
《Redis开发与运维》读书笔记
最近在看《Redis开发与运维》,个人认为这是一本很好的 Redis 实战书籍,书中有多处讲解了提升 Redis 性能的小技巧,以及使用 Redis 过程中踩过的一些“坑”,这周打算把这部分提炼总结成一篇文章,在开发过程中能够快速查阅。
1、使用批量操作(mset、mget)代替多个单条操作(多个set、多个get),可以显著提高 Redis 性能。
127.0.0.1:6379> set a 1
OK
127.0.0.1:6379> set b 2
OK
127.0.0.1:6379> set c 3
OK
127.0.0.1:6379> set d 4
OK
(1)、n 次 get 命令,如下图所示,耗时如下:n 次 get 时间 = n 次网络时间 + n 次命令时间。
127.0.0.1:6379> get a
"1"
127.0.0.1:6379> get b
"2"
127.0.0.1:6379> get c
"3"
127.0.0.1:6379> get d
"4"
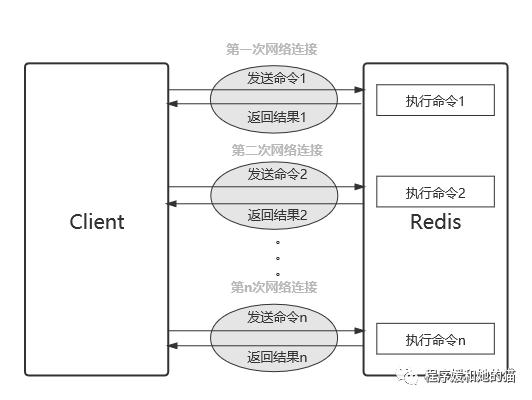 n 次 get 命令
n 次 get 命令(2)、1 次 mget 命令,如下图所示,耗时如下:1 次 mget 时间 = 1次网络时间 + n次命令时间。
127.0.0.1:6379> mget a b c d
1) "1"
2) "2"
3) "3"
4) "4"
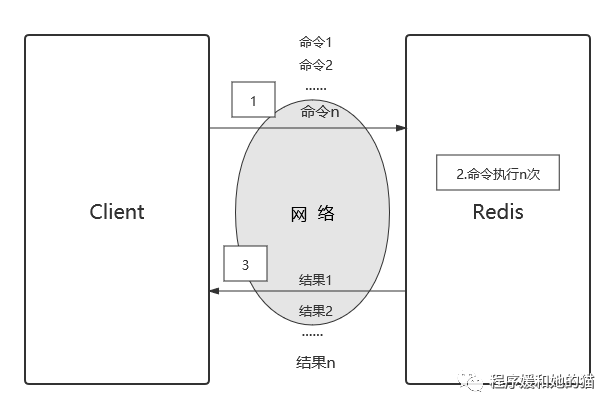 (3)、总结
(3)、总结
对于客户端来说,一次命令除了命令时间还有网络时间,假设网络时间为1毫秒,命令时间为0.1毫秒(按照每秒处理1万条命令算),那么执行 1000 次 get 命令和 1 次 mget 命令的区别如下表所示,因为Redis的处理能力已经
足够高,对于开发人员来说,网络可能会成为性能的瓶颈,使用mget操作可以减少网络的影响。
| 操作 | 时间 |
|---|---|
| 1000次get | 10001+10000.1=1100毫秒=1.1秒 |
| 1次mget | 11+10000.1=101毫秒=0.101秒 |
需要注意的是,虽然使用mget命令可以减少网络对性能的影响,但是每次批
量操作所发送的命令数不是无节制的,如果数量过多可能造成Redis阻塞或
者网络拥塞。
2、Redis设计合理的键名,有利于防止键冲突和项目的可维护性。
比较推荐使用“业务名:对象名:id:[属性]”作为键名,比如 MySQL 数据库名为 vs,用户表名为 user,那么对应的键可以用"vs:user:1","vs:user:1:name"来表示
如果键名比较长,可以在能描述键含义的前提下适当减少键的长度,从而减少由于键过长的内存浪费。
例如“user:{uid}:friends:messages:{mid}”,可以变为变为“u:{uid}:fr:m:{mid}”。
3、smembers(返回set中所有元素)、lrange(返回list所有元素)、hgetall(返回hash中所有元素),它们都是一次性返回所有元素,时间复杂度O(n),如果元素过多存在阻塞 Redis 的可能性,这时可以使用 scan 命令渐进式分段获取元素,避免 Redis 阻塞。
4、对于字符串类型键,执行set命令会去掉过期时间,这个问题很容易在开发过程中被忽视。
127.0.0.1:6379> set hello world
(integer) 1
127.0.0.1:6379> expire hello 50
(integer) 1
127.0.0.1:6379> ttl hello
(integer) 48
127.0.0.1:6379> set hello happy // 此时 hello 这个key会失效
OK
127.0.0.1:6379> ttl hello
(integer) -1
5、建议生产环境不要使用全局遍历命令 keys ,因为如果 Redis 包含了大量的键,执行 keys 命令很可能会造成 Redis 阻塞。
// 遍历所有符合给定模式 pattern 的键,parttern取值如下所示
keys pattern
*:代表匹配任意字符。
[]:代表匹配部分字符,例如[1,3]代表匹配数字1和3,[1-10]代表匹配1到10 的任意数字。
keys命令使用举例:
// 匹配以j,r开头,紧跟edis字符串的所有键
127.0.0.1:6379> keys [j,r]edis
1) "jedis"
2) "redis"
// 匹配包含h、l、l的键
127.0.0.1:6379> keys hll*
1) "hill"
2) "hello"
我们已经知道,在生产环境最好不使用keys命令,但有时候确实有遍历键的需求该怎么办,可以在以下三种情况使用:
(1)、在一个不对外提供服务的Redis从节点上执行,这样不会阻塞到客户端的请求,但是会影响到主从复制。
(2)、如果确认键值总数确实比较少,可以执行该命令。
(3)、使用 scan 命令渐进式的遍历所有键,可以有效防止阻塞。
6、Redis 从2.8版本后,提供了 scan 命令,采用渐进式遍历的方式,解决 hgetall、keys、smembers、lrange 这些命令(时间复杂度为 O(n) )阻塞 Redis 的问题。scan 命令的时间复杂度也是O(n),但是它是通过游标分步进行,不会一下子阻塞住 Redis。
scan命令是针对list做遍历,Redis还提供了其他数据结构的渐进式遍历命令,比如hscan命令是针对hash做遍历,sscan命令是针对set做遍历,zscan命令是针对zset做遍历。
在 scan 的过程中如果有键发生了变化(增加、删除、修改),那么遍历效果可能会碰到如下问题:新增的键可能没有遍历到,遍历出了重复的键等情况(对于重复问题,需要客户端做去重处理),也就是说scan并不能保证完整的遍历出来所有的键,这些是我们在开发时需要考虑的。
7、慎用flushdb/flushall命令。
flushdb和flushall的区别:
flushdb:Redis内部默认有16个数据库,flushdb用于清除当前数据库中的所有key,但是不执行持久化操作。
flushall:flushall用于清除Redis中所有的key,执行持久化操作。
这两条命令是原子性的,不会终止执行,一旦开始执行,将不会执行失败。如果当前数据库键值数量比较多,flushdb/flushall存在阻塞 Redis 的可能。
