
首期 Go 开源说实录:Excelize 开源背后的故事



电子表格办公文档有着广泛的应用 自动化电子表格文档处理系统与云计算、边缘计算场景融合 开发者需要通过编程方式处理 Excel 文档 对复杂或包含大规模数据的 Excel 文档进行操作的需求 文档格式领域难以完全实现的复杂技术标准 开源领域、Go 语言缺少具备良好兼容性的基础库
v1.0.0 (2016-09-19) 首次发布:支持插入图片、图表、合并单元格等 v1.1.0 (2017-08-19) 支持条件格式、复制工作表 v1.2.0 (2017-12-01) 兼容 Go 1.9,支持堆积图表 v1.3.0 (2018-05-11) 行列分组、单元格批量赋值 v1.4.0 (2018-08-14) 支持数据验证、色值转换 v1.4.1 (2019-01-01) 搜索单元格、保护工作表 v2.0.0 (2019-05-02) 引入流式读写,性能进一步提升 v2.0.1 (2019-07-01) 页眉页脚、文档属性设置 v2.0.2 (2019-10-09) 嵌入 VBA 工程、数据透视表 v2.1.0 (2020-02-10) 支持非 UTF-8 编码文档 v2.2.0 (2020-05-11) 支持图表工作表、富文本、分页 v2.3.0 (2020-08-06) 新增工作表视图属性设置 v2.3.1 (2020-09-23) 兼容 Go 1.15,支持读加密 Excel v2.3.2 (2021-01-04) 图表、数据透视表功能增强,更好的兼容性与更快的流式读写
调研市面上主流的技术实现
理解相关技术标准 ECMA-376,ISO/IEC 29500,MS-OFFCRYPTO
使用 Go 语言编写代码实现功能
数据结构代码生成器的设计
公式词法 / 语法分析、计算框架
文档格式标准解读 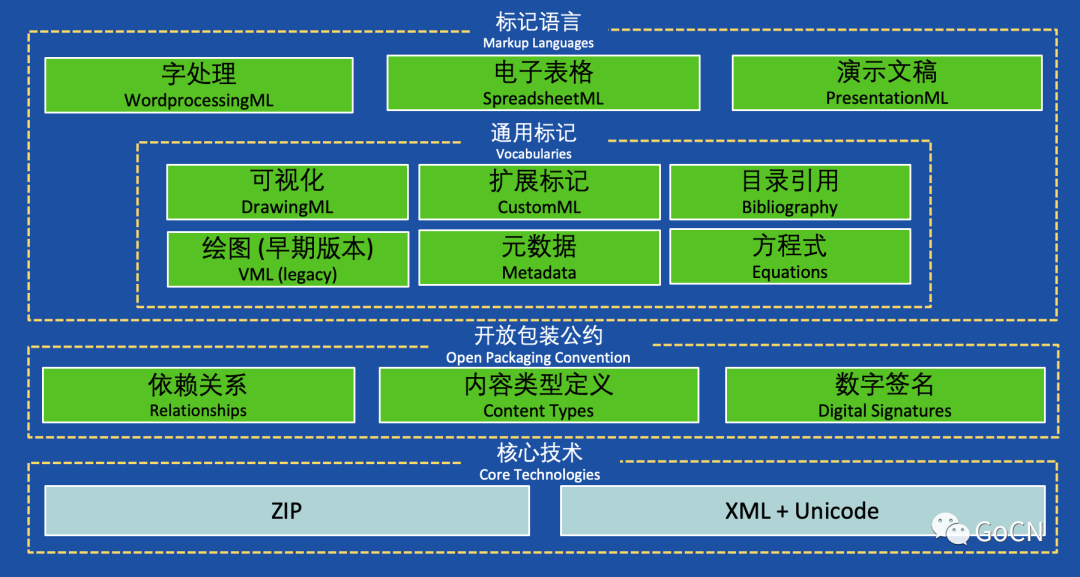
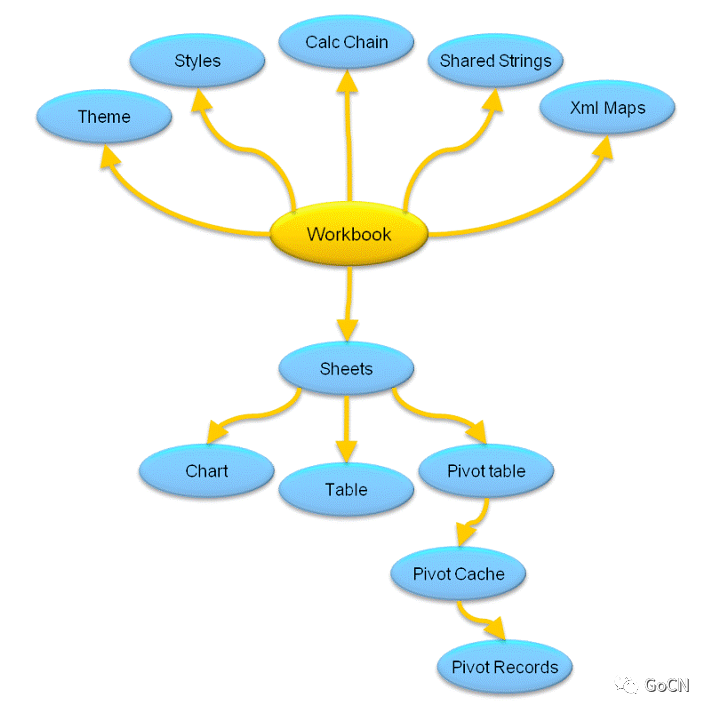
电子表格文档格式典型关系
