
深入解析常见三次握手异常
大家好,我是飞哥!
在后端接口性能指标中一类重要的指标就是接口耗时。具体包括平均响应时间 TP90、TP99 耗时值等。这些值越低越好,一般来说是几毫秒,或者是几十毫秒。如果响应时间一旦过长,比如超过了 1 秒,在用户侧就能感觉到非常明显的卡顿。如果长此以往,用户可能就直接用脚投票,卸载我们的 App 了。
在正常情况下一次 TCP 连接耗时也就大约是一次 RTT 多一点。但事情不一定总是这么美好,总会有意外发生。在某些情况下,可能会导致连接耗时上涨、CPU 处理开销增加、甚至是超时失败。
今天飞哥就来说一下我在线上遇到过的那些 TCP 握手相关的各种异常情况。
一、客户端 connect 异常
端口号和 CPU 消耗这二者听起来感觉没啥太大联系。但我却遭遇过因为端口号不足导致 CPU 消耗大幅上涨的情况。来听飞哥分析分析为啥会出现这种问题!
客户端在发起 connect 系统调用的时候,主要工作就是端口选择(参见TCP连接中客户端的端口号是如何确定的?)。
在选择的过程中,有个大循环,从 ip_local_port_range 的一个随机位置开始把这个范围遍历一遍,找到可用端口则退出循环。如果端口很充足,那么循环只需要执行少数几次就可以退出。但假设说端口消耗掉很多已经不充足,或者干脆就没有可用的了。那么这个循环就得执行很多遍。我们来看下详细的代码。
//file:net/ipv4/inet_hashtables.c
int __inet_hash_connect(...)
{
inet_get_local_port_range(&low, &high);
remaining = (high - low) + 1;
for (i = 1; i <= remaining; i++) {
// 其中 offset 是一个随机数
port = low + (i + offset) % remaining;
head = &hinfo->bhash[inet_bhashfn(net, port,
hinfo->bhash_size)];
//加锁
spin_lock(&head->lock);
//一大段的选择端口逻辑
//......
//选择成功就 goto ok
//不成功就 goto next_port
next_port:
//解锁
spin_unlock(&head->lock);
}
}
在每次的循环内部需要等待锁,以及在哈希表中执行多次的搜索。注意这里的是自旋锁,是一种非阻塞的锁,如果资源被占用,进程并不会被挂起,而是会占用 CPU 去不断尝试获取锁。
但假设端口范围 ip_local_port_range 配置的是 10000 - 30000, 而且已经用尽了。那么每次当发起连接的时候都需要把循环执行两万遍才退出。这时会涉及大量的 HASH 查找以及自旋锁等待开销,系统态 CPU 将会出现大幅度的上涨。
这是线上截取到的正常时的 connect 系统调用耗时,是 22 us(微秒)。
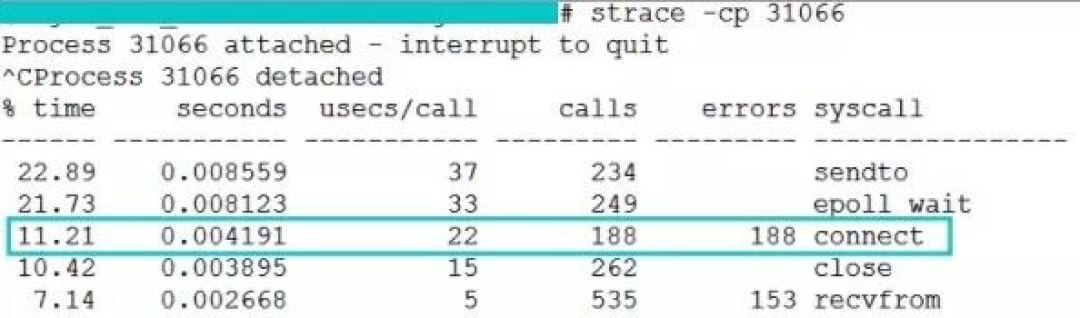
这个是我们一台服务器在端口不足情况下 connect 开销,是 2581 us(微秒)。
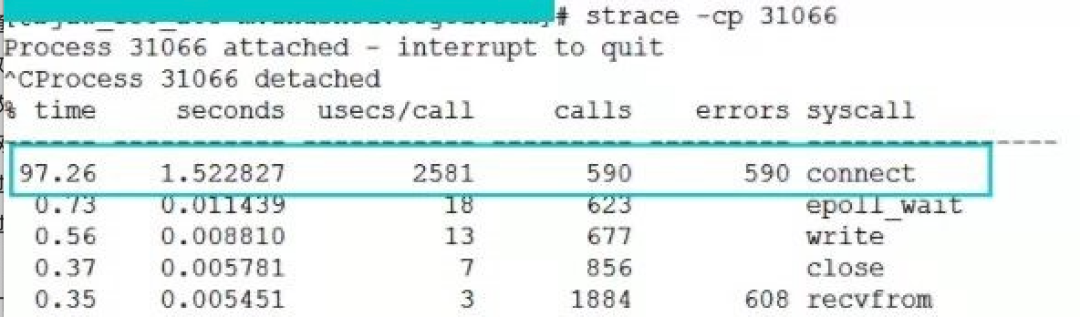