对于keys、flushall、flashdb这些危险命令,为了避免我们不小心用了,我们可以在配置文件中把这些命令设置为禁用,redis.conf配置文件中的rename-command参数。
rename-command KEYS ""
rename-command FLUSHALL ""
rename-command FLUSHDB ""
8、对bigkey执行del命令,可能会导致Redis阻塞。
说明:
Redis是单线程处理客户端发送过来的命令,相当于命令是串行执行的,某条命令耗时过长(比如del bigkey),会阻塞接下来的命令,这就是Redis阻塞。
所以避免在生产环境中使用耗时过长的命令。
bigkey是指key对应的value所占的内存空间比较大。按照数据结构来细分的话,bigkey分为字符串类型bigkey和非字符串类型bigkey。
字符串类型:体现在单个value值很大,一般认为超过10KB就是bigkey。
非字符串类型:哈希、列表、集合、有序集合,体现在元素个数过多。
那么对于bigkey,如果不用del删除,我们应该怎么删除呢?
一、分批删除
(1)、Delete Large List Key(删除大的list键)
方法1:使用ltrim key start end命令,分多次删除,每次删除少量元素。
// 只保留[start, end]之间的元素,不在这个区间的元素都将被删除。
// 下标 0 表示列表的第一个元素,下标 1 表示列表的第二个元素,依次类推。
// 也可以使用负数下标, -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,依次类推。
ltrim key start end;
// 插入元素
127.0.0.1:6379> lpush listkey a b c d e f
(integer) 6
// 分多次删除元素
// 第一次删除,删除"a"和"b"
127.0.0.1:6379> ltrim listkey 0 1
(integer) 2
// 第一次删除之后,遍历list
127.0.0.1:6379> lrange 0 -1
"c"
"d"
"e"
"f"
// 第二次删除,删除"c"和"d"
127.0.0.1:6379> ltrim listkey 0 1
(integer) 2
// 第二次删除之后,遍历list
127.0.0.1:6379> lrange 0 -1
"e"
"f"
// 第三次删除,删除"e"和"f"
127.0.0.1:6379> ltrim listkey 0 1
(integer) 2
// 第三次删除之后,遍历list
127.0.0.1:6379> lrange 0 -1
(empty list or set)
方法2:使用lpop或者rpop命令,依次将list队列中所有的元素出队,直至清空队列,达到删除的目的。
// 插入元素
127.0.0.1:6379> lpush listkey a b c d e
(integer) 5
// 删除元素
127.0.0.1:6379> lpop listkey
"e"
127.0.0.1:6379> lpop listkey
"d"
127.0.0.1:6379> lpop listkey
"c"
127.0.0.1:6379> lpop listkey
"b"
127.0.0.1:6379> lpop listkey
"a"
// 获取list列表长度,列表长度为0,表示列表已经被清空。
127.0.0.1:6379> llen listkey
(integer) 0
(2)、Delete Large Hash Key(删除大的hash键)
首先通过hscan命令遍历出指定数量的元素,然后使用hdel命令依次删除遍历出来的数据集中的每个元素。
见下面的例子,通过hscan命令,每次获取500个元素,再用hdel命令对这500个元素一条一条进行删除。
Jedis jedis = new Jedis("0.0.0.0",6379);
public void deleteLargeHashKey(){
// 分批删除
try {
ScanParams scanParams = new ScanParams();
scanParams.count(500);// 每次删除 500 条
String cursor = "";// 分批删除的游标,游标为0,说明全部数据都已经被遍历
while (!cursor.equals("0")){
ScanResult<String> scanResult=jedis.sscan(hashkey, cursor, scanParams);
cursor = scanResult.getStringCursor();
List<String> result = scanResult.getResult();
long t1 = System.currentTimeMillis();
// 遍历出来的数据集,依次删除每一条数据
for(int i = 0;i < result.size();i++){
String hashvalue = result.get(i);
jedis.srem(hashkey, hashvalue);// 删除一条数据
}
long t2 = System.currentTimeMillis();
System.out.println("删除"+result.size()+"条数据,耗时: "+(t2-t1)+"毫秒,cursor:"+cursor);
}
}catch (JedisException e){
e.printStackTrace();
}finally {
if(jedis != null){
jedis.close();
}
}
}
(3)、Delete Large Set Key(删除大的set键)
和hash类似,使用sscan命令,每次获取500个元素,再用srem命令命令对这500个元素一条一条进行删除。
(4)、Delete Large Sorted Set Key(删除大的zset键)
方法1:和List类似,使用sortedset自带的zremrangebyrank zsetkey 0 99命令,每次删除下标在[0, 99]之间的元素,即删除top前100个元素。
// 删除指定排名内的升序元素
