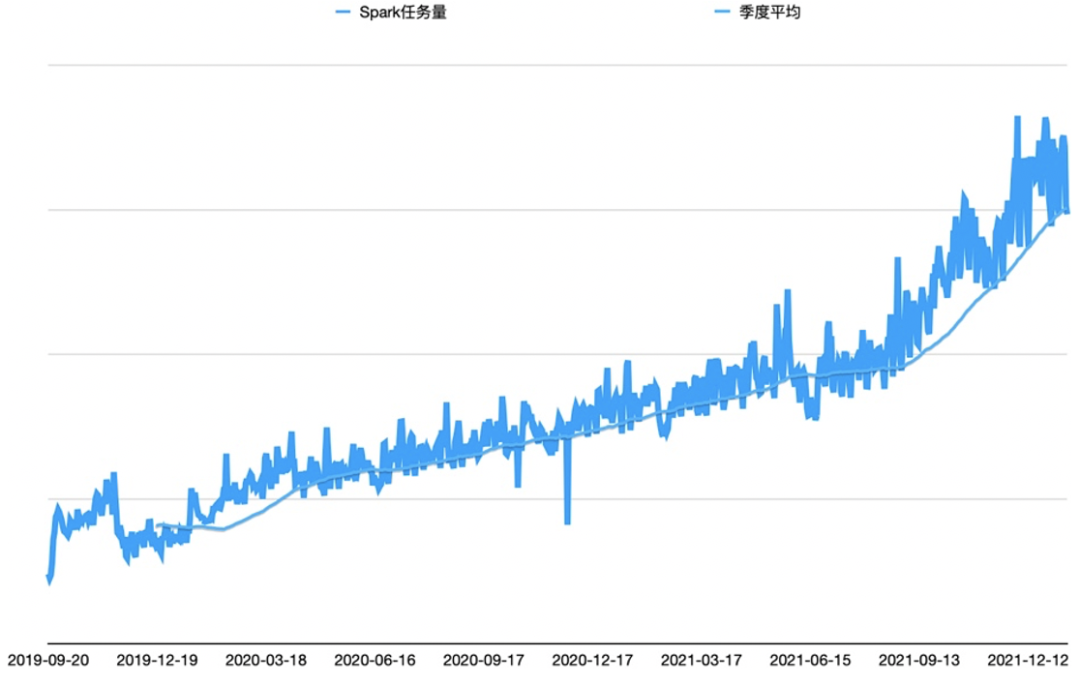
在详细介绍Runtime Filter Join特性之前,先对Spark SQL 的整体架构做一下概述, 由下图3可知,无论使用DataFrame、 SQL 语句还是使用DataSet ,都会经过如下步骤转换成 DAG 对 RDD 的操作:
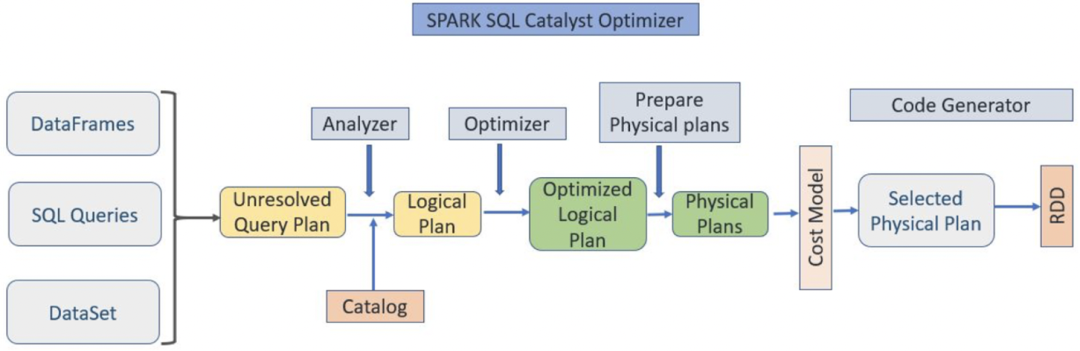
图 3 Spark SQL 的整体架构
1. 先解析 SQL,生成 Unresolved Logical Query Plan
2. 由 Analyzer 结合 Catalog 信息生成 Resolved Logical Plan
3. Optimizer根据预先定义好的规则对 Resolved Logical Plan 进行优化并生成 Optimized Logical Plan
4. Query Planner 将 Optimized Logical Plan 转换成多个 Physical Plan
5. 根据 Cost Model 算出每个 Physical Plan 的代价并选取代价最小的 Physical Plan 作为最终的 Physical Plan
6. Spark 以 DAG 的方法执行上述 Physical Plan
7. 在Spark 3.0版本以后,引入AQE(Adaptive Query Execution),其在执行 DAG 的过程中,会根据运行时信息动态调整执行计划从而提高执行效率。
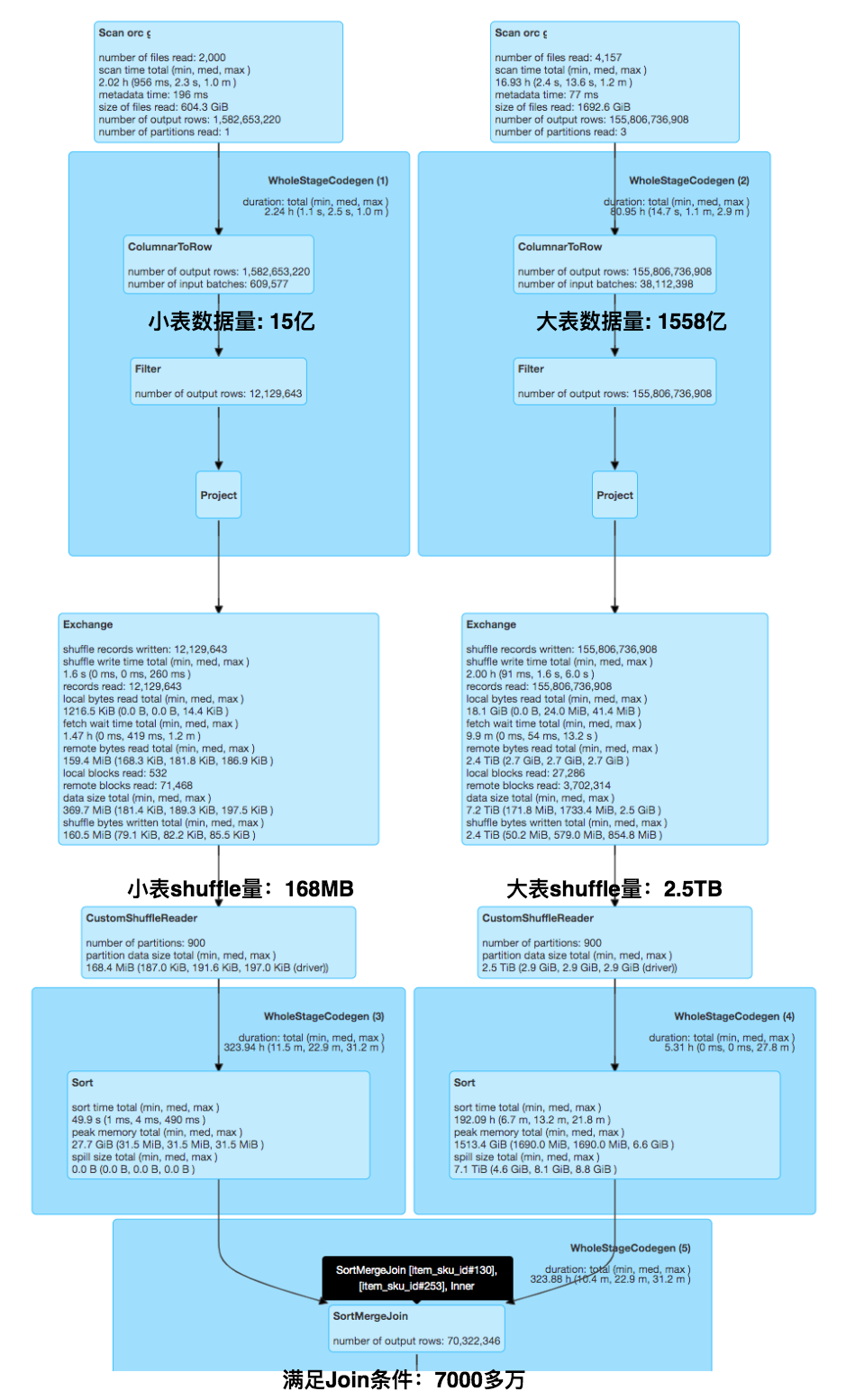