从上两张图中可以看出,异常情况下的 connect 耗时是正常情况下的 100 多倍。虽然换算成毫秒只有 2 ms 多一点,但是要知道这消耗的全是 CPU 时间。
二、第一次握手丢包
服务器在响应来自客户端的第一次握手请求的时候,会判断一下半连接队列和全连接队列是否溢出。如果发生溢出,可能会直接将握手包丢弃,而不会反馈给客户端。接下来我们分别来详细看一下。
2.1 半连接队列满
我们来看下半连接队列在何种情况下会导致丢包。
//file: net/ipv4/tcp_ipv4.c
int tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb)
{
//看看半连接队列是否满了
if (inet_csk_reqsk_queue_is_full(sk) && !isn) {
want_cookie = tcp_syn_flood_action(sk, skb, "TCP");
if (!want_cookie)
goto drop;
}
//看看全连接队列是否满了
...
drop:
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENDROPS);
return 0;
}
在上面代码中,inet_csk_reqsk_queue_is_full 如果返回 true 就表示半连接队列满了,另外 tcp_syn_flood_action 判断是否打开了内核参数 tcp_syncookies,如果未打开则返回 false。
//file: net/ipv4/tcp_ipv4.c
bool tcp_syn_flood_action(...)
{
bool want_cookie = false;
if (sysctl_tcp_syncookies) {
want_cookie = true;
}
return want_cookie;
}
也就是说,如果半连接队列满了,而且 ipv4.tcp_syncookies 参数设置为 0,那么来自客户端的握手包将 goto drop,意思就是直接丢弃!
SYN Flood 攻击就是通过消耗光服务器上的半连接队列来使得正常的用户连接请求无法被响应。不过在现在的 Linux 内核里只要打开 tcp_syncookies,半连接队列满了仍然也还可以保证正常握手的进行。
2.2 全连接队列满
我们注意到当半连接队列判断通过以后,紧接着还有全连接队列满的相关判断。如果这个条件成立,服务器对握手包的处理还是会 goto drop,丢弃了之。我们来看下源码:
//file: net/ipv4/tcp_ipv4.c
int tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb)
{
//看看半连接队列是否满了
...
//看看全连接队列是否满了
if (sk_acceptq_is_full(sk) && inet_csk_reqsk_queue_young(sk) > 1) {
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
goto drop;
}
...