zremrangebyrank key start end
// 插入元素
127.0.0.1:6379> zadd zsetkey 2000 jack 5000 tom 3500 peter 4000 lily 3000 alice
// 第一次删除,删除下标在[0, 1]之间的元素
127.0.0.1:6379> zremrangebyrank zsetkey 0 1
// jack 2000和alice 3000被删除,此时遍历一下集合。
127.0.0.1:6379> zrange zsetkey 0 -1 withscores
1) "peter"
2) "3500"
3) "lily"
4) "4000"
5) "tom"
6) "5000"
// 第二次删除,删除下标在[0, 1]之间的元素
127.0.0.1:6379> zremrangebyrank zsetkey 0 1
// peter 3500和lily 4000被删除,此时遍历一下集合。
127.0.0.1:6379> zrange zsetkey 0 -1 withscores
1) "tom"
2) "5000"
// 第三次删除,删除下标在[0, 1]之间的元素
127.0.0.1:6379> zremrangebyrank zsetkey 0 1
// tom 5000被删除,此时遍历一下集合,集合为空。
127.0.0.1:6379> zrange zsetkey 0 -1 withscores
(empty list or set)
方法2:和hash类似,使用zscan命令,每次获取500个元素,再用zrem命令命令对这500个元素一条一条进行删除。
二、后台删除之Lazy Free方式
为了解决redis使用del命令删除大体积的key,或者使用flushdb、flushall删除数据库时,造成redis阻塞的情况,在redis 4.0版本中引入了lazy free机制,可将删除操作放在后台,让后台子线程(bio)执行,避免主线程阻塞。使用lazy delete free的方式,删除大键的过程不会阻塞正常请求。
Lazy Free的使用分为两类:第一类是与DEL命令对应的主动删除,第二类是过期key删除、maxmemory key驱逐淘汰删除。
- 主动删除
UNLINK命令是与DEL一样删除key功能的lazy free实现。唯一不同时,UNLINK在删除集合类键时,如果集合键的元素个数大于64个,会把真正的内存释放工作,交给单独的bio来操作,这样就不会阻塞 Redis 主线程了。
示例如下:使用UNLINK命令删除一个大键mylist, 它包含200万个元素,但用时只有0.03毫秒。
// 查询mylist中元素个数
127.0.0.1:7000> LLEN mylist
(integer) 2000000
// 使用UNLINK命令删除mylist
127.0.0.1:7000> UNLINK mylist
(integer) 1
// 获取慢查询日志
127.0.0.1:7000> SLOWLOG get
1) 1) (integer) 1
2) (integer) 1505465188
3) (integer) 30 // 命令耗时30微妙,0.03毫秒
4) 1) "UNLINK"
2) "mylist"
- 被动删除
lazy free应用于被动删除中,目前有4种场景,每种场景对应一个配置参数,默认都是关闭的(no)。
lazyfree-lazy-eviction no
lazyfree-lazy-expire no
lazyfree-lazy-server-del no
slave-lazy-flush no
lazyfree-lazy-eviction:针对redis中内存使用达到maxmeory,并设置有淘汰策略的键,在被动淘汰时,是否采用lazy free机制。此场景开启lazy free,可能出现如下问题:因为内存释放不及时,导致redis内存超用,超过maxmemory的限制。此场景使用时,请结合业务测试。
lazyfree-lazy-expire:针对设置有TTL的键,到达过期时间,被redis删除时是否采用lazy free机制。此场景建议开启,因TTL本身是自适应调整的速度。
lazyfree-lazy-server-del:针对有些指令在处理已存在的键时,会带有一个隐式的DEL键的操作。如rename命令,当目标键已存在,redis会先删除目标键,如果这些目标键是一个bigkey,那就会引入阻塞删除的性能问题。此参数设置就是解决这类问题,建议开启。
slave-lazy-flush:主从之间进行全量数据同步时,slave(从)在加载master(主)的RDB文件之前,会运行flushall来清理自己的数据。这个参数设置决定同步过程中是否采用异常flush机制,如果内存变动不大,建议开启,可减少全量同步耗时。
9、了解每个命令的时间复杂度在开发中至关重要,例如在使用keys、 hgetall、smembers、zrange等时间复杂度(O(n))较高的命令时,需要考虑数据规模(即 n)对Redis的影响。
10、对于一些不支持批量操作的命令,尽量使用Pipeline支持批量执行,提高程序效率。
(1)、为什么使用 Pipeline?
Redis客户端执行一次命令分为如下4个过程:1.发送命令-> 2.命令排队-> 3.命令执行-> 4.返回结果,其中 1 + 4 称为 Round Trip Time(RTT,命令执行往返时间)。
Redis提供了批量操作命令(例如mget、mset等),相对于单条操作命令(例如get、set等),可以有效地节约RTT。但是Redis还有大部分命令是不支持批量操作的,比如要执行n次hgetall命令,并没有 mhgetall 命令存在,所以需要引入pipeline来解决这个问题。
见下图,逐条执行n条命令,整个过程需要n次RRT,而使用Pipeline执行n条命令,整个过程只需要1次RTT,可以看出来使用Pipeline可以减少网络开销,提高Redis请求的速度,减少Redis请求所需时间,同时提高Redis的吞吐量和并发量。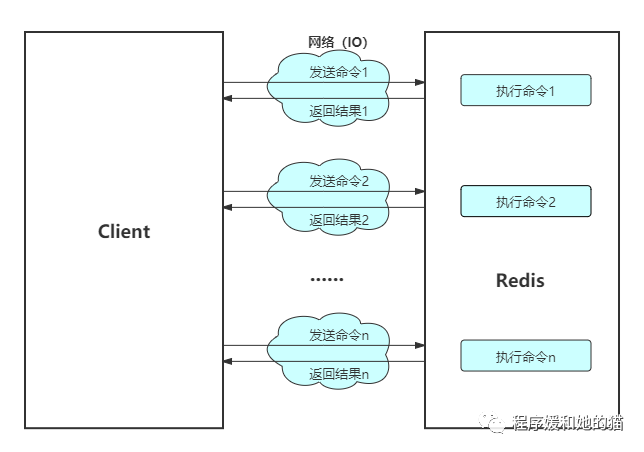
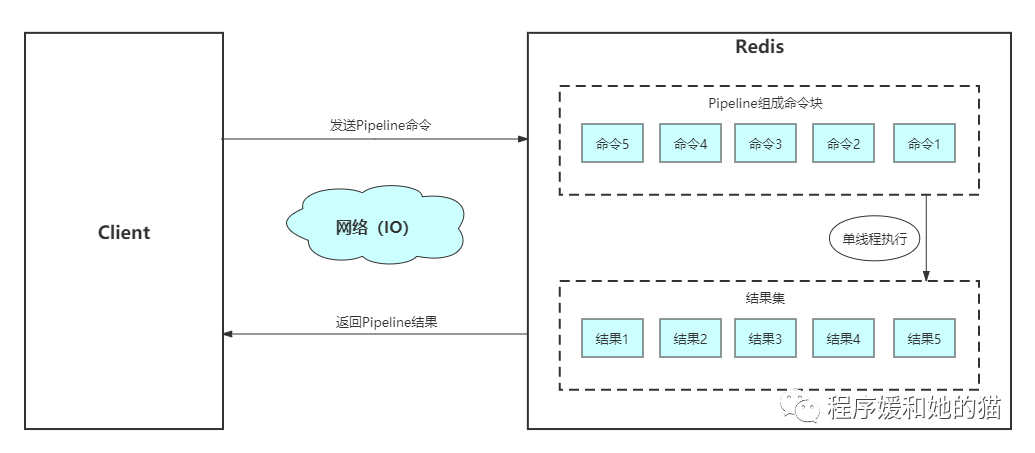 使用Pipeline执行n条命令模型
使用Pipeline执行n条命令模型(2)、非Pipeline和Pipeline性能对比?
