
Kylin 特性 | Kylin 4 最新功能预览 + 优化实践抢先看
自 Kylin 4.0.0-beta 发布以来,2021 年上半年 Kylin 社区一直在积极推动 Kylin 4.0.0 的发布工作,与有赞、小米等 Kylin 深度用户一起开发和测试,包括:
支持手动调整 Cuboid list 并重构历史 segment;
从 Kylin 3 到 Kylin 4 的元数据升级工具;
支持 Spark 3 等;
除了以上新功能外,社区还对实际使用过程中遇到的一些性能以及稳定性问题进行了优化。快来一起看看具体有什么新功能和优化实践吧~
1
Kylin 4 功能更新
支持用户手动调整 Cuboid List
为了让用户可以根据业务场景更灵活的调整 Cube,Kylin 4.0 提供了允许用户手动调整 cuboid list 的能力。通过调用 REST API 为指定 Cube 传入需要删除或增加的 cuboids,就可以更新指定 Cube 的 cuboid list。Cuboid list 更新后,Kylin 会对该 Cube 中每个已经构建过的 segment 生成对应的 optimize segment job 来更新历史 segment 的 cuboid list。
Optimize segment job 不同于 Refresh segment Job,它不会重新构建历史 segment 中所有的 cuboid,而是从已有的 cuboid 数据来构建新增 cuboid,并移除需要删除的 cuboid。所有的 Optimize segment job 完成之后,最后会通过一个 checkpoint job 来统一更新 Cube 元数据,并进行垃圾清理。在这个过程中用户的所有查询任务都不会受到影响。
JIRA issue:
https://issues.apache.org/jira/browse/KYLIN-4966
元数据升级工具
对于 Kylin 2.x 和 Kylin 3.x 的老用户来说,想要升级到 Kylin 4.0,需要对元数据进行升级。有赞在升级 Kylin 4.0 的实践过程中,在 Kylin 提供的 Cube 迁移工具 CubeMigrationCLI 的基础上,开发出了元数据升级工具,支持将 Kylin 2.x/ Kylin 3.x 版本的元数据以不同粒度迁移到 Kylin 4.0,用户可以选择指定单个 Cube 迁移、指定 project 迁移或者全量迁移。
JIRA issue:
https://issues.apache.org/jira/browse/KYLIN-4923
使用文档:
https://cwiki.apache.org/confluence/display/KYLIN/How+to+migrate+metadata+to+Kylin+4
Kylin 4 支持 Spark 3.1.1
