
Spark调优 | 不可避免的 Join 优化
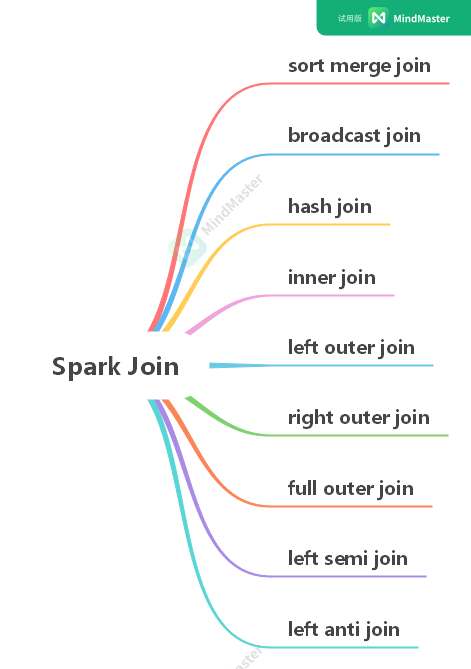
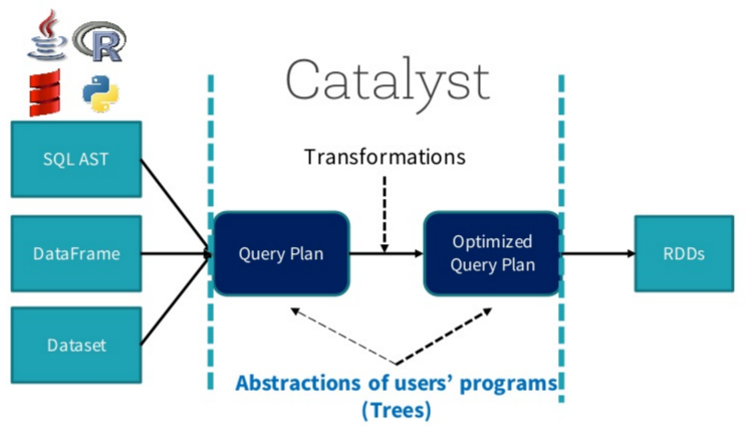
SparkSQL总体流程介绍
Join基本要素
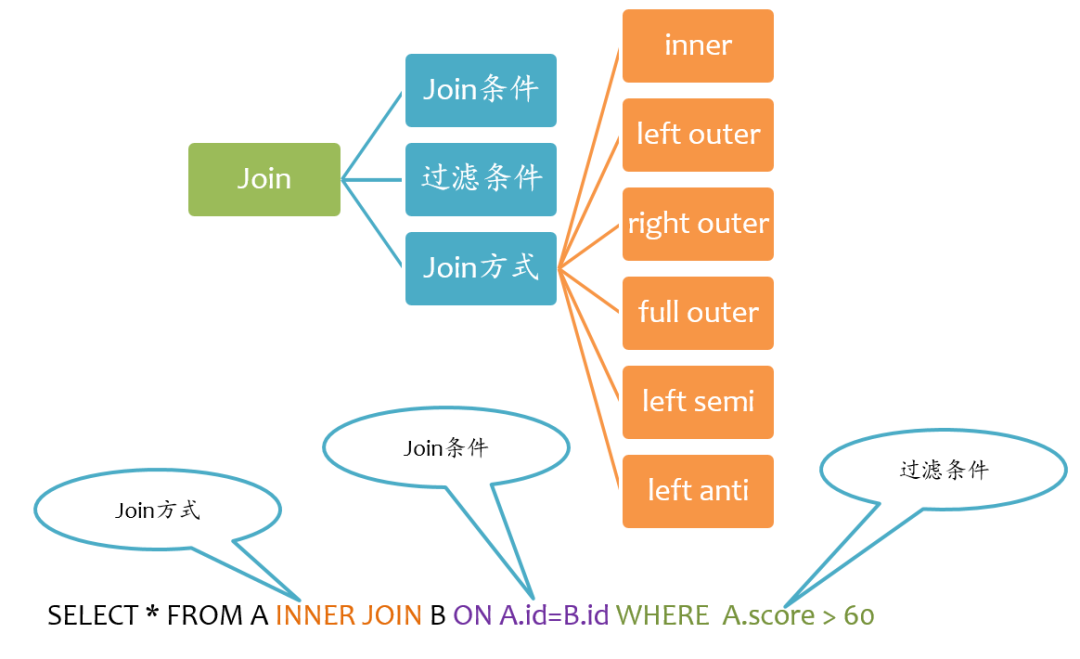
inner join
left outer join