JD Spark Runtime Filter Join的技术实现包括:基于逻辑执行计划(Logical Plan)数据裁剪和基于物理执行计划(Physical Plan)数据裁剪,其中前者是在逻辑执行计划(Logical Plan)优化过程中(上述步骤3),动态基于小表数据构建BloomFilter,并将该BloomFilter 算子插入到大表侧对其进行过滤;后者是对前者场景的补充,如果未能在逻辑执行计划优化中动态插入BloomFilter算子对大表进行过滤,在物理执行计划优化中(上述步骤7),通过AQE基于小表构建BloomFilter并对大表进行过滤,二者的主要区别是前者是在大表shuffle 前进行过滤,后者是在大表shuffle后进行过滤,其具体实现架构如图4所示,为了描述方便我们这里结合一个case进行阐述,下面以Table-A Inner Join Table-B为例,其中Table-A是一张小表:
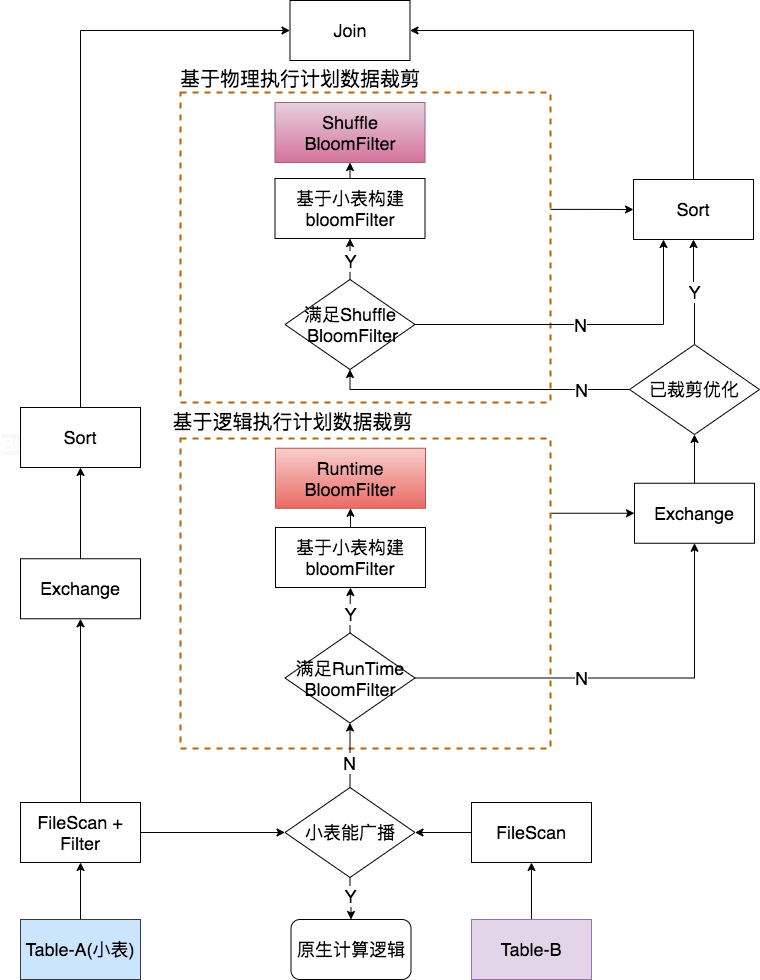
图 4 Runtime Filter Join架构图
基于Bloom Filter算法的Runtime Filter Join优化机制的执行流程如下:
1. 在逻辑执行计划过程中,我们实现了相应的Rule,首先判断小表Table-A 是否可以广播,如果可以广播会走BroadcastHashJoin,因BroadcastHashJoin不会引入shuffle、sort,往往性能表现良好,因此对于满足BroadcastHashJoin的场景,保持Spark原生计算逻辑;否则,会默认走SortMergeJoin;
2. 对于SortMergeJoin,上述Rule会根据表数据文件大小和schema信息对两个表的Row count进行评估,并基于两表的Row count信息进行代价评估(例如:Table-A-Row-count/Table-B-Row-count小于一定阈值等),当小表Row count与大表Row count满足一定条件,上述Rule会基于Table-A的join