反向传播和生物学没关系?NO!大牛告诉你:在反向传播基础上找到生物学解释 关注 共
3904字,需浏览
8分钟
·
2021-02-24 17:58
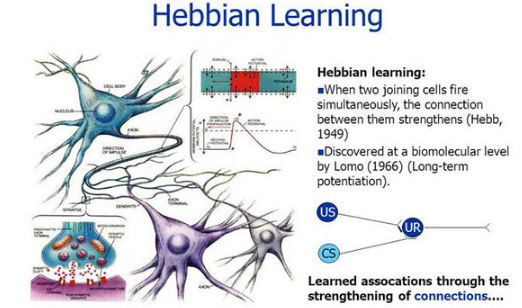
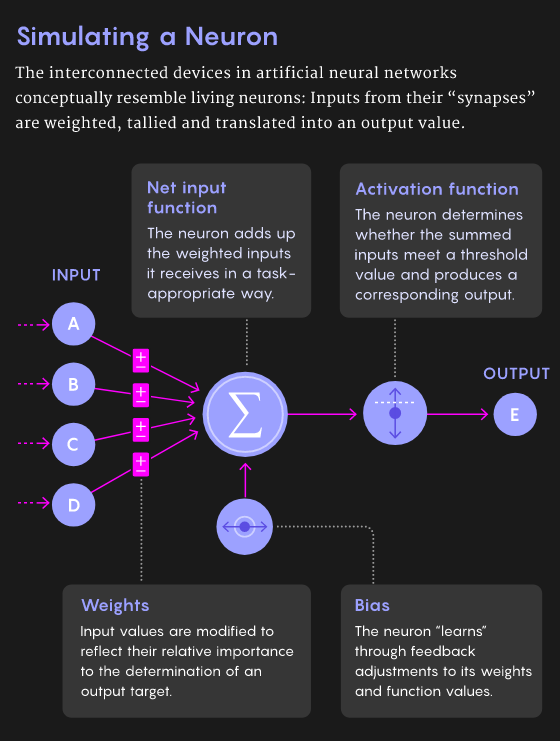
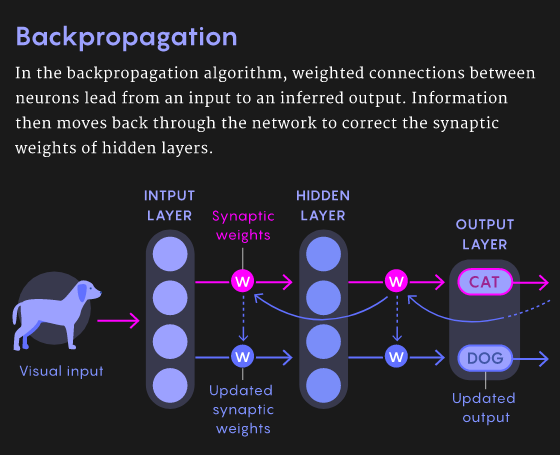
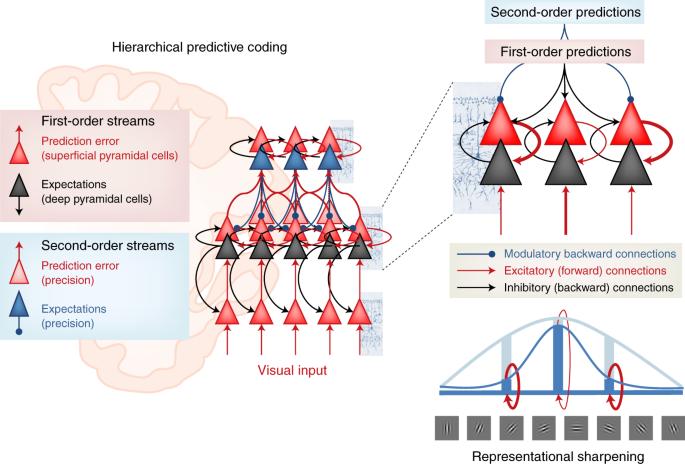
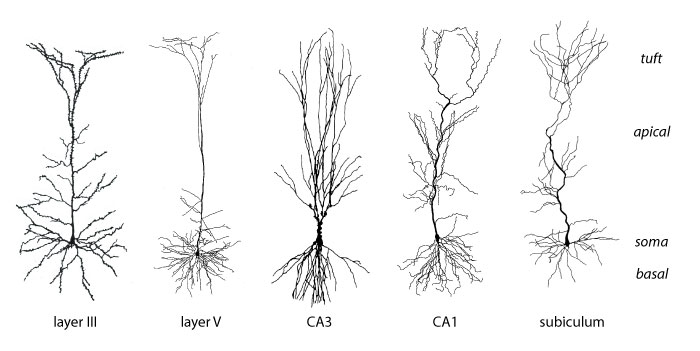
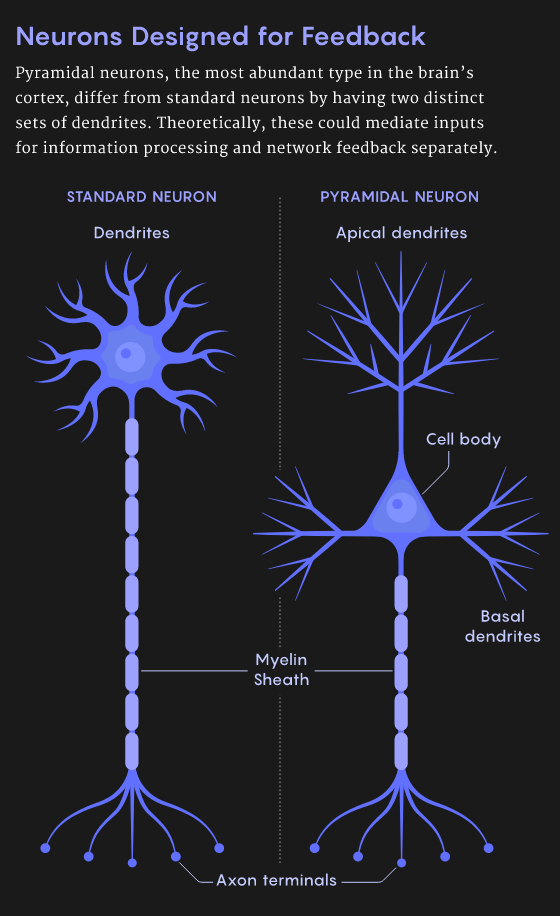
【新智元导读】 反向传播和生物学无关?近期网上出现了一些质疑,那么二者之间真的没有关系?也许Hinton和Bengio的想法可以解答你的疑惑。2007年,深度学习研究的先驱们在NIPS召开期间发起了一场关于「深度学习」的非正式研讨会,当时距离深度神经网络接管人工智能还有几年时间。 这次会上,最后一位发言人是多伦多大学的杰弗里·辛顿(Geoffrey Hinton),他以一个笑话开场: 「大概一年前,我回家吃晚饭,我说,‘我想我终于弄明白大脑是怎么工作的了’,我15岁的女儿说,‘哎呀,爸爸,又来了,别这样了。」观众大笑。 辛顿继续说:「而这,就是它的工作原理」。这又引发了更多的笑声。 人工智能领域一直都有一个严肃的追求:如何利用人工智能来理解大脑。今天,深层神经网络统治人工智能的部分原因是源于反向传播(backpropagation)算法。 但是真正的大脑不可能依赖反向传播算法。「大脑的概括和学习能力比最先进的AI系统更快更好」(Bengio),而且反向传播不符合大脑的解剖学和生理学,特别是在大脑皮层。 许多研究人员一直在思考更具生物学意义的学习机制,其中,反馈比对法、平衡传播法和预测编码法具有独特的应用前景。 一些研究人员还将某些类型的皮层神经元和注意力等过程的特性加入到他们的模型中,这些研究使我们更能理解哪些算法可能在大脑中起作用。 「人们普遍认为,对于大脑这个巨大的谜团,如果我们能够解开其中的一些原理,那将对人工智能有所帮助。但它本身也有价值。」Bengio说。 