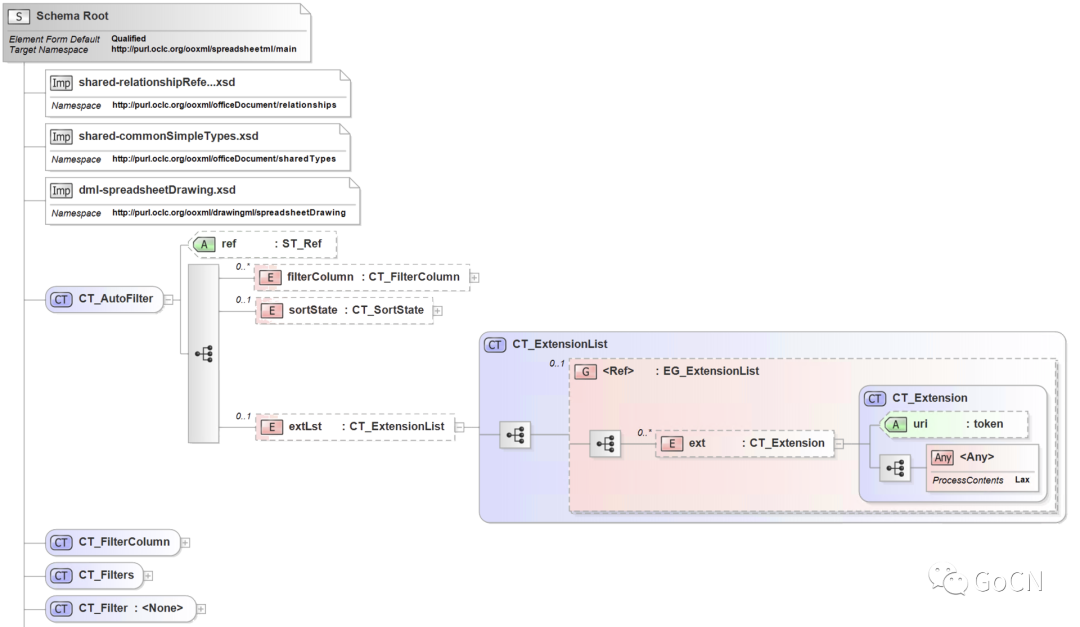
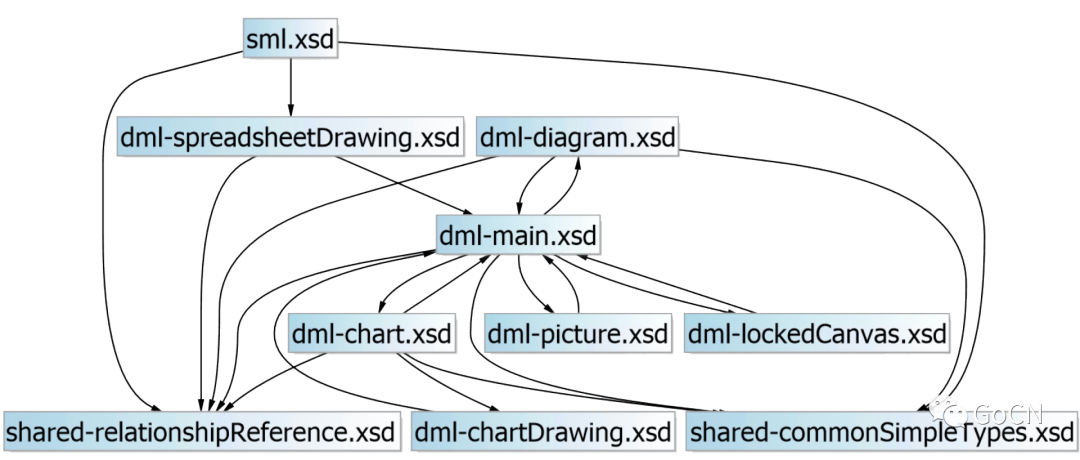
xgen -i /path/to/your/xsd -o /path/to/your/output -l Go
-i 参数指定了输入源(input),可以传入 XSD 目录,-o 参数指定了代码生成的输出路径(output),-l 参数用于指定生成代码的编程语言(language),该工具也开源到了 GitHub 上:https://github.com/xuri/xgen。这样我们就获得了操作数据模型所需要的结构体定义代码了。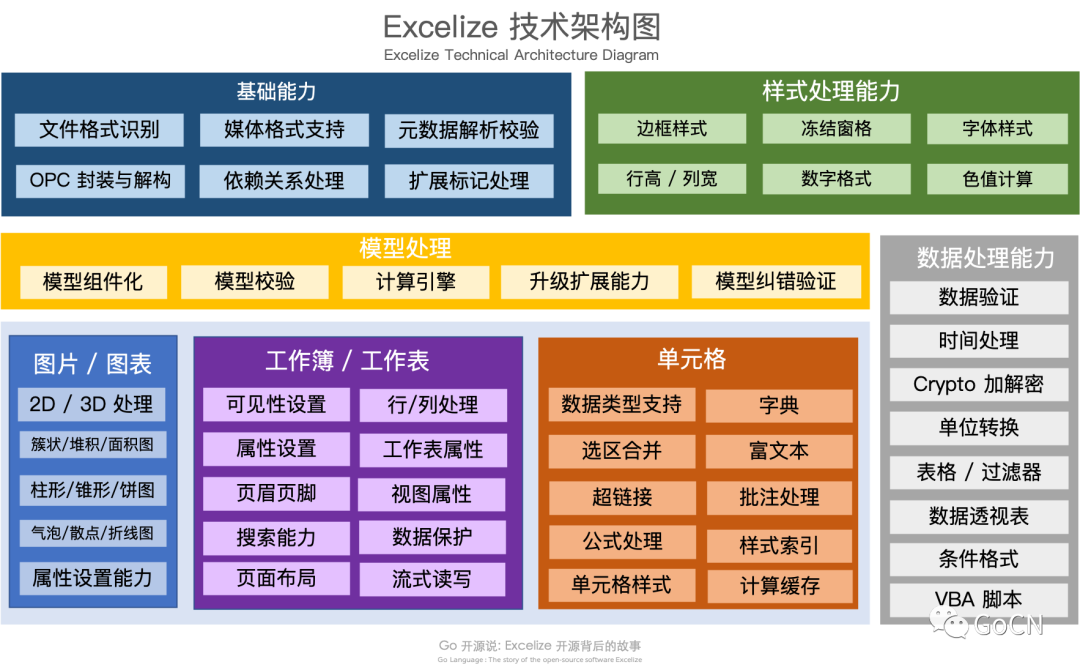
基础能力 - 文件格式识别、媒体格式支持、元数据解析校验、OPC 封装与解构、依赖关系处理、扩展标记处理; 样式处理能力 - 边框样式、冻结窗格、字体样式、行高 / 列宽、数字格式、色值计算; 模型处理 - 模型组件化、模型校验、计算引擎、升级扩展能力、模型纠错验证; 图片 / 图表 - 2D / 3D 处理、簇状 / 堆积 / 面积图、柱形 / 锥形 / 棱锥 / 饼图、气泡 / 散点 / 折线图、属性设置能力; 工作簿 / 工作表 - 可见性设置、行 / 列处理、属性设置、工作表属性、页眉页脚、视图属性、搜索能力、数据保护、页面布局和流式读写; 单元格 - 数据类型支持、字典、选区合并、富文本、超链接、批注处理、公式处理、样式索引、单元格样式和计算缓存处理; 数据处理能力 - 数据验证、时间处理、Crypto 加解密、单位转换、表格 / 过滤器、数据透视表、条件格式、VBA 脚本
=1+SUM(SUM(1,2*3),4)
import "github.com/xuri/efp"// ...ps := efp.ExcelParser()ps.Parse("=1+SUM(SUM(1,2*3),4)")println(ps.PrettyPrint())
