GDE全球开发者大赛-KPI异常检测告一段落,来自深圳福田莲花街道的“原子弹从入门到精通“有幸取得了总榜TOP1的成绩,下面给出他的解决方案。
核心网在移动运营商网络中占据举足轻重的地位,其异常往往会导致呼叫失败、网络延迟等现网故障,对全网的服务质量带来重大的负面影响,多则影响十数万用户,并引发大面积投诉[1]。因此需要快速及时地发现核心网的异常风险,在影响扩大之前及时消除故障。
KPI是一类能够反映网络性能与设备运行状态的指标,本赛题提供某运营商核心网的KPI真实数据,数据形式为KPI时间序列,采样间隔为1小时,选手需要使用[2019-08-01,2019-09-23)的数据进行建模,使用训练好的模型对未来7天的数据进行预测,识别未来一周KPI序列中的异常点。
评估指标:
本赛题采用F1作为评估指标,具体计算公式如下:
P = TP/(TP+FP)
R = TP/(TP+FN)
F1 = 2*P*R/(P+R)
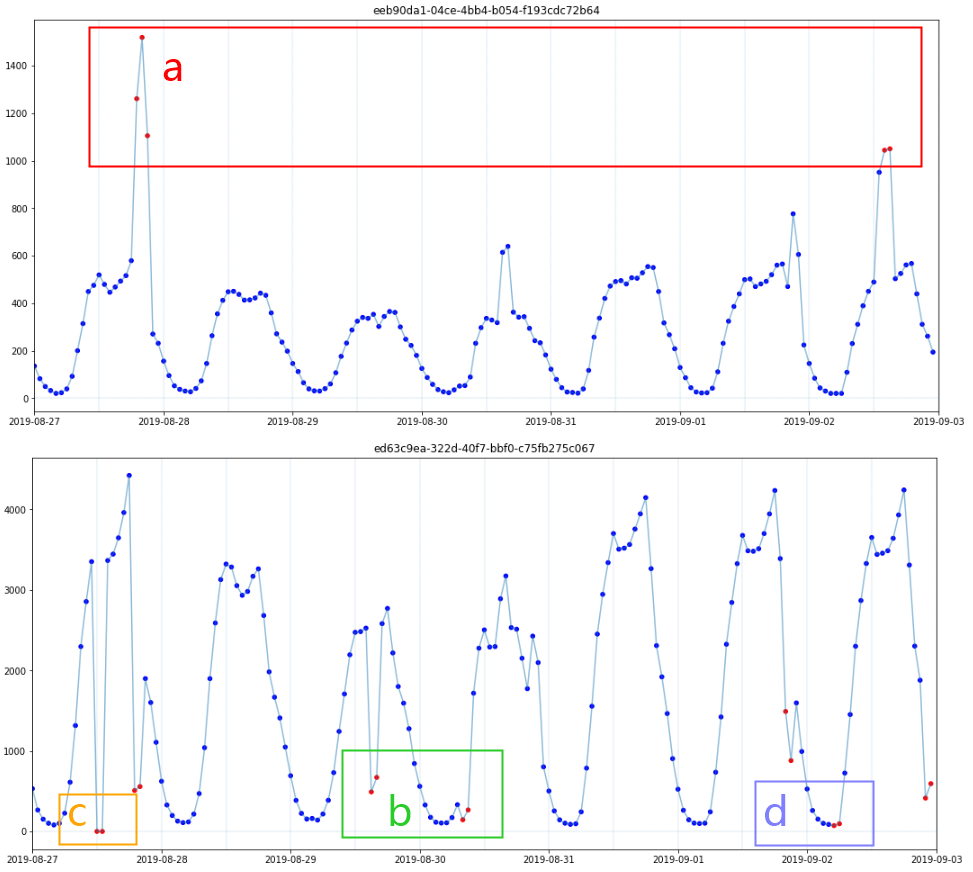
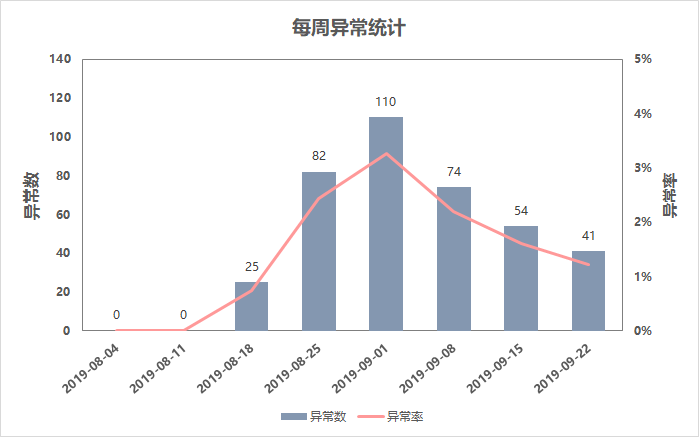
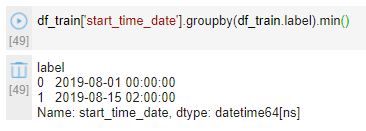
数据中共有20个不同的KPI,不同的KPI物理意义不同,代表了不同的核心网指标,由于赛题需要对未来7天的数据进行预测,因此对于建模样本也进行周级别的分布查看。从Fig1中可以明显看到训练集中前三周的异常率显著低于后续几周。进一步分析可以发现虽然赛题提供了[2019-08-01,2019-09-23)的全部数据,但2019-08-15之前所有20个KPI均毫无异常,第一个异常点是从2019-08-15 02:00:00开始出现的(Fig2),因此推测8.15前的数据分布不同于后续样本,或8.15之前存在标注异常的问题。