两者性能对比见下表,执行10000条set命令,使用非Pipeline和Pipeline的执行时间对比。
| 网络类型 | 客户端和Redis实例之间网络延迟 | 非Pipeline | Pipeline |
|---|---|---|---|
| 客户端和Redis实例部署在同一台机器上 | 0.17ms | 573ms | 134ms |
| 客户端和Redis实例部署在内网的两台机器上 | 0.41ms | 1610ms | 240ms |
| 客户端和Redis实例部署在异地机房 | 7ms | 78499ms | 1104ms |
这是一组统计数据出来的数据,使用Pipeline执行速度比逐条执行要快,特别是客户端与服务端的网络延迟越大,性能体现地越明显。
(3)、Redis原生批量命令(mset、mget)与Pipeline对比
a)原生批量命令是原子的,Pipeline是非原子的,如果想要保证Pipeline里面所有的操作要么全部执行,要么都不执行,就要把Pipeline放到Redis事务中执行。
b)原生批量命令是一个命令对应多个key,Pipeline是对应多个命令。
c)原生批量命令是Redis内部自己实现的,而Pipeline需要Redis和客户端共同实现。
(4)、开发中需要注意的地方
a)使用 Pipeline 发送命令时,每次 Pipeline 组装的命令个数不能没有节制,否则一次组装的命令数据量过大,一方面会增加客户端的等待时间,另一方面会造成一定的网络阻塞,可以将一次包含大量命令的 Pipeline 拆分成多个较小的 Pipeline 来完成。
b)虽然Pipeline只能操作一个Redis实例,但是在分布式 Redis 场景中,Pipeline也可以作为批量操作的重要优化手段。
c)使用Pipeline的前提条件时,多个指令之间没有依赖关系,先写后读这种场景就不能使用Pipeline因为读之前必须写,二者之间有依赖关系。
// 此时不能使用Pipeline
set name Tom
get name
(5)、Pipeline实战
// 使用pipeline提交所有命令并返回执行结果
public void testPipeline(){
// 建立Redis连接
Jedis jedis = new Jedis("192.168.1.111", 6379);
// 创建pipeline对象
Pipeline pipeline = jedis.pipelined();
// pipeline执行命令,注意此时命令并未真正执行
pipeline.set("name", "james"); // set命令
pipeline.incr("age");// incr命令
pipeline.get("name");// get命令
// 将所有命令一起提交,此时命令才真正被执行,并将执行结果以List形式返回。
List<Object> list = pipeline.syncAndReturnAll();
for (Object obj : list) {
// 将执行结果打印出来
System.out.println(obj);
}
// 断开连接,释放资源
jedis.disconnect();
}
1.pipelined.sync():一次性将所有命令异步发送到redis,不关注执行结果。
2.pipelined.syncAndReturnAll():使用这个方法,程序会阻塞,等到所有命令执行完之后返回一个List集合。
11、Redis每条原生命令都是原子性的,但是多条原生命令放在一起就无法保证是原子性的了,此时我们可以将这多条命令放在 Redis 事务中,以此来保证原子操作。
(1)、multi命令和exec命令
Redis提供了简单的事务功能,将一组需要一起执行的命令放到 multi 和 exec两个命令之间。multi命令表示事务的开始,exec 命令表示事务的执行,它们之间的命令是原子顺序执行的,即这组动作,要么全部执行,要么全部不执行。
例如在社交网站上用户A关注了用户B,那么需要在用户A的关注表中加入用户B,并且在用户B的粉丝表中添加用户A,这两个行为要么全部执行,要么全部不执行,否则会出现数据不一致的情况。
127.0.0.1:6379> multi
OK
127.0.0.1:6379> sadd user:a:follow user:b
QUEUED
127.0.0.1:6379> sadd user:b:fans user:a
QUEUED
// 此时上述命令还没有真正执行,所以用户B还未加入到用户A的关注表中,用户A还未加入到用户B的粉丝表中。
127.0.0.1:6379> sismember user:a:follow user:b
(integer) 0
127.0.0.1:6379> sismember user:b:fans user:a
(integer) 0
127.0.0.1:6379> exec
1) (integer) 1
2) (integer) 1
// 此时命令执行完了,用户B加入到了用户A的关注表中,用户A加入到了用户B的粉丝表中。
127.0.0.1:6379> sismember user:a:follow user:b
(integer) 1
上面的指令演示了如何使用事务保证上述业务的正确性。在Redis事务中,所有的指令在 exec 之前不执行,而是缓存在服务器的一个事务队列中,服务器一旦收到 exec 指令,才开始执行整个事务队列,执行完毕后一次性返回所有指令的运行结果。因为 Redis 的单线程特性,它不用担心自己在执行队列的时候被其它指令打搅,所以可以保证队列中的指令能够得到的「原子性」执行。
(2)、discard命令
如果要停止事务的执行,使用discard命令代替exec命令即可。discard 表示事务的丢弃,用于丢弃事务缓存队列中的所有指令,在 exec 执行之前。
127.0.0.1:6379> set books 10
127.0.0.1:6379> get books
"10"
127.0.0.1:6379> multi
OK
127.0.0.1:6379> incr books
QUEUED
127.0.0.1:6379> incr books
QUEUED
127.0.0.1:6379> discard
OK
127.0.0.1:6379> get books
"10"
我们可以看到 discard 之后,队列中的所有指令都没执行,就好像 multi 和 discard 中间的所有指令从未发生过一样。
(3)、在分布式环境,当多个客户端并发访问存储在 Redis 中的共享数据时,为了保证数据一致性,除了可以使用分布式锁(悲观锁),也可以使用 Redis 事务机制以及 watch 指令实现的乐观锁,乐观锁的效率相对悲观锁要高得多。
watch 会一直监控这个共享变量直到exec命令结束,当事务执行时,也就是Redis接收到 exec 指令要顺序执行事务队列中的命令时,Redis 会检查共享变量自 watch 之后,是否被修改了,如果共享变量被人动过了,exec 指令就会返回 null 告知客户端事务执行失败,这个时候客户端一般会选择重试。
见下面这个业务场景,Redis 中存储了我们的账户余额数据,现在有两个并发的客户端要对账户余额进行修改操作,我们需要先取出余额,然后做计算,最后将结果写回 Redis,Java代码如下所示。
public int doubleAccount(String userId){
Jedis jedis = new Jedis("192.168.1.111", 6379);
String key = userId;// key:用户ID,value:账户余额
while (true) {
jedis.watch(key);// watch
int value = Integer.parseInt(jedis.get(key));// 账户余额
value *= 2; // 修改余额
Transaction transaction = jedis.multi();// multi
transaction.set(key, String.valueOf(value));// set命令
List<Object> res = transaction.exec(); // exec,并返回exec执行结果
if (res != null) {
break; // 如果exec返回null,说明共享变量已经被其他客户端修改了,此时需要重试,重新进入循环。
}
}
}
注意事项 :Redis 禁止在 multi 和 exec 之间执行 watch 指令,watch 指令必须在 multi 之前,因为只有从一开始就盯住这个有可能修改的变量,才能绝对保证不出错。
(4)、使用Redis事务时,如何优化性能?
