
前端视角解读 Why Rust
大厂技术 高级前端 精选文章
点击上方 全站前端精选,关注公众号
回复1,加入高级前段交流群
为什么要学 Rust
因为我们需要使用合适的工具解决合适的问题
目前 Rust 对 WebAssembly 的支持是最好的,对于前端开发来说,可以将 CPU 密集型的 JavaScript 逻辑用 Rust 重写,然后再用 WebAssembly 来运行,JavaScript 和 Rust 的结合将会让你获得驾驭一切的力量。
但是 Rust 被公认是很难学的语言,学习曲线很陡峭。(学不动了
对于前端而言,所需要经历的思维转变会比其他语言更多。从命令式(imperative)编程语言转换到函数式(functional)编程语言、从变量的可变性(mutable)迁移到不可变性(immutable)、从弱类型语言迁移到强类型语言,以及从手工或者自动内存管理到通过生命周期来管理内存,难度逐级递增。
而当我们迈过了这些思维转变后,会发现 Rust 的确有过人之处:
从内核来看,它重塑了我们对一些基本概念的理解。比如 Rust 清晰地定义了变量在一个作用域下的生命周期,让开发者在摒弃垃圾回收(GC)前提下,还能够无需关心手动内存管理,让内存安全和高性能二者兼得。
从外观来看,它使用起来感觉很像 Python/TypeScript 这样的高级语言,表达能力一流,但性能丝毫不输于 C/C++,从而让表达力和高性能二者兼得。
拥有友好的编译器和清晰明确的错误提示与完整的文档,基本可以做到只要编译通过,即可上线。
大概了解这些后,那我们开始从几个简单的 Rust demo 开始吧~
Ps:这篇文章并不能带你直接掌握或者入门 Rust,并不会涉及到过多 api 讲解,如有需求可直接跳转文末参考资料。
Rust 初体验
可使用 Rust Playground[1] 快速体验
Hello World
// main()函数在独立可执行文件中是不可或缺的,是程序的入口
fn main() {
// 创建String类型的字符串字面量,使用 let 创建的默认是不可变的
let target = String::from("rust");
// println!()是一个宏,用于将参数输出到 STDOUT
println!("Hello World: {}", target);
}
函数抽象示例
fn apply(value: i32, f: fn(i32) -> i32) -> i32 {
f(value)
}
// 入参和返回类型为i32(有符号,大小在[-2^31, 2^31 - 1]范围内的数字类型)
fn square(value: i32) -> i32 {
// 没有写;代表直接返回,相当于 return value * value;
value * value
}
fn cube(value: i32) -> i32 {
value * value * value
}
fn main() {
// js中相当于console.log(`apply square: ${apply(2, square)}`)
println!("apply square: {}", apply(2, square));
println!("apply cube: {}", apply(2, cube));
}
控制流与枚举
// 4种硬币的值都属于 Coin 类型
enum Coin {
Penny,
Nickel,
Dime,
Quarter,
}
fn value_in_cents(coin: Coin) -> u8 {
// 使用 match 进行类型匹配
match coin {
Coin::Penny => 1,
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter => 25,
}
}
先聊聊堆和栈
我们在写 js 的时候,似乎不需要特别关注堆和栈以及内存的分配,js 会帮忙我们“自动”搞定一切。但这个“自动”正是一切混乱的根源,让我们错误的感觉我们可以不关心内存管理。
