
ZooKeeper源码分析系列一开篇基础知识剖析
点击关注公众号,Java干货及时送达
一、ZooKeeper总体介绍
1.1、什么是zookeeper
ZooKeeper 是一个分布式的,开放源码的分布式应用程序协同服务+存储系统,同时是一款世界级的优秀开源产品,在大数据生态系统中 Hadoop、Storm、HBase、Spark、Flink、Kafka 随处都是 ZooKeeper的应用场景。特别是在粗粒度分布式锁、分布式选主、主备高可用切换等不需要高 TPS 的场景下有不可替代的作用。
1.2、ZooKeeper 应用场景
很多分布式协调服务都可以用 ZooKeeper 来做,其中典型应用场景如下:
1、配置管理:比如微服务系统,各个独立服务都要使用集中化的配置管理,这个时候就需要 ZooKeeper。
2、组成员管理:比如上面讲到的 HBase 其实就是用来做集群的组成员管理。
3、各种分布式锁:ZooKeeper 适用于存储和协同相关的关键数据,不适合用于大数据量存储。如果要存 KV 或者大量的业务数据,还是要用数据库或者其他 NoSql 来做。
4、注册中心:大多数中小型公司都用zk来做注册中心
至于为什么 ZooKeeper 不适合大数据量存储呢?主要有以下两个原因:
1、设计方面:ZooKeeper 需要把所有的数据(它的 data tree)加载到内存中。这就决定了ZooKeeper 存储的数据量受内存的限制。一般的数据库系统例如 MySQL可以存储大于内存的数据,这是因为 InnoDB 是基于 B-Tree 的存储引擎(基于内存+磁盘一致性)。
2、工程方面:ZooKeeper 的设计目标是为协同服务提供数据存储,数据的高可用性和性能是最重要的系统指标,处理大数量不是 ZooKeeper 的首要目标。因此,ZooKeeper 不会对大数量存储做太多工程上的优化。
二.ZooKeeper源码环境
2.1、ZooKeeper版本选择
在了解任何技术源码的时候,最重要的两件事要搞清楚:
1、版本如何选择
2、源码环境准备
zookeeper的大版本:
1、zookeeper-3.4.x 企业最常用,大数据技术组件最常用
2、zookeeper-3.5.x
3、zookeeper-3.6.x
