
SpringBoot 的多数据源配置

2020-12-29 杭州 雪
最近在项目开发中,需要为一个使用 MySQL 数据库的 SpringBoot 项目,新添加一个 PLSQL 数据库数据源,那么就需要进行 SpringBoot 的多数据源开发。代码很简单,下面是实现的过程。
环境准备
实验环境:
JDK 1.8 SpringBoot 2.4.1 Maven 3.6.3 MySQL 5.7
因为我本地只有 MySQL 数据库,为了方便演示,我会在启动一个本地 MySQL,在 MySQL 创建两个数据库,每个库中均有一个表,以此进行演示。
数据准备
本地 MySQL 端口默认不做改动,端口号 3306。
创建数据库 demo1,demo2。在 demo1 数据库中创建表 book。
-- create table
create table Book
(
id int auto_increment
primary key,
author varchar(64) not null comment '作者信息',
name varchar(64) not null comment '书籍名称',
price decimal not null comment '价格',
createTime datetime null comment '上架时间',
description varchar(128) null comment '书籍描述'
);
-- insert data
INSERT INTO demo1.Book (id, author, name, price, createTime, description) VALUES (1, '金庸', '笑傲江湖', 13, '2020-12-19 15:26:51', '武侠小说');
INSERT INTO demo1.Book (id, author, name, price, createTime, description) VALUES (2, '罗贯中', '三国演义', 14, '2020-12-19 15:28:36', '历史小说');
在 demo2 数据库中创建表 user。
-- create table
create table User
(
id int auto_increment
primary key,
name varchar(32) null comment '用户名称',
birthday date null comment '出生日期'
)
comment '用户信息表';
-- insert data
INSERT INTO demo2.User (id, name, birthday) VALUES (1, '金庸', '1924-03-10');
INSERT INTO demo2.User (id, name, birthday) VALUES (2, '罗贯中', '1330-01-10');
数据准备完毕,表中都新增了两条数据。
项目准备
这里直接从 Spring 官方上初始化一个添加了 web、lombok、mybatis、mysql 依赖的 SpringBoot 项目。
访问直接下载:
https://start.spring.io/starter.zip?type=maven-project&language=java&bootVersion=2.4.1.RELEASE&baseDir=demo&groupId=com&artifactId=wdbyte&name=demo&description=Demo%20project%20for%20Spring%20Boot&packageName=com.wdbyte.demo&packaging=jar&javaVersion=1.8&dependencies=mybatis,lombok,web,mysql
如果你手上已经有了一个 SpringBoot 项目,既然你想改造成多数据源,那么你应该已经有了一个数据源了,如果新增的数据源数据库和目前的一致,你可以直接使用你的项目进行改造测试。
多数据源
SpringBoot 的多数据源开发十分简单,如果多个数据源的数据库相同,比如都是 MySQL,那么依赖是不需要任何改动的,只需要进行多数据源配置即可。
如果你新增的数据库数据源和目前的数据库不同,记得引入新数据库的驱动依赖,比如 MySQL 和 PGSQL。
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<scope>runtimescope>
dependency>
<dependency>
<groupId>org.postgresqlgroupId>
<artifactId>postgresqlartifactId>
<version>42.2.7version>
dependency>
连接配置
既然有多个数据源,因为数据库用户名密码可能不相同,所以是需要配置多个数据源信息的,直接在 properties/yml 中配置即可。这里要注意根据配置的属性名进行区分,同时因为数据源要有一个默认使用的数据源,最好在名称上有所区分(这里使用 primary 作为主数据源标识)。
########################## 主数据源 ##################################
spring.datasource.primary.jdbc-url=jdbc:mysql://127.0.0.1:3306/demo1?characterEncoding=utf-8&serverTimezone=GMT%2B8
spring.datasource.primary.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.primary.username=root
spring.datasource.primary.password=
########################## 第二个数据源 ###############################
spring.datasource.datasource2.jdbc-url=jdbc:mysql://127.0.0.1:3306/demo2?characterEncoding=utf-8&serverTimezone=GMT%2B8
spring.datasource.datasource2.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.datasource2.username=root
spring.datasource.datasource2.password=
# mybatis
mybatis.mapper-locations=classpath:mapper/*.xml
mybatis.type-aliases-package=com.wdbyte.domain
注意,配置中的数据源连接 url 末尾使用的是 jdbc-url.