小米在试用 Kylin 4.0 的实践过程中,根据实际需要将 Spark 版本从 Spark 2.4.6 升级到了 Spark 3.1.1,并且已经向社区提了 PR,目前我们正在 review 和测试,预计将在 Kylin 4.0.0 中提供对 Spark 3.1.1 的支持。
未来在 Kylin 4.0 支持 Spark 3 之后,用户不仅能够使用 Spark 3.0 中很多强大的新特性,比如 AQE 等,同时也能够实现对 Hive 2 和 Hive 3 更好的兼容。
JIRA issue:
https://issues.apache.org/jira/browse/KYLIN-4925
2
Kylin 4 性能优化实践
解决构建过程中产生的数据倾斜问题
对于存在精确去重度量的 Cube,在构建 base cuboid 之前,Kylin 需要对 Flat Table 使用全局字典进行编码。Kylin 4.0 的构建引擎在进行编码时,为了提高编码效率,会将 Flat Table 按照当前编码列进行 repartition。当编码列存在数据倾斜时,对它进行 repartition 操作就会导致重分区后 Flat Table 的某一个或者少数几个 partition 的数据量特别大,用这样的 Flat Table 去构建 base cuboid 时,数据量大的 partition 所对应的 task 可能就会占用特别长的时间,造成不合理的构建时长。
为了解决这个问题,Kylin 4.0 在编码过程之后增加了一个可配置的步骤。该步骤会根据所有 Rowkey 列再次进行 repartition,纠正根据编码列进行重分区后产生的数据倾斜问题,然后数据就会比较均匀的分布在各个 partition,这样再进行后面的构建 base cuboid 操作时,各个 task 的用时情况就会比较平均。
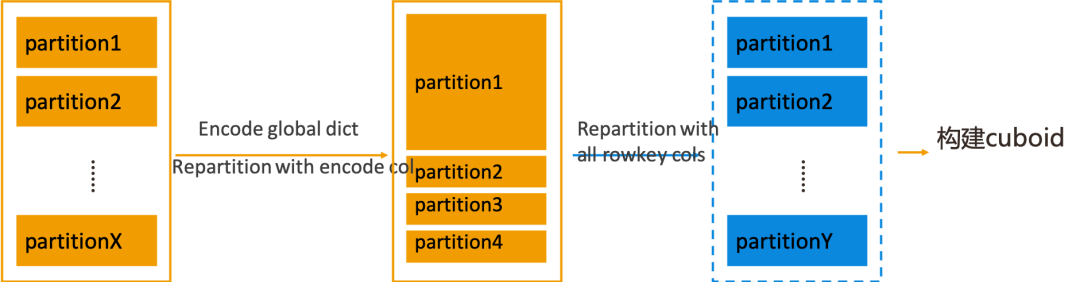
以上这个步骤在默认情况下是关闭的,用户可以根据自己的实际场景来决定是否打开,配置项为:kylin.engine.spark.repartition.encoded.dataset。
除了开关以外,此步骤还有一个相关的配置项:kylin.engine.spark.dataset.repartition.num.after.encoding,用于控制该 repartition 步骤的分区数量。在默认情况下,会使用之前为编码列编码过程中分区数量的最大值作为这次重分区操作的分区数。
在有赞的实践案例中,经过以上的优化,base cuboid 的构建时长可以从 20 分钟减小至 4 分钟。
JIRA issue:
https://issues.apache.org/jira/browse/KYLIN-4945
避免构建过程中重复读取 Cuboid 文件
Kylin 4.0 在构建过程中会将所有 cuboid 组织成一棵 Spanning tree,构建下一层 child cuboid 时将上一层 cuboid 作为 parent cuboid,构建 child cuboid 时会从 hdfs 中读取已经构建好的 parent cuboid 数据。这样就会造成多个 child cuboid 都使用同一个 parent cuboid 进行构建时会重复读取 HDFS 中的 Cuboid 文件的情况。
