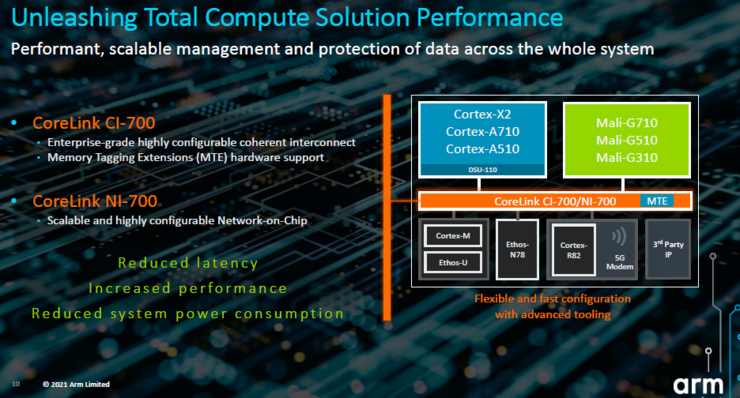
Paul Williamson指出,“以往算力用基准测试来衡量,但全面计算的时代PPA的重要性越来越低,交付更好的用户体验和更高的系统性能将变得更加重要。Arm 全新的全面计算解决方案采用系统范围的整体优化方法,横跨硬件 IP、物理 IP、软件、工具和标准,满足所有终端细分市场的应用场景和成本区间。”
对算力需求越来越高以及应用越来越丰富是可以看到的趋势,在变化越来越快的5G、AI和数字化时代,芯片巨头都已经转向多芯片组合竞争的时代,更加灵活的产品组合能够满足不同应用的性能需求。当然,与之相对应的还有制程、异构集成、封装等一系列的问题,需要整个产业链共同面对。
Arm的全面计算策略能获得多大的成功?
本文由雷锋网原创,作者:包永刚。申请授权请回复“转载”,未经授权不得转载。

VR之变:Pico修正航向,互联网巨头候场

造车,360要与哪吒“闹海”