
【关于 KBQA】 那些你不知道的事
作者:杨夕
介绍:本项目是作者们根据个人面试和经验总结出的自然语言处理(NLP)面试准备的学习笔记与资料,该资料目前包含 自然语言处理各领域的 面试题积累。
NLP 百面百搭 地址:https://github.com/km1994/NLP-Interview-Notes
推荐系统 百面百搭 地址:https://github.com/km1994/RES-Interview-Notes
搜索引擎 百面百搭 地址:https://github.com/km1994/search-engine-Interview-Notes 【编写ing】
NLP论文学习笔记:https://github.com/km1994/nlp_paper_study
推荐系统论文学习笔记:https://github.com/km1994/RS_paper_study
GCN 论文学习笔记:https://github.com/km1994/GCN_study
推广搜 军火库:https://github.com/km1994/recommendation_advertisement_search
【注:手机阅读可能图片打不开!!!】
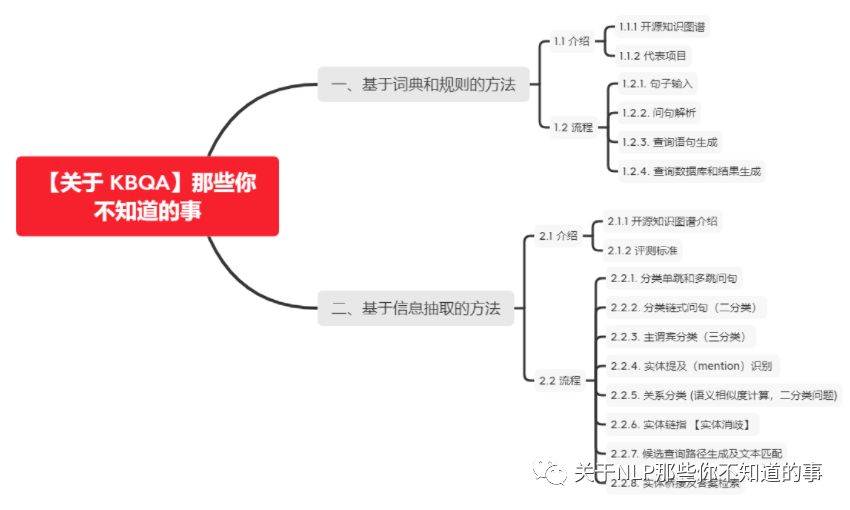
一、基于词典和规则的方法
1.1 介绍
1.1.1 开源知识图谱
工业界的知识图谱有两种分类方式,第一种是根据领域的覆盖范围不同分为通用知识图谱和领域知识图谱。其中通用知识图谱注重知识广度,领域知识图谱注重知识深度。通用知识图谱常常覆盖生活中的各个领域,从衣食住行到专业知识都会涉及,但是在每个领域内部的知识体系构建不是很完善;而领域知识图谱则是专注于某个领域(金融、司法等),结合领域需求与规范构建合适的知识结构以便进行领域内精细化的知识存储和问答。代表的知识图谱分别有:
通用知识图谱
Google Knowledge Graph
Microsoft Satori & Probase
领域知识图谱
Facebook 社交知识图谱
Amazon 商品知识图谱
阿里巴巴商品知识图谱
上海交大学术知识图谱
第二种分类方式是按照回答问题需要的知识类别来定义的,分为常识知识图谱和百科全书知识图谱。针对常识性知识图谱,我们只会挖掘问题中的词之间的语义关系,一般而言比较关注的关系包括 isA Relation、isPropertyOf Relation,问题的答案可能根据情景不同而有不同,所以回答正确与否往往存在概率问题。而针对百科全书知识图谱,我们往往会定义很多谓词,例如DayOfbirth, LocatedIn, SpouseOf 等等。这些问题即使有多个答案,这些答案往往也都是确定的,所以构建这种图谱在做问答时最优先考虑的就是准确率。代表的知识图谱分别有:
常识知识图谱
WordNet, KnowItAll, NELL, Microsoft Concept Graph
百科全书知识图谱
Freebase, Yago, Google Knowledge Graph
1.1.2 代表项目
豆瓣影评问答
基于医疗知识图谱的问答系统
1.2 流程
1.2.1. 句子输入
- eg:query:高血压要怎么治?需要多少天?1.2.2. 问句解析
实体抽取:
举例说明:
作用:得到匹配的词和类型
方法:
模式匹配:
介绍:主要采用规则 提槽
工具:正则表达式
词典:
介绍:利用词典进行匹配
采用的词典匹配方法:trie和Aho-Corasick自动机,简称AC自动机
工具:ahocorasick、FlashText 等 python包
基于词向量的文本相似度计算:
介绍:计算 query 中 实体 与 实体库 中候选实体的相似度,通过设定阈值,得到最相似的 实体
工具:词向量工具(TF-idf、word2vec、Bert 等)、相似度计算方法(余弦相似度、L1、L2等)
命名实体识别方法:
利用 命名实体识别方法 识别 query 中实体
方法:BiLSTM-CRF等命名实体识别模型
eg:通过解析 上面的 query ,获取里面的实体和实体类型:{'Disease': ['高血压'], 'Symptom': ['高血压'], 'Complication': ['高血压']}属性和关系抽取:
作用:抽取 query 中 的 属性和关系
方法:
模式匹配:
介绍:主要采用规则匹配
工具:正则表达式
词典:
介绍:利用词典进行匹配
采用的词典匹配方法:trie和Aho-Corasick自动机,简称AC自动机
工具:ahocorasick、FlashText 等 python包
意图识别方法:
介绍:采用分类模型 对 query 所含关系 做预测
工具:
机器学习方法:LR、SVM、NB
深度学习方法:TextCNN、TextRNN、Bert 等
命名实体识别方法:【同样,可以采用命名实体识别挖掘出 query 中的某些动词和所属类型】
利用 命名实体识别方法 识别 query 中实体
方法:BiLSTM-CRF等命名实体识别模型
举例说明:
- eg:通过解析 上面的 query ,获取里面的实体和实体类型:
- predicted intentions:['query_period'] 高血压要怎么治?
- word intentions:['query_cureway'] 需要多少天?1.2.3. 查询语句生成
作用:根据 【问句解析】 的结果,将 实体、属性和关系转化为对于的 图数据库(eg:Neo4j图数据库等)查询语句
举例说明:
- eg:
对于 query:高血压要怎么治?需要多少天?
- sql 解析结果:
[{'intention': 'query_period', 'sql': ["MATCH (d:Disease) WHERE d.name='高血压' return d.name,d.period"]}, {'intention': 'query_cureway', 'sql': ["MATCH (d:Disease)-[:HAS_DRUG]->(n) WHERE d.name='高血压' return d.name,d.treatment,n.name"]}]1.2.4. 查询数据库和结果生成
作用:利用 【查询语句生成】 的结果,去 图数据库 中 查询 答案,并利用预设模板 生成答案
- eg:
- 高血压可以尝试如下治疗:药物治疗;手术治疗;支持性治疗二、基于信息抽取的方法
2.1 介绍
2.1.1 开源知识图谱介绍
Knowledge Based Question Answering
CCKS开放域知识图谱问答比赛数据集
介绍:
问题类型:简单问题:复杂问题(多跳推理问题)=1:1
训练集:2298
验证集:766
测试集:766
资源地址:知识库 密码(huc8),问答集
方案:ccks2019-ckbqa-4th-codes、CCKS2018 CKBQA 1st 方案、中文知识图谱问答 CCKS2019 CKBQA - 参赛总结
NLPCC开放域知识图谱问答比赛数据集
介绍:
问题类型:简单问题(单跳问题)
训练集:14609
验证集 + 测试集:9870
资源地址:知识库,问答集
方案:NLPCC2016 KBQA 1st 方案
2.1.2 评测标准
Mean Reciprocal Rank (MRR)
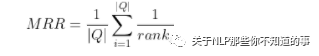
|Q|代表问题总数,rank_i代表第一个正确的答案在答案集合C_i中的位置
如果C_i中没有正确答案,
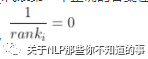
Accuracy@N
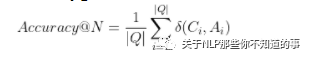
当答案集合C_i中至少有一个出现在gold answerA_i中,
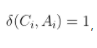
,否则为0
Averaged F1
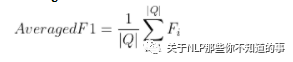
F_i是Q_i问题产生答案的F1值,如果A_i和C_i无交集F1为0
2.2 流程
2.2.1. 分类单跳和多跳问句
思路:利用 文本分类方法 对 query 进行分类,判断其属于 一跳问题还是多跳问题
方法:文本分类方法【TextCNN、TextRNN、Bert 等】
解析
单跳:SPARQL 只出现一个三元组
q26:豌豆公主这个形象出自于哪?