1 <Operand> <Number>+ <OperatorInfix> <Math>SUM <Function> <Start>SUM <Function> <Start>1 <Operand> <Number>, <Argument> <>2 <Operand> <Number>* <OperatorInfix> <Math>3 <Operand> <Number><Function> <Stop>, <Argument> <>4 <Operand> <Number><Function> <Stop>

通过上述过程即可实现对公式的求值运算,具体代码可参考 Excelize 源代码 calc.go 文件中的 evalInfoxExp 函数。公式函数的动态调用入口如下:
// call formula function to evaluateresult, err := callFuncByName(&formulaFuncs{},strings.NewReplacer("_xlfn", "", ".", "").Replace(opfStack.Peek().(efp.Token).TValue),[]reflect.Value{reflect.ValueOf(argsList),})
当执行公式函数调用时,将 OPF(函数栈)栈顶元素类型推断为 Token,元素的值即为函数名,先对函数名称做预处理,然后进行函数调用,其中 callFuncByName 的实现如下面的代码所示,它会根据给定的函数 Receiver、函数名称(name)和函数参数(params)进行函数调用:
// callFuncByName calls the no error or only// error return function with reflect by given// receiver, name and parameters.func callFuncByName(receiver interface{},name string, params []reflect.Value) (result string, err error) {function := reflect.ValueOf(receiver).MethodByName(name)if function.IsValid() {rt := function.Call(params)if len(rt) == 0 {return}if !rt[1].IsNil() {err = rt[1].Interface().(error)return}result = rt[0].Interface().(string)return}err = fmt.Errorf("not support %s function",name)return}
这样仅需实现一些列函数签名与 callFuncByName 形参数据类型相一致的公式函数即可,例如实现求和公式 SUM:
func (fn *formulaFuncs) SUM(argsList *list.List) (result string, err error)余弦三角函数 COS:
func (fn *formulaFuncs) COS(argsList *list.List) (result string, err error)中位数函数 MEDIAN:
func (fn *formulaFuncs) MEDIAN(argsList *list.List) (result string, err error)这样避免了定义公式函数名与函数的映射关系,并具备高度的可扩展性,开发者可以根据此模式继续实现其他公式函数或创建自定义公式函数。
使用 Go 语言编写,得益于其跨平台、高性能的优势
兼容性第一原则,以高保真无损编辑为目标
简洁明了的 API 设计,遵循最小可用原则,兼顾其他语言开发者
图文并貌的多国语言参考文档 https://xuri.me/excelize
代码开源,丰富 Go 语言生态
时刻与开源社区保持积极互动
动态度表
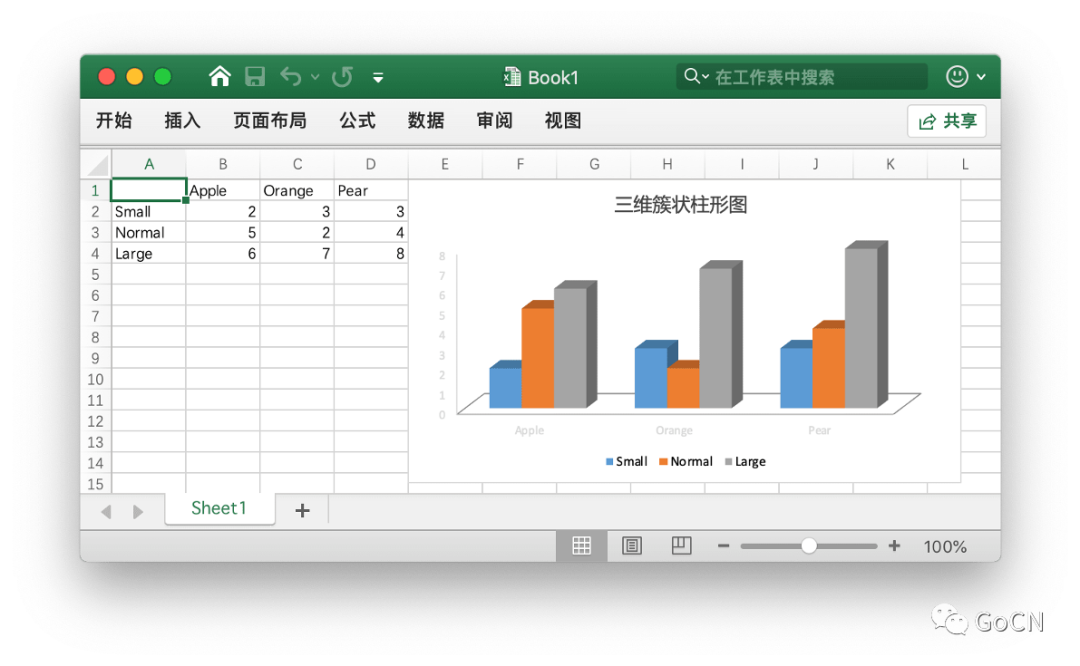