上面的 Redis 事务在发送每个指令到事务缓存队列时都要经过一次网络读写,当一个事务内部的指令较多时,需要的网络 IO 时间也会线性增长。所以通常 Redis 的客户端在执行事务时都会结合 pipeline 一起使用,这样可以将多次 IO 操作压缩为单次 IO 操作。
(5)、在事务这块,Redis和MySQL不一样,当Redis事务中某条命令执行失败,不会进行回滚。
当Redis事务中某条命令执行失败的话,Redis会如何处理呢?分两种情况,如下所示:
a)命令语法错误。
如果事务中有一条命令语法不正确,进入事务队列的时候就会报错。
这种情况下,事务中所有的命令就都不会执行。
// 下面操作错将set写成了sett,属于语法错误,会造成整个事务无法执行,key和counter的值未发生变化。
127.0.0.1:6388> mget key counter
1) "hello"
2) "100"
127.0.0.1:6388> multi
OK
127.0.0.1:6388> sett key world
(error) ERR unknown command 'sett'
127.0.0.1:6388> incr counter
QUEUED
127.0.0.1:6388> exec
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6388> mget key counter
1) "hello"
2) "100"
b)命令格式正确,而操作的数据的类型不符合命令要求。
当事务中存在某条命令,其语法正确,但是这条命令操作的数据的类型不符合该条命令的要求,那么这条命令会进入事务队列,但是在执行时会出现错误。
这种情况下,该条命令会执行失败,而其之前和之后的命令都会被正常执行。
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set name Tom
QUEUED
// name是字符串格式,不能进行计算。
127.0.0.1:6379> incr name
QUEUED
127.0.0.1:6379> set age 25
QUEUED
127.0.0.1:6379> exec
1) (integer) 1 // set name Tom 执行成功
2) (error) WRONGTYPE Operation against a key holding the wrong kind of value // zadd 这条命令执行报错
3) (integer) 1 // set age 25 执行成功
127.0.0.1:6379> get name
"Tom"
127.0.0.1:6379> get age
25
第一种情况,所有命令要么全部执行成功,要么全部执行失败,这不会产生什么问题,大不了检查一下,重新执行。但是第二种情况,有可能一部分命令执行成功,一部分命令执行失败,这就可能产生数据不一致的问题。
所以对于一些重要的操作,我们必须通过程序去检测事务中命令操作的数据是否符合命令的要求,以保证 Redis 事务的正确执行,避免出现数据不一致的情况。
Redis 之所以保持这样简易的事务,完全是为了保证移动互联网的核心问题——性能。
12、Lua脚本同样可以实现 Pipeline 和 Redis 事务的功能,Redis可以使用Lua脚本创造出原子、高效、自定义命令组合。
Lua脚本的好处如下所示:
- Lua脚本在Redis中是原子执行的,执行过程中间不会插入其他命令(和 Redis 的事务很相似)。
- Lua脚本可以帮助开发和运维人员创造出自己定制的命令,并可以将这 些命令常驻在Redis内存中,实现复用的效果。
- Lua脚本可以将多条命令一次性打包,有效地减少网络开销(和 Redis 的 Pipeline 很相似)。
13、运维提示:在 RDB 持久化的过程中,如果遇到坏盘或磁盘写满的情况,可以通过 config set dir{newDir} 命令,在线修改文件路径到可用的磁盘路径,之后执行 bgsave 进行磁盘切换,同样适用于 AOF 持久化文件。
// 在持久化运行期间动态修改持久化文件存储路径。
config set dir{newDir}
14、Redis 默认采用 LZF 算法对生成的 RDB 文件做压缩处理,压缩后的文件内存变小很多很多,默认开启,可以通过 config set rdbcompressionyesno命令动态修改。运维提示:虽然压缩 RDB 会消耗 CPU,但可大幅降低文件的体积,方便保存到硬盘或通过网络发送给从节点,因此线上建议开启。
15、Redis 持久化功能一直是影响 Redis 性能的高发地,在本篇文章中,首先将列举 Redis 持久化过程中影响 Redis 性能的几个要素,以及如何避免它们拖慢 Redis 性能?
(1)、fork 操作对 Redis 性能的影响
a)为什么 fork 操作会影响 Redis 性能?
当 Redis 做 RDB 或 AOF 重写时,一个必不可少的操作就是执行 fork 操作创建子进程(RDB 持久化和 AOF 持久化中的 AOF 重写,都是由父进程 fork 出来的子进程执行的),fork操作是一个重量级操作,耗时过长,会阻塞 Redis 主进程。
因为 Redis 是单线程模式接收并执行客户端的命令,如果 Redis 发生阻塞,客户端发出的命令无法被执行,造成客户端命令堆积。
虽然 fork 创建的子进程不需要拷贝父进程的全部物理内存空间,但是会复制父进程的空间内存页表。例如对于 10GB 的 Redis 进程(Redis 中存储数据量占用内存大小为 10 GB),需要复制大约 20MB 的内存页表。所以说 fork 操作耗时时长和 Redis 内存中存储数据量成正相关,即 Redis 内存中存储的数据集越大,fork 操作耗时时间越长。
b)fork 操作耗时问题定位?