几十年来,神经科学家关于大脑如何学习的理论主要受到1949年提出的「赫布理论」影响,通常被解释为「共同激发的神经元之间存在连接」,即相邻神经元的活动越相关,它们之间的突触联系就越强。 这个原则经过一些修改后,成功解释了某些类型的学习和分类任务。 赫布规则在使用错误信息时,是一种的非常狭窄、特殊且不敏感的方法。尽管如此,这对神经科学家来说,仍然是最好的学习规则,甚至在20世纪50年代后期,它就激发了第一个人工神经网络的发展。 这些网络中的每个人工神经元接收多个输入并产生一个输出,就真实的神经元一样。人工神经元用一个所谓的「突触」权重(一个表示该输入重要性的数字),然后对输入进行加权求和。 到了20世纪60年代,这些神经元可以被组织成一个有输入层和输出层的网络,人工神经网络可以被训练来解决某些简单的问题。 在训练过程中,神经网络为其神经元确定最佳权值,以降低误差。 然而直到1986年以前,没有人知道如何有效地训练带有隐藏层的人工神经网络,直到Hinton发表了「反向传播算法」相关论文。 反向传播的发明立即引起了一些神经科学家的强烈抗议,他们认为这种方法不可能在真正的大脑中起作用。 首先,虽然计算机可以很容易地在两个阶段实现该算法,但是对于生物神经网络来说,这样做并不简单。 其次,是计算神经科学家所说的权重传递问题: 反向传播算法复制或「传输」关于推理所涉及的所有突触权重的信息,并更新这些权重以获得更高的准确性。 但是在生物网络中,神经元只能看到其他神经元的输出,而不能看到影响输出的突触权重或内部过程。 从神经元的角度来看,「知道自己的突触权重是可以的,你不能知道其他神经元的突触权重。」 任何生物学上似乎可行的学习规则也需要遵守神经元只能从相邻神经元获取信息的限制; 反向传播可能需要从更远的神经元获取信息。 因此,「如果你反向传播信号,大脑似乎不可能计算。」 2016年,DeepMind的Timothy Lillicrap提供了一个解决权重传递问题的特殊方法:使用一个随机值初始化的矩阵作为反向传递的权重矩阵,而不使用正向传递。 一旦被赋值,矩阵中的值是恒定的,因此不需要为每个反向通道传输权重。让人惊讶的是,网络仍然是可训练的。 由于用于推理的正向权值和每次反向通道的更新频率一致,因此网络仍然沿着不同的路径减小误差。 正向权重慢慢地与随机选择的反向权重对齐,最终得到正确的答案,这种算法就是「反馈对齐」。 