keys动态构建BloomFilter,我们定义为RuntimeBloomFilter,并作为Filter算子动态插入到Table-B的过滤条件中,因RuntimeBloomFilter会在大表shuffle前进行过滤,提前过滤掉大表侧join时不会被命中的数据,从而减少大表的shuffle量;
3. 在物理执行计划过程中,同样实现了相应的Rule,该Rule会根据Join策略的不同,检查SortMergeJoin的Left或Right节点中,是否在逻辑执行计划中已基于小表join keys构建了BloomFilter对大表侧进行过滤,如果存在,该步骤会自动跳过;否则,我们会基于AQE在执行计划中,基于小表join keys动态构建BloomFilter,这里定义其为ShuffleBloomFilter,并作为Filter算子动态插入读取大表shuffle数据后面,对shuffle数据过滤,从而减少大表join 前sort的数据量、减少spill数据量。这里与以上优化的不同点在于,其作为AQE的一条规则且依赖于AQE功能的开启,该项优化主要是用于优化中间Stage。
基于上述架构设计在实现中面临的挑战及技术攻坚:
1. BloomFilter算子支持codegen
为了实现上述架构设计,我们内部自定义了BloomFilter算子,为了提升该算子的处理性能,内部实现的BloomFilter算子支持codegen。
2. 支持多join keys场景且多个join keys只需一个BloomFilter
两张表join时,可能存在多个关联键,例如:Table-A a Inner Join Table-B b on a.col1=b.col1 and a.col2=b.col2,如果基于小表每个join