
7张图了解kafka基本概念
作者:xindoo
来源:SegmentFault 思否社区
kafka是apache基金会管理的开源流处理平台(官网:Apache Kafka),但国内大多数人对其认知基本都是消息队列,所以我们先来了解下什么是消息队列。
消息队列
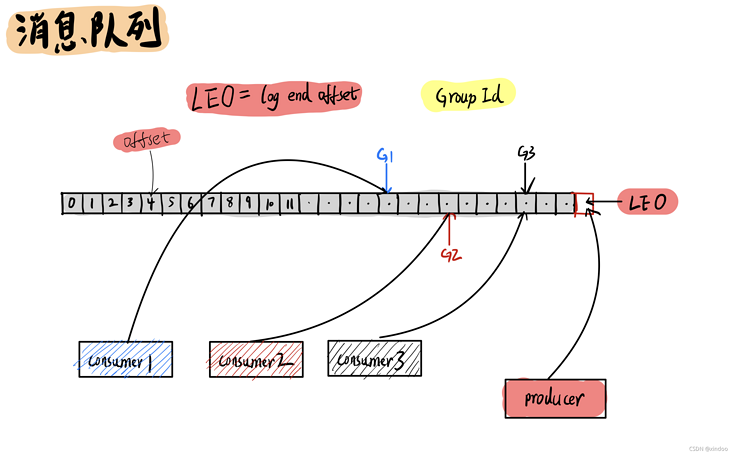
消息队列顾名思义就是存储消息的一个队列,消息生产者(producer) 往消息队列中投放消息, 消费者(consumer)读取消息队列中的内容。在消息队列中的每条消息都会有个位置,就好比数组中的下标(index),在kafka中我们称之为offset。对于生产者而言,有个特殊的offset——LEO(log end offset) ,指向的是消息队列中下一个将被存放消息的位置。
这里重点说下消费者(consumer),一个消息队列当然可以被多个消费者(consumer)读取,每个消费者(consumer)都有唯一一个group-id将其区分开来。kafka也会记录下来每个消费者(consumer)已经读到哪个位置了(offset)。
问:为什么消费者消费的offset是由kafka记录,而不是由消费者自己记录?
主题(Topic)

上文我们以一份数据为例,讲了什么是消息队列。如果有多份数据(多个队列)该怎么办?也很简单,kafka中我们可以使用不同的主题(Topic)将不同的数据区分开。不同的生产者(producer)可以往不同的Topic中存放数据,不同的消费者(consumer)也可以从不同的Topic中读取数据。
分区(Partation)
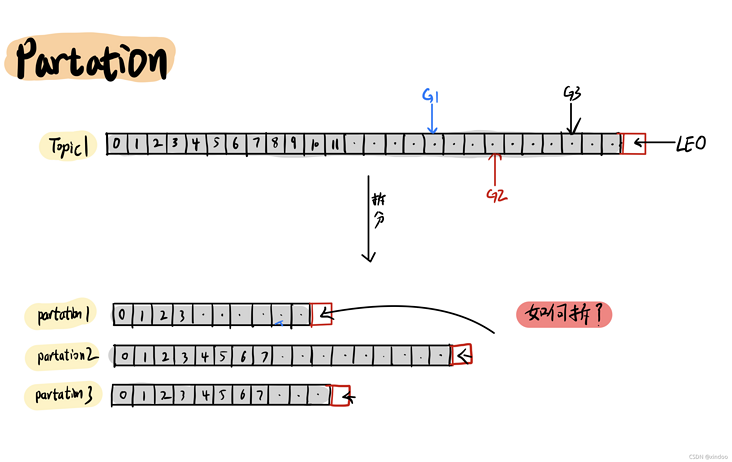
当一份数据非常大的情况下怎么办?当然是考虑拆分了。在kafka中,你可以设置将一个主题(Topic)拆分成多个不同的分区(Partation),然后以分区(Partation)的维度来管理、生产和消费数据。拆分带来最明显的好处就是提升吞吐性能,多个分区(Partation)之间并行,互不干扰。