right outer join
full outer join
left semi join
left anti join
Join基本实现流程
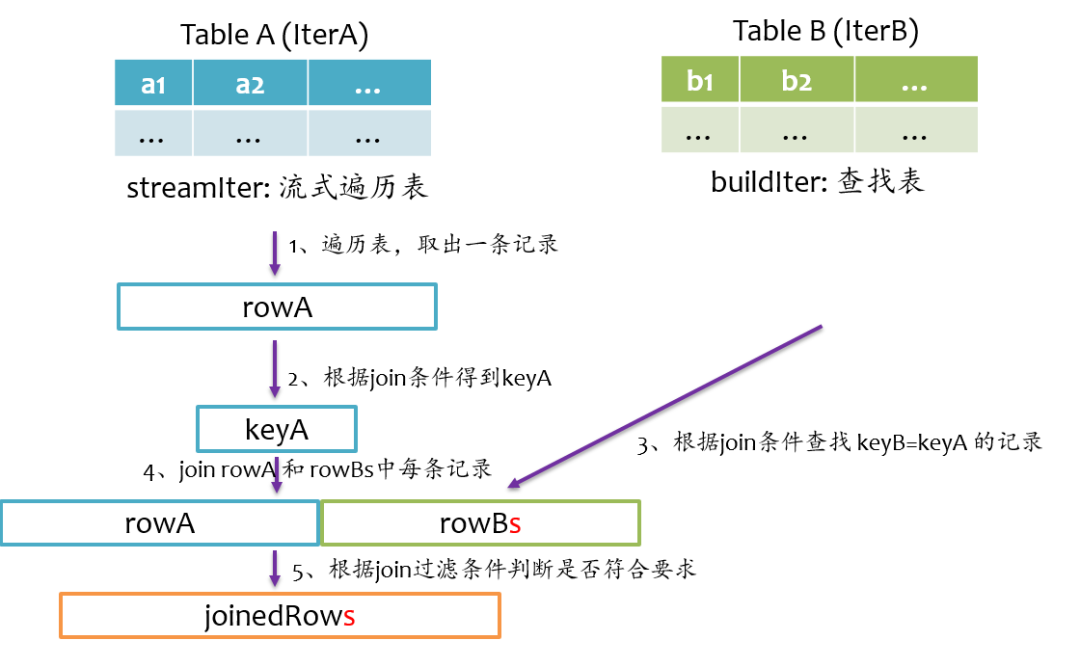
sort merge join实现
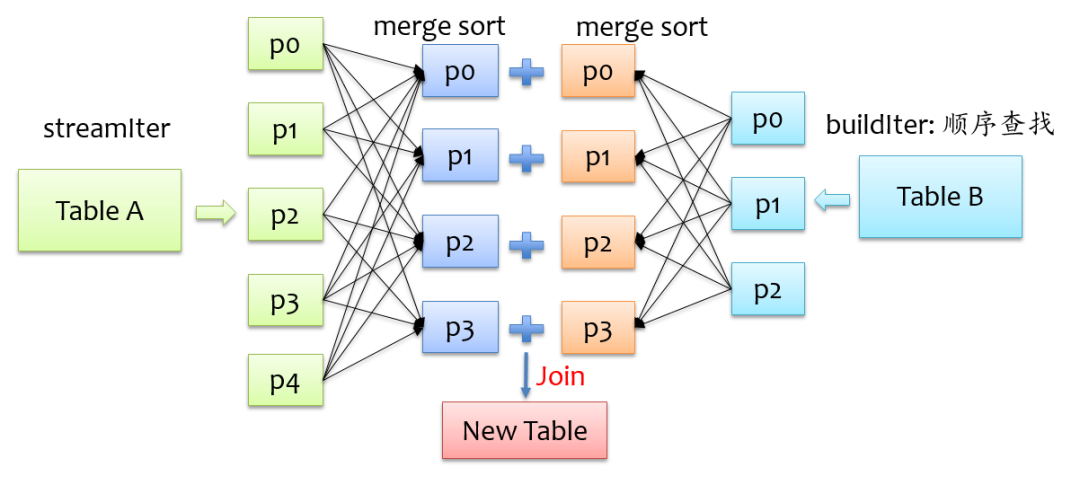
broadcast join实现
