
图解Kafka中的基本概念
本文公众号来源:草捏子 作者:草捏子 本文已收录至我的GitHub
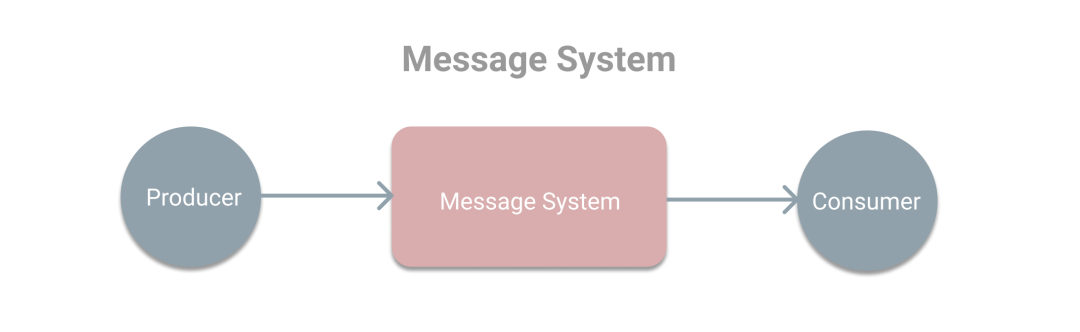
本次将学习Kafka中的基本概念。首先我们回顾下在消息系统的使用场景中有三种角色分别是生产者、消息系统和消费者,其中生产者负责产生消息和发送消息到消息系统,而消息系统将为消费者提供消息用于处理,如下图。
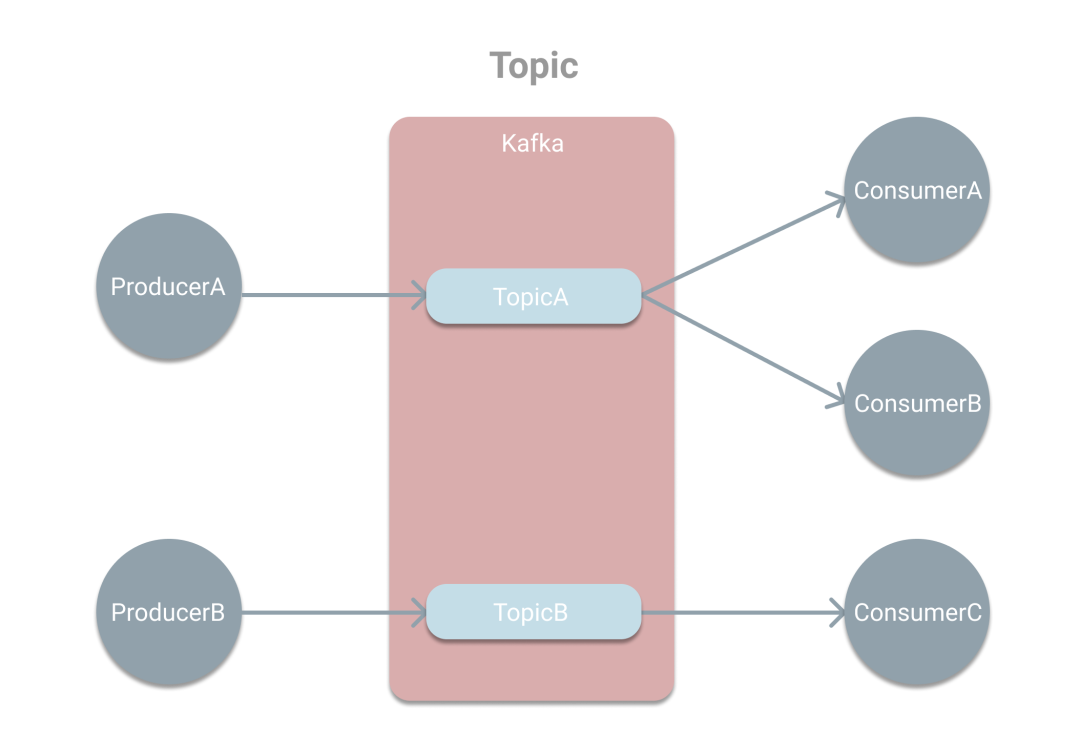
Kafka是基于发布/订阅模式的消息系统,如下图。生产者会将消息推送到Kafka中的某个Topic上。引入Topic的目的则是为了对消息进行分类,这样消费者就可以根据需要订阅相应的Topic获取消息。
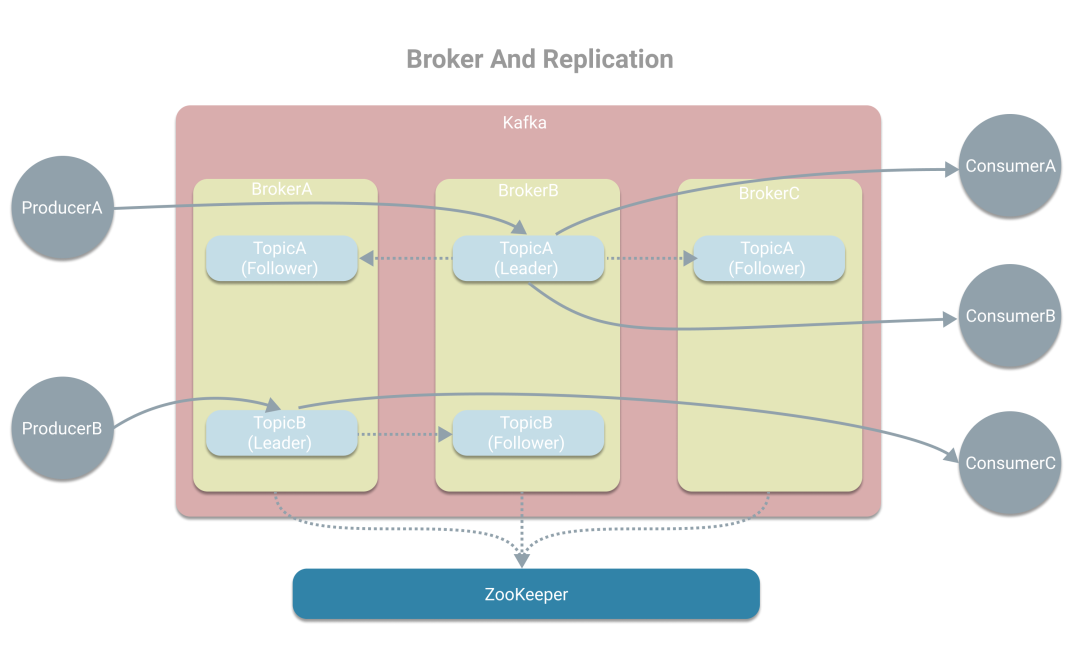