如果 fork 操作耗时在秒级别就将拖慢 Redis 几万条命令执行,对线上应用延迟影响非常明显,正常情况下 fork 耗时应该是每 GB 消耗 20 毫秒左右,即 fork 正常操作耗时 = (Redis数据集 /1 GB) * 20 毫秒。
我们可以执行 info stats 命令,获得 latest_fork_usec 参数,这个参数表示最近一个 fork 操作的耗时,单位为微秒,根据 Redis 当前数据量大小计算正常情况下的 fork 耗时,二者进行对比,判断当前是否发生 fork 超时了。
c)既然 fork 操作在所难免,那么如何尽量降低其对 Redis 性能的影响呢?
c.1)在部署 Redis 时,优先使用物理机或者高效支持fork操作的虚拟化技术,避免使用 Xen 虚拟机。
c.2)控制 Redis 实例存储的数据量,fork 耗时跟 Redis 存储数据量成正比,线上建议每个 Redis 实例存储数据量占用内存大小控制在10GB以内。
c.3)合理配置部署 Redis 的 Linux 操作系统的内存分配策略,避免物理内存不足导致 fork 失败,具体看后述《使用 Redis时,Linux 操作系统的配置》。
c.4)降低fork操作的频率,比如当使用 AOF 持久化时,可以调大 auto-aof-rewrite-min-size 和 auto-aof-rewrite-percentage 这两个参数,降低 AOF 和 AOF 重写的频率。
(2)、子进程对 CPU、内存、硬盘三部分的开销,以及如何优化尽量降低开销。
子进程负责 RDB 和 AOF重写,它的运行过程主要涉及CPU、内存、硬盘三部分的消耗。
a)CPU开销
a.1)开销
子进程负责把 Redis 主进程内的数据分批写入 RDB 或者 AOF 文件中,这个过程属于CPU密集操作,通常子进程对单核 CPU 的利用率接近90%。
a.2)优化
1、最好不要把 Redis 实例绑在一个 CPU 核上,因为 fork 子进程非常消耗CPU,会和 Redis 主进程抢占 cpu 资源,导致 Redis 主进程变慢,影响性能。
我们可以把 Redis 实例绑定到一个物理核上,因为我们的 CPU 一个物理核上有两个逻辑核,这样可以把我们的两个逻辑核都给用上,可以在一定程度上缓解 CPU 的资源竞争。还有一种办法,就是修改 Redis 源代码,把子进程和主进程绑到不同的CPU核上。
2、不要将 Redis 和其他 CPU 密集型服务部署在一起,造成CPU过度竞争。
3、如果部署多个Redis实例,尽量保证同一时刻只有一个子进程执行重写工作。
b)内存消耗
b.1)开销
子进程是由主进程 fork 出来的,所以子进程占用内存和主进程内存成正相关。
理论上,主进程在 fork 子进程的时候,会将自己的内存复制完整的一份给子进程。由于这个全量复制的过程非常耗时,所以 Linux 操作系统引入了写时复制(copy-on-write)机制,父子进程一开始就共享相同的物理内存页,只有当父进程有写入的时候,父进程才会把要修改的物理内存页创建副本发给子进程。
b.2)如何查看 fork 内存消耗是多少?
查看使用 RDB 持久化方式, fork 操作消耗的内存大小,Redis 进行 RDB 时,Redis日志输出内容如下所示:
* Background saving started by pid 7692
* DB saved on disk
* RDB: 5 MB of memory used by copy-on-write
* Background saving terminated with success
从日志第三行,可以看到 RDB 持久化 fork 子进程的时候,消耗了 5MB 的内存。
查看使用 AOF 持久化方式, fork 操作消耗的内存大小,Redis 进行 AOF 时,Redis日志输出内容如下所示:
* Background append only file rewriting started by pid 8937
* AOF rewrite child asks to stop sending diffs.
* Parent agreed to stop sending diffs. Finalizing AOF...
* Concatenating 0.00 MB of AOF diff received from parent.
* SYNC append only file rewrite performed
* AOF rewrite: 53 MB of memory used by copy-on-write
* Background AOF rewrite terminated with success
* Residual parent diff successfully flushed to the rewritten AOF (1.49 MB)
* Background AOF rewrite finished successfully
从日志第六行,可以看到 AOF 重写 fork 子进程的时候消耗了 53MB 的内存。
b.3)优化
1、如果部署多个 Redis 实例,尽量保证同一时刻只有一个子进程在工作。
2、避免在大量写入时做持久化操作,这样将导致父进程维护大量内存页副本,造成内存消耗。
3、在使用 Linux 2.6.38及以后的版本,建议关闭 Linux 的 THP 功能,可以降低 fork 操作的内存消耗。
Linux kernel 在 2.6.38 及以后的版本中,增加了 Transparent Huge Pages(内存大页机制,THP)功能,该功能支持 2MB 的大页内存分配,默认开启。
THP 能减少内存分配的次数,同时可以加快子进程的 fork 速度。但是如果开启 THP,复制内存页单位将从原来的 4KB 变为 2MB,如果主进程只写入或者修改了 2KB 的数据,Redis 也需要从主进程复制 2MB 的内存大页给子进程,而在常规情况下,只需要复制 4KB 的内存页,这使得每次写命令引起的复制内存页的单位放大了 512 倍,这会拖慢写操作,影响 Redis 的性能。
c)硬盘消耗
c.1)开销
子进程主要职责是把 AOF 或者 RDB 文件写入硬盘持久化,势必会造成硬盘写入的压力。
c.2)优化
1、不要和其他高硬盘负载的服务部署在一起。如:存储服务、消息队列服务等。
2、当开启 AOF 功能的 Redis 用于高流量写入场景时,这时 Redis 实例的瓶颈主要在 AOF 文件同步到硬盘这个操作上。
3、对于单机配置多个Redis实例的情况,可以配置不同实例分盘存储 AOF文件,分摊硬盘写入压力。
16、巧用慢查询,可以帮助我们找出一些慢redis操作,这些慢操作可能阻塞Redis,及时发现及时解决,此外对慢操作进行优化,可以提高程序性能。
(1)、什么是慢查询?