对于大规模的问题和具有更多隐藏层的更深层次的网络,反馈对齐不如反向传播好: 因为正向权重的更新不如真正的反向传播信息准确,所以训练网络需要更多的数据。 在辛顿研究的基础上,本吉奥的团队在2017年提出了一个学习规则,要求神经网络具有循环连接(也就是说,如果神经元A激活神经元B,那么神经元B反过来激活神经元A)。 如果给这样一个网络一些输入,网络就会自我学习,每个神经元都与直接相邻的神经元来传递权重。 神经网络达到一个最终状态,在这个状态中神经元与输入以及彼此之间处于平衡,它产生一个输出,然后该算法将输出神经元推向预期结果。 这就通过网络设置了另一个反向传播的信号,引发了类似的动态。网络找到了新的平衡点。训练网络在大量的标记数据上重复这个「平衡传播」过程。 Beren Millidge提出的预测编码(predictive coding),也同样要求反向传播。「如果合理设置预测编码,将会生成一个在生物学上看起来很合理的学习规则。」 预测编码假定大脑不断地对感觉输入的原因进行预测。这个过程包括了神经处理的层次结构。 为了产生特定的输出,每一层必须预测前一层的神经活动。如果最上层想要看到一张脸,那他就会预测前一层的活动来判断这种感知的预测。 前面的层对更前的层进行相似的预测,以此类推。最低层能够预测实际的感受输入,比如说光子落在视网膜上。 但是错误可能发生在任何一个网络中的任何一个层,每层的期望的输入和实际的输入之间的存在误差。 最底层根据接收到的感知信息调整突触的权重来降低误差。这个调整结果导致了更新后的高层和更上面一层之间的误差,因此更高层也必须调整突触的权重来降低预测误差。 这些错误信号向上逐层传递,直到每层的预测误差都达到最小值。通过适当的设置,预测编码网络可以收敛到和反向传播几乎相同的学习梯度值。 然而,对于反向传播运行一次来说,预测编码网络必须迭代多次。尽管如此,如果可以接受一定程度上不准确的预测结果,预测编码通常可以快速地得到有用的答案。 一些科学家已经开始研究基于单个神经元的已知特性来构建类似反向传播的算法。 标准神经元有树突,它们从其他神经元的轴突中收集信息。树突传递信号到神经元的细胞体来整合信号。 但并非所有的神经元都有这种结构。特别是锥体神经元,它在大脑皮层中有着最丰富的的神经元类型。 锥体神经元具有树状结构,有两套不同的树突。树干向上伸展,分枝形成所谓的顶端树突。 