
4次优化,我把Redis性能“压榨”到极致!
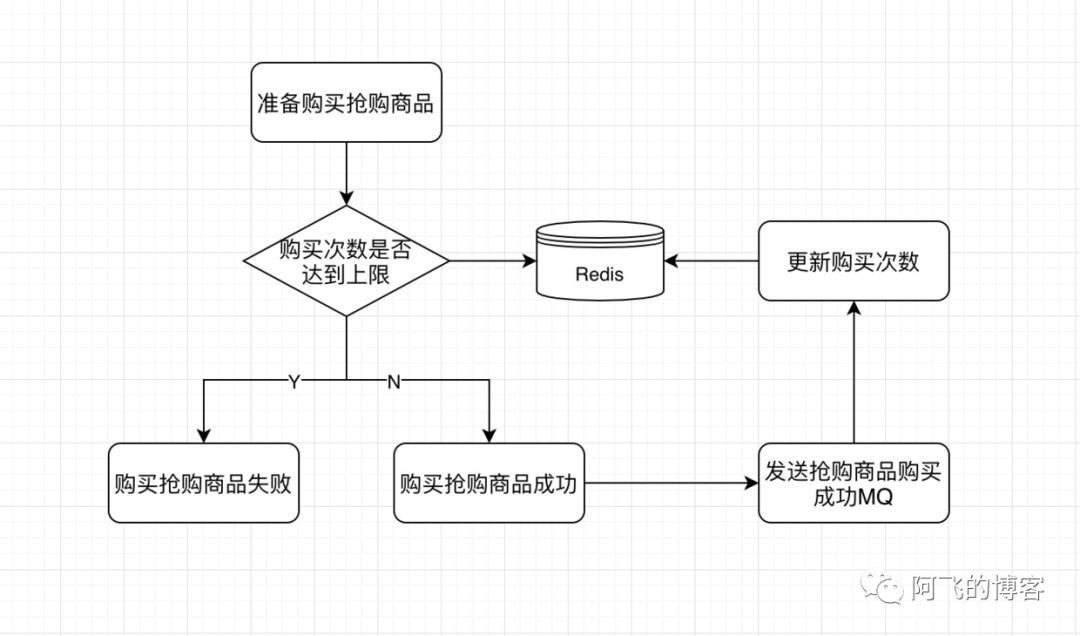
我们有个这样的需求:每天每一个抢购商品只能买一次,并且全场抢购商品总购买次数不允许超过5次。那么,整个商品限购的流程大概如下图所示:
[{
"orderId": "2020020622000001",
"orderTime": "1581001673012",
"productId": "599055114591",
"userId": "860000000000001",
"merchantCode": "A045"
}, {
"orderId": "2020020622000001",
"orderTime": "1581001673012",
"productId": "599055114592",
"userId": "860000000000001",
"merchantCode": "A045"
}]
命令1:hset mall:sale:freq:ctrl:8600000000000015990551145911(hash结构,field表示购买的商品ID,value表示购买次数)
命令2:hset mall:sale:freq:ctrl:8600000000000015990551145922
命令3:expire mall:sale:freq:ctrl:8600000000000013127(设置过期时间)
命令4:set mall:total:freq:ctrl:8600000000000013
