
12 个问题搞懂 Redis
都说学习需要带着问题,带着思考进行学习,下面就以问题的形式来学习下 Redis 。
1、什么是 Redis ?
Redis 是一个高性能的 key-value 数据库; 作者来自意大利西西里岛的 Salvatore Sanfilippo ; Redis 使用 ANSI C 语言编写、并遵守 BSD 开源协议; Redis 支持网络、可基于内存、分布式、也可以用来实现简易的消息队列; 提供丰富的数据结构:字符串(String)、哈希(Hash)、列表(list)、集合(sets)和有序集合(sorted sets) 。
2、都说 Redis 是单线程模型,到底是什么意思?
单线程并不是说在 Redis 中所有的操作都是由一个线程来完成; 核心功能,比如:网络 IO 和数据的读写是由一个线程来进行处理的; 其他的一些辅助功能,比如:持久化、集群间的数据同步是由单独的线程进行处理; 所以说 Redis 的单线程不是“真正”的单线程。
3、为什么在数据读写处理上不使用多线程?
多线程虽然可以增加系统的吞吐率,但线程的切换会有开销; 多个线程对共享资源的并发处理问题,必然会用到各种锁,有锁就会存在等待锁的释放,反而吞吐率降低了; 处理各种多线程带来的问题,会使系统变得复杂,复杂的系统就容易出现问题。
4、为什么使用单线程,速度却很快?
Redis 的操作是基于内存的,相比较于磁盘,速度上有先天的优势; Redis 有高效的数据结构,比如:哈希表、跳表; 采用了多路复用机制,可以并发处理大量的请求,实现高吞吐率。
5、单线程处理的瓶颈是什么?
如果有耗时长的操作,后面的请求都需要进行等待; 单个 value 的内容过大,在添加、获取、删除时都会比较耗时; 使用复杂的命令,比如:SORT/SUNION/ZUNIONSTORE; 集合的数据非常大,而又进行了全量查询。 并发量非常大时,虽然 IO 有多路复用机制,从内核缓冲区中拷贝数据的操作仍然是同步操作,会带来性能瓶颈。
6、Redis 6.0 调整为多线程的原因?
上面提到过 6.0 之前的版本是网络 IO 和数据读写是在一个线程中完成的; 随着硬件性能的提升,Redis 的性能瓶颈有时会出现在网络 IO 的处理上,也就是说,单个主线程处理网络请求的速度跟不上底层网络硬件的速度,而读写的操作和网络 IO 是在一个主线程中,势必会有所影响; 所以在 Redis 6.0 中,网络 IO 是由多个 IO 线程并行处理,可以充分利用服务器的多核资源,提高网络读写操作; Redis 数据的读写处理仍然在单个主线程中完成。
7、在 Redis 中怎样做持久化?
在 Redis 实现持久化有两种方式:AOF 日志 和 RDB 快照; AOF 日志 命令执行成功后,才记录日志; 命令执行后进行日志记录,不会堵塞当前的写操作。 命令执行完,日志记录前宕机,数据会丢失; AOF 日志在主线程中执行,有 IO 瓶颈时会对后面的操作有堵塞风险; 数据量比较大的时候,恢复很慢。 配置项(appendfsync) Always,同步写回磁盘:每个写命令执行完,立即同步将日志写回磁盘; Everysec,每秒写回磁盘:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,每隔一秒把缓冲区中的内容写入磁盘; No,操作系统控制的写回磁盘:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘。 RDB 快照
和 AOF 相比较,RDB 快照记录的是某一个时刻的数据,数据恢复是直接将 RDB 文件读入内存,速度很快;
生成 RDB 文件的两种方式:
save:在主线程中执行,会导致阻塞;
bgsave:创建一个子进程,专门用于写入 RDB 文件,避免了主线程的阻塞,这也是 Redis RDB 文件生成的默认配置。子进程是由主线程 fork 生成的,可以共享主线程的所有内存数据。
RDB 快照的间隔时间不宜设置过短,因为频繁进行 Redis 的全量快照,会带来性能问题:
前一个快照还没做完,后面一个开始了,会给磁盘带来压力;
bgsave 的子进程虽然不会阻塞主线程,但创建的过程会阻塞,频繁创建也会带来性能问题。
解决上面问题的一种办法就是使用增量快照;
在 Redis 4.0 中提出了一种混合 AOF 日志和 RDB 快照的方式:
RDB 快照的间隔时间可以设置比较大,就不会影响到主线程的操作;
在快照的间隔期间可以使用 AOF 日志记录所有的操作,当下一次做全量 RDB 快照的时候,清空 AOF 日志;
通过 aof-use-rdb-preamble yes 来进行设置。
8、常说的缓存雪崩、击穿、穿透是什么?
