
满满干货!!!lambda表达式使用总结

前言
最近一段时间一直在赶项目,所以也比较忙,今天我抽一些时间,把整个项目参与的收获和各位小伙伴分享下,也算是一个小阶段的总结,不过今天的主题是lambda,所以只能算是局部知识点的总结。
由于整个项目都采用redis存储数据(你没听错,就是拿redis当数据库),所以在数据读写方面,特别是查询的时候,很多场景下都是拿到数据后,还需要手动处理下,所以本次对lambda使用的频次特别高,今天我们就先抽点时间做一个简单的梳理和总结。
拉姆达表达式
提到lambda表达式,想必各位小伙伴一定不会感到陌生,lambda是JDK1.8引入的新特性,而且经常在面试的时候被问道,更重要的是使用lambda确实也可以让我们的代码更简洁,很多场景也更容易实现。前面我们也分享过lambda的相关知识点,感兴趣的小伙伴可以去看下:



今天我们主要lambda中的以下几块内容,这几个也是本次用的频次比较高的:
mapfilterjoiningmax排序 flatMapcollect
map
map其实就类似于一个处理器,我们可以通过map方法将现有对象的集合转换成我们需要的数据类型。
过滤属性
其中最常见的用法就是从一个对象实例的list中,过滤出对象实例的某个属性,比如User的name`属性:
User user1 = new User(1L, "syske");
User user2 = new User(2L, "yun zhong zhi");
List userList = Lists.newArrayList(user1, user2);
// 用户
System.out.printf("userList = %s\n",userList);
// 用户名list
List userNameList = userList.stream().map(User::getUsername).collect(Collectors.toList());
System.out.printf("userNameList = %s\n",userNameList);
运行结果如下:

user源码:
public class User {
/**
* 用户 id
*/
private Long id;
/**
* 用户名
*/
private String username;
/*
省略getter/setter方法
*/
}
这里我们其实也演示了collect方法的简单用法,collect方法的作用就是将我们map处理之后的数据流收集起来,后面我们还会详细演示它的用法。
转换类型
这里说的类型转换主要也是将List中的数据转换成我们需要的,比如将user转换为String:
List userStrList = userList.stream().map(String::valueOf).collect(Collectors.toList());
或者转换为json:
List collect = userList.stream().map(JSON::toJSONString).collect(Collectors.toList());
或者将String转成Integer:
ArrayList strings = Lists.newArrayList("0912", "1930", "1977", "1912");
List integers = strings.stream().map(Integer::parseInt).collect(Collectors.toList());
当然,map的用法会有很多,感兴趣的小伙伴自行探索下吧,下面我们看下其他lambda表达式的用法。
filter
filter也是日常开发中经常用到的一个表达式,而且非常好用,比如数据检索、数据过滤等:
ArrayList countList = Lists.newArrayList(89, 97, 99, 12, 15, 45, 55, 35, 25, 18);
// 过滤大于 40的数据
List collect1 = countList.stream().filter(a -> a > 40).collect(Collectors.toList());
// 过滤结果:[89, 97, 99, 45, 55]
过滤用户名中包含s的用户:
User user1 = new User(1L, "syske");
User user2 = new User(2L, "yun zhong zhi");
List userList = Lists.newArrayList(user1, user2);
// 过滤username包含s的用户
List users = userList.stream().filter(user -> user.getUsername().contains("s")).collect(Collectors.toList());
joining
joining主要是针对List聚合成string的场景,它主要用于需要将集合中的元素通过特定的符号拼接,比如,分割:
ArrayList ages = Lists.newArrayList(89, 97, 99, 12, 15, 45, 55, 35, 25, 18);