drop:
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENDROPS);
return 0;
}
sk_acceptq_is_full 来判断全连接队列是否满了,inet_csk_reqsk_queue_young 判断的是有没有 young_ack(未处理完的半连接请求)。
这段代码可以看到,假如全连接队列满的情况下,且同时有 young_ack ,那么内核同样直接丢掉该 SYN 握手包。
2.3 客户端发起重试
假设说服务器侧发生了全/半连接队列溢出而导致的丢包。那么从转换到客户端视角来看就是 SYN 包没有任何响应。
好在客户端在发出握手包的时候,开启了一个重传定时器。如果收不到预期的 synack 的话,超时重传的逻辑就会开始执行。不过重传计时器的时间单位都是以秒来计算的,这意味着,如果有握手重传发生,即使第一次重传就能成功,那接口最快响应也是 1 s 以后的事情了。这对接口耗时影响非常的大。
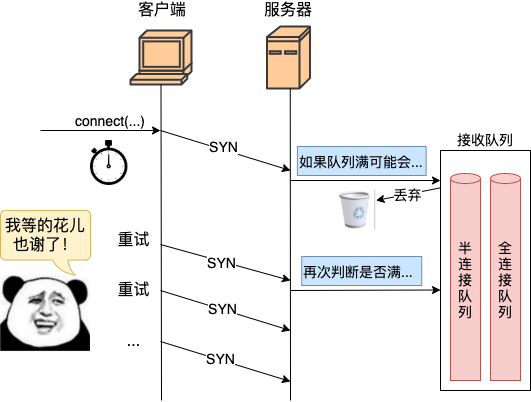
我们来详细看下重传相关的逻辑。服务器在 connect 发出 syn 后就开启了重传定时器。
//file:net/ipv4/tcp_output.c
int tcp_connect(struct sock *sk)
{
...
//实际发出 syn
err = tp->fastopen_req ? tcp_send_syn_data(sk, buff) :
tcp_transmit_skb(sk, buff, 1, sk->sk_allocation);
//启动重传定时器
inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS,
inet_csk(sk)->icsk_rto, TCP_RTO_MAX);
}
在定时器设置中传入的 inet_csk(sk)->icsk_rto 是超时时间,该值初始的时候被设置为了 1 秒。
//file:ipv4/tcp_output.c
void tcp_connect_init(struct sock *sk)
{
//初始化为 TCP_TIMEOUT_INIT
inet_csk(sk)->icsk_rto = TCP_TIMEOUT_INIT;
...
}
//file: include/net/tcp.h
#define TCP_TIMEOUT_INIT ((unsigned)(1*HZ))
在一些老版本的内核,比如 2.6 里,重传定时器的初始值是 3 秒。
//内核版本:2.6.32
//file: include/net/tcp.h
#define TCP_TIMEOUT_INIT ((unsigned)(3*HZ))
如果能正常接收到服务器响应的 synack,那么客户端的这个定时器会清除。这段逻辑在 tcp_rearm_rto 里。(tcp_rcv_state_process -> tcp_rcv_synsent_state_process -> tcp_ack -> tcp_clean_rtx_queue -> tcp_rearm_rto)
//file:net/ipv4/tcp_input.c
void tcp_rearm_rto(struct sock *sk)
{
inet_csk_clear_xmit_timer(sk, ICSK_TIME_RETRANS);
}
如果服务器端发生了丢包,那么定时器到时后会进行回调函数 tcp_write_timer 中进行重传。
其实不只是握手,连接状态的超时重传也是在这里完成的。不过这里我们只讨论握手重传的情况。
//file: net/ipv4/tcp_timer.c
static void tcp_write_timer(unsigned long data)
{
tcp_write_timer_handler(sk);
...
}
void tcp_write_timer_handler(struct sock *sk)
{
//取出定时器类型。
event = icsk->icsk_pending;
switch (event) {
case ICSK_TIME_RETRANS:
icsk->icsk_pending = 0;
tcp_retransmit_timer(sk);
break;
......
}
}
tcp_retransmit_timer 是重传的主要函数。在这里完成重传,以及下一次定时器到期时间的设置。
//file: net/ipv4/tcp_timer.c
void tcp_retransmit_timer(struct sock *sk)
{
...
//超过了重传次数则退出
if (tcp_write_timeout(sk))
goto out;
//重传
if (tcp_retransmit_skb(sk, tcp_write_queue_head(sk)) > 0) {
//重传失败
......
}
//退出前重新设置下一次超时时间
out_reset_timer:
//计算超时时间
if (sk->sk_state == TCP_ESTABLISHED ){
......
