
预测过去?DeepMind用AI复原古希腊铭文,登Nature封面

来源:机器之心 本文约2400字,建议阅读9分钟
用深度神经网络(DNN)修复受损的古希腊铭文,DeepMind 探索 AI 与古文字学的融合。

论文地址: https://www.nature.com/articles/s41586-022-04448-z GitHub 地址: https://github.com/deepmind/ithaca
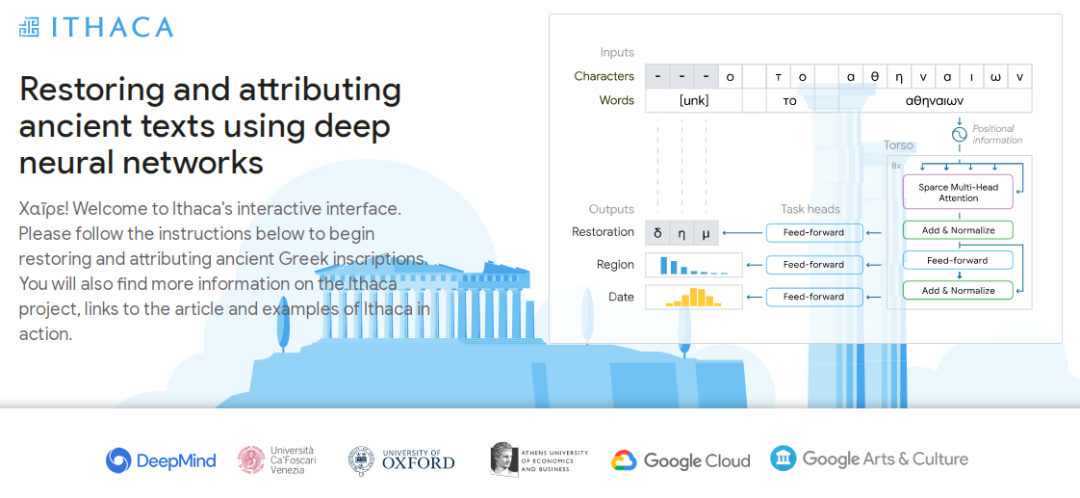