至于怎么拆分,kafka有提供几个默认分区策略 轮询、随机、hash,当然你可以自己实现自己的分区策略,这里就不过多展开了。
消费者组(Consumer-group)
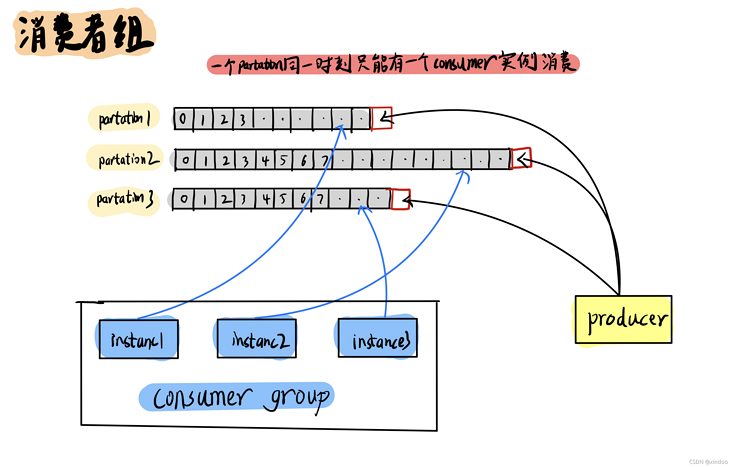
主题(Topic)做完分区以后,消费者如何消费?这里就不得不提到消费者组(Consumer-group)的概念,在kafka中,为了保证数据的一致性,同一个分区(Partation)同时只能被一个消费者(consumer)实例消费,为了提升消费者(consumer)的吞吐量,一般都会设置多个消费者(consumer)实例来消费不同的分区(Partation),这些实例共同组成一个消费者组(Consumer-group) ,他们共用一个Group-id。
注意:
由于同一个分区(Partation)同时只能被一个消费者(consumer)实例消费,所以超过分区(Partation)数量的消费者(consumer)实例个数没有任何意义,多余的消费者(consumer)实例也会被闲置。
如果消费者组(Consumer-group) 中有实例发生变化(上下线),或者分区(Partation)数量发生变化,都会触发消费者组rebalence。
副本(Replication)
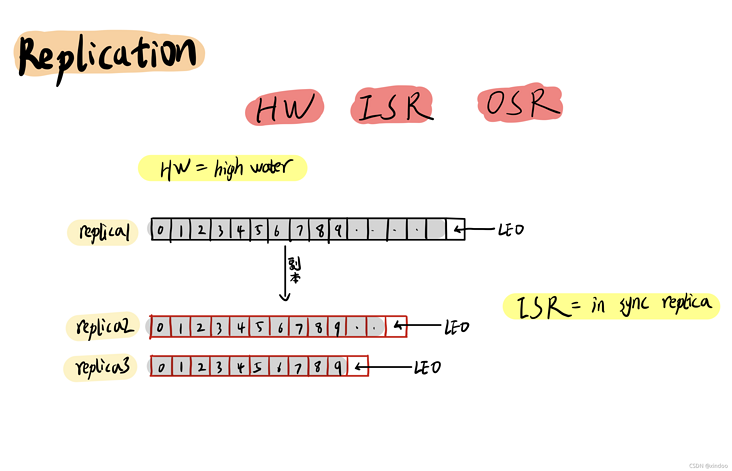
kafka如何解决数据高可用的问题?在分布式环境下,要想保证数据尽可能不丢失,唯一的方法就是多复制几份放到不同的机器上,复制出来的数据就叫做副本(Replication)。
这里有几个关键词。
HW: high-water,一个特殊的offset,只有在这个offset以下的消息才能被消费者(consumer)读到,高水位的具体值取决于主从副本数据同步的状态,这里不再展开。
ISR: in-sync-replica,处于同步状态的副本集合,是指副本数据和主副本数据相差在一定返回(时间范围或数量范围)之内的副本,当然主副本肯定是一直在ISR中的。当主副本挂了之后,新的主副本将从ISR中被选出来接替它的工作。