f, err := excelize.OpenFile("Book1.xlsx")if err != nil {fmt.Println(err)return}f.AddChart("Sheet1", "E1", `{"type": "col3DClustered","series": [{"name": "Sheet1!$A$2","categories": "Sheet1!$B$1:$D$1","values": "Sheet1!$B$2:$D$2"},{"name": "Sheet1!$A$3","categories": "Sheet1!$B$1:$D$1","values": "Sheet1!$B$3:$D$3"},{"name": "Sheet1!$A$4","categories": "Sheet1!$B$1:$D$1","values": "Sheet1!$B$4:$D$4"}],"title": { "name": "三维簇状柱形图" }}`)
数据透视
数据透视表是一种交互式的表,是计算、汇总和分析数据的强大工具,可以帮助我们了解数据中的对比情况、模式和趋势。通过 Excelize 提供的 AddPivotTable API 我们在一个包含 5 列源数据的工作表上创建一个数据透视表:
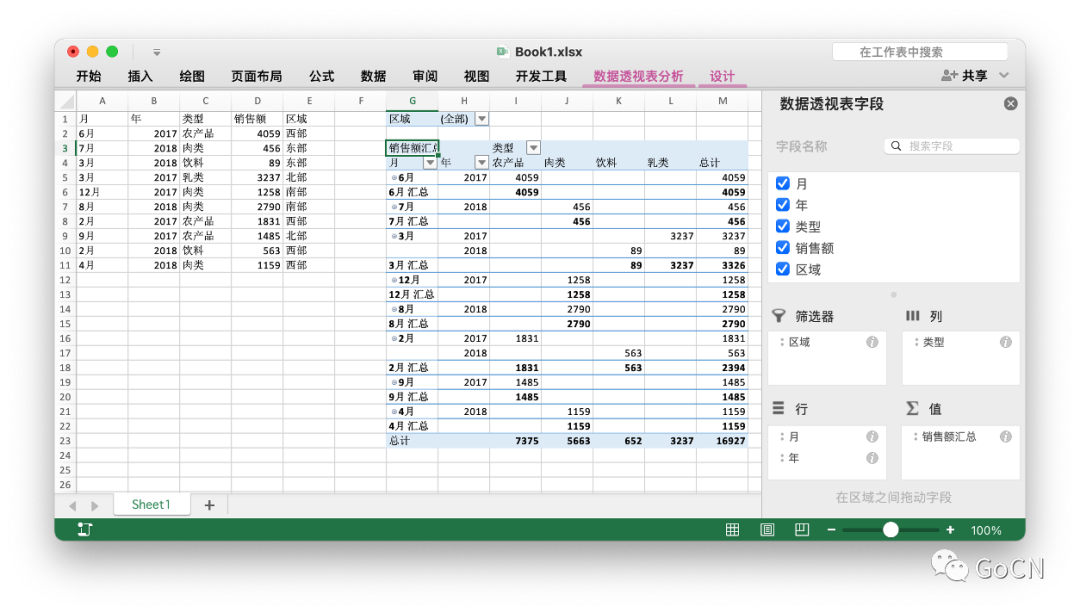
f.AddPivotTable(&excelize.PivotTableOption{DataRange: "Sheet1!$A$1:$E$31",PivotTableRange: "Sheet1!$G$2:$M$24",Rows: []excelize.PivotTableField{{Data: "月",DefaultSubtotal: true},{Data: "年"}},Filter: []excelize.PivotTableField{{Data: "区域"}},Columns: []excelize.PivotTableField{{Data: "类型",DefaultSubtotal: true}},Data: []excelize.PivotTableField{{Data: "销售额",Name: "销售额汇总",Subtotal: "Sum"}},RowGrandTotals: true,ColGrandTotals: true,ShowDrill: true,ShowRowHeaders: true,ShowColHeaders: true,ShowLastColumn: true,})
PivotTableOption 中可以指定数据透视表中的字段、筛选项、行/列数据、聚合维度等多种分析条件。上面的例子实现了按月对各区域在售的商品销售额进行分类汇总,并支持按销售区域、时间和分类进行筛选。
大规模数据处理
NewStreamWriter API 创建了一个流式写入器,接着创建了字体样式,并按行将数据写入工作表中,与此同时还可以指定单元格的样式,写入结束后调用 Flush 结束流式写入过程,创建了一个包含 102400 行 * 50 列累计 512 万单元格的工作表。对于需要生成大规模数据的场景,流式 API 相比普通写入在耗时和内存占用方面都有明显的优势。streamWriter, err := file.NewStreamWriter("Sheet1")if err != nil {fmt.Println(err)}styleID, err := file.NewStyle(`{"font":{"color":"#777777"}}`)if err != nil {fmt.Println(err)}if err := streamWriter.SetRow("A1",[]interface{}{excelize.Cell{StyleID: styleID, Value: "Data",},}); err != nil {fmt.Println(err)}for rowID := 2; rowID <= 102400; rowID++ {row := make([]interface{}, 50)for colID := 