针对这个问题,Kylin 4.0 的解决方案是对拥有多个 child cuboid 的 parent cuboid 做 persist 操作。当发现某个 parent cuboid 的 child cuboid 的数量大于 1 的时候,就会在首次读取该 parent cuboid 时将 cuboid dataset persist 到指定 storage level,这样其他的 child cuboid 需要读取该 parent cuboid 时,就可以从 cache 中读取到,不必再去访问 HDFS,当 parent cuboid 的所有 child cuboid 都构建完成后,对应的 cache 会被 release。
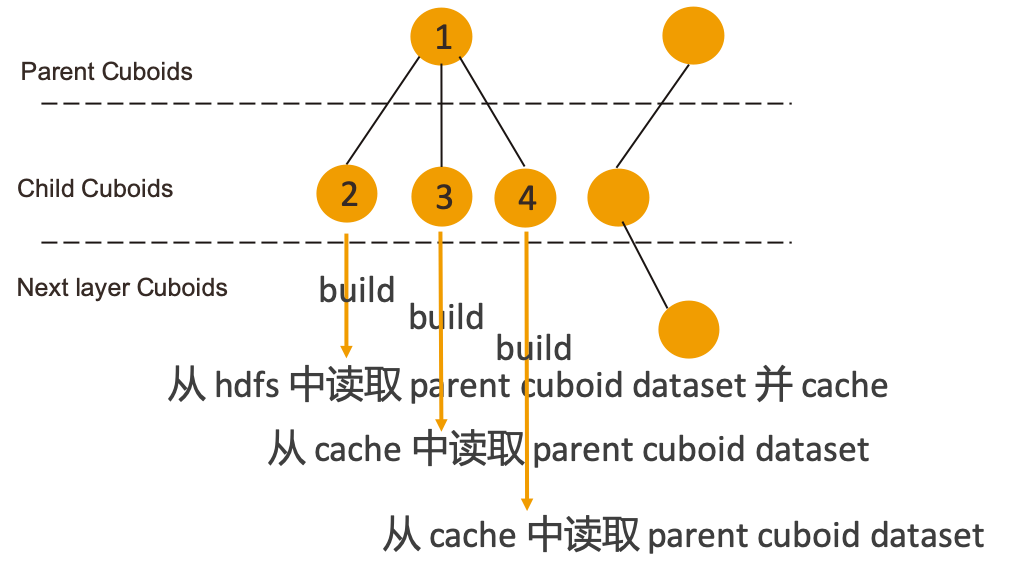
Persist 的 storage level 是需要用户自己配置的, 配置项为 kylin.engine.spark.parent-dataset.storage.level,默认为 NONE,即不提供缓存。用户可以将其配置为 MEMORY_ONLY、MEMORY_AND_DISK 等这些 Spark 的 StorageLevel 中提供的类型。
除此之外,为了防止内存占用过多,新增配置项 kylin.engine.spark.parent-dataset.max.persist.count 来控制同一时间最多可以 persist 多少个 cuboid dataset,默认为 1。如果这个值配置为 10,那么在并行发起一层 cuboid 的构建时,当 cache 数量达到 10 时,后续需要 persist parent cuboid 的 child cuboid 的构建任务将会被阻塞,直到 cache 中有 parent cuboid 的缓存被 release,才会继续进行后续的构建任务,所以开启这个功能之后,会在一定程度上影响构建的并行度。用户可以参考自身需求,根据实际场景来使用。
在有赞的实践经验中,配置 StorageLevel 为MEMORY_AND_DISK,max persist count 为 5,可以提高 20~30% 的构建速度。
JIRA issue:
https://issues.apache.org/jira/browse/KYLIN-4903
优化对于精准命中 Cuboid 的 SQL 的处理
Kylin 4 在查询过程中,需要将 calcite 的 SQL 执行计划转化成 Spark 的执行计划,对于 calcite 中 aggregate 类型的 RelNode,转换到 Spark 执行计划中就是一个 aggregate 算子,Spark 在执行 aggregate 的过程会产生 shuffle。大家都知道,shuffle 是一个比较昂贵的操作,它会产生大量的磁盘 IO 和网络资源以及内存消耗。
