
详解低延时高音质:回声消除与降噪篇

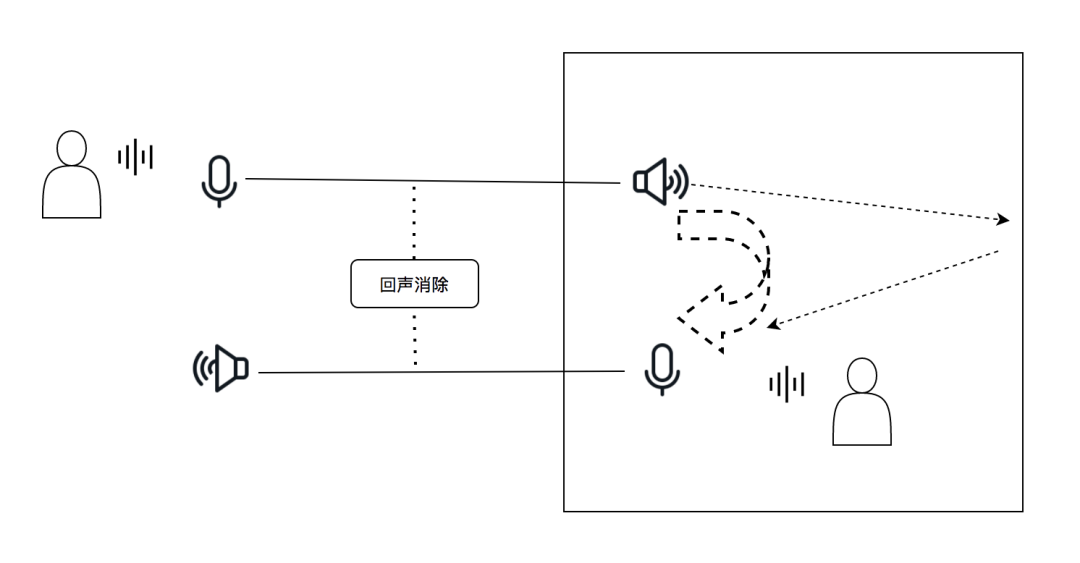
在实时音频互动场景中,除了我们上一篇讲到的编解码会影响音质与体验,在端上,降噪、回声消除、自动增益模块同样起着重要作用。在本篇内容中我们将主要围绕回声消除和降噪模块,讲讲实时互动场景下的技术挑战,以及我们的解决思路与实践。「文末有个小彩蛋:) 」
 回声消除的三大算法模块优化
回声消除的三大算法模块优化声学环境,包括反射,混响等;
通话设备本身声学设计,包括音腔设计以及器件的非线性失真等;
系统性能,处理器的计算能力以及操作系统线程调度的能力。
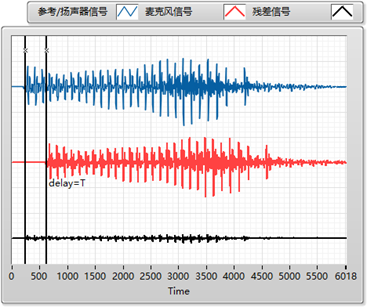
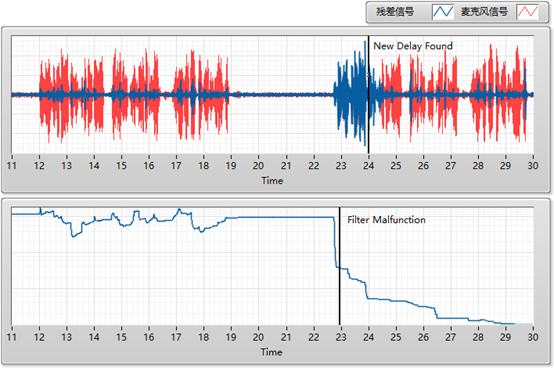
第一步需要找到参考信号/扬声器信号(蓝色折线)跟麦克风信号(红色折线)之间的延迟,也就是图中的 delay=T。
第二步根据参考信号估计出麦克风信号中的线性回声成分,并将其从麦克风信号中减去,得到残差信号(黑色折线)。
第三步通过非线性的处理将残差信号中的残余回声给彻底抑制掉。
延迟估计(Delay Estimation)
线性自适应滤波器(Linear Adaptive Filter)
非线性处理(Nonlinear Processing)
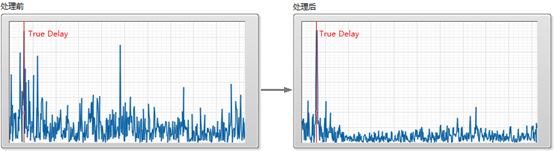