我们重新回过来看一看这些基础知识,以及 Rust 是怎么处理内存管理的。
栈空间
栈的特点是 “LIFO,即后进先出” 。数据存储时只能从顶部逐个存入,取出时也需从顶部逐个取出。比如一个乒乓球的盒子,先放进去(入栈)的乒乓球就只能后出来(出栈)。
在每次调用函数,都会在栈的顶端创建一个栈帧,用来保存该函数的上下文数据。比如该函数内部声明的局部变量通常会保存在栈帧中。当该函数返回时,函数返回值也保留在该栈帧中。当函数调用者从栈帧中取得该函数返回值后,该栈帧被释放。
堆空间
不同于栈空间由操作系统跟踪管理,堆的特点是 无序 的key-value 键值对 存储方式。
堆是在程序运行时,而不是在程序编译时,申请某个大小的内存空间。即动态分配内存,对其访问和对一般内存的访问没有区别。对于堆,我们可以随心所欲的进行增加变量和删除变量,不用遵循次序。
可以这么总结:
栈适合存放存活时间短的数据。 数据要存放于栈中,要求数据所属数据类型的大小是已知的。 使用栈的效率要高于使用堆。
对于存入栈上的值,它的大小在编译期就需要确定。栈上存储的变量生命周期在当前调用栈的作用域内,无法跨调用栈引用。
堆可以存入大小未知或者动态伸缩的数据类型。堆上存储的变量,其生命周期从分配后开始,一直到释放时才结束,因此堆上的变量允许在多个调用栈之间引用。
可以将栈理解为将物品放进大小合适的纸箱并将纸箱按规律放进储物间,堆理解为在储物间随便找一个空位置来放置物品。显然,以纸箱为单位来存取物品的效率要高的多,而直接将物品放进凌乱的储物间的效率要低的多,而且储物间随意堆放的东西越多,空闲位置就越零碎,存取物品的效率就越低,且空间利用率就越低。
Rust 如何使用堆和栈
问题来了,我们先看看 JavaScript 是如何使用堆和栈的
JavaScript 中的内存也分为栈内存和堆内存。一般来说:
栈内存中存放的是存储对象的地址;
而堆内存中存放的是存储对象的具体内容。
对于原始类型的值而言,其地址和具体内容都存在于栈内存中;
而基于引用类型的值,其地址存在栈内存,其具体内容存在堆内存中。
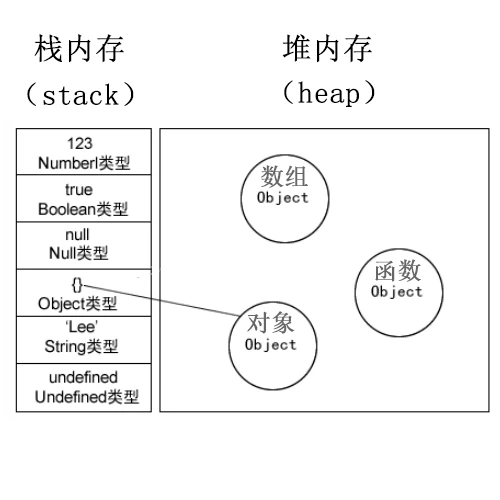
Rust 中各种类型的值默认都存储在栈中,除非显式地使用Box::new()将它们存放在堆上。对于动态大小的类型 (如 Vec、String),则数据部分分布在堆中,并在栈中留下胖指针指向实际的数据,栈中的那个胖指针结构是静态大小的。
在堆与栈的使用中,各个语言看起来是差不多的,主要区别在于 GC 上。
在 JavaScript 的 GC 中,因为没有一些高级语言所拥有的垃圾回收器,js 自动寻找是否一些内存“不再需要”是很难判定的。因此,js 的垃圾回收实现只能有限制的解决一般问题。
比如现在对于引用的垃圾回收,使用的标记-清除算法[2],仍然会存在那些无法从根对象查询到的对象都将被清除的限制(尽管这是一个限制,但实践中我们很少会碰到类似的情况,所以开发者不太会去关心垃圾回收机制)。
而 Rust 不同于其他的高级语言,它没有提供 GC,也无需手动申请和手动释放堆内存,但 Rust 可以保证我们当前的内存是安全的,即不会出现悬空指针等问题。其中一个原因是因为 Rust 使用了自己的一套内存管理机制:Rust 中所有的大括号都是一个独立的作用域,作用域内的变量在离开作用域时会失效,而变量绑定的数据(无论是堆内还是栈中数据)则自动被释放。
fn main() {
// 每个大括号都是独立的作用域
{
let n = 33;
println!("{}", n);
}
// 变量n在这个时候失效
// println!("{}", n); // 编译错误
}
那如果碰到这种情况呢:
fn main() {
let v = vec![1, 2, 3];
println!("{}", v[0]);
}
v 变量本身分配在栈中,用一个胖指针指向了堆中 v 里的三个元素。当函数退出后,v 的作用域结束了,它所引用的堆中的元素也会被自动回收,听起来不错。
但问题来了,如果想要将 v 的值绑定在另一个变量 v2 上,会出现什么情况呢?