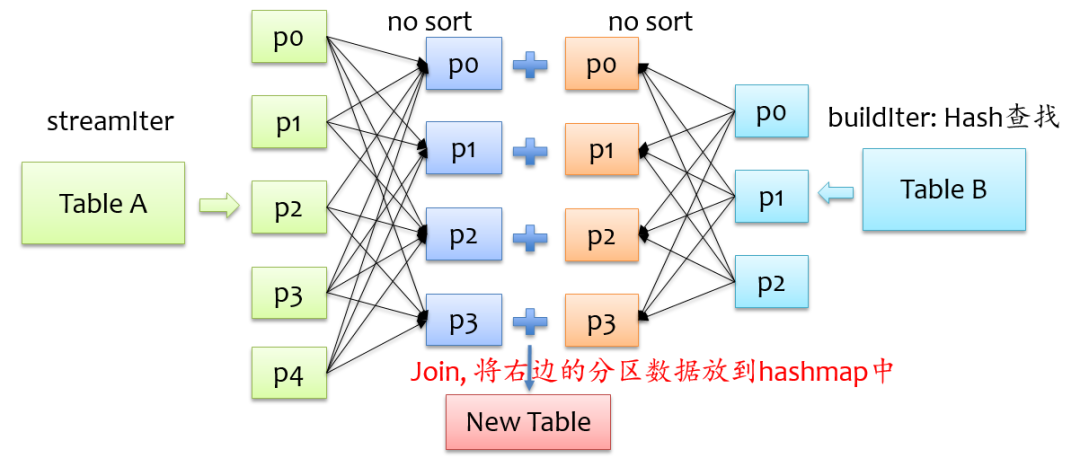
hash join实现
buildIter总体估计大小超过spark.sql.autoBroadcastJoinThreshold设定的值,即不满足broadcast join条件;
开启尝试使用hash join的开关,spark.sql.join.preferSortMergeJoin=false;