实际上,对于一条可以与某个 cuboid 精确匹配的 SQL 而言,不需要进行任何上卷聚合,就可以从匹配的 cuboid 中 select 出符合条件的数据。
但是 Kylin 4 在将 calcite 执行计划转化成 Spark 执行计划时,无论 cuboid 是否精确匹配,calcite 中的 aggregate 都会转化成 Spark 执行计划中的 aggregate,而在精准匹配 cuboid 的情况下,这里的 aggregate 除了会在操作过程中产生 shuffle,实际上并没有进行任何的数据聚合。
为了优化这种查询场景,我们在将 calcite 的 aggregate 的 relnode 转化成 Spark plan 时,增加了对是否精确匹配 cuboid 的判断。当 aggregate relnode 中 group by 的列与 cuboid 的列完全一致时,就认为当前聚合是精确匹配到 cuboid 的,不需要进行二次聚合,这时候就会跳过 Spark 中的 aggregate,直接转化成 project。
当然,这里也会有一些特殊情况需要处理,对于查询的度量是精确去重或者近似去重时,还是需要先计算出去重的结果。经过优化,同样的一条 SQL 查询任务产生的 Spark job DAG 图对比如下:
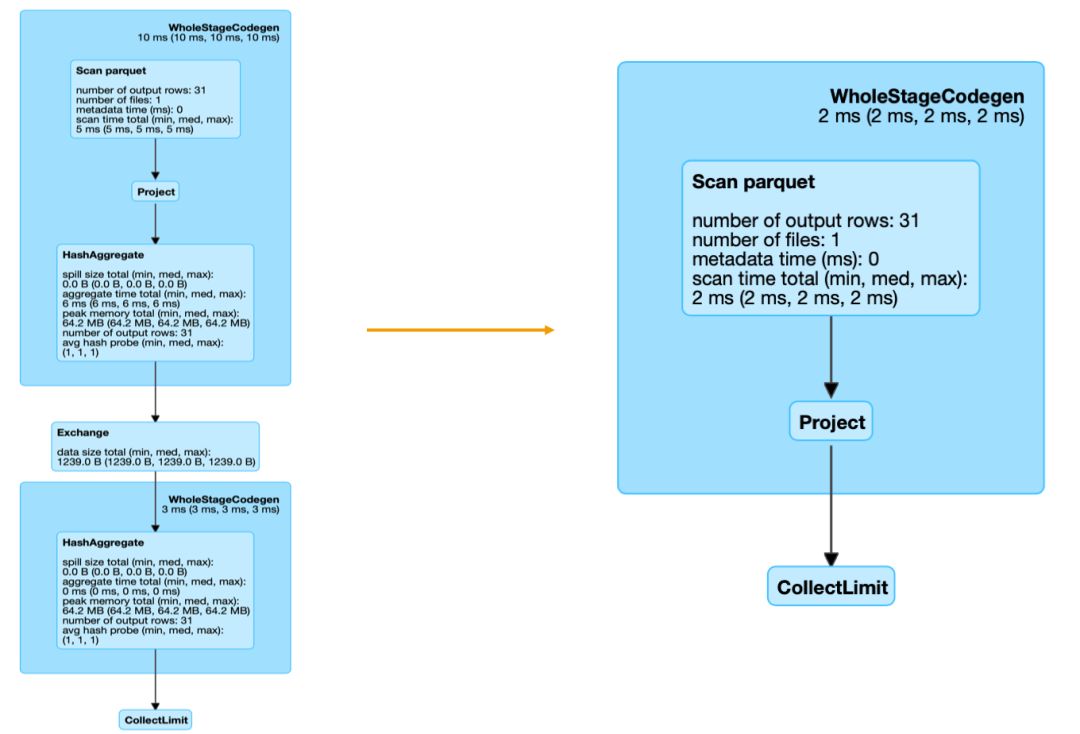
在有赞的实践案例中,经过以上优化,对包含去重指标(无论是精确去重还是近似去重)的查询,QPS 可以从 39 提升到 49,对于没有去重指标的查询,QPS 可以从 40 提高到 60。
3
Kylin 4 近期技术会议
目前有赞和小米都在深度试用 Kylin 4.0,已经向社区贡献了各类优化改进等十几个 PR, 社区也对他们在试用过程中遇到的各类问题积极响应,这些实践经验也帮助 Kylin 4.0 变得更快速、更稳定。随着 Kylin 4.0 实践的深入,近期我们将会在两场技术大会上分享 Kylin 4.0 的实践和调优经验:
QCon 全球软件开发者大会
在 2021 年 5 月 29 日 - 31 日举办的 QCon 全球软件开发者大会上,来自有赞的数据基础平台负责人郑生俊将会在大数据开源框架与应用专题上分享有赞内部对 Kylin 4.0 的使用经历和优化实践。
*活动链接:
https://qcon.infoq.cn/2021/beijing/presentation/3384
ApacheCon Asia
今年 8 月 6 日 - 8 日即将举办首次 ApacheCon Asia 线上大会,来自 Kyligence 的高级架构师张智超将会从架构升级、构建调优、查询调优等几个方面来介绍 Apache Kylin 4.0 全新的调优之路,具体活动议程将于六月公布,请大家敬请期待~
*活动链接:https://apachecon.com/acasia2021/
欢迎对 Kylin 4.0 感兴趣的小伙伴们报名参加!

点击阅读原文,试用 Kylin 4.0.0-beta