因为使用了 Mybatis 框架,所以 Mybatis 框架的配置信息也是少不了的,指定扫描目录 mapper 下的mapper xml 配置文件。
Mybatis 配置
如何编写 Mybatis Mapper 或者如何使用工具生成 Mybatis Mapper 不是本文的重点,如果你不知道可以参考 Mybatis 官方文档或者我之前的文章。
链接二:使用 Mybatis 集成 pagehelper 分页插件和 mapper 插件
下面我已经按照上面的两个库中的两个表,Book 和 User 表分别编写相应的 Mybatis 配置。
创建 BookMapper.xml 和 UserMapper.xml 放到配置文件配置的路径 mapper 目录下。创建 UserMapper 和 BookMapper 接口操作类放在不同的目录。这里注意 Mapper 接口要按数据源分开放在不同的目录中。后续好使用不同的数据源配置扫描不同的目录,这样就可以实现不同的 Mapper 使用不同的数据源配置。
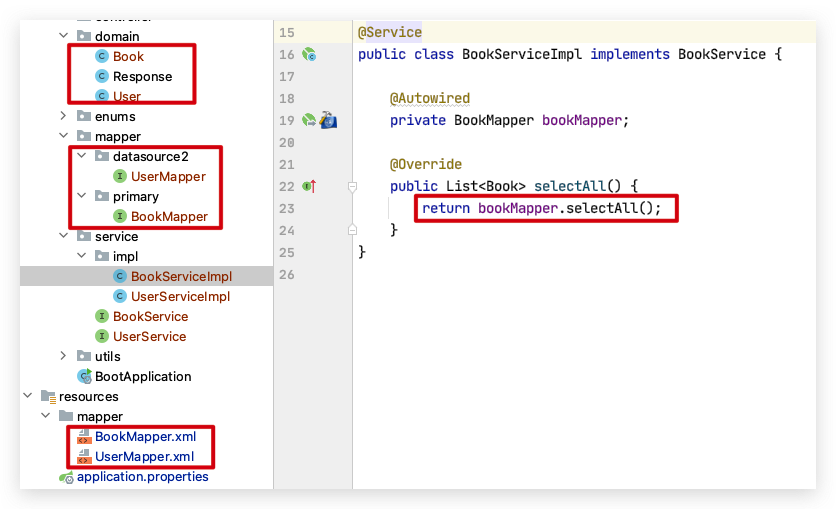
Service 层没有变化,这里 BookMapper 和 UserMapper 都有一个 selectAll() 方法用于查询测试。
多数据源配置
上面你应该看到了,到目前为止和 Mybatis 单数据源写法唯一的区别就是 Mapper 接口使用不同的目录分开了,那么这个不同点一定会在数据源配置中体现。
主数据源
开始配置两个数据源信息,先配置主数据源,配置扫描的 MapperScan 目录为 com.wdbyte.mapper.primary
/**
* 主数据源配置
*
* @author niujinpeng
* @website: https://www.wdbyte.com
* @date 2020/12/19
*/
@Configuration
@MapperScan(basePackages = {"com.wdbyte.mapper.primary"}, sqlSessionFactoryRef = "sqlSessionFactory")
public class PrimaryDataSourceConfig {
@Bean(name = "dataSource")
@ConfigurationProperties(prefix = "spring.datasource.primary")
@Primary
public DataSource dataSource() {
return DataSourceBuilder.create().build();
}
@Bean(name = "sqlSessionFactory")
@Primary
public SqlSessionFactory sqlSessionFactory(@Qualifier("dataSource") DataSource dataSource) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(dataSource);
bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:mapper/*.xml"));
return bean.getObject();
}
@Bean(name = "transactionManager")
@Primary
public DataSourceTransactionManager transactionManager(@Qualifier("dataSource") DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
@Bean(name = "sqlSessionTemplate")
@Primary
public SqlSessionTemplate sqlSessionTemplate(@Qualifier("sqlSessionFactory") SqlSessionFactory sqlSessionFactory) {
return new SqlSessionTemplate(sqlSessionFactory);
}
}
和单数据源不同的是这里把
dataSourcesqlSessionFactorytransactionManagersqlSessionTemplate
都单独进行了配置,简单的 bean 创建,下面是用到的一些注解说明。
@ConfigurationProperties(prefix = "spring.datasource.primary"):使用spring.datasource.primary 开头的配置。@Primary:声明这是一个主数据源(默认数据源),多数据源配置时必不可少。@Qualifier:显式选择传入的 Bean。
第二个数据源
第二个数据源和主数据源唯一不同的只是 MapperScan 扫描路径和创建的 Bean 名称,同时没有 @Primary 主数据源的注解。
/**
* 第二个数据源配置
*
* @author niujinpeng
* @website: https://www.wdbyte.com
* @date 2020/12/19
*/
@Configuration
@MapperScan(basePackages = {"com.wdbyte.mapper.datasource2"}, sqlSessionFactoryRef = "sqlSessionFactory2")
public class SecondDataSourceConfig {
@Bean(name = "dataSource2")
@ConfigurationProperties(prefix = "spring.datasource.datasource2")
public DataSource dataSource() {
return DataSourceBuilder.create().build();
}
@Bean(name = "sqlSessionFactory2")
public SqlSessionFactory sqlSessionFactory(@Qualifier("dataSource2") DataSource dataSource) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(dataSource);
bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:mapper/*.xml"));
return bean.getObject();
}
@Bean(name = "transactionManager2")
public DataSourceTransactionManager transactionManager(@Qualifier("dataSource2") DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
