
分享一次简单的 JVM 调优,拿去写在简历上

本文收录于 www.cswiki.top
分享篇 JVM 调优的文章,算是入门级别的,对于初学者来说应该算是一个很好的了解调优思路的文章(对于校招就问有无 JVM 调优经验的我只能说一句 sb),原文来自 https://zhenbianshu.github.io,里面有一些句子和图片等我都重新做了整理和解释
背景
最近对负责的项目进行了一次性能优化,其中包括对 JVM 参数的调整,算是进行了一次简单的 JVM 调优,JVM 参数调整之后,服务的整体性能有 5% 左右的提升,还算不错。
先介绍一下项目的基本情况:
项目是一个高 QPS(Queries Per Second:每秒查询率,一台服务器每秒能够响应的查询请求的次数) 压力的 web 服务,单机 QPS 一直维持在 1.5K 以上,由于旧机器的”拖累”,配置的堆大小是 8G,其中 Young 区是 4G,垃圾回收器用的是 parNew + CMS
旧状
首先是查看当前 GC 的情况,主要是使用 jstat 查看 GC 的概况,再查看 GC log,分析单次 GC 的详细状况。
使用 jstat -GCutil pid 1000 每隔一秒打印一次 GC 统计信息。
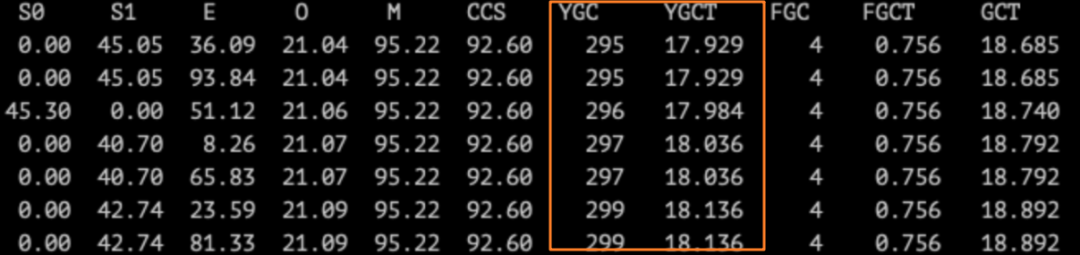
参数说明如下:
S0:新生代中 Survivor space 0 区已使用空间的百分比 S1:新生代中 Survivor space 1 区已使用空间的百分比 E:新生代已使用空间的百分比 O:老年代已使用空间的百分比 P:永久带已使用空间的百分比 YGC:从应用程序启动到当前,发生 Young GC 的次数 YGCT:从应用程序启动到当前,Young GC 所用的时间【单位秒】 FGC:从应用程序启动到当前,发生 Full GC 的次数 FGCT:从应用程序启动到当前,Full GC 所用的时间 GCT:从应用程序启动到当前,用于垃圾回收的总时间【单位秒】
可以看到,单次 GC 平均耗时是 GCT / (YGC + FGC) = 60ms 左右 ,还算可以接受,但 YGC 太过频繁。
接着查看 GC log,打印 GC log 需要在 JVM 启动参数里添加以下参数:
-XX:+PrintGCDateStamps:打印 GC 发生的时间戳。-XX:+PrintTenuringDistribution:打印 GC 发生时的分代信息。-XX:+PrintGCApplicationStoppedTime:打印 GC 停顿时长-XX:+PrintGCApplicationConcurrentTime:打印 GC 间隔的服务运行时长-XX:+PrintGCDetails:打印 GC 详情,包括 GC 前/内存等。-XlogGC:../GClogs/GC.log.date:指定 GC log 的路径
看到的 GC log 形如:

单次 GC 方面并不能直接看出问题,但可以看到 GC 前有很多次约 18ms 左右的停顿。
分析和调整
YGC 频繁
直接查看 GC log 并不直观,我们可以借用一些可视化工具来帮助我们分析,GCeasy - https://GCeasy.io/ 是个挺不错的网站,我们把 GC log 上传上去后, GCeasy 可以帮助我们生成各个维度的图表帮助分析。
查看 GCeasy 生成的报告,发现我们服务的 GC 吞吐量是 95% (GC 吞吐量指 GC 所花费的时间和系统总运行时间的比值, 系统总运行时间= 应用程序耗时+GC 耗时),它指的是 JVM 运行业务代码的时长占 JVM 总运行时长的比例,这个比例确实有些低了,运行 100 分钟就有 5 分钟在执行 GC。幸好这些 GC 中绝大多数都是 YGC,单次时长可控且分布平均,这使得我们服务还能平稳运行。
解决这个问题要么是减少对象的创建,要么就增大 Young 区。前者不是一时半会儿都解决的,需要查找代码里可能有问题的点,分步优化。
而后者虽然改一下配置就行,但以我们对 GC 最直观的印象来说,增大 Young 区,YGC 的时长也会迅速增大。
其实这点不必太过担心,我们知道 YGC 的耗时是由 标记 + 复制 组成的,相对于复制,标记过程是非常快的。而 Young 区内大多数对象的生命周期都非常短,如果将 Young 区增大一倍,标记的时长会提升一倍,但到 GC 发生时被标记的对象大部分已经死亡, 复制的时长肯定不会提升一倍,所以我们可以放心增大 Young 区大小。
由于低内存旧机器都被换掉了,我把堆大小从 8 调整到了 12G,Young 区从 4 提升为 8G。
分代调整
除了 GC 太频繁之外,GC 后各分代的平均大小也需要调整。
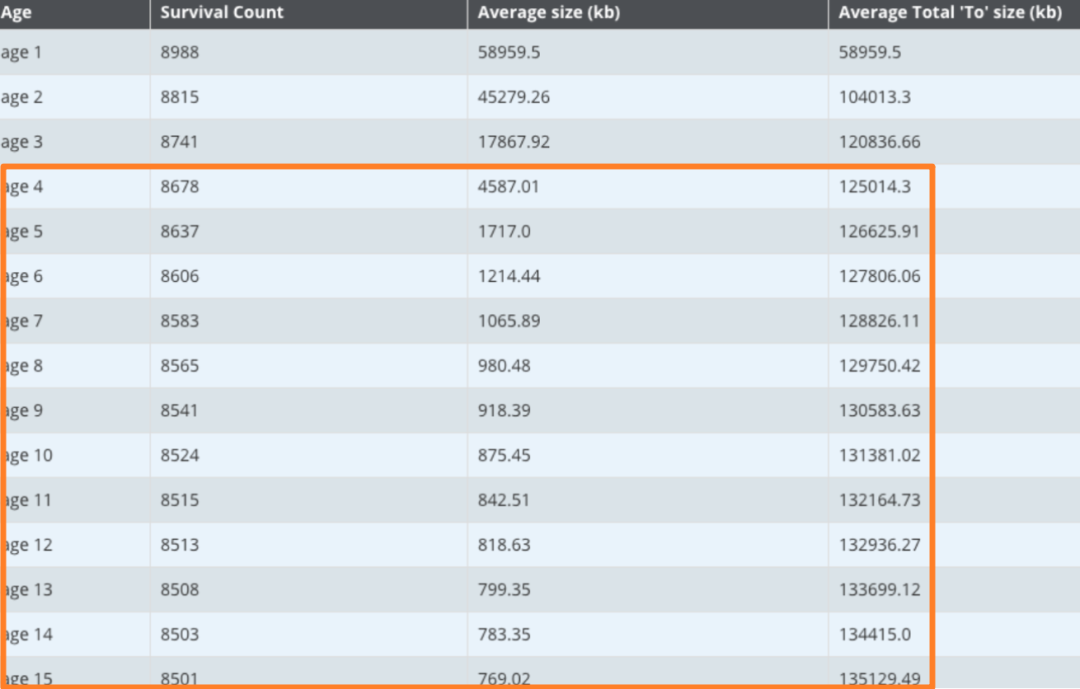
我们知道 GC 的提升机制,每次 GC 后,JVM 存活代数大于 MaxTenuringThreshold 的对象提升到老年代。
当然,JVM 还有动态年龄计算的规则:按照年龄从小到大对其所占用的大小进行累积,当累积的某个年龄大小超过了 survivor 区的一半时,取这个年龄和 MaxTenuringThreshold 中更小的一个值,作为新的晋升年龄阈值。不过看各代总的内存大小,是达不到 survivor 区的一半的。

所以这十五个分代内的对象会一直在两个 Survivor 区之间来回复制,再观察各分代的平均大小,可以看到,四代以上的对象已经有一半都会保留到老年区了,所以可以将这些对象直接提升到老年代,以减少对象在两个 survivor 区之间复制的性能开销。
所以我把 MaxTenuringThreshold 的值调整为 4,将存活超过四代的对象直接提升到老年代。
偏向锁停顿
还有一个问题是 GC log 里有很多约 18ms 左右的停顿,有时候连续有十多条,虽然每次停顿时长不长,但连续多次累积的时间也非常可观。
这个问题其实就是 JDK1.8 之后 JVM 对锁进行了优化,添加了偏向锁的概念,避免了很多不必要的加锁操作,但偏向锁一旦遇到锁竞争,就会进行锁释放,而锁释放操作需要进入安全点 safe point,导致 STW。
解决方式很简单,JVM 启动参数里添加 -XX:-UseBiasedLocking 取消偏向锁即可 (JDK15 已经废弃偏向锁了)。
结果
调整完 JVM 参数后先是对服务进行压测,发现性能确实有提升,也没有发生严重的 GC 问题,之后再把调整好的配置放到线上机器进行灰度,同时收集 GC log,再次进行分析。
由于 Young 区大小翻倍了,所以 YGC 的频率减半了,GC 的吞量提升到了 97.75%。不过平均 GC 时长略有上升,从 60ms 左右提升到了 66ms,还是挺符合预期的。
由于 CMS 在进行 GC 时也会清理 Young 区,CMS 的时长也受到了影响,CMS 的最终标记和并发清理阶段耗时增加了,也比较正常。
另外我还统计了对业务的影响,之前因为 GC 导致超时的请求大大减少了。
心之所向,素履以往,我是小牛肉,回复『春秋招』我拉你进春秋招交流群