select ?x where { <豌豆公主_(安徒生童话)> <作品出处> ?x. }
<安徒生童话>双跳或多跳:SPARQL 只出现两个以上三元组
q524:博尔赫斯的国家首都在哪里?
select ?x where { <豪尔赫·路易斯·博尔赫斯_(阿根廷作家)> <出生地> ?y. ?y <首都> ?x}
<布宜诺斯艾利斯_(阿根廷的首都和最大城市)>2.2.2. 分类链式问句(二分类)
思路:利用 文本分类方法 对 query 进行分类,判断其是否 属于 链式问句
介绍:链式:SPARQL 多个三元组呈递进关系,x->y->z,非交集关系
q894:纳兰性德的父亲担任过什么官职?
select ?y where { <纳兰性德> <父亲> ?x. ?x <主要职位> ?y. }
"武英殿大学士" "太子太傅"
q554:宗馥莉任董事长的公司的公司口号是?
select ?y where { ?x <董事长> <宗馥莉>. ?x <公司口号> ?y. }
"win happy health,娃哈哈就在你身边"2.2.3. 主谓宾分类(三分类)
思路:利用 文本分类方法 对 query 进行分类,判断 问句的答案对应三元组里面的 主谓宾
问句的答案对应三元组里面的主语,spo=0
q70:《悼李夫人赋》是谁的作品?
select ?x where { ?x <代表作品> <悼李夫人赋>. }
<汉武帝_(汉朝皇帝)>问句的答案对应三元组里面的谓语,spo=1
q506:林徽因和梁思成是什么关系?
select ?x where { <林徽因_(中国建筑师、诗人、作家)> ?x <梁思成>. }
<丈夫>问句的答案对应三元组里面的宾语,spo=2
q458:天津大学的现任校长是谁?
select ?x where { <天津大学> <现任校长> ?x . }
<李家俊_(天津市委委员,天津大学校长)>2.2.4. 实体提及(mention)识别
思路:对于 给定 query,我们需要 识别出 query 中 所含有的 实体提及(mention)
问题:主办方提供的数据中 包含 :query、sql语句,但是 sql语句中的实体并不能在 query 中被找到,如下:
q1440:济南是哪个省的省会城市?
select ?x where { ?x <政府驻地> <济南_(山东省省会)>. }
<山东_(中国山东省)>注:query 中 的 济南 是 <济南_(山东省省会)>的 简称、省会城市 在 知识库中 对应 <政府驻地>
解决方法:根据训练语料的SPARQL语句,查找实体的提及,反向构建训练数据
思路 1:神经网络
训练语料构建
思路 1
根据 query 和 sql,查询 实体提及 【常用做法: 寻找 query 和 sql 中 entity 的最长子串作为 query 实体提及】
反向构建训练数据
思路 2
实体链接词典:实体链接词典为文本中的实体提及到知识库实体的映射【由CCKS2019 CKBQA主办方提供】
反向构建训练数据
命名实体识别:训练 命名实体识别模型 抽取 未标注数据 中 实体信息
方法:BiLSTM-CRF、Bert-CRF 等
q6:叔本华信仰什么宗教?