String collect2 = ages.stream().map(String::valueOf).collect(Collectors.joining(","));
// 运行结果:89,97,99,12,15,45,55,35,25,18
因为最终的结果是String,所以在joining之前先要通过map处理下数据,如果数据是String类型,则可以直接操作:
ArrayList strings = Lists.newArrayList("0912", "1930", "1977", "1912");
String collect3 = strings.stream().collect(Collectors.joining());
严格来说,joining操作属于collect方法的范畴,和Collectors.toList属于同一类操作。
max
max就很简单了,就是获取集合中的最大值,和min相对。支持对数字、字符串等数据进行操作:
Optional max = ages.stream().max(Comparator.naturalOrder());
System.out.println(max.get());
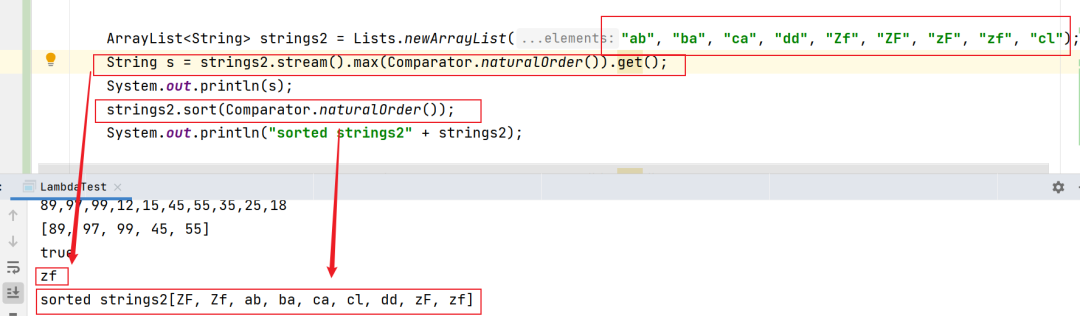
这里的Comparator.naturalOrder就是安装自然顺序排序,也就是9-1,或者z-a,我测试的时候发现,如果存在相同字符(但是大小写不同,针对字符串),排序的时候是按照小写大于大写的规则进行排序的,具体可以看下面的截图:
如果数据是数字:
ArrayList ages = Lists.newArrayList(89, 97, 99, 12, 15, 45, 55, 35, 25, 18);
Optional max = ages.stream().max(Comparator.naturalOrder());
// 运行结果:99
这里有个骚操作,如果把Comparator.naturalOrder()改成Comparator.reverseOrder()获取到的就是最小值,我在想如果你就是想写这样一个让别人想不到的bug,你可以试试这样操作,看会不会被打死。
排序
排序其实在上面max以及有提及了,这里我们再详细看下。一般我们并不会单通过stream进行排序,因为常用的集合基本上都提供了排序方法,比如List:
ArrayList strings2 = Lists.newArrayList("ab", "ba", "ca", "dd", "Zf", "ZF", "zF", "zf", "cl");
strings2.sort(Comparator.naturalOrder());
只有在stream处理之后,数据还要求有顺序要求的时候,我们才会通过stream进行排序:
ArrayList ages = Lists.newArrayList(89, 97, 99, 12, 15, 45, 55, 35, 25, 18);
List collect1 = ages.stream().filter(a -> a > 40).sorted(Comparator.naturalOrder()).collect(Collectors.toList());
这样处理完成之后的数据就是有序集合了,这样的性能会比拿到集合之后再排序要好。
flatMap
flatMap和map有点像,当然区别也挺大,map其实就类似水管中单进单出的处理器,进去多少个,出来多少个,而flatMap是单入多出的处理器,进去一个,出来可能是多个。下面我们看下他们的对比:
// 原始数据
ArrayList strings3 = Lists.newArrayList("09,12", "19,30", "19,77", "19,12");
// map处理
List collect4 = strings3.stream().map(string -> string.split(",")).collect(Collectors.toList());
// flatMap
List collect5 = strings3.stream().flatMap(string -> Arrays.stream(string.split(","))).collect(Collectors.toList());
可以看到map只能把数据最终分割成与原有元素数量相等的数据数组,而flatMap这里可以进一步将数据进行分割,最终直接返回我们的目标数据,进一步说就是flatMap可以改造流,而map只能在流的基础上处理。
另外,需要注意的是,流和水管中的水一样,一旦被处理之后(流过)就不存在了,所以是没有办法作为参数被频繁使用。
collect
toMap
collect我们前面的示例一直都在使用,和其他方法相比,collect就是流的终点,也就是最终的收集器,collect除了可以把数据收集到List、Set中,还可以把数据处理成map
User user1 = new User(1L, "syske");