命令5:expire mall:total:freq:ctrl:8600000000000013127(设置过期时间)
如下图所示:
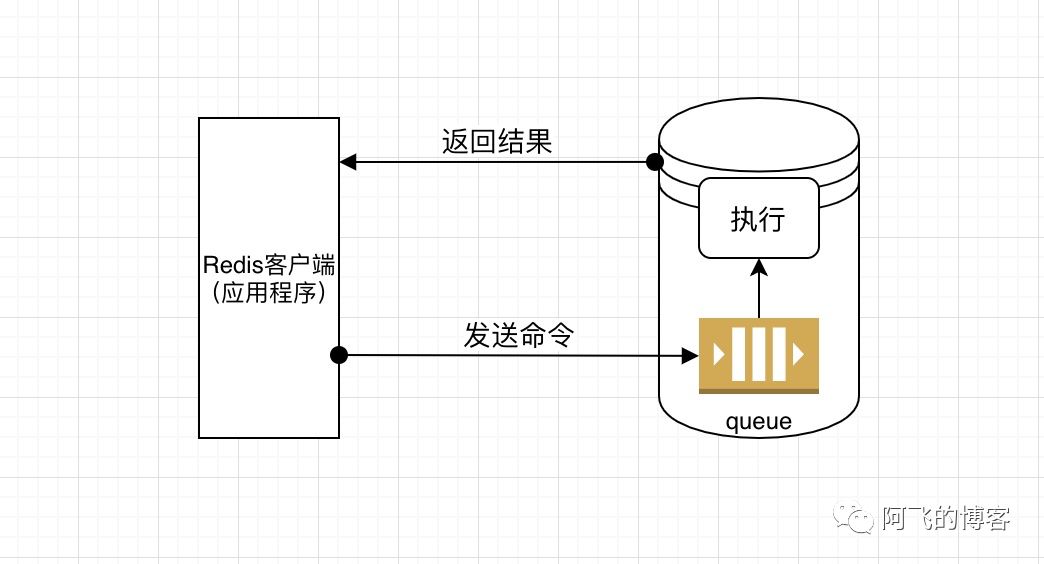
第1次优化
hmset mall:sale:freq:ctrl:860000000000001 599055114591 1 599055114592 2
expire mall:sale:freq:ctrl:860000000000001 3127
set mall:total:freq:ctrl:860000000000001 3
expire mall:total:freq:ctrl:860000000000001 3127第2次优化
hmset mall:sale:freq:ctrl:860000000000001 599055114591 1 599055114592 2
expire mall:sale:freq:ctrl:860000000000001 3127
setex mall:total:freq:ctrl:860000000000001 3127 3第3次优化
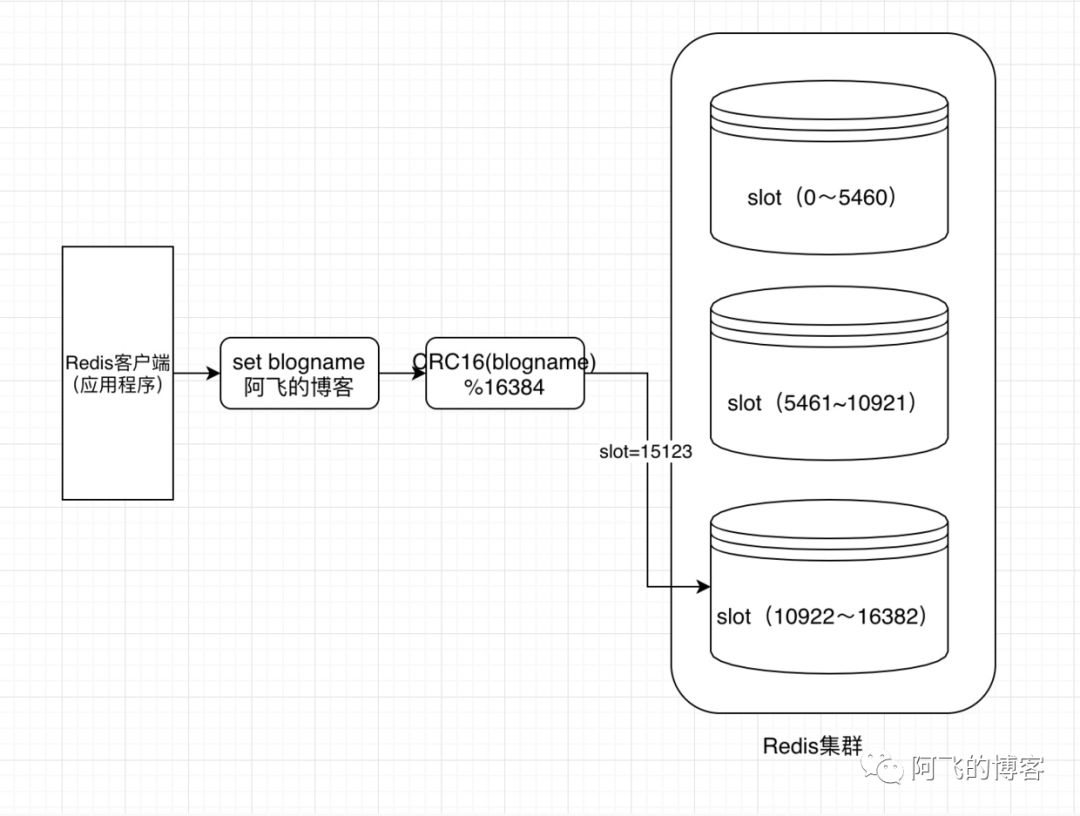
-- 这两条命令的key都是一样的,肯定在同一个slot上
pipeline(
hmset mall:sale:freq:ctrl:860000000000001 599055114591 1 599055114592 2
expire mall:sale:freq:ctrl:860000000000001 3127
)