select ?y where { <亚瑟·叔本华> <信仰> ?y. }
<佛教>
>>>
叔本华信仰什么宗教? ['叔本华']
亚瑟·叔本华信仰什么宗教? ['亚瑟·叔本华']
>>>
叔 本 华 信 仰 什 么 宗 教 ? B-SEG I-SEG E-SEG O O O O O O O
亚 瑟 · 叔 本 华 信 仰 什 么 宗 教 ? B-SEG I-SEG I-SEG I-SEG I-SEG E-SEG O O O O O O O思路 2:规则
自定义字典(分词,词频,倒排索引)识别
分词词典:将 语料中的实体信息、知识库中的实体信息 合并后构建成一个 jieba 分词词典
词频:狗开源的中文词频词典 SogouLabDic.dic 、语料中的实体信息、知识库中的实体信息
倒排索引字典:该词典用于识别属性值的模糊匹配,使用知识库中所有属性值,构建字到词的映射。
建立停用词表删去无用词
分词后的词与知识图谱的实体的字符串匹配(jaccord,编辑距离)
辅助工具
NER工具包识别问句中人名,地点,机构等
2.2.5. 关系分类 (语义相似度计算,二分类问题)
目标:查询实体关系中与问句最相似的关系
思路:
正例:根据给定 训练集,获得 实体和关系 的样本
负例:根据 该实体名 从 Neo4j 图数据库中随机抽取出 5个关系作为负例
q1:莫妮卡·贝鲁奇的代表作?
select ?x where { <莫妮卡·贝鲁奇> <代表作品> ?x. }
<西西里的美丽传说>
>>> 表达形式一:
正例:
莫妮卡·贝鲁奇的代表作?代表作品 1
负例:
莫妮卡·贝鲁奇的代表作?出生地 0
莫妮卡·贝鲁奇的代表作?类型 0
莫妮卡·贝鲁奇的代表作?制片地区 0
莫妮卡·贝鲁奇的代表作?主演 0
莫妮卡·贝鲁奇的代表作?作者 0模型选择:
关系和问题的语义相似度(bert-bilstm-fc-cosine)
关系值和问题的语义相似度(bert-bilstm-fc-cosine)
关系和问题的字符覆盖率
关系模型1:关系识别与排序(1/2hop)
关系模型2:路径排序
将链接到的实体和 实体的1/2跳关系 组成路径,通过bert-similarity模型进行训练
路径与问题的jaccard,编辑距离
自身定义的模板匹配度...
关系模型3:规则匹配排序
将问题分割为多个部分,参照word/phrases in the kb + existing word segmentation tools,将问题分为各部分都和kb中实体/属性/关系相似的部分,按分值高低与知识图谱对应部分进行链接。
将问题分为单跳,多跳类型(共8种),记录下各自的结构,与问题中分割出的问题结构进行相似度比较
2.2.6. 实体链指 【实体消歧】
问题:对于 问句中的实体提及在 Neo4j 图数据库 中可能存在多个相关实体,如何选取 将 实体提及 链指到 对应的 知识库中的实体
q15:清明节起源于哪里?