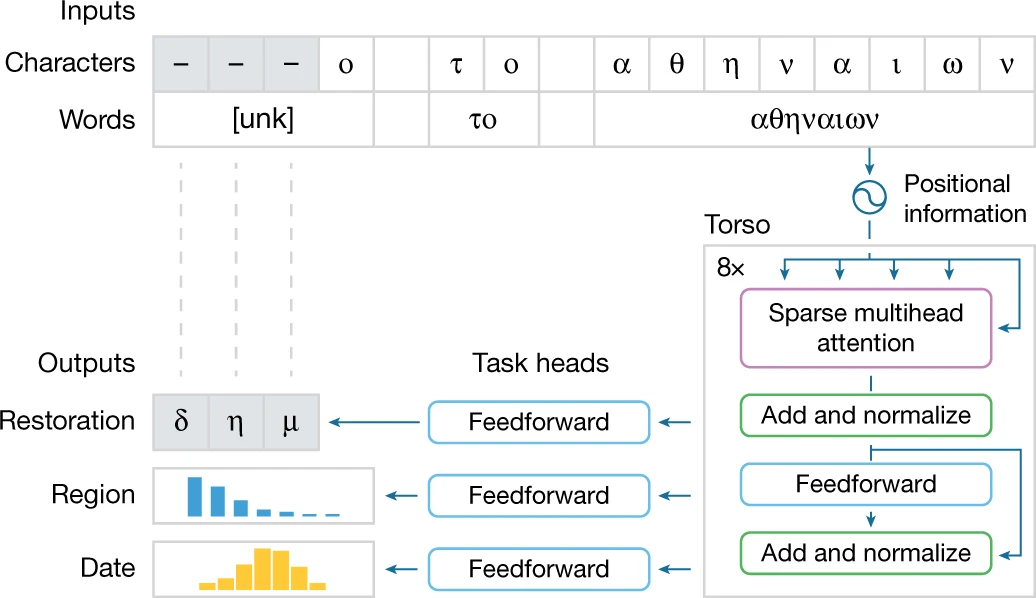
 。提供输入后,Ithaca 恢复了文本,并识别出文本编写的时间和地点。
。提供输入后,Ithaca 恢复了文本,并识别出文本编写的时间和地点。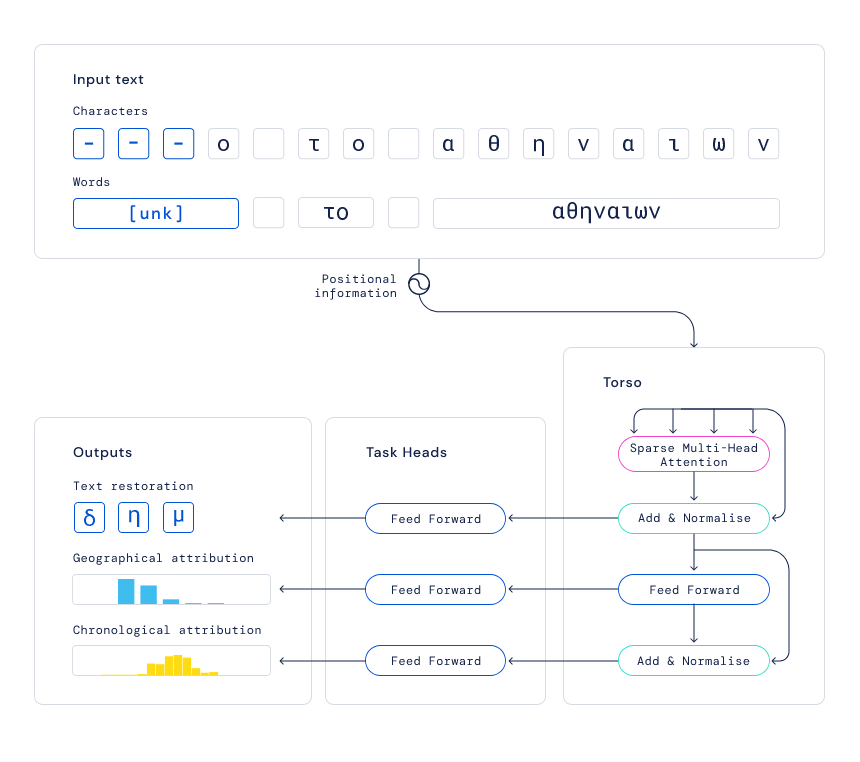
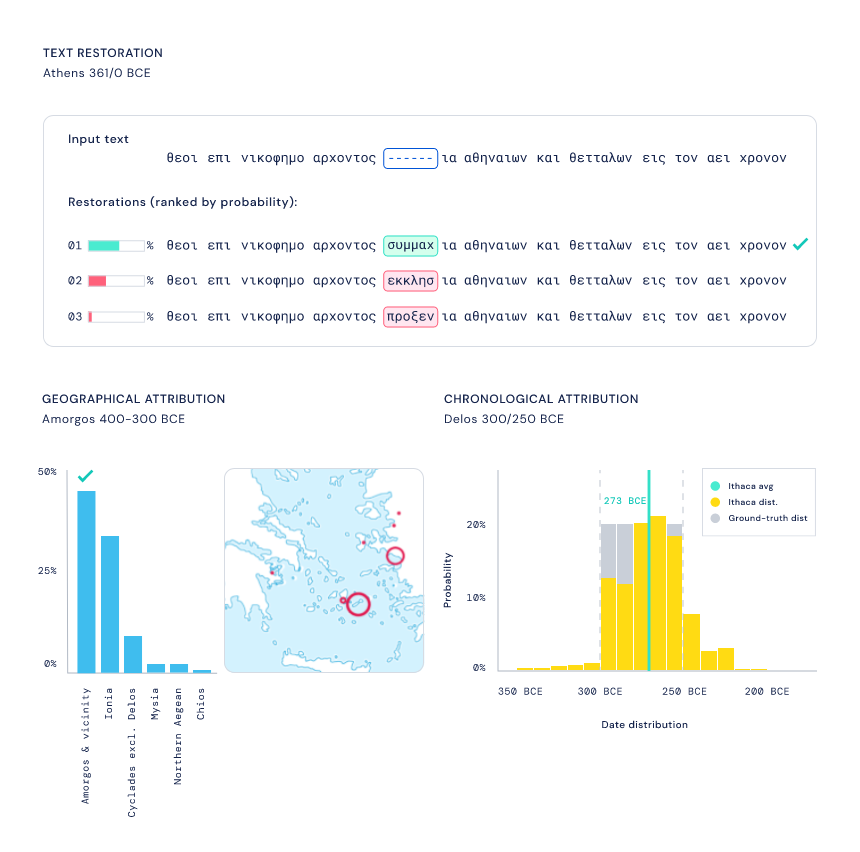
恢复假设:Ithaca 为文本修复任务生成几个预测假设,供历史学家利用自身专业知识进行选择; 地理归属:Ithaca 通过为历史学家提供所有可能预测的概率分布来显示其不确定性,而不仅仅是单个输出。因此,Ithaca 返回代表其确定性水平的 84 个不同古代区域的概率。可以在地图上将这些结果可视化,以阐明古代世界可能存在的潜在地理联系; 时间归属:当需要确定一篇文献的年代时,Ithaca 会产生从公元前 800 年到公元 800 年预测日期分布,这可以使历史学家了解模型对特定日期范围的可信度,提供有价值的历史见解; 显着图:为了将结果传达给历史学家,Ithaca 使用计算机视觉中常用的一种技术来识别哪些输入序列对预测的贡献最大,输出以不同颜色强度突出 Ithaca 预测缺失文本、地点和日期的单词。


评论