树干向上延伸,分枝形成顶端树突。根向下延伸,分枝形成基部树突。 2001年由Kording独立开发的模型已经表明锥体神经元能够同时进行向前和向后计算,可以作为深度学习网络的基本单元。 模型的关键是分离进入神经元的信号,包括前向推理或者向后的流动误差。这些误差可以通过基树突和顶树突分别处理。 这两种信号都可以编码在神经元传递到轴突电活动的尖峰中。 Richards的团队最新研究表明,已经可以通过相当真实的神经元模拟,来训练锥体神经元网络去完成各种各样的任务。 对于使用反向传播的深度网络,一个隐含的要求就是必须有「老师」来帮助计算神经元网络的误差。 但是,大脑中没有一个老师会告诉运动皮层中的每一个神经元,「你应该被打开,你应该被关闭。」 Roelfsema认为大脑解决这个问题的方案是「注意力」。 在上世纪90年代后期,他和他的同事发现,当猴子盯着一个物体,在大脑皮层中表示该物体的神经元变得更加活跃。 「这是一个高度选择性的反馈信号,它不是一个错误信号。他只是告诉这些神经元:你们负责这个动作。」 当这种反馈信号与其他神经科学的研究成果结合起来时,可以实现类似反向传播学习的效果。 剑桥大学的Wolfram Schultz和其他研究人员已经证明:当动物做一个行动产生比预期更好的结果时,大脑中的多巴胺系统就会被激活。 「他让整个大脑充满了神经调节剂。多巴胺水平就像一个全局强化的信号。」 理论上,注意力的反馈信号只能通过更新对应的突触权重来启动那些负责对整体强化信号做出反应的神经元。 Roelfsema和他的同事利用这个想法构建了一个深层神经网络,并且研究了数学属性,得到的是和反向传播基本相同的等式,但在生物学上有了合理的解释。 这个团队在NIPS上展示了这项工作,它可以被训练成深层次的网络,这只比反向传播慢两到三倍,比其他所有生物学相关的算法都要快。 鉴于这些进步,计算神经学家们对未来的发展十分乐观。 Hinton提出的反向传播,并且是深度学习的大大牛,但是现在他一直在否定自己的工作,提出胶囊网络还有其他工作来增加生物学上的解释。 https://www.quantamagazine.org/artificial-neural-nets-finally-yield-clues-to-how-brains-learn-20210218/ 浏览
54
分享
手机扫一扫分享
分享
手机扫一扫分享