接下来,我们先围绕这三个算法模块,分别讲讲其中的技术挑战与优化思路。一、延迟估计受具体系统实现的影响,当把参考信号与麦克风信号分别送入 AEC 模块进行处理之时,它们所存入的数据 buffer 之间存在一个时间上的延迟,即我们在上图中看到的“delay=T”。假设这个产生回声的设备是一部手机,那么声音从它的扬声器发出后,一部分会经过设备内部传导到麦克风,也可能会经过外部环境传回到麦克风中。所以这个延迟就包含了设备采集播放 buffer 的长度,声音在空气中传输的时间,也包含了播放线程与采集线程开始工作的时间差。正是由于影响延迟的因素很多,因此这个延迟的值在不同系统,不同设备,不同 SDK 底层实现上都各不相同。它在通话过程中也许是一个定值,也有可能会中途变化(所谓的 overrun 和 underrun)。这也是为什么一个 AEC 算法在设备 A 上可能起作用,但换到另一个设备上可能效果会变差。延迟估计的精确性是 AEC 能够工作的先决条件,过大的估计偏差会导致 AEC 的性能急剧下降,甚至无法工作,而无法快速跟踪时延变化是出现偶现回声的重要因素。增强延迟估计算法鲁棒性传统算法通常通过计算参考信号跟麦克风信号之间的相关性来决定延迟。相关性的计算可以放在频域上,典型的就是 Binary Spectrum 的方法,通过计算单频点上的信号能量是否超过一定门限值,实际将参考信号跟麦克风信号映射成了两维的0/1数组,然后通过不断移动数组偏移来找到延迟。最新的 WebRTC AEC3 算法通过并行的多个NLMS线性滤波器来寻找延迟,这个方法在检测速度及鲁棒性方面都取得了不错的效果,但是计算量非常大。