对于有 GC 的系统来说,这不是问题,v 和 v2 都引用同一个堆中的引用,最终由 GC 来回收就是了。
对于没有 GC 的 Rust 而言,自然有它的办法,那就是所有权特性中的 move 语义,这个我们在后面会讲到。
Rust 语言特性
所有权和生命周期的存在使 Rust 成为内存安全、没有 GC 的高效语言。
所有权:掌控值的生死大权
计算机的内存资源非常宝贵,所有的程序运行的时候都需要某种方式来合理地利用计算机的内存资源,我们再看一下常见的几种语言是如何利用内存的:
语言 | 内存使用方案 |
Java、Go | 垃圾回收机制,不停地查看一些内存是否没有在使用了,如果不再需要就将其释放,占用更多的内存和CPU资源 |
C、C++ | 程序员自己手动申请和释放内存,容易出错且难以排查 |
JavaScript | 在创建变量(对象,字符串等)时自动进行了分配内存,并且在不使用它们时“自动”释放。这个“自动”是混乱的根源,并让 JavaScript(和其他高级语言)开发者错误的感觉他们可以不关心内存管理。 |
Rust | 所有权机制,内存由所有权系统根据一系列的规则来管理,这些规则只会在程序编译期间检查 |
Rust 的流行和受欢迎是因为它可以在不使用垃圾收集的同时保证内存安全。而其它诸如 JavaScript、Go 等语言则是使用垃圾收集来做内存管理,垃圾收集器以资源和性能为代价为开发人员提供了方便,但是一旦碰到问题,就会很难排查。在 rust 世界里,当你严格遵循规则的时候,就可以抛开垃圾收集实现内存安全。
我们先从一个变量使用堆栈的行为开始,探究 Rust 设计所有权和生命周期的用意。
变量在函数调用时发生了什么
我们先来看一段代码:
fn main() {
// 定义一个动态数组
let data = vec![10, 42, 9, 8];
let v = 42;
// 使用 if let 进行模式匹配。
// 它和直接 if 判断的区别是 if 匹配的是布尔值而 if let 匹配的是模式
if let Some(pos) = find_pos(data, v) {
println!("Found {} at {}", v, pos);
}
}
// 在 data 中查找 v 是否存在,存在则返回 v 在 data 中的下标,不存在返回 None
fn find_pos(data: Vec<u32>, v: u32) -> Option<usize> {
for (pos, item) in data.iter().enumerate() {
// 解除 item 的引用,可以访问到 item 的具体值
if *item == v {
return Some(pos);
}
}
None
}
Option 是 Rust 的系统类型,它是一个枚举,包含了 Some 和 None,用来表示值不存在的可能,这在编程中是一个好的实践,它强制 Rust 检测和处理值不存在的情况。
这段代码不难理解,要再强调一下的是,动态数组因为大小在编译期无法确定,所以放在堆上,并且在栈上有一个包含了长度和容量的胖指针指向堆上的内存。
在调用 find_pos() 时,main() 函数中的局部变量 data 和 v 作为参数传递给了 find_pos(),所以它们会被放在 find_pos() 的参数区。
按照大多数编程语言的做法,现在堆上的内存就有了两个引用。不光如此,我们每把 data 作为参数传递一次,堆上的内存就会多一次引用。
但是,这些引用究竟会做什么操作,我们不得而知,也无从限制;而且堆上的内存究竟什么时候能释放,尤其在多个调用栈引用时,很难厘清,取决于最后一个引用什么时候结束。所以,这样一个看似简单的函数调用,给内存管理带来了极大麻烦。
所有权和 Move 语义
在 Rust 的所有权规则下,上述的问题将不再是问题,所有权规则可以总结:
一个值只能被一个变量所拥有,这个变量被称为所有者。
一个值同一时刻只能有一个所有者。
当所有者离开作用域,其拥有的值被丢弃,内存得到释放。
在所有权的规则下,我们看一下上述的引用问题是如何解决的: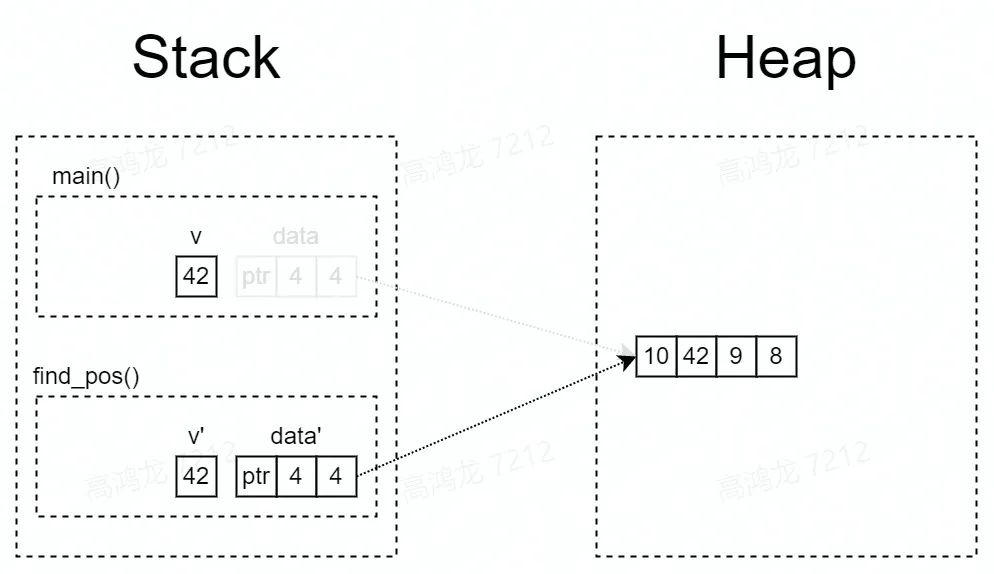
原先 main() 函数中的 data,被移动到 find_pos() 后,就失效了,编译器会保证 main() 函数随后的代码无法访问这个变量,这样,就确保了堆上的内存依旧只有唯一的引用。
但为什么 v 没有被移动反而依旧被复制了呢?一会你就明白了。
所以在所有权规则下,解决了谁真正拥有值的生死大权问题,让堆上数据的多重引用不复存在,这是它最大的优势。
但是很明显它也产生了一些问题,最大的一个就是会让代码变得很复杂,尤其是一些只存储在栈上的简单数据,如果要避免所有权转移之后不能访问的情况,我们就需要调用 clone() 来进行复制,这样效率也不会很高。