每个分区的平均大小不超过spark.sql.autoBroadcastJoinThreshold设定的值,即shuffle read阶段每个分区来自buildIter的记录要能放到内存中;
streamIter的大小是buildIter三倍以上;
inner join
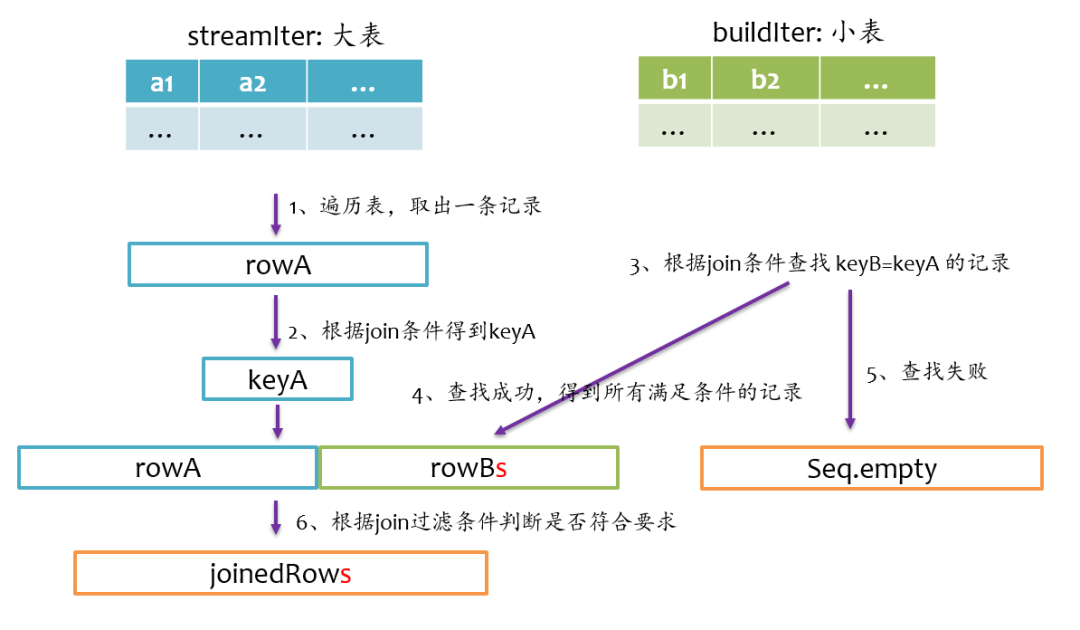
left outer join
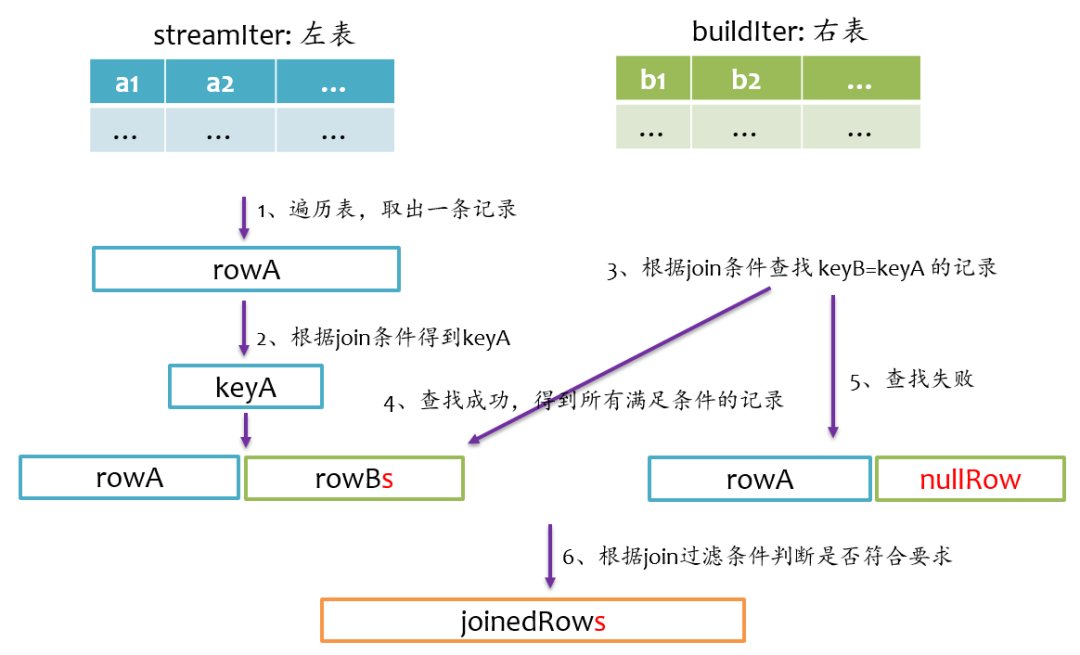