虽然Kafka这样已经能开始工作了,但紧接着又面临单点问题。而为了解决单点问题,Kafka引入了Broker的概念。一个Broker是一个Kafka实例,而一台机器上可运行多个Broker,这里我们认为一台机器上只有一个Kafka实例。多个Broker将形成一个Kafka集群,而Topic也可指定副本数量,作为多个副本位于多台机器上。Kafka使用ZooKeeper在多个副本中选举出一个Leader,其他副本将作为Follower。Leaer主要负责读写消息,也就是和生产者、消费者打交道,同时将消息同步写到其他副本中。当有Broker失效时,如果Topic没有了Leader,则会重新选举出新的Leader,从而解决单点问题。
引入Broker和副本后解决了单点问题,接着面对的是性能问题,对于单个Topic来说,只有Leader所在的Broker与生产者、消费者进行通信,这样吞吐量将受到Broker所在的机器限制。那么如何提高吞吐量。Kafka将Topic拆分成多个分区,也就是将消息进行划分,类似数据库的分库,这样起到了负载均衡的作用,可不受单机的限制。如下图,生产者A分别往TopicA的分区0和分区1写消息,而消费者A、B则也从分区0、1获取消息。这里注意下,在不同分区存储的消息也是不同的,和副本的概念要分清楚。