key都构建一个BloomFilter并分别作为Filter算子对大表侧进行过滤,会导致多次读取小表,增加IO,另外由于BloomFilter是以广播向量的方式存在,如果产生过多的BloomFilter会带来driver和executor的内存压力,为此我们采用XxHash64 对join keys 进行处理,以获取一个新的散列值,基于新的散列值构建BloomFilter并对大表侧过滤,这样能够有效提升性能及减少OOM发生。
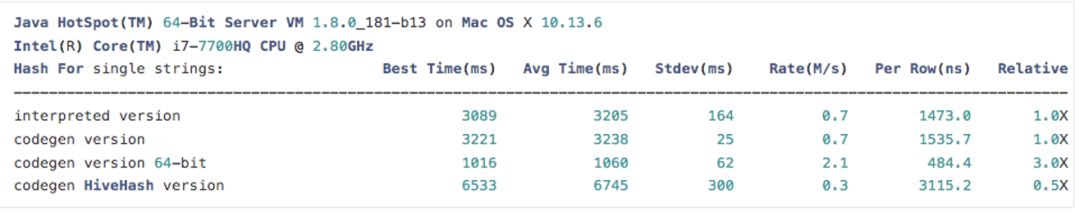
选取XxHash64 处理多join keys的原因:首先,XxHash64支持codegen,能够与上述实现的BloomFilter算子有机结合,另外基于HashBenchmark验证可知,XxHash64在处理基本数据类型相对Murmur3Hash、HiveHash均有不错的表现,且京东线上的join keys一般是string类型,下面是验证效果:
3. 设计构建BloomFilter的timeout fallback机制
结合上面的Runtime Filter Join的执行流程可知,两表join时如果触发了RuntimeBloomFilter或ShuffleBloomFilter特性,均会先基于小表构建相应的BloomFilter,然后再作为Filter算子对大表进行过滤,这就要求对大表的处理需要等待基于小表构建BloomFilter完后才执行,极端情况下可能会导致任务延迟问题,这在京东复杂、多变且SLA要求严格的背景下,如果想全场景铺开Runtime Filter Join特性会面临很大的挑战。为了解决上述问题,我们设计构建BloomFilter的timeout fallback机制,即在规定时间内未能完成基于“小表”构建BloomFilter,Spark执行计划会自动回退到原始处理逻辑,这样能够有效规避因大表被误判成小表,导致构建BloomFilter耗时过长所引起的性能回归问题等。