select ?x where { <清明_(二十四节气之一)> <起源> ?x. }
<绵山风景名胜区>
>>>
问句中 实体提及:清明
对应的知识库中的 实体:<清明_(二十四节气之一)>、清明_(汉语词汇)、清明_(长篇小说)、清明_(唐代杜牧诗作)等目标:查找问句中实体提及对应的唯一实体
思路:
在训练集上,令标注的实体标签为1,其余候选实体标签为0,使用逻辑回归对上述特征进行拟合。
在验证集和测试集上,使用训练好的机器模型对每个实体打分,保留分数排名前n的候选实体。
特征选择:
问题和实体提及间 特征 mention_features
该词典用于计算实体提及和属性值提及的词频特征,使用搜狗开源的中文词频词典 SogouLabDic.dic 构建;
实体提及的长度:该实体对应的实体提及的字数;
实体提及的词频:该实体对应的实体提及的词频;
实体提及的位置:该实体对应的实体提及距离句首的距离;
实体类型与问题的匹配度
# 获取 mention 的特征 mention_features : [mention, f1, f2, f3]
# f1 : mention的长度
# f2 : mention 在 SogouLabDic.dic 中 的词频
# f3 : mention 在 question 中 的位置
def get_mention_feature(self,question,mention):
f1 = float(len(mention)) #mention的长度
try:
f2 = float(self.word_2_frequency[mention]) # mention的tf/10000
except:
f2 = 1.0
if mention[-2:] == '大学':
f2 = 1.0
try:
f3 = float(question.index(mention))
except:
f3 = 3.0
#print ('这个mention无法提取位置')
return [mention,f1,f2,f3]图谱子图与问题的匹配度:计算问题和主语实体及其两跳内关系间的相似度
实体提及及两跳内关系和实体与问题重叠词数量
实体提及及两跳内关系和实体与问题重叠字数量
# similar_features : [overlap,jaccard] * {(q_tokens,e_tokens), (q_chars,e_chars), (q_tokens,p_tokens), (q_chars,p_chars)} = 8
def extract_subject(self,entity_mentions,subject_props,question):
...
#得到实体两跳内的所有关系
entity = '<'+entity+'>'
if entity in self.entity2hop_dic:
relations = self.entity2hop_dic[entity]
else:
relations = kb.GetRelations_2hop(entity)
self.entity2hop_dic[entity] = relations
# 计算问题和主语实体及其两跳内关系间的相似度
similar_features = ComputeEntityFeatures(question,entity,relations)
...
def ComputeEntityFeatures(question,entity,relations):
'''
抽取每个实体或属性值2hop内的所有关系,来跟问题计算各种相似度特征
input:
question: python-str
entity: python-str <entityname>
relations: python-dic key:<rname>
output:
[word_overlap,char_overlap,word_embedding_similarity,char_overlap_ratio]
'''
#得到主语-谓词的tokens及chars
p_tokens = []
for p in relations:
p_tokens.extend(segger.cut(p[1:-1]))
p_tokens = [token[0] for token in p_tokens]
p_chars = [char for char in ''.join(p_tokens)]
q_tokens = segger.cut(question)
q_tokens = [token[0] for token in q_tokens]
q_chars = [char for char in question]
e_tokens = segger.cut(entity[1:-1])
e_tokens = [token[0] for token in e_tokens]
e_chars = [char for char in entity[1:-1]]
qe_feature = features_from_two_sequences(q_tokens,e_tokens) + features_from_two_sequences(q_chars,e_chars)
qr_feature = features_from_two_sequences(q_tokens,p_tokens) + features_from_two_sequences(q_chars,p_chars)
#实体名和问题的overlap除以实体名长度的比例
return qe_feature+qr_feature
def features_from_two_sequences(s1,s2):
#overlap
overlap = len(set(s1)&(set(s2)))
#集合距离
jaccard = len(set(s1)&(set(s2))) / len(set(s1)|(set(s2)))
#词向量相似度
#wordvecsim = model.similarity(''.join(s1),''.join(s2))
return [overlap,jaccard]实体提及的流行度特征
实体提及在图谱中关系个数/出现频率
# popular_feature : GetRelationNum = 1 实体的流行度特征
def extract_subject(self,entity_mentions,subject_props,question):
...
#实体的流行度特征
popular_feature = kb.GetRelationNum(entity)
...
def GetRelationNum(self,entity):
'''根据实体名,得到与之相连的关系数量,代表实体在知识库中的流行度'''
cql= "match p=(a:Entity)-[r1:Relation]-() where a.name=$name return count(p)"
res = self.session.run(cql,name=entity)
ans = 0
for record in res:
ans = record.values()[0]
return ans实体名称和问题的字符串匹配度(char/word)
问题和实体提及语义相似度
问题和实体关系的最大相似度
...
