
OpenCV双目稠密匹配BM算法源代码详细解析
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自:视觉算法
template <typename mType>static voidfindStereoCorrespondenceBM( const Mat& left, const Mat& right,
Mat& disp, Mat& cost, const StereoBMParams& state,
uchar* buf, int _dy0, int _dy1, const int disp_shift ){
// opencv代码的特点:1.空间换时间:申请足够大的内存,预先计算出可以复用的数据并保存,后期直接查表使用; // 2.非常好地定义和使用了各种指针和申请的内存。
const int ALIGN = 16;
int x, y, d;
int wsz = state.SADWindowSize, wsz2 = wsz/2;
int dy0 = MIN(_dy0, wsz2+1), dy1 = MIN(_dy1, wsz2+1); // dy0, dy1 是滑动窗口中心点到窗口第一行和最后一行的距离, // 由于一般使用奇数大小的方形窗口,因此可以认为dy0 = dy1 = wsz2 int ndisp = state.numDisparities;
int mindisp = state.minDisparity;
int lofs = MAX(ndisp - 1 + mindisp, 0);
int rofs = -MIN(ndisp - 1 + mindisp, 0);
int width = left.cols, height = left.rows;
int width1 = width - rofs - ndisp + 1;
int ftzero = state.preFilterCap; // 这里是前面预处理做x方向的sobel滤波时的截断值,默认为31. // 预处理的结果并不是sobel滤波的直接结果,而是做了截断: // 滤波后的值如果小于-preFilterCap,则说说明纹理较强,结果为0; // 如果大于preFilterCap,则说明纹理强,结果为2*prefilterCap; // 如果滤波后结果在[-prefilterCap, preFilterCap]之间(区间表示,下同),对应取[0, 2*preFilterCap]。 int textureThreshold = state.textureThreshold;
int uniquenessRatio = state.uniquenessRatio;
mType FILTERED = (mType)((mindisp - 1) << disp_shift);
int *sad, *hsad0, *hsad, *hsad_sub, *htext;
uchar *cbuf0, *cbuf;
const uchar* lptr0 = left.ptr() + lofs;
const uchar* rptr0 = right.ptr() + rofs;
const uchar *lptr, *lptr_sub, *rptr;
mType* dptr = disp.ptr<mType>();
int sstep = (int)left.step;
int dstep = (int)(disp.step/sizeof(dptr[0]));
int cstep = (height+dy0+dy1)*ndisp;
int costbuf = 0;
int coststep = cost.data ? (int)(cost.step/sizeof(costbuf)) : 0;
const int TABSZ = 256;
uchar tab[TABSZ];
sad = (int*)alignPtr(buf + sizeof(sad[0]), ALIGN); // 注意到sad的前面留了一个sizeof(sad[0])的位置,函数最后要用到。 hsad0 = (int*)alignPtr(sad + ndisp + 1 + dy0*ndisp, ALIGN); // 这里额外说一句,opencv每次确定变量的字节数时都直接使用变量而不是int, double等类型, // 这样当变量类型变化时可以少修改代码。 htext = (int*)alignPtr((int*)(hsad0 + (height+dy1)*ndisp) + wsz2 + 2, ALIGN);
cbuf0 = (uchar*)alignPtr((uchar*)(htext + height + wsz2 + 2) + dy0*ndisp, ALIGN);
// 建立映射表,方便后面直接引用。以之前的x方向的sobel滤波的截断值为中心,距离这个截断值越远,说明纹理越强。 for( x = 0; x < TABSZ; x++ )
tab[x] = (uchar)std::abs(x - ftzero);
// initialize buffers memset( hsad0 - dy0*ndisp, 0, (height + dy0 + dy1)*ndisp*sizeof(hsad0[0]) );
memset( htext - wsz2 - 1, 0, (height + wsz + 1)*sizeof(htext[0]) );
// 首先初始化计算左图 x 在[-wsz2 - 1, wsz2), y 在[-dy0, height + dy1) 范围内的各个像素, // 右图视差为[0. ndisp)像素之间的SAD.