最总结论:zookeeper-3.4.14.tar.gz,安装包就是源码包, ZooKeeper-3.5 以上,源码 和 安装包就分开了。
2.2、 ZooKeeper源码环境准备
1、准备一个IDE:IDEA
2、从官网下载源码包,IDEA去导入这个源码项目即可
3、稍微等待一下,maven去下载一些依赖jar
4、从官网下载 zookeeper-3.4.14.tar.gz 安装包,该安装包直接包含源码或者从 github 去拉取源码项目
三.ZooKeeper基础之序列化机制
3.1、序列化使用场景
1、当在网络中需要进行消息,数据传输,那么这些数据就需要进行序列化和反序列化
2、当数据需要被持久化到磁盘的时候
3.2、什么是序列化, 为什么要进行序列化操作
1、序列化是指将我们定义好的 go/php/java 类型转化成数据流的形式。之所以这么做是因为在网络传输过程中,TCP 协议采用“流通信”的方式,提供了可以读写的字节流
2、任何一个分布式系统的底层,都必然会有网络通信,这就必然要提供一个分布式通信框架和序列化机制。所以我们在看 ZooKeeper 源码之前,先搞定 ZooKeeper 网络通信和序列化。
3.3、序列化实现方式
3.3.1、java序列化实现
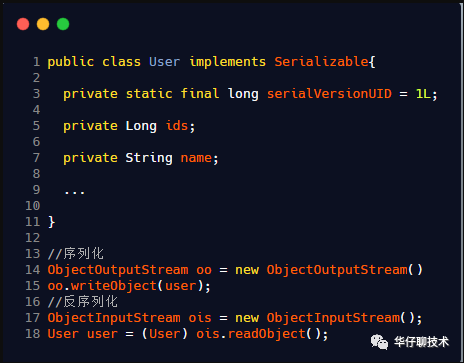
Java 中进行序列化和反序列化的过程中,主要使用 ObjectInputStream 和 ObjectOutputStream 来进行具体的序列化和反序列化。
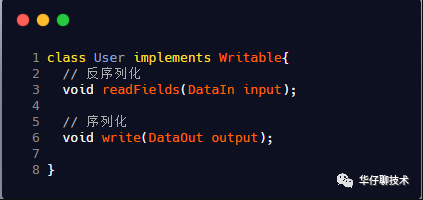
3.3.2、hadoop的序列化实现
3.3.3、ZooKeeper 中的序列化机制
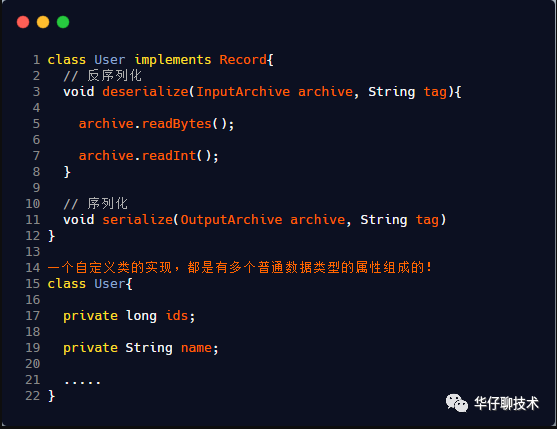
序列化的 API 主要在 zookeeper-jute 子项目中。
3.3.4、重点API:
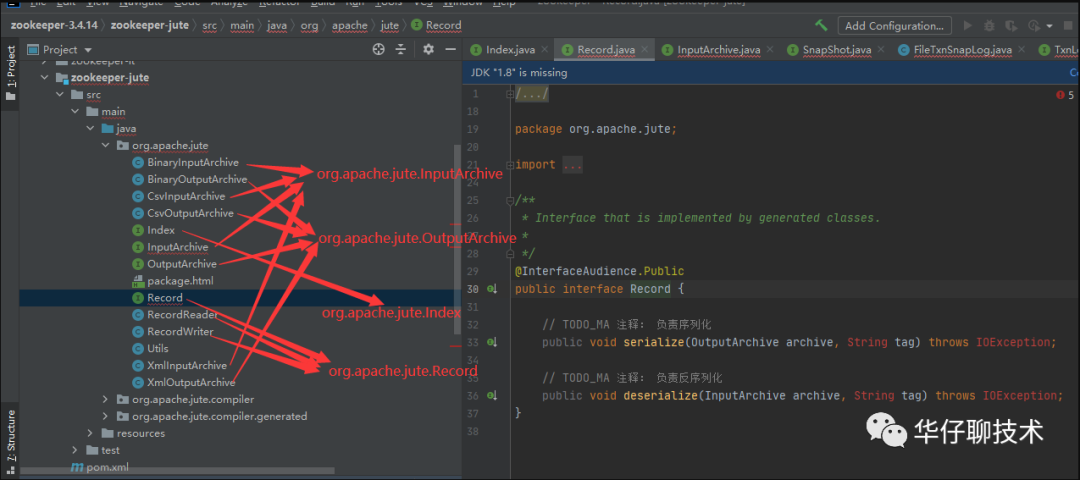
org.apache.jute.InputArchive:反序列化需要实现的接口,其中各种 read 开头的方法,都是反序列化方法
org.apache.jute.OutputArchive:所有进行序列化操作的都是实现这个接口,其中各种 write 开头的方法都是序列化方法。