right outer join
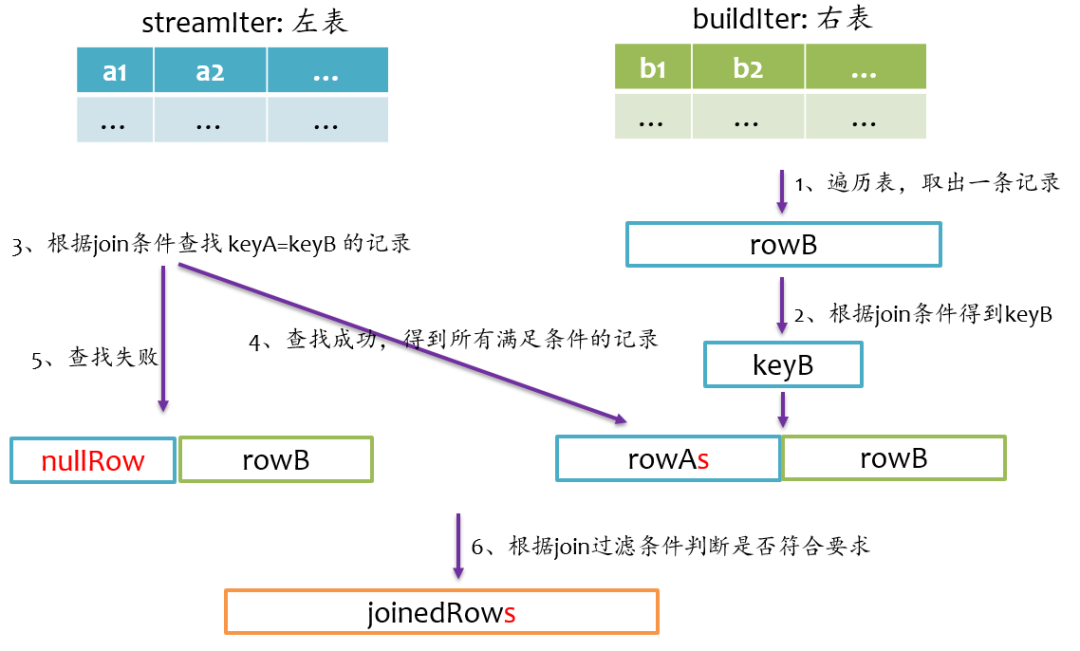
full outer join
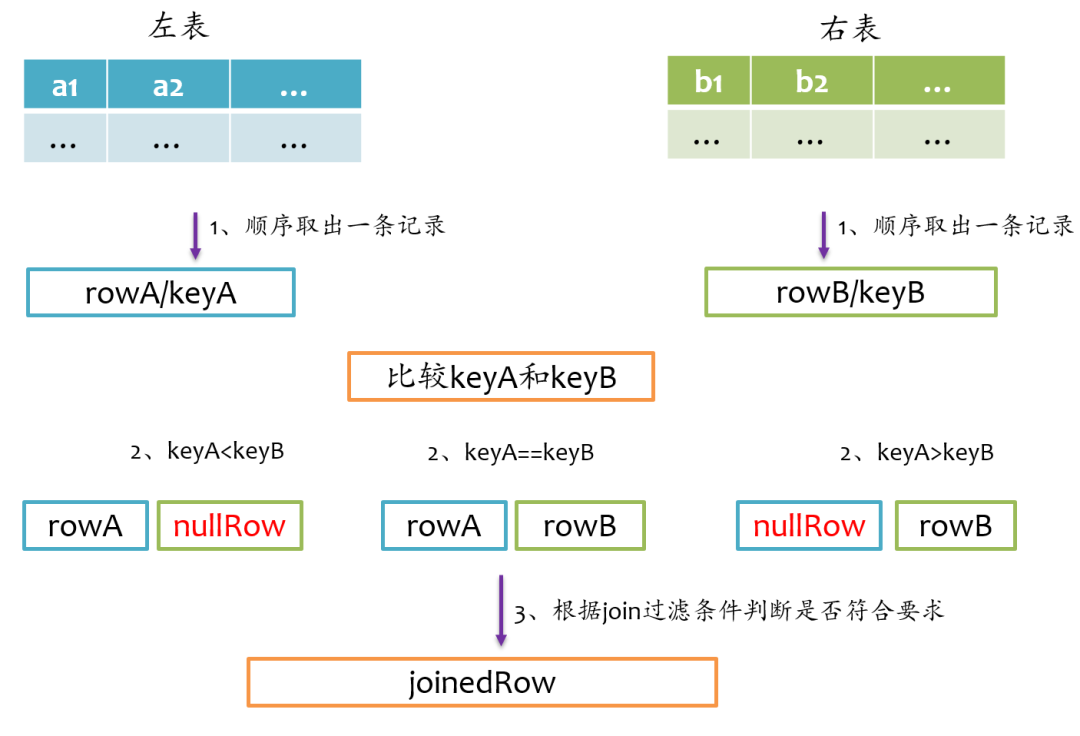
keyA<keyB,则说明右表中没有与左表rowA对应的记录,那么joinrowA与nullRow,紧接着,rowA更新到左表的下一条记录;如果keyA>keyB,则说明左表中没有与右表rowB对应的记录,那么joinnullRow与rowB,紧接着,rowB更新到右表的下一条记录。如此循环遍历直到左表和右表的记录全部处理完。left semi join
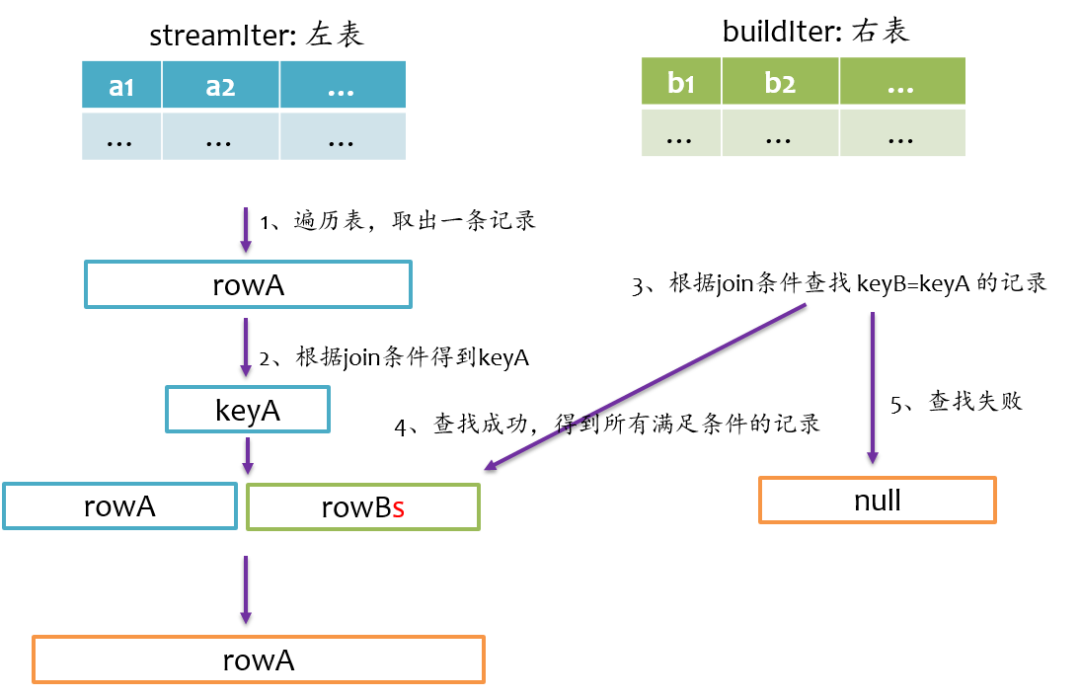
left anti join
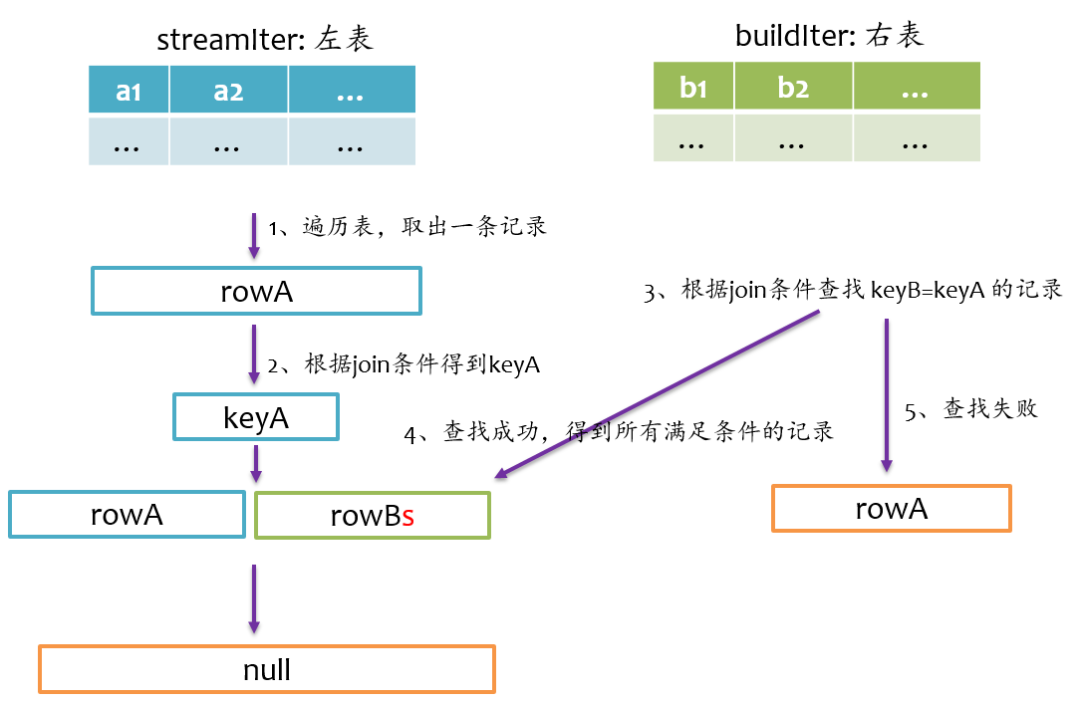
总结
评论