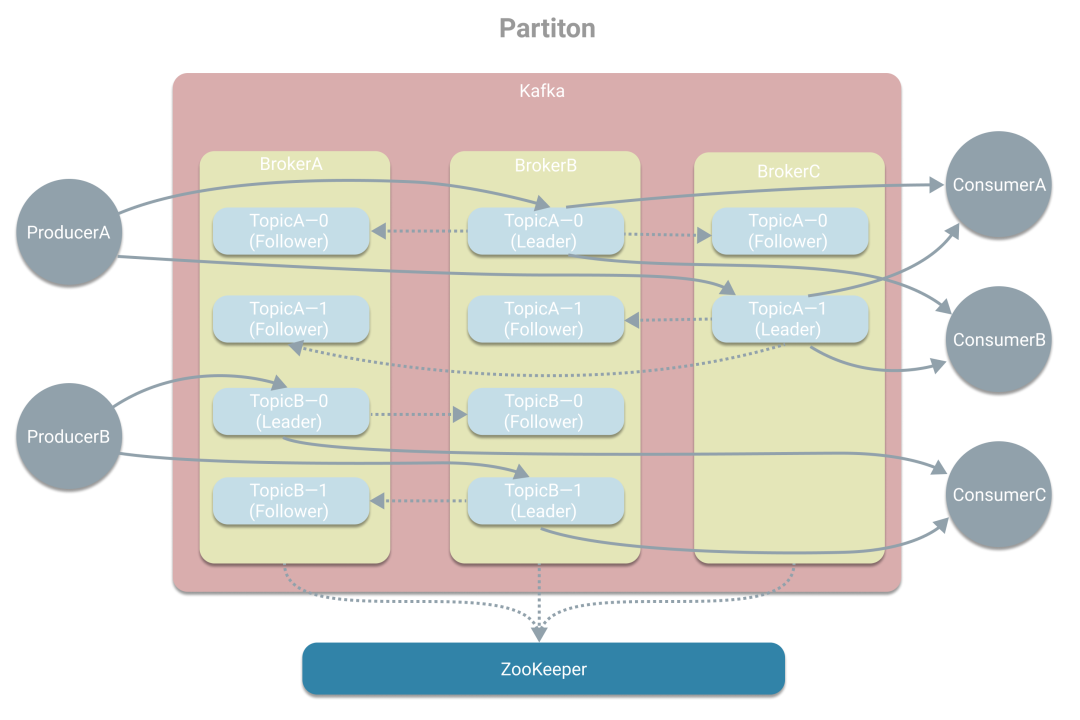
从上图中我们可看到消费者A在消费TopicA时分别从分区0、分区1中获取消息,为了进一步提高吞吐量,Kafka引入了消费组的概念,将消费者A拆分成多个消费者,从而形成一个消费组。我们可以这样理解,消费者A是一个应用A实例,为了提高消费的吞吐量,我们多部署了几个消费者A实例,这样就有多个消费者形成一个消费组,但干的都是应用A做的事,需要与消费者B(不同的应用)区分开。一般设置消费组的消费者数与分区数一致,这是为了一个消费者能负责一个分区,提高效率。如果消费组的消费者数量小于分区数,则会出现一个消费者负责多个分区。而如果消费组的消费者数量大于分区数,则会出现有消费者分不到分区,造成浪费。所以一般保持一致。为了简洁,且消费组B和消费组A类似,所以下图未将消费组B画出。