实验中剔除8.15之前的样本建模效果也优于保留该时间段样本,进一步验证了该推测。时间序列图对于快速理解数据及业务有着重要的作用,对20个时间序列进行观察后,我将异常粗分为4类,如Fig3所示。Fig3. 异常分类(时间序列中红点为异常,蓝点为正常)如Fig3中a部分(红框)所示,边界型异常中异常样本的取值范围与正常值取值完全不同,即存在明确的决策边界可以完全分离异常点。
如Fig3中b部分(绿框)所示,正常样本点的走势往往沿着一个趋势,而趋势破坏型的异常点会偏离这个趋势,但取值范围可能仍然在正常样本的取值范围内,这类异常与相邻点的差异较大,与相同时刻正常点的取值差异也较大。
如Fig3中c部分(橙框)所示,此类异常取值直接为0,根据我对业务的理解,正常的KPI不应出现0值,根据分析,20个KPI中有19个正常取值均不应为0,仅1个KPI正常取值为0,非0则为异常。
如Fig3中d部分(紫框)所示,此类异常往往既没有破坏趋势,取值也在正常的范围内,但可能会偏离相同时刻的正常取值。
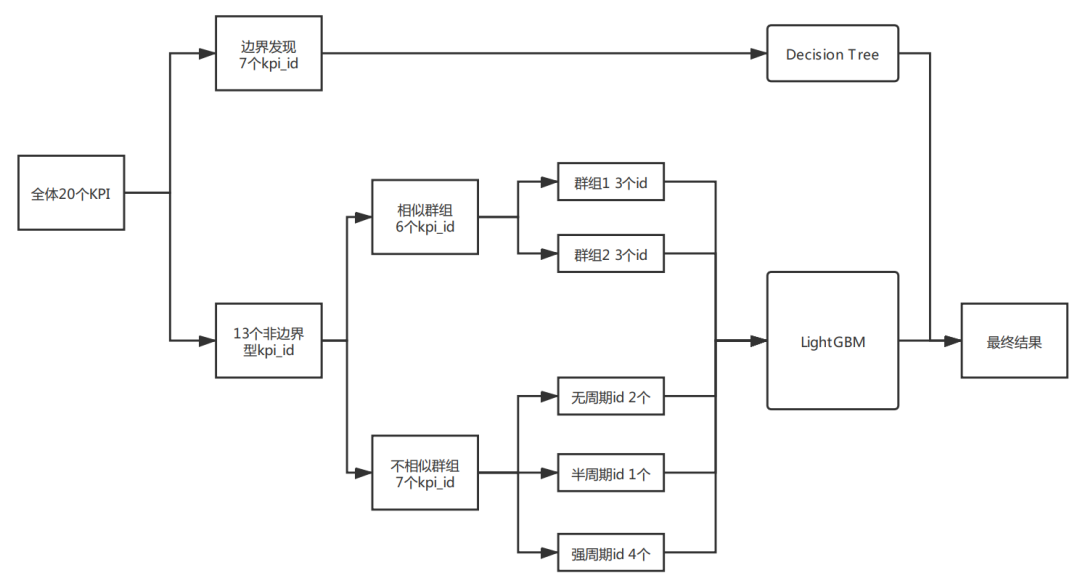
赛题中共有20个不同的KPI,KPI物理意义不同且异常的种类也多种多样,若将所有KPI作为一个整体建立一个统一的二分类模型,模型效果差强人意,难以进入前排,但若对每个KPI单独建模,则需要建立并维护调优至少20个不同的模型,维护成本过高,因此我的思路是将KPI或异常进行分类建模。
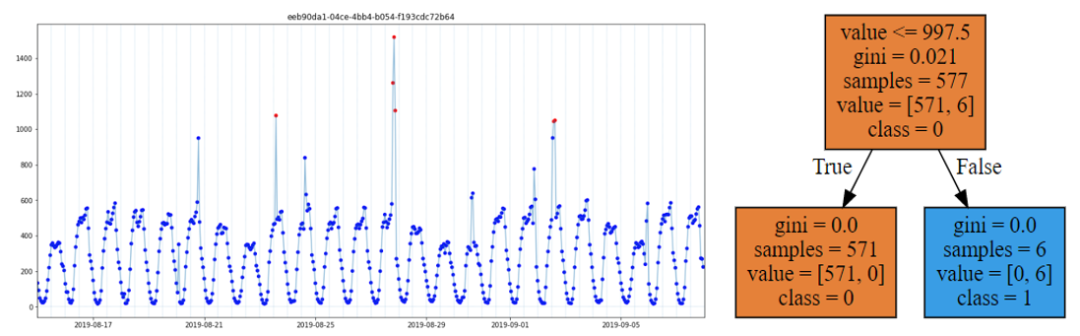
决策树会根据目标的分布将样本划分在不同的特征空间范围内(如Fig4 所示),非常适合用于边界的发现与确定。因此针对边界型异常,即好坏样本取值完全不同的异常,我采用决策树进行边界的自动发现与确定,具体如下:
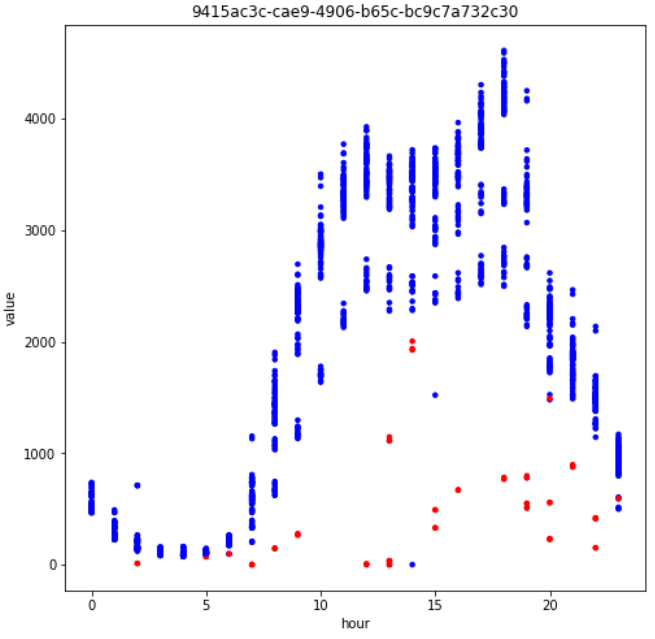