所谓慢查询日志就是系统在命令执行前后计算每条命令的执行时间,当超过预设阀值,就将这条命令的相关信息(例如:发生时间,耗时,命令的详细信息)记录下来。
(2)、慢查询的两个参数,以及如何修改参数设置。
slowlog-log-slower-than:慢查询阈值,单位是微秒,默认值是10000,假如执行了一条“很慢”的命令(例如keys *),如果它的执行时间超过了10000微秒,那么它将被记录在慢查询日志中。
slowlog-max-len:Redis使用一个列表(列表在内存中)来存储慢查询日志,slowlog-max-len是这个列表的容量,表示最多存储多少条慢查询日志。当慢查询日志列表已处于其最大长度时,最早插入的一个命令将从列表中移出。
(3)、修改慢查询的参数配置。
一种是修改配置文件Redis.conf,另一种是使用config set命令动态修改。
slowlog-log-slower-than 10000
slowlog-max-len 128
config set slowlog-log-slower-than 20000
config set slowlog-max-len 1000
config rewrite // 如果要Redis将配置持久化到本地配置文件,需要执行config rewrite命令。
(4)、慢查询日志的组成。
每个慢查询日志有4个属性组成,分别是慢查询日志的标识 id、发生时间戳、命令耗时、执行命令和参数。
127.0.0.1:6379> slowlog get // 获取慢查询日志
1) 1) (integer) 666 // 慢查询日志的标识 id
2) (integer) 1456786500 // 慢查询发生时间戳
3) (integer) 11615 // 命令耗时,单位微妙
4) 1) "BGREWRITEAOF" // 执行命令和参数
2) 1) (integer) 665
2) (integer) 1456718400
3) (integer) 12006
4) 1) "SETEX"
2) "video_info_200"
3) "300"
4) "2"
......
(5)、慢查询命令。
a)slowlog get [n]:slowlog get [n],参数n指定查询条数。
b)slowlog len:获取慢查询日志列表当前的长度,即当前Redis中有多少条慢查询。
127.0.0.1:6379> slowlog len
(integer) 45
c)slowlog reset:清理慢查询日志列表。
127.0.0.1:6379> slowlog len
(integer) 45
127.0.0.1:6379> slowlog reset
OK
127.0.0.1:6379> slowlog len
(integer) 0
17、Redis提供了三种数据迁移的方式,建议使用 migrate 命令进行键值迁移。
(1)、move key db:在Redis内部多个数据库之间进行数据迁移,迁移过程是原子性的,只能迁移一个键。
Redis内部可以有多个数据库,彼此在数据上是相互隔离的,move key db就
是把指定的键从源数据库移动到目标数据库中。由于Redis的多数据库功能不
建议在生产环境使用,所该条命令基本用不到。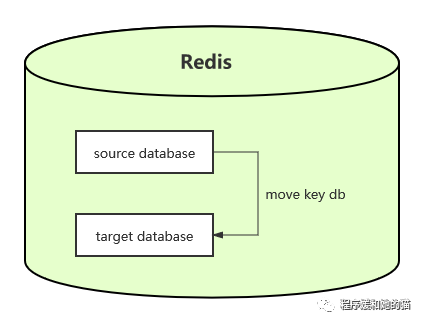
(2)、dump key + restore key ttl value:在不同的Redis实例间进行数据迁移,迁移过程是非原子性的,只能迁移一个键。
整个迁移过程分为两步:
1)在源Redis上,dump命令会将需要迁移的键值进行序列化,格式采用的是RDB格式。
2)在目标Redis上,restore命令将上面序列化的键值进行复原,其中ttl参
数代表过期时间,如果ttl=0代表没有过期时间。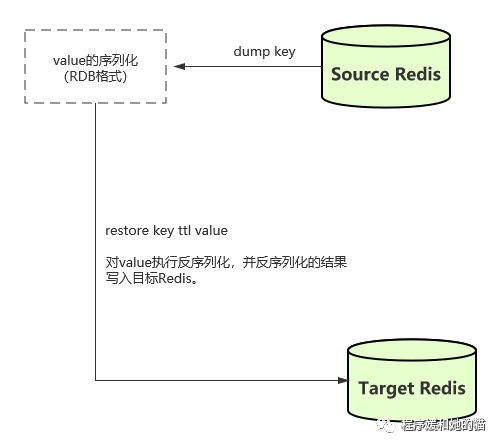
使用dump+restore,有一点需要注意,整个迁移过程并非原子性的,而是通过客户端分步完成的(source redis的客户端:将源Redis需要迁移的键对应的值执行序列化,target redis的客户端:执行反序列化,并将反序列化的结果写入目标Redis)。
下面用示例演示 dump+restore 命令,包括命令模式和Java模式,如下所示。
命令模式:
// 在源Redis上执行dump
redis-source> set hello world
OK
redis-source> dump hello
"\x00\x05world\x06\x00\x8f<T\x04%\xfcNQ"
// 在目标Redis上执行restore
redis-target> get hello
(nil)
redis-target> restore hello 0 "\x00\x05world\x06\x00\x8f<T\x04%\xfcNQ"
OK
redis-target> get hello
"world"
Java模式:
Redis sourceRedis = new Redis("sourceMachine", 6379);
Redis targetRedis = new Redis("targetMachine", 6379);
targetRedis.restore("hello", 0, sourceRedis.dump(key));
(3)、migrate host port key|"" destination-db timeout [copy] [replace] [keys key [key ..,,迁移过程是原子性的,可以迁移多个键。
•host:目标Redis的IP地址。
•port:目标Redis的端口。
•key|"":在Redis3.0.6版本之前,migrate只支持迁移一个键,所以此处是 要迁移的键,但Redis3.0.6版本之后支持迁移多个键,如果当前需要迁移多 个键,此处为空字符串""。
•destination-db:目标Redis的数据库索引,例如要迁移到0号数据库,这
里就写0。
•timeout:迁移的超时时间(单位为毫秒)。
•[copy]:如果添加此选项,迁移后并不删除源键。
•[replace]:针对这种场景,源Redis要迁移的键在目标Redis已经存在,如果添加replace选项,则正常迁移并进行数据覆盖,如果不添加replace选项,则报错迁移失败。
•[keys key[key...]]:迁移多个键,例如要迁移key1、key2、key3,此处填 写“keys key1 key2 key3”。
migrate命令也是用于在Redis实例间进行数据迁移,migrate命令是dump、restore、del三个命令的组合。
与dump+restore不同的是,migrate具有如下特点:
一是:使用migrate进行键迁移,整个过程是原子执行的,不需要在多个Redis实例上开启客户端,只需要在源Redis上执行migrate命令即可。
二是:从Redis3.0.6版本以后,migrate支持迁移多个键的功能,有效地提高了迁移效率。
基于以上两点,原子性和批量迁移,migrate成为Redis Cluster实现水平扩容的重要工具。
migrate内部操作过程,如下图所示:
第一步:在源Redis上执行migrate命令。