4. 设计Rule 支持BloomFilter 谓词下推
Spark SQL在多个join场景的一个典型优化就是谓词下推,即可以通过内部Rule优化,将某一组join的谓词下推到其他join,从而过滤掉其他join的无效数据,提升性能。通过分析京东线上业务场景,发现大部分任务存在多个join场景,例如:A as a join B as b on a.col1=b.col1 join C as c on a.col1=c.col1。然而,本文引入的BloomFilter算子是一种基于子查询的封装,基于Spark SQL 现有的内置Rule不能将其进行谓词下推,为此我们内部实现了相应的Rule支持BloomFilter算子的谓词下推,在满足多个join且关联键相同的情况下,该Rule能够基于某一组join构建的BloomFilter下推到其他join,最终实现基于一个BloomFilter过滤多组join的能力,下面结合一个案例进行展示,其中 tb1 和 tb2是两个大表,tb3是小表,其中tb1数据量10000条,tb2数据量是9000条,tb3数据量是10条。spark.range(100000) .select(col("id").as("a"), col("id").as("b"), col("id").as("c")) .write.format(tableFormat).mode(SaveMode.Overwrite) .saveAsTable("tb1")spark.range(9000) .select(col("id").as("a"), col("id").as("b"), col("id").as("c")) .write.format(tableFormat).mode(SaveMode.Overwrite) .saveAsTable("tb2")spark.range(10