} else {
icsk->icsk_rto = min(icsk->icsk_rto << 1, TCP_RTO_MAX);
}
//设置
inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS, icsk->icsk_rto, TCP_RTO_MAX);
}
tcp_write_timeout 是判断是否重试过多,如果是则退出重试逻辑。
tcp_write_timeout 的判断逻辑其实也有点小复杂。对于 SYN 握手包主要是判断依据是 net.ipv4.tcp_syn_retries,但其实并不是简单对比次数,而是转化成了时间进行对比。所以如果你在线上看到实际重传次数和对应内核参数不一致也不用太奇怪。
接着在 tcp_retransmit_timer 重发了发送队列里的头元素。而且还设置了下一次超时的时间,为前一次的两倍(左移操作相当于乘2)。
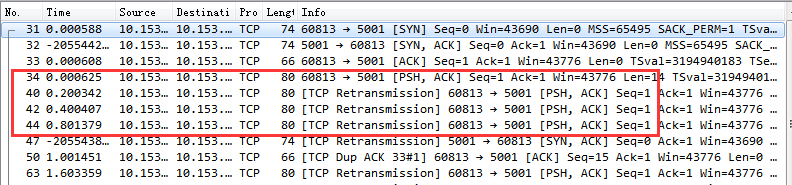
2.4 实际抓包结果
我们来看一个因为服务器端响应第一次握手丢包的握手过程抓包截图。

通过该图可以看到,客户端在 1 s 以后进行了第一次握手重试。重试仍然没有响应,那么接下来依次又分别在 3 s、7 s 15 s,31 s,63 s 等时间共重试了 6 次(我的 tcp_syn_retries 当时设置是 6)。
假如我们服务器上在第一次握手的时候出现了半/全连接队列溢出导致的丢包,那么我们的接口响应时间将至少是 1 s 以上(在某些老版本的内核上,SYN 第一次的重试就需要等 3 秒),如果连续两三次握手都失败,那 7,8 秒就出去了。你想想这对用户是不是影响很大。
三、第三次握手丢包
客户端在收到服务器的 synack 响应的时候,就认为连接建立成功了,然后会将自己的连接状态设置为 ESTABLISHED,发出第三次握手请求。但服务器在第三次握手的时候,还有可能会有意外发生。
//file: net/ipv4/tcp_ipv4.c
struct sock *tcp_v4_syn_recv_sock(struct sock *sk, ...)
{
//判断接收队列是不是满了
if (sk_acceptq_is_full(sk))
goto exit_overflow;
...
exit_overflow:
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
...
}
从上述代码可以看出,第三次握手时,如果服务器全连接队列满了,来自客户端的 ack 握手包又被直接丢弃了。
想想也很好理解,三次握手完的请求是要放在全连接队列里的。但是假如全连接队列满了,仍然三次握手也不会成功。
不过有意思的是,第三次握手失败并不是客户端重试,而是由客户端来重发 synack。
我们搞一个实际的 Case 来直接抓包看一下。我专门写了个简单的 Server 只 listen 不 accept,然后找个客户端把它的连接队列消耗光。这时候,再用另一个客户端向它发起请求时的抓包结果。
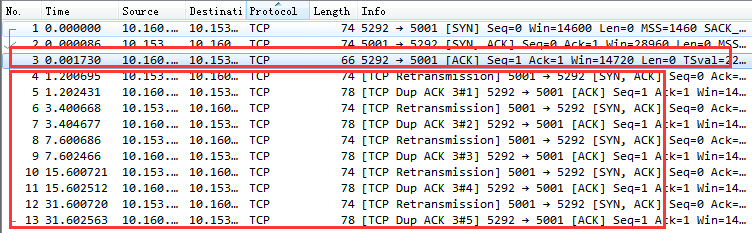
第一个红框内是第三次握手,其实这个握手请求在服务器端以及被丢弃了。但是这时候客户端并不知情,它一直傻傻地以为三次握手已经妥了呢。不过还好,这时在服务器的半连接队列中仍然记录着第一次握手时存的握手请求。
服务器等到半连接定时器到时后,向客户端重新发起 synack ,客户端收到后再重新回复第三次握手 ack。如果这期间服务器端全连接队列一直都是满的,那么服务器重试 5 次(受内核参数 net.ipv4.tcp_synack_retries 控制)后就放弃了。
在这种情况下大家还要注意另外一个问题。在实践中,客户端往往是以为连接建立成功就会开始发送数据,其实这时候连接还没有真的建立起来。他发出去的数据,包括重试都将全部被服务器无视。直到连接真正建立成功后才行。