第二步:要迁移的数据从源Redis直接传输到目标Redis,不需要序列化、反序列化操作。
第三步:目标Redis完成restore操作后会发送OK给源Redis,源Redis接收后会根据migrate对应的选项来决定是否在源Redis上删除对应的键。
下面用示例演示 migrate 命令,如下所示,现要将源Redis的hello键迁移到目标Redis中,有以下三种情况。
情况1:源Redis有键hello,目标Redis没有:
127.0.0.1:6379> migrate 127.0.0.1 6380 hello 0 1000 OK
情况2:源Redis和目标Redis都有键hello:
127.0.0.1:6379> get hello
"world"
127.0.0.1:6380> get hello
"redis"
如果migrate命令没有加replace选项会收到错误提示,如果加了replace会返回OK表明迁移成功:
127.0.0.1:6379> migrate 127.0.0.1 6379 hello 0 1000
(error) ERR Target instance replied with error: BUSYKEY Target key name already
127.0.0.1:6379> migrate 127.0.0.1 6379 hello 0 1000 replace
OK
情况3:源Redis没有键hello。如下所示,此时会收到nokey的提示:
127.0.0.1:6379> migrate 127.0.0.1 6380 hello 0 1000
NOKEY
Redis3.0.6版本以后迁移多个键的功能:
// 源Redis批量添加多个键
127.0.0.1:6379> mset key1 value1 key2 value2 key3 value3
OK
// 源Redis执行如下命令完成多个键的迁移
127.0.0.1:6379> migrate 127.0.0.1 6380 "" 0 5000 keys key1 key2 key3
OK
18、使用redis-cli --bigkeys命令,可以找到 Redis 中内存占用比较大的的键值,这些大键可能会阻塞 Redis。
redis-cli --bigkeys 内部原理使用 scan 命令进行分段采样,把历史扫描过的最大对象统计出来。
# redis-cli --bigkeys
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
# per 100 SCAN commands (not usually needed).
[00.00%] Biggest string found so far 'ptc:-571805194744395733' with 17 bytes
[00.00%] Biggest string found so far 'RVF#2570599,1' with 3881 bytes
[00.01%] Biggest hash found so far 'pcl:8752795333786343845' with 208 fields
[00.37%] Biggest string found so far 'RVF#1224557,1' with 3882 bytes
[00.75%] Biggest string found so far 'ptc:2404721392920303995' with 4791 bytes [04.64%] Biggest string found so far 'pcltm:614' with 5176729 bytes
[08.08%] Biggest string found so far 'pcltm:8561' with 11669889 bytes
[21.08%] Biggest string found so far 'pcltm:8598' with 12300864 bytes
..忽略更多输出...
-------- summary ------
Sampled 3192437 keys in the keyspace!
Total key length in bytes is 78299956 (avg len 24.53)
Biggest string found 'pcltm:121' has 17735928 bytes
Biggest hash found 'pcl:3650040409957394505' has 209 fields
2526878 strings with 954999242 bytes (79.15% of keys, avg size 377.94)
0 lists with 0 items (00.00% of keys, avg size 0.00)
0 sets with 0 members (00.00% of keys, avg size 0.00)
665559 hashs with 19013973 fields (20.85% of keys, avg size 28.57)
0 zsets with 0 members (00.00% of keys, avg size 0.00)
19、使用redis-cli --latency命令可以获取客户端到 Redis 实例之间的网络延迟。
redis-cli --latency -h [host] -p [port],查看客户端到目标Redis之间的网络延迟,它通过测量Redis服务器以毫秒为单位响应Redis PING命令的时间来实现的,这个命令对于Redis的开发和运维非常有帮助。
host和port分别是Redis实例的IP和端口,网络延迟时间的单位是毫秒。
min:0,max:15,avg:0.12(2839 samples),这是命令返回的数据。
samples:采样数,表示redis-cli一共发出的PING命令和接收回复的次数,称为一次网络连接。
min:最小值,它表示所有网络连接中的最小延迟,这是我们采样数据的最佳响应时间。
max:最大值,它表示所有网络连接中的最大延迟,这是我们采样数据的最长响应时间。
avg:平均值,它表示所有网络连接的平均响应时间。
见下图,客户端B和Redis实例都在机房B,客户端A在机房A,机房A和机房B是跨地区的。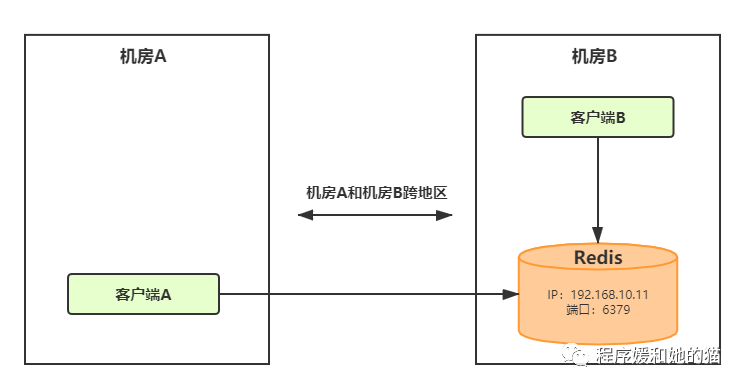
// 获取客户端B到Redis之间的网络延迟,只需在客户端B执行如下命令。
redis-cli -h 192.168.10.11 -p 6379 --latency
min: 0, max: 1, avg: 0.07 (4211 samples)
// 获取客户端A到Redis之间的网络延迟,只需在客户端A执行如下命令。
redis-cli -h 192.168.10.11 -p 6379 --latency
min: 0, max: 2, avg: 1.04 (2096 samples)
我们看到客户端A到Redis实例之间的网络延迟时间为1.04毫秒,客户端B到Redis实例之间的网络延迟时间为0.07毫秒,这是因为客户端A距离Redis比较远,所以平均网络延迟会稍微高一些。