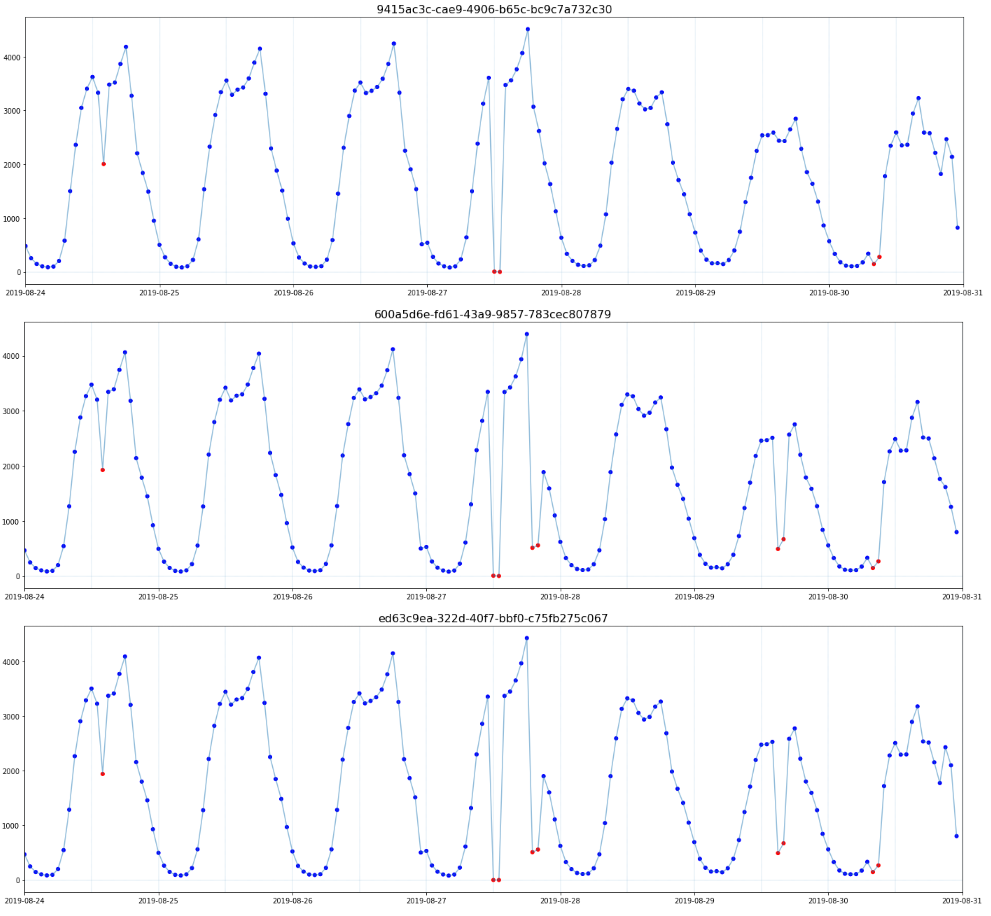
遍历20个KPI,若仅使用时间序列取值建立的单变量浅层简单决策树在训练集中的F1score=1,便认为该KPI为边界型异常KPI,并使用该决策树的预测结果作为决策边界,对相同KPI的未来样本进行预测。对KPI进行遍历后可知,存在7个KPI所有异常均为边界型异常,即7个KPI在训练集中的所有异常取值范围均不同于正常样本。最终结果也表明,该方案不仅在训练集中能100%识别边界型KPI的异常,在测试集中也能100%识别相关异常。非边界型异常往往KPI走势存在一定的周期,若将时间周期剥离出来进行分析,则可以从二维的角度对时间序列进行观察。以kpi_id= 9415a… 为例,若将日期信息剥离,x轴仅为一天中的第几小时,y轴仍然为时间序列取值,则会得到如Fig5的展示。此时整个时间序列被呈现在一个二维空间中,且异常值(红点)多与正常值(蓝点)偏离较远,一个朴素的思路便是采用无监督方法识别图中的异常。事实上,在实际的生产环境中,多达5000+原始KPI,300+衍生KPI,难以获得有异常标注的时间序列,因此在生产环境中往往使用统计方法或无监督算法进行异常检测[1,2]。但在当前有标签的赛题下,经多次尝试,无监督算法如iForest,DBSCAN以及时间序列分解方法如Prophet均无法胜过有监督机器学习算法。因此,对于非边界型异常,最终决定使用有监督机器学习算法进行建模。在3.1中基于简单决策树发现了7个边界型异常KPI,但剩余的13个KPI物理意义各不相同,需要进行分组建模。分组最基本的思想便是相似的KPI应该分在相同的组中。Pearson相关系数是我们最熟悉的相关性指标,其物理意义是表示两个变量同向或反向变动的程度,非常适合用于时间序列的相似性分析。