Rust 考虑到了这一点,所以在 Move 语义之外,Rust 还提供了 Copy 语义。如果一个数据结构实现了 Copy trait[3],那么它就会使用 Copy 语义。这样,在你赋值或者传参时,值会自动按位拷贝(浅拷贝)。
#[derive(Debug)]
struct Foo;
let x = Foo;
let y = x; // unused variable: `y`
// `x` has moved into `y`, and so cannot be used
println!("{:?}", x); // error: use of moved value
#[derive(Debug, Copy, Clone)]
struct Foo;
let x = Foo;
// 变量命名前加_代表这个变量处于 todo 状态,编译器会忽视 unused 检查
let _y = x;
// `y` is a copy of `x`
println!("{:?}", x); // A-OK!
struct:可以视为 es6 中的 class,但建议还是将 struct 视作是纯粹的数据。
trait:类似于接口,特性与接口相同的地方在于它们都是一种行为规范,可以用于标识哪些类有哪些方法。
derive:派生,编译器可以通过 derive 为 trait 加上一些基本实现,如
Copy[4]:使类型具有 “复制语义”而非 “移动语义”。
Clone[5]:可以明确地创建一个值的深拷贝,在使用 Copy 的派生时一般需要把 Clone 加上,因为 Clone 是 Copy 的超集。
Debug[6]:使用
{:?}可以完整地打印当前值。
回到 v 参数的那个问题,因为 v 是 u32 类型实现了 Copy trait,且分配在栈上,调用 find_pos 时便会自动 Copy 了一份 v' 。
但如果我们不想使用 copy 语义,避免内存过多的被复制,我们可以使用“借用”数据。
值的借用
我们来看新的一个例子:
fn main() {
let data = vec![1, 2, 3, 4];
let data1 = data;
println!("sum of data1: {}", sum(data1));
println!("data1: {:?}", data1); // error1
println!("sum of data: {}", sum(data)); // error2
}
fn sum(data: Vec<u32>) -> u32 {
// 创建一个迭代器,fold 方法用法类似 reduce
data.iter().fold(0, |acc, x| acc + x)
}
很明显上述代码无法通过编译,data 和 data1 在执行赋值语句和执行 sum 方法的时候,所有权均被 move 过去了,在后面再调用他们自然会报错。
编译器也非常智能地提示了我们错误所在:
error[E0382]: borrow of moved value: `data1`
--> src/main.rs:5:29
|
3 | let data1 = data;
| ----- move occurs because `data1` has type `Vec<u32>`, which does not implement the `Copy` trait
4 | println!("sum of data1: {}", sum(data1));
| ----- value moved here
5 | println!("data1: {:?}", data1); // error1
| ^^^^^ value borrowed here after move
error[E0382]: use of moved value: `data`
--> src/main.rs:6:37
|
2 | let data = vec![1, 2, 3, 4];
| ---- move occurs because `data` has type `Vec<u32>`, which does not implement the `Copy` trait
3 | let data1 = data;
| ---- value moved here
...
6 | println!("sum of data: {}", sum(data)); // error2
| ^^^^ value used here after move
For more information about this error, try `rustc --explain E0382`.