OSR: 和IRS相对应 out-sync-replica,其实就是指那些不在ISR中的副本。
副本主从同步
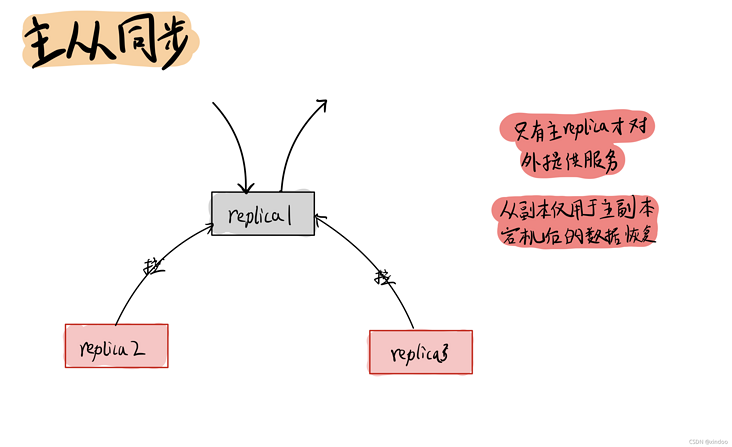
当一份数据比复制出多份副本后,肯定得涉及到主从副本的同步在,从副本会定期从主副本拉去最新的数据。另外需要注意kafka中,只有主副本才会对外提供读和写(高版本kafka从副本提供了有限的读功能),从副本的唯一作用就是给主副本当备胎。
说到主从同步,顺带提一下kafka的ack设置。
kafka中生产者(producer),可以通过request.required.acks参数来设置数据可靠性的级别:
0: 生产者(producer) 不等待来自主副本的确认,发出去即认为发送成功,这种情况效率最高但可能有丢失数据的风险。
1: (默认)生产者(producer) 发出数据后会等待主副本确认收到后,才认为消息发送成功,这种情况下主副本宕机时可能会丢失消息。
-1: (或者是all):生产者(producer) 等待ISR中的所有副本都确认接收到数据后才任务消息发送成功,可靠性最高,但因为需要等从副本拉去和确认,效率最低。
Broker
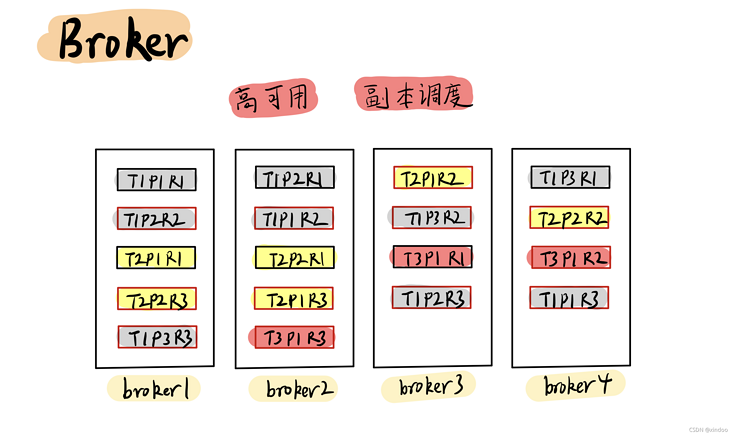
Kafka是以副本(Replica)维度管理数据的,管理这些数据肯定是需要管理者的,这个管理者就是Broker。Broker会将同一份数据的不同副本(Replication) 调度到不同的机器上,并且在副本(Replication) 数不足时生成新的副本,从而保证在部分Broker宕机后也能保证数据不丢失。
所有的Broker之间也会做一些元数据的相互同步,比如某份主数据在谁哪,从副本要从谁哪去拉取数据……
结语
第一次尝试手绘风讲解kafka入门知识,讲的很粗浅,确实很多细节都没有展开,见谅。
点击左下角阅读原文,到 SegmentFault 思否社区 和文章作者展开更多互动和交流,扫描下方”二维码“或在“公众号后台“回复“ 入群 ”即可加入我们的技术交流群,收获更多的技术文章~
- END -