// 注意这里不处理 wsz2 列,并且是从-wsz2 - 1 列开始,(这一列不在第一个窗口[-wsz2, wsz2]中), // 这是为了后续处理时逻辑统一和代码简化的需要。这样就可以在处理第一个滑动窗口时和处理之后的窗口一样, // 剪掉滑出窗口的第一列的数据 (-wsz2 - 1),加上新一列的数据 (wsz2)。 for( x = -wsz2-1; x < wsz2; x++ )
{
// 统一先往上减去半个窗口乘以ndisp的距离。 hsad = hsad0 - dy0*ndisp; // 结合下面的循环代码和内存示意图,hsad是累加的,每次回退dy0就好。 cbuf = cbuf0 + (x + wsz2 + 1)*cstep - dy0*ndisp; // 而cbuf, lptr, rptr 需要根据当前在不同x列的需要,移动指针指向当前所处理的列。 lptr = lptr0 + std::min(std::max(x, -lofs), width-lofs-1) - dy0*sstep; // 前面的min, max 是为了防止内存越界而进行的判断。 rptr = rptr0 + std::min(std::max(x, -rofs), width-rofs-ndisp) - dy0*sstep;
// 从SAD窗口的第一个像素开始。 // 循环都是以当前列为主,先处理当前列不同行的像素。 for( y = -dy0; y < height + dy1; y++, hsad += ndisp, cbuf += ndisp, lptr += sstep, rptr += sstep )
{
int lval = lptr[0];
d = 0;
// 计算不同视差d 的SAD。 for( ; d < ndisp; d++ )
{
int diff = std::abs(lval - rptr[d]); // SAD. cbuf[d] = (uchar)diff; // 存储该列所有行各个像素在所有视差下的sad,所以cbuf的大小为wsz * cstep. hsad[d] = (int)(hsad[d] + diff); // 累加同一行内,[-wsz2 - 1, wsz2) 像素,不同d下的SAD(预先进行一点cost aggregation)。 }
htext[y] += tab[lval]; // 利用之前的映射表,统计一行内,窗口大小宽度,左图像素的纹理度。 // 注意到y是从-dy0开始的,而前面buf分配指针位置、hsad0和htext初始化为0的时候已经考虑到这一点了, // 特别是分配各个指针指向的内存大小的时候,分别都分配了下一个指针变量要往上减去的对应的内存大小。 // 读者可以自己回去看alighPtr语句部分和memset部分。 }
}
// initialize the left and right borders of the disparity map // 初始化图像左右边界。 for( y = 0; y < height; y++ )
{
for( x = 0; x < lofs; x++ )
dptr[y*dstep + x] = FILTERED;
for( x = lofs + width1; x < width; x++ )
dptr[y*dstep + x] = FILTERED;
}
dptr += lofs; // 然后就可以跳过初始化的部分了。
// 进入主循环,滑动窗口法进行匹配。注意到该循环很大,包含了很多内循环。 for( x = 0; x < width1; x++, dptr++ )
{
int* costptr = cost.data ? cost.ptr<int>() + lofs + x : &costbuf;
int x0 = x - wsz2 - 1, x1 = x + wsz2; // 窗口的首尾x坐标。 // 同上,所有指针从窗口的第一行开始,即-dy0行。 // 由于之前已经初始化计算过了,x从0开始循环。 // cbuf_sub 从cbuf0 的第0行开始,cbuf在cbuf0的最后一行;下一次循环是cbuf_sub在第1行,cbuf在第0行,以此类推,存储了窗口宽度内,每一列的SAD. const uchar* cbuf_sub = cbuf0 + ((x0 + wsz2 + 1) % (wsz + 1))*cstep - dy0*ndisp;
cbuf = cbuf0 + ((x1 + wsz2 + 1) % (wsz + 1))*cstep - dy0*ndisp;
hsad = hsad0 - dy0*ndisp;
// 这里了同样地,lptr_sub 从上一个窗口的最后一列开始,即x - wsz2 - 1,lptr从当前窗口的最后一列开始,即x + wsz2. lptr_sub = lptr0 + MIN(MAX(x0, -lofs), width-1-lofs) - dy0*sstep;
lptr = lptr0 + MIN(MAX(x1, -lofs), width-1-lofs) - dy0*sstep;
rptr = rptr0 + MIN(MAX(x1, -rofs), width-ndisp-rofs) - dy0*sstep;
// 只算x1列,y 从-dy0到height + dy1 的SAD,将之更新到对应的变量中。 for( y = -dy0; y < height + dy1; y++, cbuf += ndisp, cbuf_sub += ndisp,
hsad += ndisp, lptr += sstep, lptr_sub += sstep, rptr += sstep )
{
int lval = lptr[0];
d = 0;
for( ; d < ndisp; d++ )
{
int diff = std::abs(lval - rptr[d]); // 当前列的SAD. cbuf[d] = (uchar)diff;
hsad[d] = hsad[d] + diff - cbuf_sub[d]; // 累加新一列各个像素不同d下的SAD,减去滑出窗口的那一列对应的SAD. }
htext[y] += tab[lval] - tab[lptr_sub[0]]; // 同上。 }