org.apache.jute.Index:用于迭代数据进行反序列化的迭代器
org.apache.jute.Record:在 ZooKeeper 要进行网络通信的对象,都需要实现这个接口。里面有序列化和反序列化两个重要的方法
四、ZooKeeper基础之持久化机制
对于只要底层涉及到关于数据的存储,读写操作, 一般都会有一个持久化机制来保证.那么ZooKeeper的数据模型主要涉及两类知识:数据模型 和 持久化机制, 背后是两套API来支撑
1、数据模型 : ZKDataBase + DataTree + DataNode
2、持久化机制: TxnLog + SnapLog
ZooKeeper 本身是一个对等架构(内部选举,从所有 learner 中选举一个 leader, 剩下的成为follower)
1、每个节点上都保存了整个系统的所有数据(leader存储了数据,所有的follower节点都是leader的副本节点)
2、每个节点上的都把数据放在磁盘一份,放在内存一份, 保证磁盘跟内存一致性,来平衡读写性能
ZooKeeper的数据模型,抽象出了重要的三个API用来完成数据的管理:
1、ZKDataBase 负责管理 DataTree ,执行 DataTree 的相关 快照和恢复的操作
2、DataTree znode系统的完整抽象, 整个数据树结构
3、DataNode znode 系统中的一个节点的抽象
关于 ZooKeeper 中的数据在内存中的组织,其实就是一棵树:
1、这棵树就叫做:DataTree (抽象了一棵树)
2、这棵树上的节点:DataNode (抽象一个节点)
3、关于管理这个 DataTree 的组件就是 ZKDataBase (内存数据库:针对 DataTree 能做各种操作)
ZooKeeper 的持久化的一些操作接口,都在org.apache.zookeeper.server.persistence 包中。
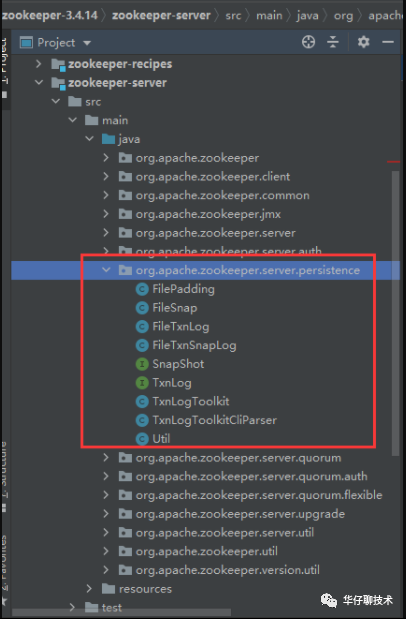
主要的类的介绍:
第一组:主要是用来操作日志的(如果客户端往zk中写入一条数据,则记录一条日志)
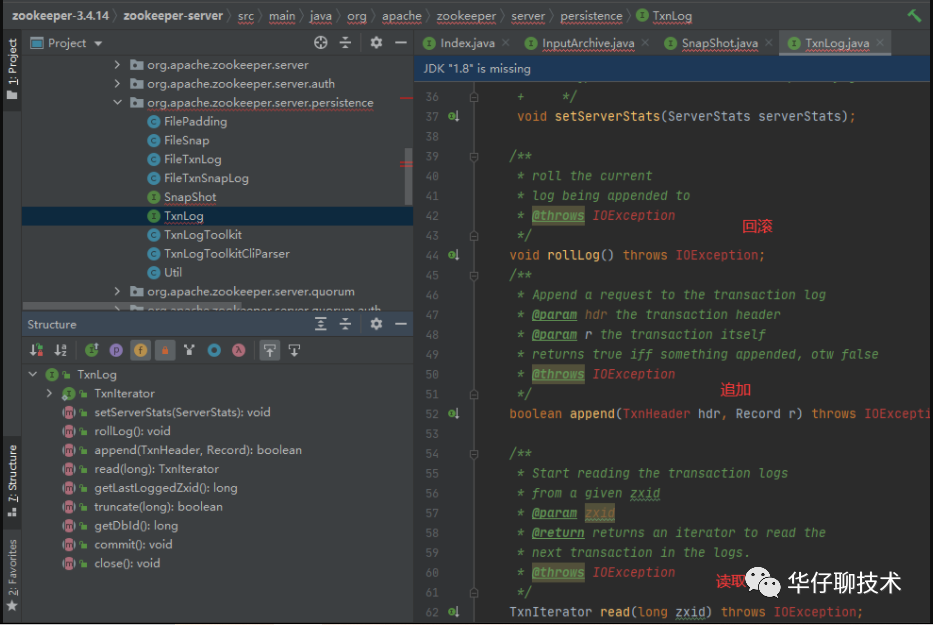