0; colID < 50; colID++ {row[colID] = rand.Intn(640000)}cell, _ := excelize.CoordinatesToCellName(1,rowID)if err := streamWriter.SetRow(cell,row); err != nil {fmt.Println(err)}}streamWriter.Flush()
与 Web 应用集成
func main() {http.HandleFunc("/process", process)http.ListenAndServe(":8090", nil)}
OpenReader API 打开数据流,接着在内存中对电子表格进行处理:func process(w http.ResponseWriter, req *http.Request) {file, _, err := req.FormFile("file")if err != nil {fmt.Fprintf(w, err.Error())return}defer file.Close()f, err := excelize.OpenReader(file)if err != nil {fmt.Fprintf(w, err.Error())return}f.NewSheet("NewSheet")w.Header().Set("Content-Disposition","attachment; filename=Book1.xlsx")w.Header().Set("Content-Type",req.Header.Get("Content-Type"))if _, err := f.WriteTo(w); err != nil {fmt.Fprintf(w, err.Error())}return}
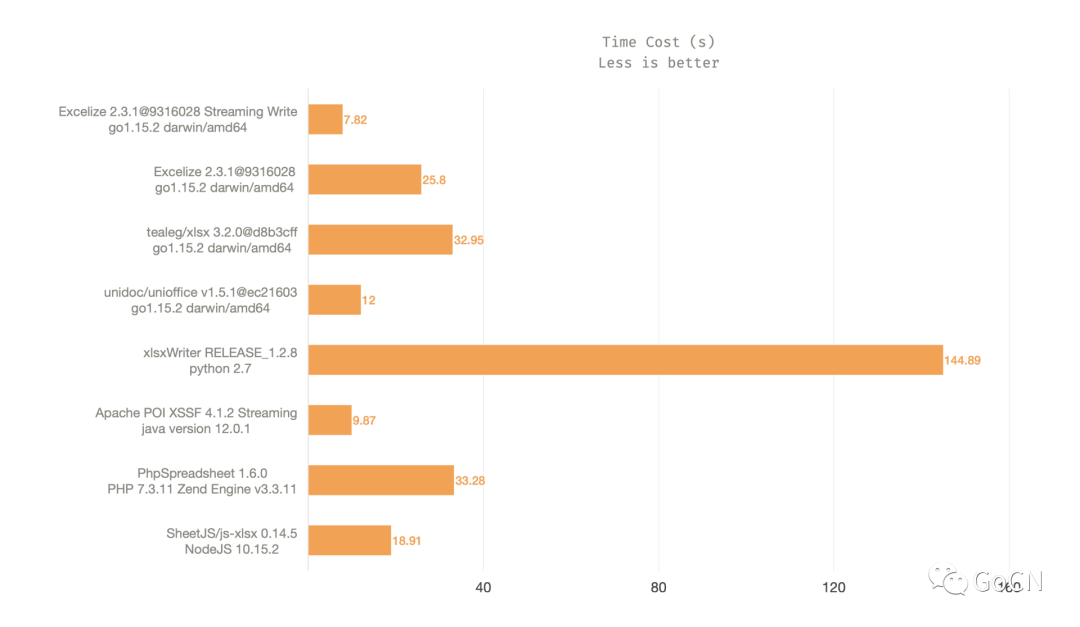
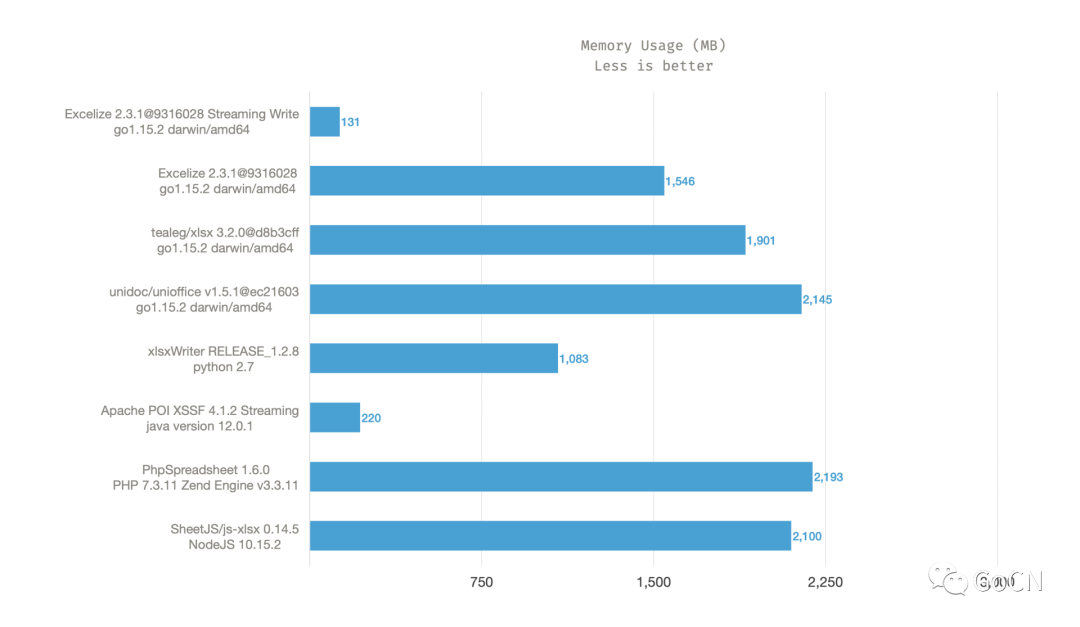
性能表现
评论