当在时域上计算两个信号的互相关时,一个明显的问题是语音信号包含大量的谐波成分并且具有时变特性,它的相关信号常常呈现出多峰值的特征,有的峰值并不代表真正的延迟,并且算法容易受到噪声干扰。声网延迟估计算法通过降低信号之间的相关性(de-correlate),能够有效抑制 local maxima 的值以大大增强算法的鲁棒性。如下图所示,左边是原始信号之间的互相关,右边是声网SDK处理后的互相关,可见信号的预处理大大增强了延迟估计的鲁棒性:注:双讲是指在交互场景中,互动双方或多方同时讲话,其中一方的声音会受到抑制,从而出现断断续续的情况。这是由于回声消除算法“矫枉过正”,消除了部分不该去除的音频信号。
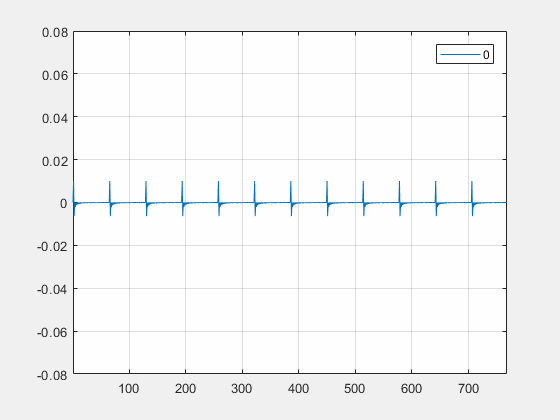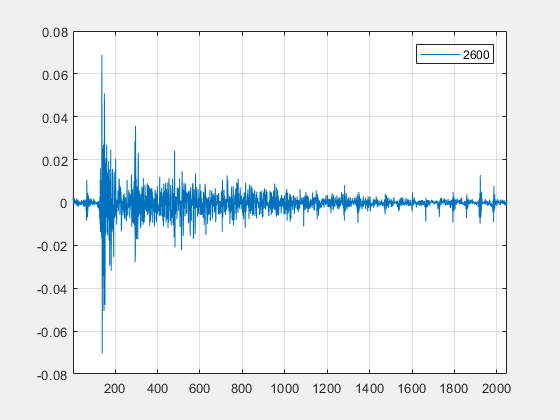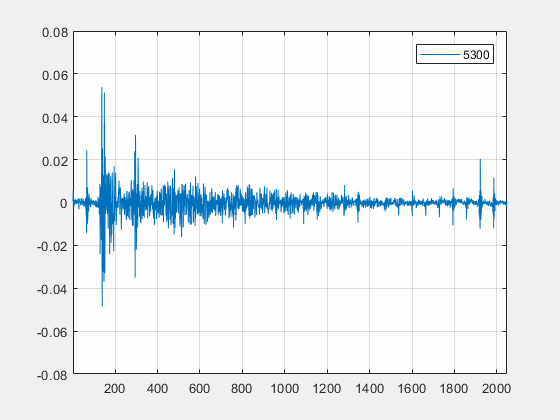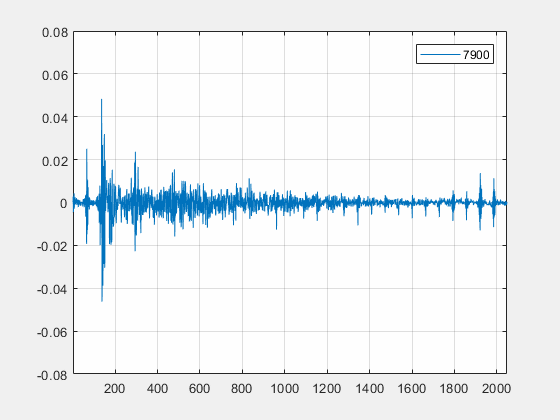
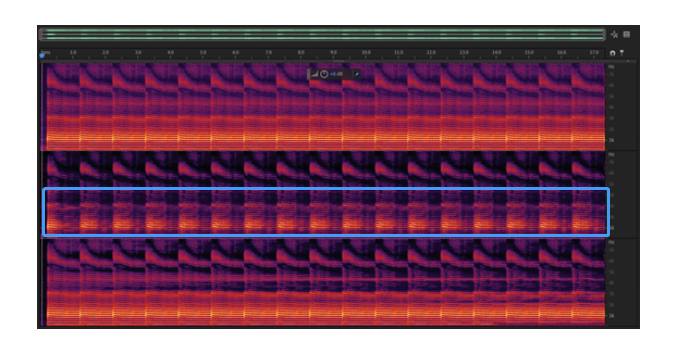
算法自适应,降低计算量通常延迟估计算法为了降低计算量的需要,会预先假设回声信号出现在某个较低的频段内,这样就可以将信号做完下采样之后再送入延迟估计模块,降低算法的计算复杂度。然而面对市面上数以万计的设备及各种路由,以上的假设往往并不成立。