TxnLog,接口,读取事务性日志的接口。
FileTxnLog,实现TxnLog接口,添加了访问该事务性日志的API。
第二组:拍摄快照(当内存数据持久化到磁盘)
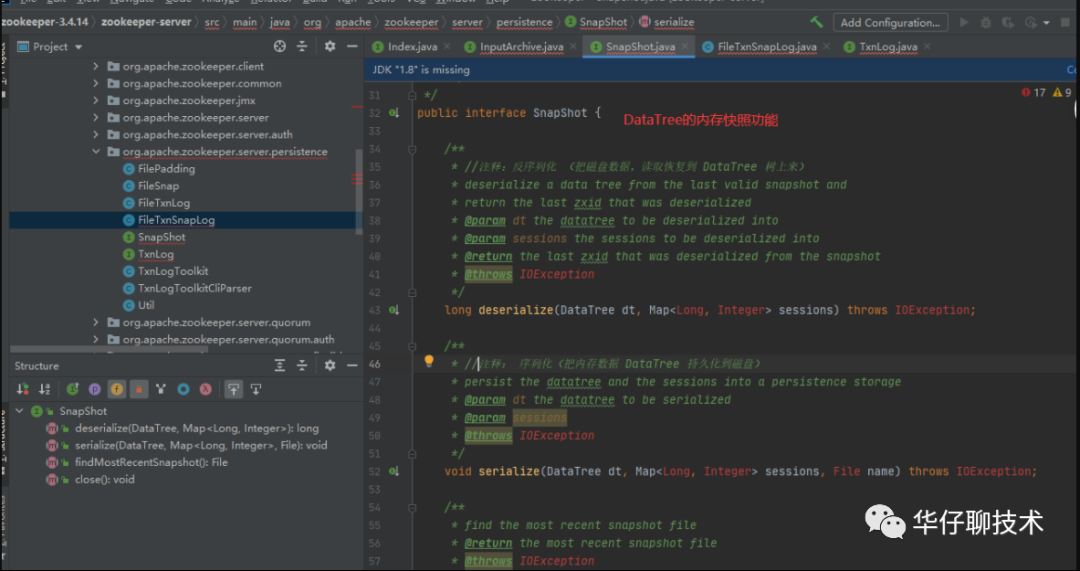
Snapshot,接口类型,持久层快照接口。
FileSnap,实现Snapshot接口,负责存储、序列化、反序列化、访问快照。
第三组;两个成员变量:TxnLog和SnapShot
FileTxnSnapLog,封装了TxnLog和SnapShot。
第四组:工具类
Util,工具类,提供持久化所需的API。
五、ZooKeeper基础之网络通信机制
Java IO 有几个种类:
1、BIO JDK-1.1(编码简单,效率低) 阻塞模型
2、NIO JDK-1.4(效率有提升,编码复杂) 基于reactor实现的异步非阻塞网络通信模型 通常的IO的选择:
1)、原生NIO 2)、基于NIO实现的网络通信框架:netty
3、AIO JDK-1.7(效率最高,编码复杂度一般) 真正的异步非阻塞通信模型
NIO 的三大API:
1、Buffer
2、Channel
3、Selector
ZooKeeper 中的通信有两种方式:
1、NIO,默认使用NIO
2、Netty
两个最重要的API:
ServerCnxn 服务端的通信组件
ClientCnxn 客户端的通信组件
关于客户端和服务端的一个定义:谁发请求,谁就是客户端,谁接收和处理请求,谁就是服务端
1、真正的client给zookeeper发请求
2、zookeeper中的leader给follower发命令
3、zookeeper中的followe给leader发请求
ServerCnxn实现包:org.apache.zookeeper.server.ServerCnxn
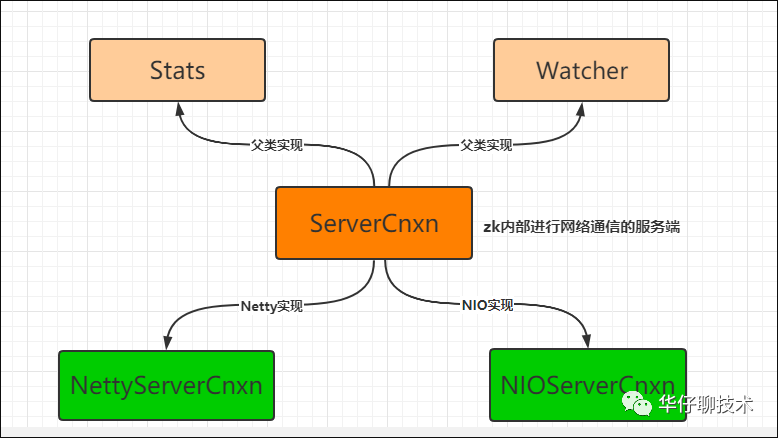
ServerCnxn实现包
详细说明:
Stats,表示ServerCnxn上的统计数据。
Watcher,表示事件处理,监听器
ServerCnxn,表示服务器连接,表示一个从客户端到服务器的连接。
ClientCnxn,存在于客户端用来执行通信的组件