User user2 = new User(2L, "yun zhong zhi");
List userList = Lists.newArrayList(user1, user2);
// 构建userId,userName 集合
Map collect6 = userList.stream().collect(Collectors.toMap(User::getId, User::getUsername));
// 构建userId,用户集合
Map collect7 = userList.stream().collect(Collectors.toMap(User::getId, Function.identity()));
需要注意的是,toMap需要避免key冲突,通常情况下我们只需要多加一个参数即可解决问题:
Map collect6 = userList.stream().collect(Collectors.toMap(User::getId, User::getUsername, (a, b) -> a));
这里的(a, b) -> a意思就是如果key已经存在,则保留旧的值,这一点可以从源码中看出来:
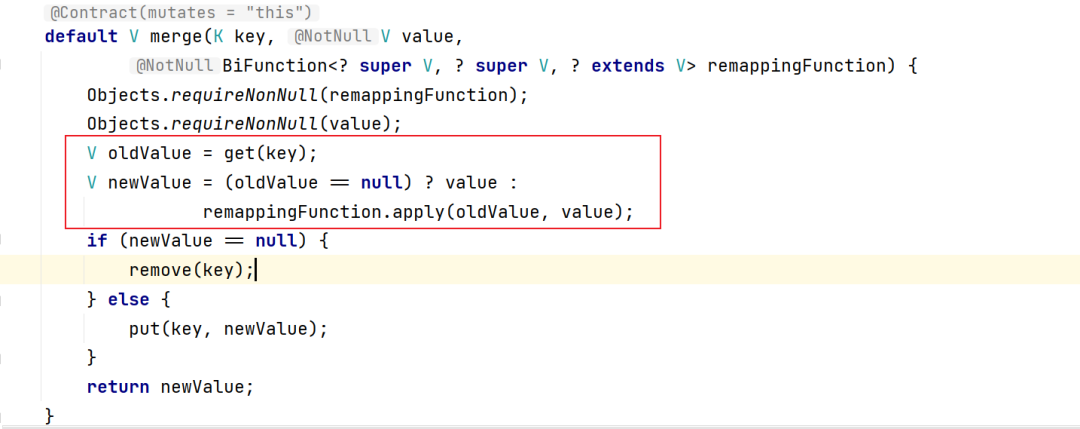
如果旧的值为null,则新值直接覆盖,否则根据我们的策略取值,即用旧值。
groupBy
除了上面的toMap,下面这个就更方便了,可以直接根据数据的某个属性分组,最终返回属性对应的map,比如这里
User user1 = new User(1L, "syske");
User user2 = new User(2L, "yun zhong zhi");
User user3 = new User(2L, "yun zhong zhi 2");
List userList = Lists.newArrayList(user1, user2, user3);
Map> collect8 = userList.stream().collect(Collectors.groupingBy(User::getId));
// 运行结果如下:
// {1=[User{id=1, username='syske'}], 2=[User{id=2, username='yun zhong zhi'}, User{id=2, username='yun zhong zhi 2'}]}
除了上面这种,还有其他更方便更强的操作,比如我想分组之后统计数量:
Map collect9 = userList.stream().collect(Collectors.groupingBy(User::getId, Collectors.counting()));
// 运行结果如下(元数据同上):{1=1, 2=2}
需要注意的是,Collectors.counting()返回的是Long。
再比如分组之后我们还需要对某个字段求和:
Map collect10 = userList.stream().collect(Collectors.groupingBy(User::getId, Collectors.summingLong(User::getId)));
// 运行结果如下(元数据同上):{1=1, 2=4}
再比如分组之后求平均值:
Map collect11 = userList.stream().collect(Collectors.groupingBy(User::getId, Collectors.averagingLong(User::getId)));
// 运行结果如下(元数据同上):{1=1.0, 2=2.0}
好了,关于groupBy我们就说这么多,还有其他需求的小伙伴可以自己再研究下。
其他
collect这块除了我们上面提到的,还有几个比较常用的,其实就是我们在groupBy那块组合用到的,比如求平均值:
Double collect12 = userList.stream().collect(Collectors.averagingLong(User::getId));
求和:
Long collect13 = userList.stream().collect(Collectors.summingLong(User::getId));
还有我们前面说的joining、maxBy、minBy、counting等,就不一一列举了,因为方法实在是太多了。
结语
应该说从jdk1.8开始,lambda让java编程更优雅也更简便,但这并不是推荐你在日常开发中全部使用lambda表达式,毕竟在某些场景下,lambda性能并不好,关于这块我们之前是有测试结果的:

当然如果用parallelStream会解决性能问题,但是在使用parallelStream的时候尽可能不要用到外部变量,否则会导致线程安全问题,这个我踩过坑。总之,就是你要慢慢学会把握使用lambda的场景,在一些性能差别不是特别大的场景下,用lamdba会让你的代码更简洁,更容易理解,最重要的是可以写更少的代码,提升开发效率。
今天虽然分享的内容有点多,但都是满满的干货,是我最近一段时间工作中使用lambda的一点点总结,希望可以真正帮到各位小伙伴,好了,晚安吧!