雪崩、击穿、穿透最终的结果都是请求压力会转移到数据库,导致系统崩溃,但场景有所区别; 雪崩 大量的不同请求无法在 Redis 中命中,导致请求都流向了数据库,数据库的压力剧增; 发生雪崩的原因可能是,有大量的缓存 Key 在同一时间过期。 击穿 并发很大的情况下,针对某个特定的请求,缓存中数据不存在,导致都请求到了数据库,造成数据库压力过大; 原因通常是某个 Key 过期了; 和雪崩相比较,击穿是针对的单个 Key。 穿透 缓存穿透是指请求的数据不在 Redis 缓存中,也不在数据库中,导致访问缓存时,找不到数据,会去请求数据库,而在数据库中也找不到相应的数据; 并发比较大的时候,数据库会遭受巨大的压力; 发生穿透的原因可能有两个: 误操作导致 Redis 和数据库中的数据都被删除了; 恶意攻击。
9、怎样解决雪崩、击穿、穿透带来的问题?
雪崩 缓存的数据过期时间设置随机,防止同一时间大量数据过期现象发生; 如果缓存数据库是分布式部署,将热数据均匀分布在不同缓存数据库中; 当发生雪崩时,可以通过服务降级来应对。 击穿 设置热数据永远不过期。 穿透 在接口层进行校验,将恶意请求直接过滤掉; 使用布隆过滤器快速判断数据是否存在; 缓存空值或缺省值。
10、怎样设计缓存的淘汰机制?
业务数据在不断地增长,不可能将所有数据全部存储在 Redis 缓存中,内存的价格远远大于磁盘。所以需要做淘汰机制的设计; 缓存的淘汰就是根据一定的策略,将不太重要的数据从缓存中进行删除; Redis 一共有 8 种淘汰策略,在 Redis 4.0 之前有 6 种,4.0 之后又增加了 2 种,如下图:
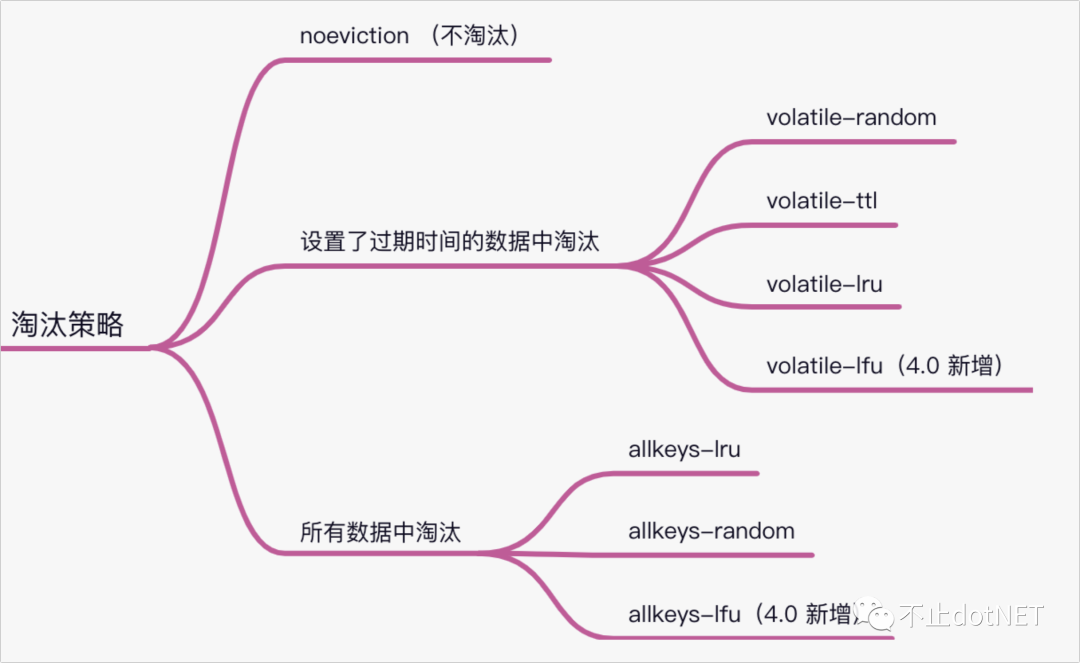
缓存策略的解释: volatile-random:在设置了过期时间的数据中,进行随机删除; volatile-ttl:根据过期时间,越早过期的数据越先删除; volatile-lru:在设置了过期时间的数据中,根据 LRU 算法进行数据删除; volatile-lfu:在设置了过期时间的数据中,根据 LFU 算法进行数据删除; allkeys-lru:在所有数据中,根据 LRU 