// fill borders for( y = dy1; y <= wsz2; y++ )
htext[height+y] = htext[height+dy1-1];
for( y = -wsz2-1; y < -dy0; y++ )
htext[y] = htext[-dy0];
// initialize sums // 将hsad0存储的第-dy0列的数据乘以2拷贝给sad. for( d = 0; d < ndisp; d++ )
sad[d] = (int)(hsad0[d-ndisp*dy0]*(wsz2 + 2 - dy0));
// 将hsad指向hsad0的第1-dy0行,循环也从1-dy0行开始,并且只处理窗口大小内的数据(到wsz2 - 1为止)。 // 不处理wsz2行和之前不处理wsz2列的原因是一样的。 hsad = hsad0 + (1 - dy0)*ndisp;
for( y = 1 - dy0; y < wsz2; y++, hsad += ndisp )
{
d = 0;
// cost aggregation 步骤 // 累加不同行、一个滑动窗口内各个像素取相同d 时的SAD。 for( ; d < ndisp; d++ )
sad[d] = (int)(sad[d] + hsad[d]);
}
// 循环累加一个滑动窗口内的纹理值。 int tsum = 0;
for( y = -wsz2-1; y < wsz2; y++ )
tsum += htext[y];
// finally, start the real processing // 虽然官方注释说现在才开始真正的处理,但之前已经做了大量的处理工作了。 for( y = 0; y < height; y++ )
{
int minsad = INT_MAX, mind = -1;
hsad = hsad0 + MIN(y + wsz2, height+dy1-1)*ndisp; // 当前窗口的最后一行。 hsad_sub = hsad0 + MAX(y - wsz2 - 1, -dy0)*ndisp; // 上个窗口的最后一行。 d = 0;
// 寻找最优视差。 for( ; d < ndisp; d++ )
{
int currsad = sad[d] + hsad[d] - hsad_sub[d]; // 同上,加上最后一行的SAD,减去滑出那一行的SAD. // 之前给sad赋值时为何要乘以2也就清楚了。一样是为了使处理第一个窗口的SAD之和时和之后的窗口相同, // 可以剪掉第一行的SAD,加上新一行的SAD。所以必须乘以2防止计算第一个窗口是漏算了第一行。
sad[d] = currsad; // 更新当前d下的SAD之和,方便下次计算使用。 if( currsad < minsad )
{
minsad = currsad;
mind = d;
}
}
tsum += htext[y + wsz2] - htext[y - wsz2 - 1]; // 同样需要更新纹理值。 // 如果一个像素附近的纹理太弱,则视差计算认为无效。 if( tsum < textureThreshold )
{
dptr[y*dstep] = FILTERED;
continue;
}
// 唯一性匹配。 // 对于前面找到的最优视差mind,及其SAD minsad,自适应阈值为minsad * (1 + uniquenessRatio). // 要求除了mind 前后一个视差之外,其余的视差的SAD都必须比阈值大,否则认为找到的视差无效。 if( uniquenessRatio > 0 )
{
int thresh = minsad + (minsad * uniquenessRatio/100);
for( d = 0; d < ndisp; d++ )
{
if( (d < mind-1 || d > mind+1) && sad[d] <= thresh)
break;
}
if( d < ndisp )
{
dptr[y*dstep] = FILTERED;
continue;
}
}
{
// 最后,经过层层校验,终于确定了当前像素的视差。 // 回顾之前sad指针在确定其指针位置和指向的大小时,前后都留了一个位置,在这里用到了。 sad[-1] = sad[1];
sad[ndisp] = sad[ndisp-2];
// 这里留两个位置的作用就很明显了:防止mind为0或ndis-1时下面的语句数组越界。 int p = sad[mind+1], n = sad[mind-1];
d = p + n - 2*sad[mind] + std::abs(p - n);
// 注意到前面将dptr的位置加上了lofs位,所以这里下标为y * dstep。 dptr[y*dstep] = (mType)(((ndisp - mind - 1 + mindisp)*256 + (d != 0 ? (p-n)*256/d : 0) + 15) // 这里如果读者留心,会发现之前计算视差d时,计算结果是反过来的。 // 即d=0时,理论上右图像素应该是和左图像素相同的x坐标, // 但其实之前在设置rptr是,此时右图像素的x坐标为x-(ndisp-1), // 因此这里所算的视差要反转过来,为ndisp-mind-1。 // 常数15是因为opencv默认输出类型为16位整数,后面为了获得真正的视差要除以16, // 这里加的一个针对整数类型除法截断的一个保护。 // 至于为何多了一个(p-n)/d,我也不太懂,应该是针对所计算的SAD的变化率的一个补偿,希望有人可以指点下:) >> (DISPARITY_SHIFT_32S - disp_shift));
costptr[y*coststep] = sad[mind]; // 最后opencv默认得到的视差值需要乘以16,所以前面乘以256,后面在右移4位。 }
} // y
}// x}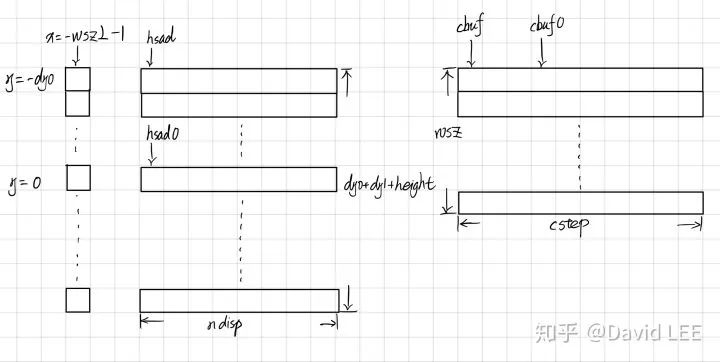
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论