) .select(col("id").as("a"), col("id").as("b"), col("id").as("c")) .write.format(tableFormat).mode(SaveMode.Overwrite) .saveAsTable("tb3")set spark.sql.autoBroadcastJoinThreshold=-1;sql(s""" |SELECT tb1.a, | tb2.b |FROM tb1 | Inner JOIN tb3 | ON tb1.a = tb3.a AND tb3.b < 4 | Inner JOIN tb2 | ON tb1.a = tb2.a |""".stripMargin)
为了验证效果,我们这里关闭BroadcastHashJoin (spark.sql.autoBroadcastJoinThreshold=-1),执行上面语句,Spark会优先处理 tb1 Inner JOIN tb3 ON tb1.a = tb3.a AND tb3.b < 4,基于Bloom Filter算法的Runtime Filter Join优化机制会自动识别出tb3是一张小表,并基于tb3构建RuntimeBloomFilter对大表tb1进行过滤,然后进行SortMergeJoin,其DAG如图5所示,由图5可知tb1的数据量得到有效过滤,只保留满足join条件的4条数据,这在生产环境中的收益是显著的,具体上线效果在京东实际场景中的收益中会阐述。
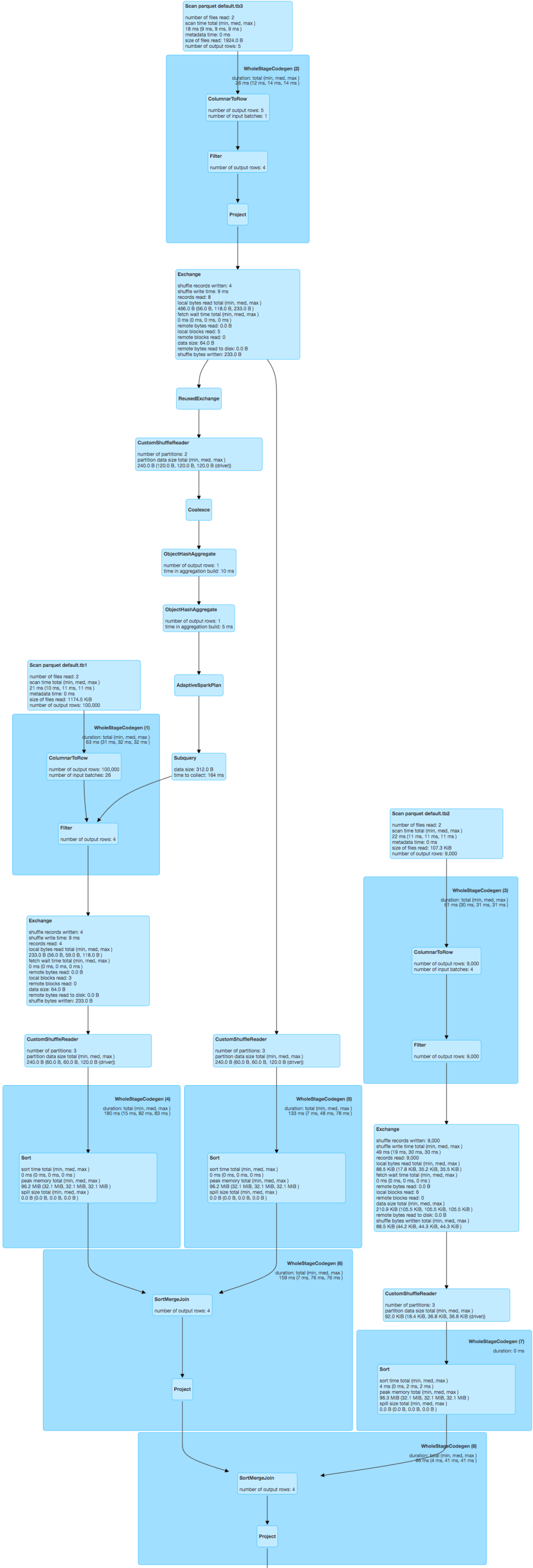
图 5 基于Runtime Filter Join优化效果