error: could not compile `playground` due to 2 previous errors
但我们只需要这样改一下,可以不使用 copy 的情况下通过编译:
fn main() {
let data = vec![1, 2, 3, 4];
let data1 = &data;
println!("sum of data1: {}", sum(&data1));
println!("data1: {:?}", data1);
println!("sum of data: {}", sum(&data));
}
fn sum(data: &Vec<u32>) -> u32 {
data.iter().fold(0, |acc, x| acc + x)
}
使用 & 可以来实现 Borrow 语义。顾名思义,Borrow 语义允许一个值的所有权,在不发生转移的情况下,被其它上下文使用。
在 Rust 中,“借用”和“引用”是一个概念,同时在 Rust 下,所有的引用都只是借用了“临时使用权”,它并不破坏值的单一所有权约束。
所以,默认情况下,Rust 的“借用”都是只读的。
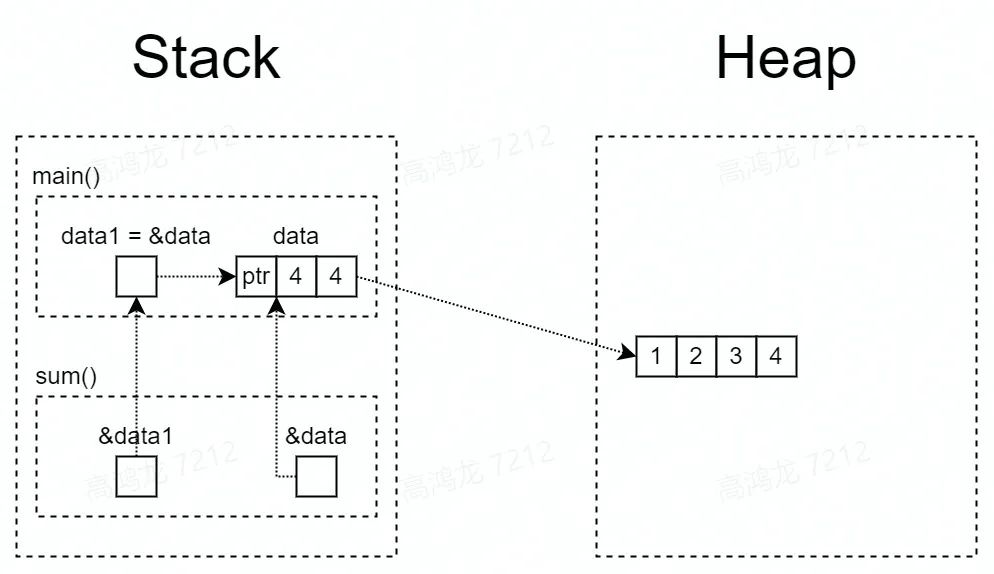
当然,我们对值的借用也得有一个限制:借用不能超过值的生命周期。
生命周期我们熟悉,写 React 或者 Vue 的时候,每个组件都有从创建到销毁的生命周期,那在 Rust 里,值的生命周期是怎么样的呢,值的借用限制什么和生命周期有关呢,我们接着往下看。
生命周期:我们创建的值可以活多久
在任何语言里,栈上的值都有自己的生命周期,它和帧的生命周期一致。
在 Rust 中,堆上的内存也引入生命周期的概念:除非显式地做 Box::leak() 等动作,一般来说,堆内存的生命周期,会默认和其栈内存的生命周期绑定在一起。
Box:使用 Box<T> 允许你将一个值放在堆上而不是栈上,留在栈上的则是指向堆数据的指针。除了数据被储存在堆上而不是栈上之外,box 没有性能损失,它们多用于如下场景:
当有一个在编译时未知大小的类型,而又想要在需要确切大小的上下文中使用这个类型值的时候(比如递归类型)
当有大量数据并希望在确保数据不被拷贝的情况下转移所有权的时候
我们先来看一个例子:
fn main() {
let r;
{
let x = 5;
r = &x;
}
println!("r: {}", r);
}
这段代码并不会通过编译,因为 r 所引用的值已经在使用之前被释放。
error[E0597]: `x` does not live long enough
--> src/main.rs:6:13
|
6 | r = &x;
| ^^ borrowed value does not live long enough
7 | }
| - `x` dropped here while still borrowed
8 |
9 | println!("r: {}", r);
| - borrow later used here
Rust 编译器有一个借用检查器,它比较作用域来确保所有的借用都是有效的,比如上述例子,我们加上生命周期的注释再看一下:
fn main() {
let r; // ---------+-- 'a
// |
{ // |
let x = 5; // -+-- 'b |
r = &x; // | |
} // -+ |
// |
println!("r: {}", r); // |
} // ---------+
如你所见,内部的 'b 块要比外部的生命周期 'a 小得多。在编译时,Rust 比较这两个生命周期的大小,并发现 r 拥有生命周期 'a,不过它引用了一个拥有生命周期 'b 的对象。程序被拒绝编译,因为生命周期 'b 比生命周期 'a 要小:被引用的对象比它的引用者存在的时间更短。
由此,我们也解释了 Rust 在值的借用中的那个规则:借用不能超过值的生命周期。
在 Rust 中,值的生命周期可分为:
静态生命周期:如果一个值的生命周期贯穿整个进程的生命周期,那么我们就称这种生命周期为静态生命周期。
动态生命周期:如果一个值是在某个作用域中定义的,也就是说它被创建在栈上或者堆上,那么其生命周期是动态的。
分配在堆和栈上的内存有其各自的作用域,生命周期是动态的。
全局变量、静态变量、字符串字面量、代码等内容,在编译时,会被编译到可执行文件中,加载入内存。生命周期和进程的生命周期一致,生命周期是静态的。
函数指针的生命周期也是静态的,因为函数在 Text 段中,只要进程活着,其内存一直存在。
有了这些概念,我们再来看一个例子:
fn main() {
let s1 = String::from("Lindsey");
let s2 = String::from("Rosie");
let result = max(&s1, &s2);
println!("bigger one: {}", result);
}
fn max(s1: &str, s2: &str) -> &str {
if s1 > s2 {
s1
} else {
s2
}
}
同样,这段代码也无法通过编译,编译器报错信息如下:
error[E0106]: missing lifetime specifier
--> src/main.rs:10:31
|
10 | fn max(s1: &str, s2: &str) -> &str {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `s1` or `s2`
help: consider introducing a named lifetime parameter
|