NettyServerCnxn,基于Netty的连接的具体实现。
NIOServerCnxn,基于NIO的连接的具体实现。
六、Zookeeper基础之Watcher工作机制
客户端的 Watcher 注册:
1、org.apache.zookeeper.ZooKeeper:客户端基础类、存储了ClientCnxn和ZkWatcherManager
2、ZKWatchManager:ZooKeeper的内部类,实现了ClientWatchManager接口,主要用来存储各种类型的Watcher,主要有三种:dataWatches、existWatches、childWatches以及一个默认的defaultWatcher
3、org.apache.zookeeper.ClientCnxn:与服务端的交互类,主要包含以下对象:LinkedListoutgoingQueue、SendThread 和 EventThread,其中outgoingQueue未待发送给服务端的Packet列表,SendThread线程负责和服务端进行请求交互,而EventThread线程则负责客户端Watcher事件的回调执行
4、WatchRegistration:Zookeeper的内容类,包装了Watcher和clientPath,并且负责Watcher的注册
5、Packet:ClientCnxn的内部类,与Zookeeper服务端通信的交互类
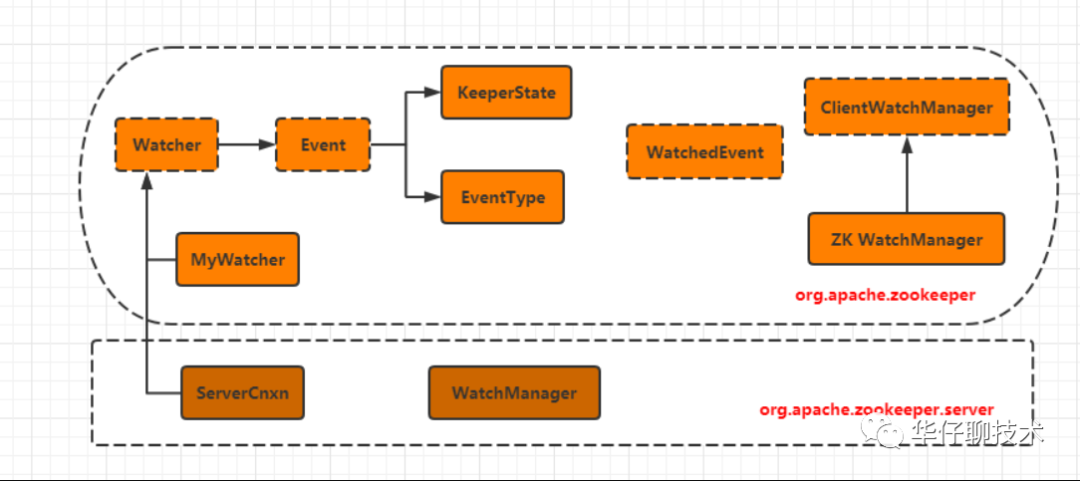
两条主线
1、实现主线:Watcher + WatchedEvent
2、管理主线:WatchManager(负责响应watcher.process(watchedEvent)) + ZKWatchManager(负责注册等相关管理)
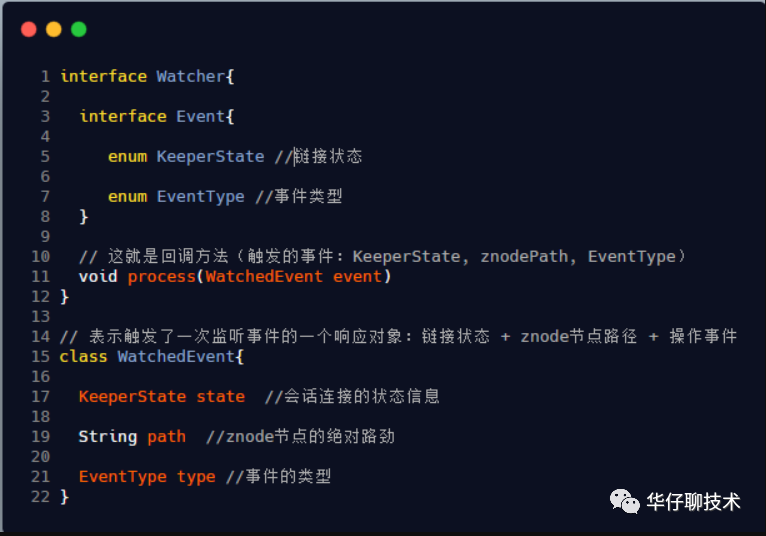
组件说明:
Watcher,接口类型,其定义了process方法,需子类实现。
Event,接口类型,Watcher的内部类,无任何方法。
KeeperState,枚举类型,Event的内部类,表示Zookeeper所处的状态。
EventType,枚举类型,Event的内部类,表示Zookeeper中发生的事件类型。