通过对剩余13个KPI的相似性分析我们可以发现,以下两组id间的两两相关系数在0.9或以上。cluster1=[9415a…, 600a5…, ed63c…]cluster2=[b3842…, bb6bb…, 3fe4d…]以cluster1为例(Fig6.),可以看到相似性分组中不同KPI的时间序列不仅走势接近,而且往往当分组内一个KPI产生异常时,其他KPI也会同步异常,表现出非常高的联动性。因此对于相似性分组的模型建立非常关键,往往异常的召回和误报均为3倍,也就是对一个则3倍上分,错一个则3倍掉分,赛程中段快速上分的核心点便是这部分模型的建立。 对于剩余的7个KPI,最终我依据是否包含周期,将其划分为3小类进行分组建模:半周期型:cluster3_1 = [4f493…]无周期型:cluster3_2 = [29374…,8f522…]强周期型:cluster3_3 = [681cb…, 0a9f5…,355ed…,3e1f1…]其中,半周期型KPI仅在部分时间段表现出周期趋势,其他时间段取值几乎完全相同。无周期型KPI取值与时间无明显关联,强周期型KPI取值随时间不同产生周期性波动。根据前文分析以及我对时间序列问题的理解,本赛题中构造了以下5种类型的变量。1.基础变量:一天中的第几小时,星期几,kpi_id的各种编码如label encoder,target encoder等等;3.平移变量:上n个时间点该kpi_id的value或差分的取值及其简单衍生,如24小时前的value取值等;4.滑窗变量:过去n段时间该kpi_id的各类统计变量及其简单衍生,如过去24小时value的均值等;5.强相关窗口统计:如过去7天内该时间点上下两小时内介于该取值0.95-1.05范围内样本的总个数等等;鉴于本赛题难以建立一个能够应用于全部KPI的统一模型,而解题过程中有较多模型需要建立与调优,为提高效率,我在早期进行不同模型的若干次尝试后便决定使用训练速度较快且效果较好的LightGBM为各个分组建立二分类模型。