@Bean(name = "sqlSessionTemplate2")
public SqlSessionTemplate sqlSessionTemplate(@Qualifier("sqlSessionFactory2") SqlSessionFactory sqlSessionFactory) {
return new SqlSessionTemplate(sqlSessionFactory);
}
}
注意:因为已经在两个数据源中分别配置了扫描的 Mapper 路径,如果你之前在 SpringBoot 启动类中也使用了 Mapper 扫描注解,需要删掉。
访问测试
编写两个简单的查询 Controller 然后进行访问测试。
// BookController
@RestController
public class BookController {
@Autowired
private BookService bookService;
@GetMapping(value = "/books")
public Response selectAll() throws Exception {
List books = bookService.selectAll();
return ResponseUtill.success(books);
}
}
// UserController
@RestController
public class UserController {
@Autowired
private UserService userService;
@ResponseBody
@GetMapping(value = "/users")
public Response selectAll() {
List userList = userService.selectAll();
return ResponseUtill.success(userList);
}
}
访问测试,我这里直接 CURL 请求。
➜ ~ curl localhost:8080/books
{
"code": "0000",
"message": "success",
"data": [
{
"id": 1,
"author": "金庸",
"name": "笑傲江湖",
"price": 13,
"createtime": "2020-12-19T07:26:51.000+00:00",
"description": "武侠小说"
},
{
"id": 2,
"author": "罗贯中",
"name": "三国演义",
"price": 14,
"createtime": "2020-12-19T07:28:36.000+00:00",
"description": "历史小说"
}
]
}
➜ ~ curl localhost:8080/users
{
"code": "0000",
"message": "success",
"data": [
{
"id": 1,
"name": "金庸",
"birthday": "1924-03-09T16:00:00.000+00:00"
},
{
"id": 2,
"name": "罗贯中",
"birthday": "1330-01-09T16:00:00.000+00:00"
}
]
}
➜ ~
至此,多数据源配置完成,测试成功。
连接池
其实在多数据源改造中,我们一般情况下都不会使用默认的 JDBC 连接方式,往往都需要引入连接池进行连接优化,不然你可能会经常遇到数据源连接被断开等报错日志。其实数据源切换连接池数据源也是十分简单的,直接引入连接池依赖,然后把创建 dataSource 的部分换成连接池数据源创建即可。
下面以阿里的 Druid 为例,先引入连接池数据源依赖。
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druidartifactId>
dependency>
添加 Druid 的一些配置。
spring.datasource.datasource2.initialSize=3 # 根据自己情况设置
spring.datasource.datasource2.minIdle=3
spring.datasource.datasource2.maxActive=20
改写 dataSource Bean 的创建代码部分。
@Value("${spring.datasource.datasource2.jdbc-url}")
private String url;
@Value("${spring.datasource.datasource2.driver-class-name}")
private String driverClassName;
@Value("${spring.datasource.datasource2.username}")
private String username;
@Value("${spring.datasource.datasource2.password}")
private String password;
@Value("${spring.datasource.datasource2.initialSize}")
private int initialSize;
@Value("${spring.datasource.datasource2.minIdle}")
private int minIdle;
@Value("${spring.datasource.datasource2.maxActive}")
private int maxActive;
@Bean(name = "dataSource2")
public DataSource dataSource() {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl(url);
dataSource.setDriverClassName(driverClassName);
dataSource.setUsername(username);
dataSource.setPassword(password);
dataSource.setInitialSize(initialSize);
dataSource.setMinIdle(minIdle);
dataSource.setMaxActive(maxActive);
return dataSource;
}
这里只是简单的提一下使用连接池的重要性,Druid 的详细用法还请参考官方文档。
文中代码已经上传到 Github:
https://github.com/niumoo/springboot
推荐阅读:
欢迎关注微信公众号:互联网全栈架构,收取更多有价值的信息。