四、总结
衡量工程师是否优秀的标准之一就是看他能否有能力定位和处理线上发生的各种问题。连看似简单的一个 TCP 三次握手,工程实践中可能会有各种意外发生。如果对握手理解不深,那么很有可能无法处理线上出现的各种故障。
今天的文章主要是描述了端口不足、半连接队列满、全连接队列满时的情况,
当端口不充足的时候,会导致 connect 系统调用的时候过多地执行自旋锁等待与 Hash 查找,会引起 CPU 开销上涨。严重情况下会耗光 CPU,影响用户业务逻辑的执行。出现这种问题处理起来方法有这么几个。
通过调整 ip_local_port_range 来尽量加大端口范围 尽量复用连接,使用长连接来削减频繁的握手处理 第三个有用,但是不太推荐的是开启 tcp_tw_reuse 和 tcp_tw_recycle
服务器端在第一次握手时可能会丢包, 在如下两种情况下会发生。
半连接队列满,且 tcp_syncookies 为 0 全连接队列满,且有未完成的半连接请求
在这两种情况下,客户端视角来看和网络断了没有区别,就是发出去的 SYN 包没有任何反馈,然后等待定时器到时后重传握手请求。第一次重传时间是 1 s ,接下来的等待间隔是翻倍地增长,2 s,4 s,8 s ...。总的重传次数由 net.ipv4.tcp_syn_retries 内核参数影响(注意我的用词是影响,而不是决定)。
服务器在第三次握手时也可能会出问题,如果全连接队列满,仍将会发生丢包。不过第三次握手失败时,只有服务器端知道(客户端误以为连接已经建立成功了)。服务器根据半连接队列里的握手信息发起 synack 重试,重试次数由 net.ipv4.tcp_synack_retries 控制。
一旦你的线上出现了上面这些连接队列溢出导致的问题,你的服务将会受到比较严重的影响。即使第一次重试就能够成功,那你的接口响应耗时将直接上涨到 1 s(老版本上是 3 s)。如果重试上两三次都没有成功,Nginx 很有可能直接就报访问超时失败了。
正因为握手重试对我们服务影响很大,所以能深刻理解三次握手中的这些异常情况很有必要。再说说如果出现了丢包的问题,我们该如何应对。
方法1,打开 syncookie
在现代的 Linux 版本里,我们可以通过打开 tcp_syncookies 来防止过多的请求打满半连接队列包括 SYN Flood 攻击,来解决服务器因为半连接队列满而发生的丢包。
方法2,加大连接队列长度
在《为什么服务端程序都需要先 listen 一下?》中,我们讨论过全连接队列的长度是 min(backlog, net.core.somaxconn)半连接队列长度是。半连接队列长度有点小复杂,是 min(backlog, somaxconn, tcp_max_syn_backlog) + 1 再上取整到 2 的幂次,但最小不能小于16。
如果需要加大全/半连接队列长度,请调节以上的一个或多个参数来达到目的。只要队列长度合适,就能很大程序降低握手异常概率的发生。
方法3,尽快地 accept
另外这个虽然一般不会成为问题,但也要注意一下。你的应用程序应该尽快在握手成功之后通过 accept 把新连接取走。不要忙于处理其它业务逻辑而导致全连接队列塞满了。
方法4,尽量减少 TCP 连接的次数
如果上述方法都未能根治你的问题,那说明你的服务器上 TCP 连接请求太、太过于频繁了。这个时候你应该思考下是否可以用长连接代替短连接,减少过于频繁的三次握手。这个方法不但能解决握手出问题的可能,而且还顺带砍掉了三次握手的各种内存、CPU、时间上的开销,对提升性能也有较大帮助。
最后,还是求赞,求再看,求转发!!
Github: https://github.com/yanfeizhang/coder-kung-fu