在实际的建模中我发现仅用[2019-08-15,2019-09-08]的数据建模效果优于全部数据或使用更接近测试集样本的后几周数据,结合Fig1中异常率在后几周大幅持续降低的现象,我判断[2019-09-09,2019-09-22]的异常分布可能不同或存在部分标注问题。在进一步探索后发现嫁接学习的引入能够充分的使用到全部异常数据并取得更好的效果。嫁接学习是迁移学习的一种,用来描述将一个树模型a的输出作为另一个树模型b的输入的方法(a,b往往数据分布不同或完全属于不同产品,与同分布数据的常规融合有着本质区别),此种方法与树木繁殖中的嫁接类似,故而得名[3]。在IJCAI2018广告算法大赛中,前六天和最后一天数据分布不同,于是大部分人用同分布的第七天上半天的数据预测下半天,而植物大佬用前六天的数据训练了一个模型,预测第七天得到的分数作为第七天模型的特征,再用第七天上半天的数据预测下半天,最后轻松得到solo冠军,事后植物说这是他玩的最容易的比赛,毕竟人家用半天数据,植物用的是六天半的数据[3,4,5]。其他数据分布不同的场景下TOP方案中亦有嫁接学习的身影,如蚂蚁金服ATEC支付风险识别TOP1方案[6],CCF BDCI 2018 个性化套餐匹配TOP1方案[7]等[3] 。在若干次尝试后,我最终确定了以存在异常日期样本为1层模型样本, [2019-08-15,2019-09-08]样本结合1层模型分数作为2层模型输入的方案,模型框架如Fig7.所示,该框架的引入在本赛题中提分明显,是上分的关键点之一。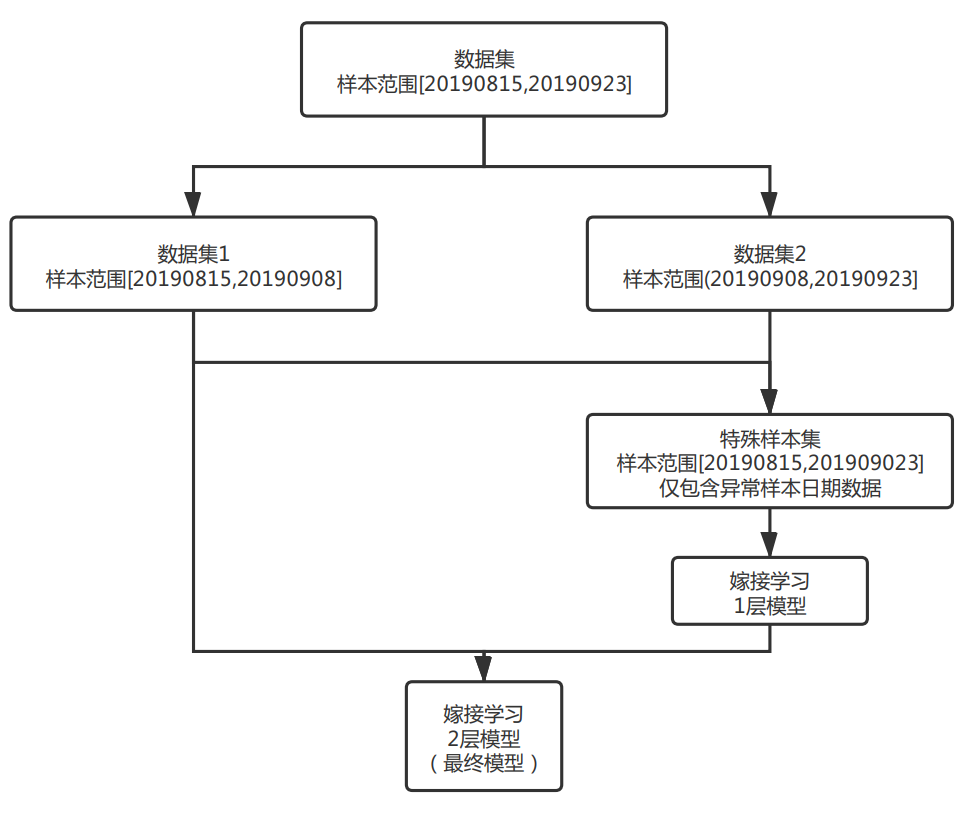