下图是 VivoX20 在耳机模式下麦克风信号的频谱图,可见回声都集中在 4kHz 以上的频段内,传统的算法针对这些 case 都会导致回声消除模块的失效。声网延迟估计算法会在全频段内搜索回声出现的区域,并自适应地选择该区域计算延迟,确保算法在任何设备,路由下都有精确的延迟估计输出。
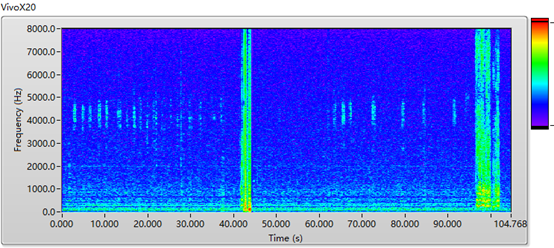
图:VivoX20 接入耳机后的麦克风信号
1. 适应尽量多的设备、声学环境,且在尽量短的时间内根据设备、声学环境的因素匹配合适的算法;
2. 在突发随机的延迟变化后,能及时动态调整算法策略。
以下是声网 SDK 与友商之间的延迟估计性能对比,总共使用了数据库中 8640 组测试数据。从图中数据可以看出,声网 SDK 可以在更短的时间内找到大多数测试数据的初始时延。在 96% 的测试数据中,声网 SDK 能在 1s 之内找到它们正确的延迟,而友商这一比例为 89%。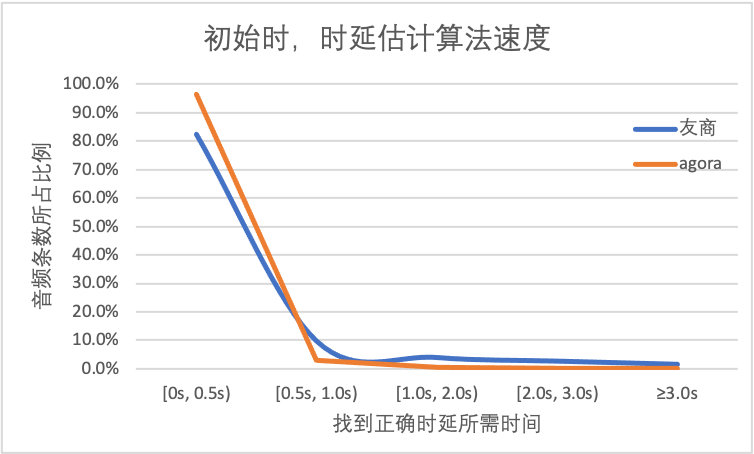
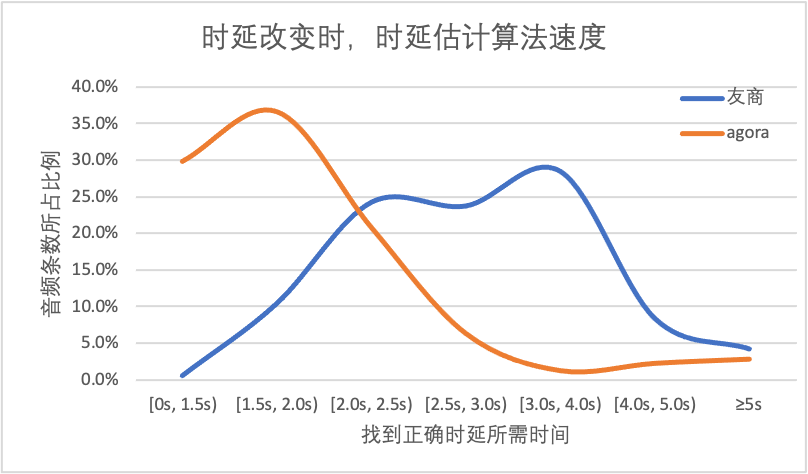
第二个测试的是在通话过程中出现随机的延迟抖动,测试延迟估计算法要在尽量短的时间内找到精确的延迟值。如图中所示,声网 SDK 在 71% 的测试数据中能在 3s 之内重新找到变化后的精确延迟值,而友商这个比例为 44%。
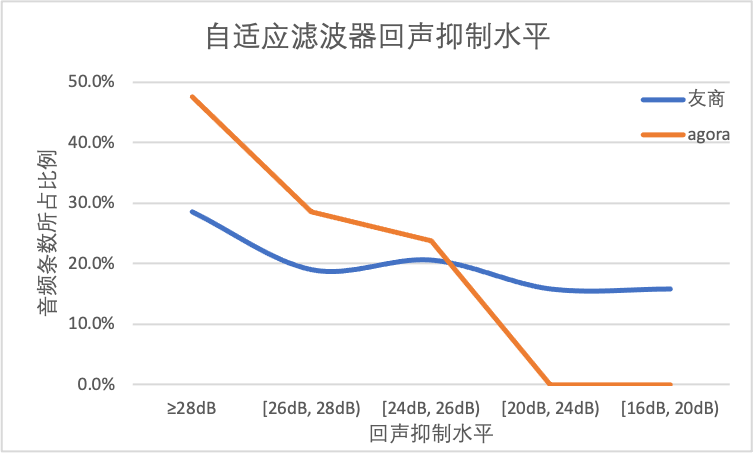