标签:是否为 对应实体
q15:清明节起源于哪里?
select ?x where { <清明_(二十四节气之一)> <起源> ?x. }
<绵山风景名胜区>
>>>
清明节起源于哪里?<清明_(二十四节气之一)> 1.0 1.0 0.43 0.15978466 0.6 0.99257445 ... 0
清明节起源于哪里?<清明_(汉语词汇)> 0.9 1.0 0.43 0.97132427 0.58 0.99660385 ... 1
清明节起源于哪里?<清明_(长篇小说)> 0.8 1.0 0.43 0.920861 0.38 0.0007164952 ... 0
清明节起源于哪里?<清明_(唐代杜牧诗作)> 0.8 1.0 0.43 0.920861 0.38 0.0007164952 ... 0
...分类方法:
LR、SVM、xgboost 等
2.2.7. 候选查询路径生成及文本匹配
问题:根据前面的操作会得到 query 对应的候选实体和关系信息,由于预训练模型是基于自然语言训练的,而将生成的候选查询路径是不符合自然语言逻辑的,那如何 转化成自然语言处理能够理解的形式,和判断 所抽取的 实体提及 和 关系 是正确的呢?
目标:判断 所抽取的 实体提及 和 关系 是正确性
方法:对于每个候选实体,抽取与其相连的单跳关系和两跳关系作为候选的查询路径,形式如(entity,relation)或(entity,relation1,relation2)。
思路:
候选查询路径:将 (entity,relation) 转化成 自然语言处理 能够处理的 文本形式:eg :entity 的 relation
文本匹配:利用 Bert 计算 query 和 entity 的 relation 的相似度
思路:
在训练集上,对于每个问题,随机选择三个候选查询路径作为负例,令标注的候选查询路径标签为1,负例的标签为0,将自然语言问题和人工问题拼接,训练一个文本分类模型。
在验证集和测试集上,使用该模型对所有的自然语言问题-人工问题对进行打分。
q15:清明节起源于哪里?
select ?x where { <清明_(二十四节气之一)> <起源> ?x. }
<绵山风景名胜区>
>>> 实体提及 和 关系
实体提及 <清明_(二十四节气之一)>
关系 起源
>>> (entity,relation)
(entity,relation):(<清明_(二十四节气之一)>,起源 )
>>> 候选查询路径:(entity,relation) => entity 的 relation
(<清明_(二十四节气之一)>,起源 ): 清明_(二十四节气之一)的起源
>>> 文本匹配:
清明节起源于哪里?清明_(二十四节气之一)的起源 1
清明节起源于哪里?清明_(二十四节气之一)的类型 0
清明节起源于哪里?清明_(汉语词汇)的起源地 0
清明节起源于哪里?清明_(汉语词汇)的类型 02.2.8. 实体桥接及答案检索
动机:
2.2.7 节 所提方法只能处理 单实体问题,但是 样本中 不仅 包含 单实体问题,还包含 多实体问题,那需要怎么解决呢?
eg:北京大学出了哪些哲学家解决方法:实体桥接
思路:
对于每个问题,首先对2.2.7 节 打分后的候选查询路径进行排序,保留前30个单关系的查询路径(entity1,relation1)。
对于这些查询路径,到知识库中进行检索,验证其是否能和其他候选实体组成多实体情况的查询路径(entity1,relation1,ANSWER,relation2,entity2),将其加入候选查询路径中。
最后,本文将2.2.7 节 单实体情况排名前三的候选查询路径和本节得到的双实体情况查询路径同时和问题计算重叠的字数,选择重叠字数最多的作为最终的查询路径,认为其在语义和表达上最与问题相似。
参考资料
中文知识图谱问答 CCKS2019 CKBQA - 参赛总结
ccks2019-ckbqa-4th-codes
QA-Survey
中文知识图谱问答 CCKS2019 CKBQA 参赛总结
CCKS2019 测评报告