-- mall:total:freq:ctrl:860000000000001和mall:sale:freq:ctrl:860000000000001两条命令不在同一个slot上,所以需要单独执行下面这条命令
setex mall:total:freq:ctrl:860000000000001 3127 3
第4次优化
pipeline(
hmset mall:sale:freq:ctrl:${860000000000001} 599055114591 1 599055114592 2
expire mall:sale:freq:ctrl:${860000000000001} 3127
setex mall:total:freq:ctrl:${860000000000001} 3127 3
)
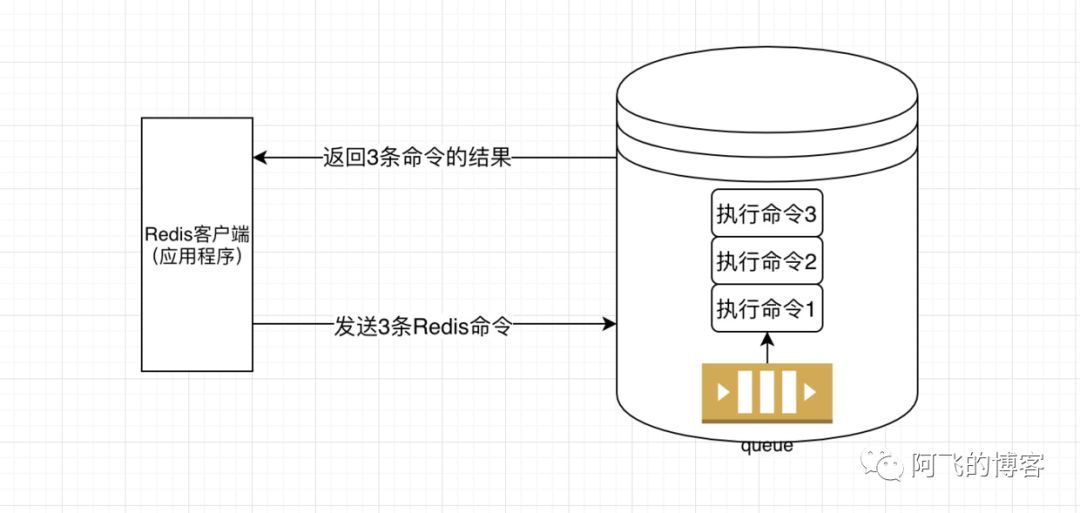 优化后,5条Redis命令压缩到3条Redis命令,并且3条Redis命令只需要发送一次,并且结果也一次就能全部返回。简直完美!!
优化后,5条Redis命令压缩到3条Redis命令,并且3条Redis命令只需要发送一次,并且结果也一次就能全部返回。简直完美!!注意事项

往 期 推 荐 1、Intellij IDEA这样 配置注释模板,让你瞬间高出一个逼格!
2、Spring+SpringMVC+Mybatis实现校园二手交易平台【实战项目】
5、惊呆了,Spring Boot居然这么耗内存!你知道吗?
7、Spring中毒太深,离开Spring我居然连最基本的接口都不会写了 点分享
点收藏
点点赞
点在看




评论