如果不引入BloomFilter谓词下推优化,我们的优化到此已经结束,上述计算结果最终再与tb2进行SortMergeJoin,这时我们发现tb2的数据会全部参与计算,其中9000条数据均会进行shuffle并最终与第一组join的结果进行join匹配,但满足join条件的数据也仅4条,即tb2存在大量无效数据参与shuffle、sort,对于上述场景我们自定义的Rule能够有效将基于tb3构建RuntimeBloomFilter下推到第二组join里,并对tb2进行谓词下推,其具体的优化效果如图6所示,由图可知tb2的数据量也得到有效过滤,只保留了满足join条件的4条数据,最终实现了基于一组join的BloomFilter谓词下推到其他join,从而减少shuffle量,减少集群负载,提升任务时效,同时节省大量的计算资源。
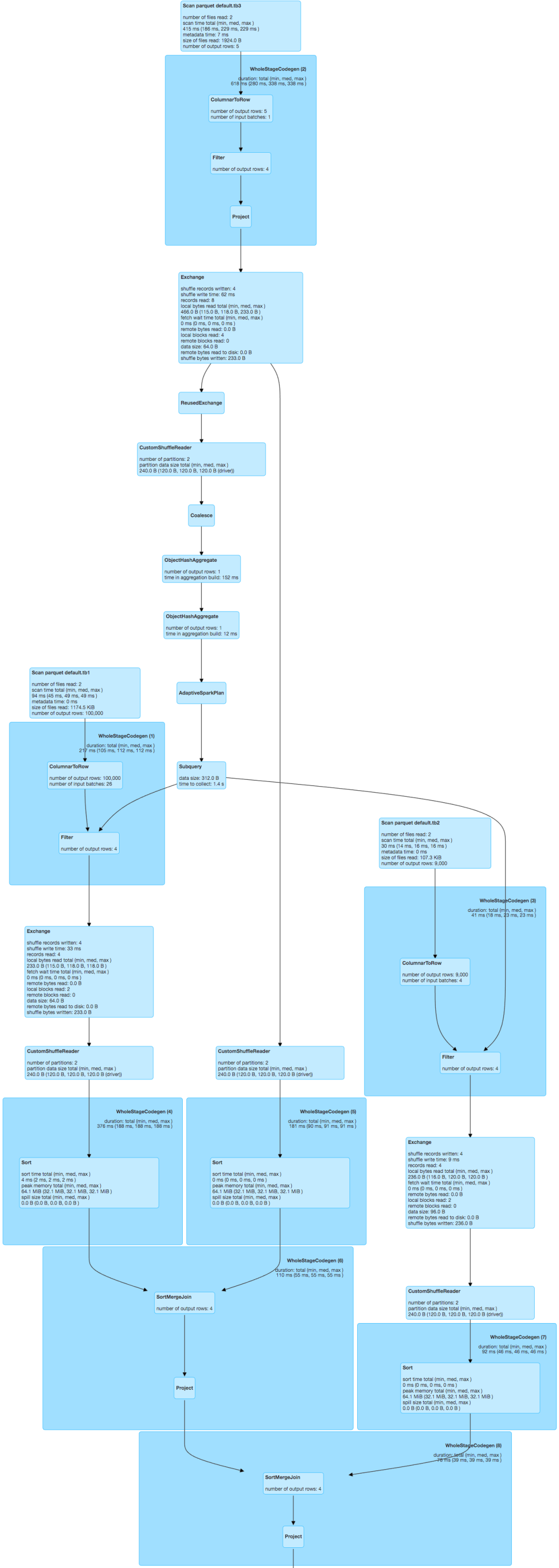
图 6 基于BloomFilter谓词下推的优化效果
基于TPC-DS 10TB 基准测试验证,如图7所示,99个查询中有9个被Runtime Filter Join特性命中,其中shuffle量减少1.5%~73.7%。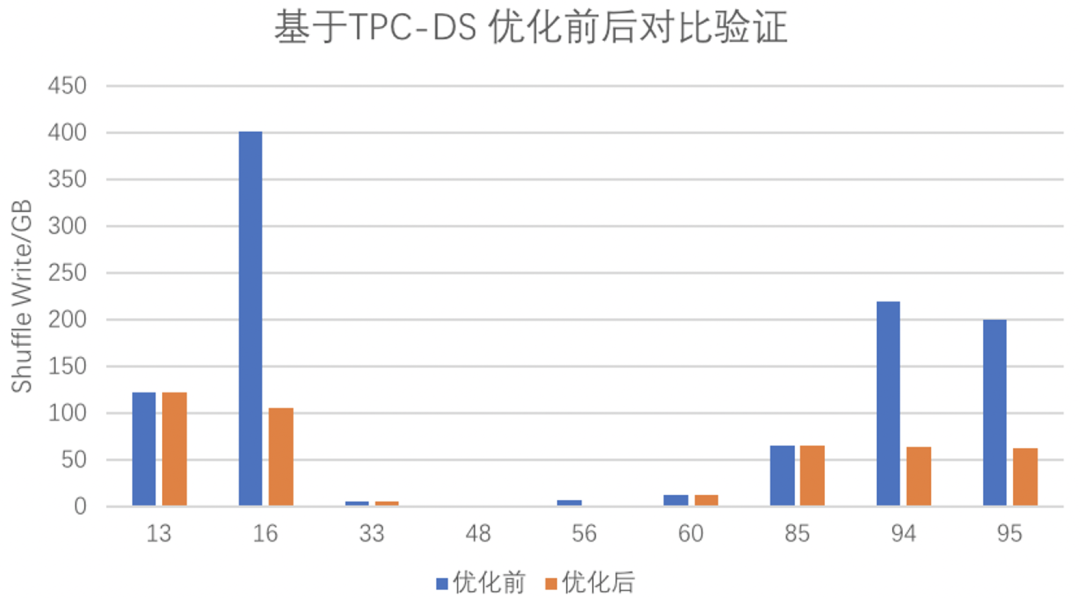
图 7 基于TPC-DS基准测试验证
下面是京东线上的优化案例:其为某重要业务线的某商品SKU属性表(小表)与某商品SKU扩展属性模型表(大表)进行Left Outer Join,因业务需要两张表在join前会根据相关字段进行group by,最终再通过商品SKU编号进行关联,涉及业务较为复杂,这里不展开描述,该业务场景是非常符合本文的Runtime Filter Join优化,下面是优化前后的对比效果:
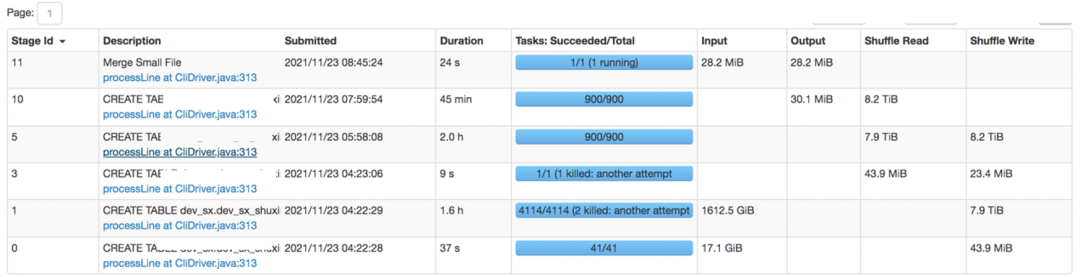
图 8 某核心任务优化前效果

图 9 某核心任务优化后效果