10 | fn max<'a>(s1: &'a str, s2: &'a str) -> &'a str {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `playground` due to previous error
Rust 的编译器始终是一个良师益友,十分严格且优秀,引导我写出更可靠而高效的代码。
missing lifetime specifier 意思是编译器在编译 max() 函数时,无法判断 s1、s2 和返回值的生命周期。
编译器也给了我们解决方法:手动添加生命周期注释,来告诉编译器 s1 和 s2 的生命周期。
fn max<'a>(s1: &'a str, s2: &'a str) -> &'a str {
if s1 > s2 {
s1
} else {
s2
}
}
这个例子或许大家看起来会很疑惑,s1 和 s2 的生命周期明明一致,为什么编译器会无法判断他们的生命周期呢?
其实很简单,刚刚我们提到过,字符串字面量的生命周期是静态的,而 s1 是动态的,它们的生命周期是不一致的。
当出现多个参数的时候,它们的生命周期不一致,返回的值的生命周期自然也不好确定,所以这个时候,我们需要进行生命周期标注,告诉编译器这些引用间生命周期的约束。
Rust 与 Webassembly
WebAssembly(wasm)可以在现代的网络浏览器中运行——它是一种低级的类汇编语言,具有紧凑的二进制格式,可以接近原生的性能运行。
简而言之,对于网络平台而言,WebAssembly 它提供了一条途径,以使得以各种语言编写的代码都可以以接近原生的速度在 Web 中运行。
对于前端而言,wasm 技术帮助解决一些场景下的性能瓶颈。
比如在浏览器中:
运行 VR、图像视频编辑、3D 游戏 可以更好的让一些语言和工具(如 AutoCAD)可以编译到 Web 平台 语言编译器或虚拟机等
脱离浏览器的情况下:
游戏分发服务(便携、安全)
服务端执行不可信任的代码。
服务端应用
移动混合原生应用
接下来,我们从一个图片处理的例子入手,看一下如何从零构建一个 web-wasm 应用。
环境准备
Rust[7]
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
在安装 Rustup 时,也会安装 Rust 构建工具和包管理器的最新稳定版,即 Cargo。
Cargo 可以做很多事情,如:
cargo build可以构建项目
cargo run可以运行项目cargo test可以测试项目cargo doc可以为项目构建文档cargo publish可以将库发布到 crates.io[8]。
很明显,Cargo 在 Rust 中扮演的 Npm 在 Node 中的角色。
Wasm-pack[9]
curl https://rustwasm.github.io/wasm-pack/installer/init.sh -sSf | sh
wasm-pack 用于构建和使用我们希望与 JavaScript,浏览器或 Node.js 互操作的 Rust 生成的 WebAssembly。
Vite[10]
这里的前端构建工具我使用的是 Vite,在 Vite 中还需要增加一个插件:
vite-plugin-rsw[11]:集成了 wasm-pack 的 CLI
支持 rust 包文件热更新,监听 src目录和Cargo.toml文件变更,自动构建
vite 启动优化,如果之前构建过,再次启动 npm run dev,则会跳过wasm-pack构建
快速开始
创建一个 vite 项目
yarn create vite vite-webassembly
添加 vite-plugin-rsw 插件
yarn add vite-plugin-rsw -D
并增加相应配置:
// vite.config.ts
import { defineConfig } from 'vite'
import react from '@vitejs/plugin-react'
import ViteRsw from 'vite-plugin-rsw'
export default defineConfig({
plugins: [
react(),
// 查看更多:https://github.com/lencx/vite-plugin-rsw
ViteRsw({
// 如果包在`unLinks`和`crates`都配置过
// 会执行,先卸载(npm unlink),再安装(npm link)
// 例如下面会执行
// `npm unlink picture-wasm`
unLinks: ['picture-wasm'],
// 项目根路径下的rust项目
// `@`开头的为npm组织
// 例如下面会执行:
// `npm link picture-wasm`
// 因为执行顺序原因,虽然上面的unLinks会把`picture-wasm`卸载
// 但是这里会重新进行安装
crates: [ picture-wasm ],
}),
],
})
使用 cargo 初始化一个 rust 项目
在当前目录下执行:
cargo new picture-wasm
我们先来看一下现在的目录结构
[my-wasm-app] # 项目根路径
|- [picture-wasm] # npm包 `wasm-hey`
| |- [pkg] # 生成wasm包的目录
| | |- picture-wasm_bg.wasm # wasm文件
| | |- picture-wasm.js # 包入口文件
| | |- picture-wasm_bg.wasm.d.ts # ts声明文件
| | |- picture-wasm.d.ts # ts声明文件
| | |- package.json
| | - ...