算法进行数据删除; allkeys-random:在所有数据中,进行随机删除; allkeys-lfu:在所有数据中,根据 LFU 算法进行数据删除; 默认情况下,当 Redis 的使用空间超过 maxmemory 设置的大小时,并不会淘汰数据,也就是执行的 noeviction 策略,如果写满,再有写请求时就会出错; 如果业务中有明显的热数据和冷数据,优先使用 allkeys-lru 策略,让热数据保留在缓存中; 如果业务中没有明显冷热数据,可以使用 volatile-random 或 allkeys-random。
11、怎样保证缓存和数据库的数据一致?
缓存和数据库一致的意思是,当缓存中有数据时,缓存和数据库数据相同,当没有数据时,数据库中是最新的; 在做增删改操作的时候,对缓存的更新有两种方式: 新增直接添加到数据库,删除和修改时先更新缓存,然后同步或异步进行数据库的更新; 新增直接添加到数据库,删除和修改时先更新数据库,再删除对应的缓存。 上面的操作都涉及到两个,操作 Redis 和操作数据库,当其中一个成功一个失败时就会出现数据不一致的情况; 解决不一致的问题: 将操作通过消息队列异步处理,设置重试机制,保证最终的一致性; 使用分布式事务,保证操作 Redis 和数据库的两个操作在一个事务中。
12、Redis 有什么使用规范?
Redis 单实例的内存大小都不要设置太大,建议在 2~6GB ,设置太大,会导致 RDB 快照、从 AOF 日志恢复、主从集群进行数据同步等都会耗时很长,阻塞正常请求的处理; 对集合进行全量数据获取时,时间复杂度是 O(n),所以这个 n 不宜太大; 单个 key 的值不要太大,即便是最新的 6.0 版本,在读写这部分仍然是单线程,大 value 的读取会耗时,导致堵塞; 根据具体的业务特点设计好淘汰策略; 使用高效的序列化和压缩方法对缓存数据进行处理,来进一步提升性能; 生产环境中禁止使用 KEYS、FLUSHALL、FLUSHDB 等操作,数据量大的时候耗时长,会阻塞主线程; 有时为了排查错误,会使用 MONITOR 命令进行监控,该命令也会对性能造成严重影响;
Redis 的知识远不止如此,本文总结了一些我认为比较重要的一些点,希望对您有所帮助!