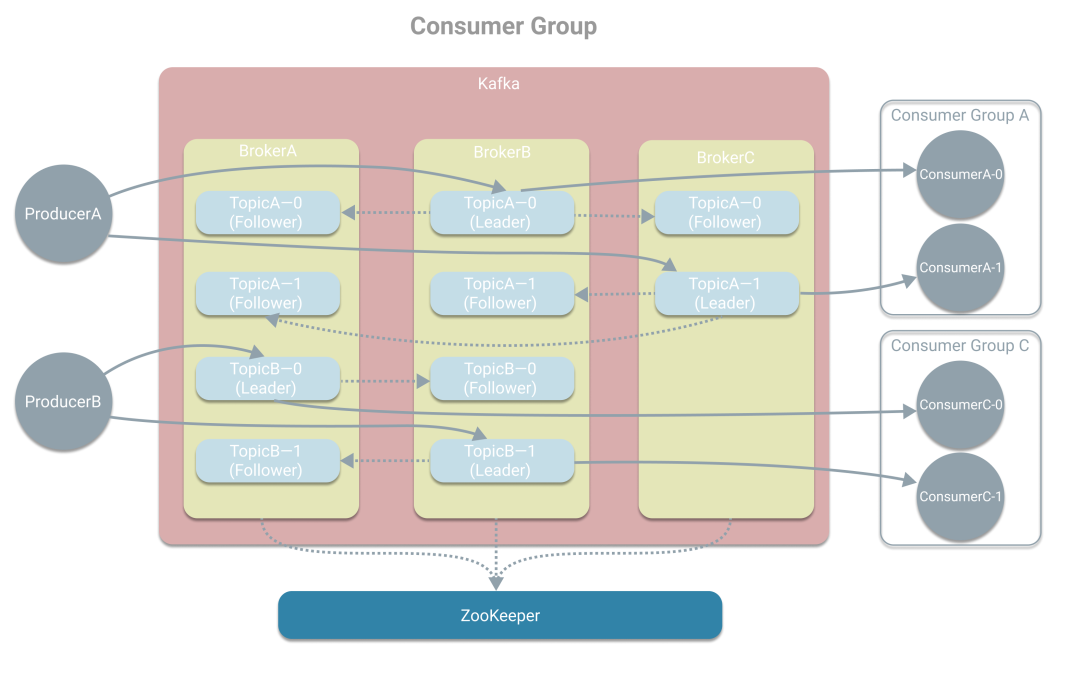
Kafka中的基本概念就是以上这些:生产者、消费者、Topic、Broker、副本、分区和消息组。最后为了大家更好的理解分区的概念,再画一张细节图。
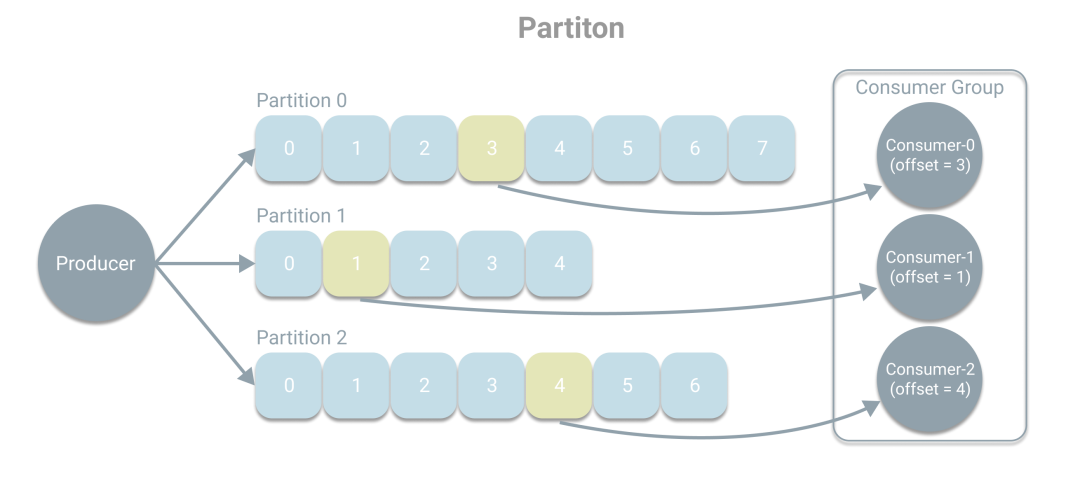
一个分区可以看做是一个单独的队列,生产者根据策略将消息写入对于的分区,策略有三种:一、直接指定分区;二、如果未指定分区,则根据消息的key,通过哈希函数指定分区;三、如果没有key,则轮询分区。这里想强调的是分区中的数据是不同的,一条消息只会进入一个分区。而消费组中的消费者则会根据偏移量去分区中取得相应的消息进行消费处理。
各类知识点总结
下面的文章都有对应的原创精美PDF,在持续更新中,可以来找我催更~
扫码或者微信搜Java3y 免费领取原创思维导图、精美PDF。在公众号回复「888」领取,PDF内容纯手打有任何不懂欢迎来问我。
原创电子书
原创思维导图

 |
|