| |- [src] rust源代码
| | # 了解更多: https://doc.rust-lang.org/cargo/reference/cargo-targets.html
| |- [target] # 项目依赖,类似于npm的 `node_modules`
| | # 了解更多: https://doc.rust-lang.org/cargo/reference/manifest.html
| |- Cargo.toml # rust包管理清单
| - ...
|- [node_modules] # 前端的项目包依赖
|- [src] # 前端源代码(可以是vue, react, 或其他)
| # 了解更多: https://nodejs.dev/learn/the-package-json-guide
|- package.json # `yarn` 包管理清单
| # 了解更多: https://vitejs.dev/config
|- vite.config.ts # vite配置文件
| # 了解更多: https://www.typescriptlang.org/docs/handbook/tsconfig-json.html
|- tsconfig.json # typescript配置文件
可以看到,生成的 picture-wasm 项目中,有一个 Cargo.toml 文件,它就类似于我们的 package.json ,是用作 Rust 的包管理的一个清单。
往 Cargo.toml 中增加配置
[package]
name = "picture-wasm"
version = "0.1.0"
edition = "2021"
[lib]
crate-type = ["cdylib", "rlib"]
[dependencies]
wasm-bindgen = "0.2.70"
base64 = "0.12.1"
image = { version = "0.23.4", default-features = false, features = ["jpeg", "png"] }
console_error_panic_hook = { version = "0.1.1", optional = true }
wee_alloc = { version = "0.4.2", optional = true }
[dependencies.web-sys]
version = "0.3.4"
features = [
'Document',
'Element',
'HtmlElement',
'Node',
'Window',
]
dependencies:依赖列表
package:对于包的定义lib:我们当前是属于库工程(src 下是 lib.rs )而不是可执行工程(src 下是 main.rs),需要对其进行额外设置。rlib:Rust Library 特定静态中间库格式。如果只是纯 Rust 代码项目之间的依赖和调用,那么,用 rlib 就能完全满足使用需求(默认)。 cdylib:c 规范的动态库,它可以公开了 FFI 的一些功能,并可以被其他语言所调用。
添加 Rust 代码
// picture-wasm/src/lib.rs
// 链接到 `image` 和 `base64` 库,导入其中的项
extern crate image;
extern crate base64;
// 使用 `use` 从 image 的命名空间导入对应的方法
use image::DynamicImage;
use image::ImageFormat;
// 从 std(基础库)的命名空间导入对应方法,可用解构的方式
use std::io::{Cursor, Read, Seek, SeekFrom};
use std::panic;
use base64::{encode};
// 引入 wasm_bindgen 下 prelude 所有模块,用作 在 Rust 与 JavaScript 之间通信
use wasm_bindgen::prelude::*;
// 当`wee_alloc`特性启用的时候,使用`wee_alloc`作为全局分配器。
#[cfg(feature = "wee_alloc")]
#[global_allocator]
static ALLOC: wee_alloc::WeeAlloc = wee_alloc::WeeAlloc::INIT;
// #[wasm_bindgen] 属性表明它下面的函数可以在JavaScript和Rust中访问。
#[wasm_bindgen]
extern "C" {
// 该 extern 块将外部 JavaScript 函数 console.log 导入 Rust。
// 通过以这种方式声明它,wasm-bindgen 将创建 JavaScript 存根 console
// 允许我们在 Rust 和 JavaScript 之间来回传递字符串。
#[wasm_bindgen(js_namespace = console)]
fn log(s: &str);
}
fn load_image_from_array(_array: &[u8]) -> DynamicImage {
// 使用 match 进行兜底报错匹配
let img = match image::load_from_memory_with_format(_array, ImageFormat::Png) {
Ok(img) => img,
Err(error) => {
panic!("There was a problem opening the file: {:?}", error)
}
};
img
}
fn get_image_as_base64(_img: DynamicImage) -> String {
// 使用 mut 声明可变变量,类似 js 中的 let,不使用 mut 为不可变
// 使用 Cursor 创建一个内存缓存区,里面是动态数组类型
let mut c = Cursor::new(Vec::new());
// 写入图片
match _img.write_to(&mut c, ImageFormat::Png) {
Ok(c) => c,
Err(error) => {
panic!(
"There was a problem writing the resulting buffer: {:?}",
error
)
}
};
// 寻找以字节为单位的偏移量,直接用 unwrap 隐式处理 Option 类型,直接返回值或者报错
c.seek(SeekFrom::Start(0)).unwrap();
// 声明一个可变的动态数组作输出
let mut out = Vec::new();
c.read_to_end(&mut out).unwrap();
// 使用 encode 转换
let stt = encode(&mut out);
let together = format!("{}{}", "data:image/png;base64,", stt);
together