结合前文的内容,最终我的建模方案如Fig8所示,先进行KPI边界的自动发现,解决7个边界型KPI的异常,对于剩余的13个KPI,先根据相似性将其拆解为相似群组(6个KPI)和不相似群组(7个KPI),相似群组由组内相关系数较高的cluster1和cluster2构成,不相似群组按照是否包含周期划分为半周期群组cluster3_1,无周期群组cluster3_2和强周期群组cluster3_3,再对不同的群组分别建模,最后汇总生成最终结果。最终该方案取得了线上最高分及答辩最高分的成绩。非常感谢希旭哥,苕芸博士,素颜姐,小爱姐等人在比赛过程中的帮助与指导,希旭哥还是一如既往的热情,总能在第一时间为大家答疑解惑。
感谢庐山大佬赛后的精彩分享[2],让人受益匪浅。以前我没看过华为云开发者沙龙的分享,这次看完后觉得可针不戳,以后每期都不能错过。[1] 网络AI-KPI异常检测,利器大揭秘https://bbs.huaweicloud.com/videos/103579[2] DevRun开发者沙龙—火遍网络的KPI异常检测到底什么https://vhall.huawei.com/fe/watch/6658[3] 嫁接学习简述https://zhuanlan.zhihu.com/p/98728768[4] 结构化数据的迁移学习:嫁接学习https://zhuanlan.zhihu.com/p/51901122[5] IJCAI-2018 TOP1分享https://github.com/plantsgo/ijcai-2018[6] ATEC支付风险大赛Top1解决方案https://zhuanlan.zhihu.com/p/45826529[7] CCF BDCI 2018 个性化套餐匹配TOP1方案https://github.com/PPshrimpGo/BDCI2018-ChinauUicom-1st-solution加群交流学习