同样的,我们也使用数据库中大量测试数据进行声网 SDK 与友商之间的性能对比,对比的指标包括稳态失调(滤波器收敛之后对回声的抑制程度)以及收敛速度(滤波器达到收敛状态需要的时长)。第一张图代表自适应滤波器的稳态失调,声网SDK在 47%的测试数据中能达到超过 20dB 的回声抑制,而友商的比例为 39%。
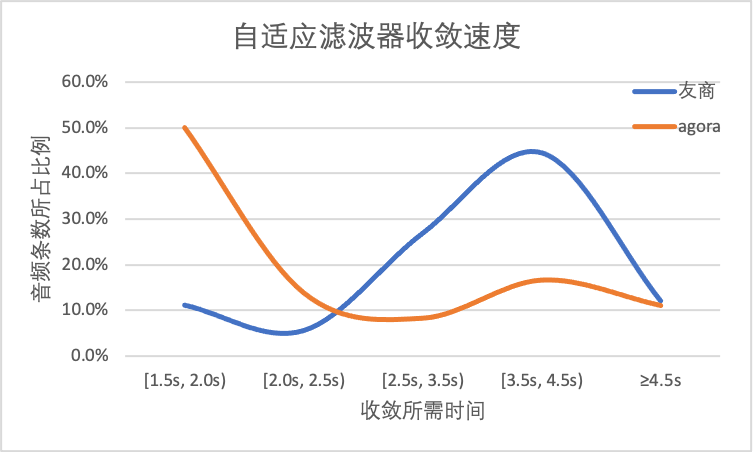
下图显示的是自适应滤波器的收敛速度,声网 SDK 在 51% 的测试样本中能在通话前 3s 之内收敛到稳态,而友商的比例为13%。
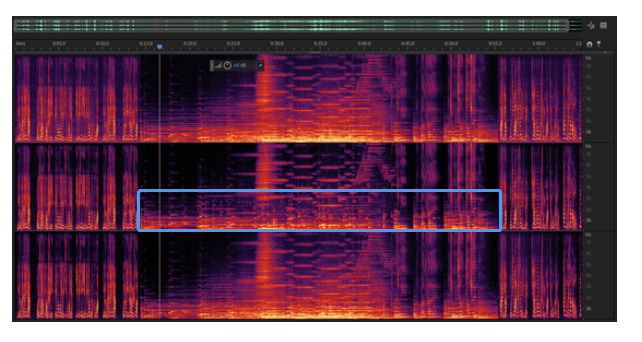
音质优先的降噪策略降噪对信号音质的影响大于回声消除模块,这一点源自于在降噪算法的设计之初,我们先验的假设底噪都是平稳信号(至少是短时平稳的),而根据这个假设,音乐跟底噪的区分度明显弱于语音跟底噪的区分度。声网 SDK 在降噪模块的前端预置了信号分类模块,能够精确的检测出信号的类型,并根据信号的类型调整降噪算法的类型及参数,常见的信号类型包括一般语音、清唱、音乐信号等。下图所示是两个降噪算法处理的信号片段,其中第一个是语音与音乐的混合信号,前15秒为含噪的语音信号,之后是40s是音乐信号,再之后是10s的含噪语音,语谱图从上到下分别是原始信号、友商处理结果、声网SDK处理结果。结果显示在语音段信号降噪性能差不多的前提下,竞品处理过信号中的音乐部分受到了严重的损伤,而声网SDK的处理并没有降低音乐的音质。
END