}
#[wasm_bindgen]
pub fn grayscale(_array: &[u8]) -> Result<(), JsValue> {
let mut img = load_image_from_array(_array);
img = img.grayscale();
let base64_str = get_image_as_base64(img);
append_img(base64_str)
}
pub fn append_img(image_src: String) -> Result<(), JsValue> {
// 使用 `web_sys` 来获取 window 对象
let window = web_sys::window().expect("no global `window` exists");
let document = window.document().expect("should have a document on window");
let body = document.body().expect("document should have a body");
// 创建 img 元素
// 使用 `?` 在出现错误的时候会直接返回 Err
let val = document.create_element("img")?;
// val.set_inner_html("Hello from Rust!");
val.set_attribute("src", &image_src)?;
val.set_attribute("style", "height: 200px")?;
body.append_child(&val)?;
log("success!");
Ok(())
}
React 项目中调用 Wasm 方法
// src/App.tsx
import React, { useEffect } from "react" ;
import init, { grayscale } from "picture-wasm" ;
import logo from "./logo.svg";
import "./App.css";
function App() {
useEffect(() => {
// wasm初始化,在调用`picture-wasm`包方法时
// 必须先保证已经进行过初始化,否则会报错
// 如果存在多个wasm包,则必须对每一个wasm包进行初始化
init();
}, []);
const fileImport = (e: any) => {
const selectedFile = e.target.files[0];
//获取读取我文件的File对象
// var selectedFile = document.getElementById( files ).files[0];
var reader = new FileReader(); //这是核心,读取操作就是由它完成.
reader.readAsArrayBuffer(selectedFile); //读取文件的内容,也可以读取文件的URL
reader.onload = (res: any) => {
var uint8Array = new Uint8Array(res.target.result as ArrayBuffer);
grayscale(uint8Array);
};
};
return (
<div className="App">
<header className="App-header">
<img src={logo} className="App-logo" alt="logo" />
<p>Hello WebAssembly!</p>
<p>Vite + Rust + React</p>
<input type="file" id="files" onChange={fileImport} />
</header>
</div>
);
}
export default App;
执行!
在根目录下执行 yarn dev ,rsw 插件会打包 rust 项目并软链接过来,这样一个本地彩色图片转换为黑白图片的 web-wasm 应用就完成了。
参考资料
[1]
Rust Playground: https://play.rust-lang.org/
[2]
标记-清除算法: https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Memory_Management#垃圾回收
[3]
Copy trait: https://doc.rust-lang.org/std/marker/trait.Copy.html
[4]
Copy: https://rustwiki.org/zh-CN/core/marker/trait.Copy.html
[5]
Clone: https://rustwiki.org/zh-CN/std/clone/trait.Clone.html
[6]
Debug: https://rustwiki.org/zh-CN/std/fmt/trait.Debug.html
[7]
Rust: https://www.rust-lang.org/zh-CN/
[8]
crates.io: https://crates.io/
[9]
Wasm-pack: https://github.com/rustwasm/wasm-pack
[10]
Vite: https://cn.vitejs.dev/
[11]
vite-plugin-rsw: https://github.com/lencx/vite-plugin-rsw
其他参考
陈天 · Rust 编程第一课 https://time.geekbang.org/column/article/408400
Rust 入门第一课 https://rust-book.junmajinlong.com/ch1/00.html
2021年 Rust 行业调研报告-InfoQ https://www.infoq.cn/article/umqbighceoa81yij7uyg
24 days from node.js to Rust
通过例子学 Rust https://rustwiki.org/zh-CN/rust-by-example/hello.html
客户端视角认识与感受 Rust 的红与黑 https://tech.bytedance.net/articles/7036575152028516365
实现一个简单的基于 WebAssembly 的图片处理应用https://juejin.cn/post/6844904205417709581
Rust 和 WebAssembly https://rustmagazine.github.io/rust_magazine_2021/chapter_2/rust_wasm_frontend.html
24 days from node.js to Rust
24 days from node.js to Rust (vino.dev)