由上面优化前后的对比效果图8和图9可知,1)优化前,该线上任务的shuffle量大概是:16TB+,任务运行时间:4.4小时;2)基于Runtime Filter Join优化后,shuffle量减少至:200MB+,任务运行时间缩短至:4分钟,计算性能提升:95%+,同时节省了大量的计算资源。基于Bloom Filter算法的Runtime Filter Join优化机制在京东的线上优化案例不胜枚举,限于篇幅原因这里不一一展开。目前,基于Bloom Filter算法的Runtime Filter Join优化机制已全面上线(默认关闭),基于京东自研Spark版本相对Spark社区版本,命中任务平均处理数据量(shuffle量)减少72%、性能提升53%。
本文讨论京东Spark计算引擎研发团队基于Bloom Filter算法的Runtime Filter Join优化机制,助力京东大促场景的探索和实践。目前上线效果显著,但仍有一些不足及待提升项:1、目前表Row count主要是通过表文件大小及其schema信息进行判断,存在一定误差,后续会尝试开启CBO进行精准判断;
2、目前是基于小表动态构建BloomFilter,需要读取小表的数据信息,后续会考虑基于列式文件存储的一些特性来丰富整个架构,例如:如果要基于小表的全量数据构建BloomFilter,且存储格式是ORC或Parquet等,可直接基于其Data文件内部的Index BloomFilter构建全表的BloomFilter,这样可以进一步提升性能;
3、目前优化的主要是两表关联的场景,后续需要增强对多表关联等复杂场景的支持。
我们后续计划将Spark Runtime Filter Join 技术与数据湖技术相结合,助力京东湖仓一体相关场景的落地及实践。同时,我们会继续加强行业内技术交流,在分享内部技术实践与经验的同时,聆听大家的反馈和建议,在满足内部业务增长需要的同时,相关技术会反馈给社区,共同建设Spark生态。