WatchedEvent,表示对ZooKeeper上发生变化后的反馈,包含了KeeperState和EventType。
ClientWatchManager,接口类型,表示客户端的Watcher管理者,其定义了materialized方法,需子类实现。
ZKWatchManager,Zookeeper的内部类,继承ClientWatchManager。
MyWatcher,ZooKeeperMain的内部类,继承Watcher。
ServerCnxn,接口类型,继承Watcher,表示客户端与服务端的一个连接。
WatchManager,管理Watcher。
Watcher 主要工作流程:
1、用户调用 Zookeeper 的 getData 方法,并将自定义的 Watcher 以参数形式传入,该方法的作用主要是封装请求,然后调用 ClientCnxn 的 submitRequest 方法提交请求
2、 ClientCnxn 在调用 submitRequest 提交请求时,会将 WatchRegistration(封装了我们传入的Watcher 和clientPath )以参数的形式传入,submitRequest 方法主要作用是将信息封装成Packet(ClientCnxn的内部类),并将封装好的 Packet 加入到 ClientCnxn 的待发送列表中(LinkedList outgoingQueue)
3、 SendThread 线程不断地从 outgoingQueue 取出未发送的 Packet 发送给客户端并且将该 Packet加入pendingQueue (等待服务器响应的Packet列表)中,并通过自身的 readResponse 方法接收服务端的响应
4、SendThread 接收到客户端的响应以后,会调用 ClientCnxn 的finishPacket 方法进行 Watcher方法的注册
5、在 finishPacket 方法中,会取出 Packet 中的 WatchRegistration 对象,并调用其 register 方法,从ZKWatchManager 取出对应的 dataWatches、existWatches 或者 childWatches 其中的一个Watcher 集合,然后将自己的 Watcher 添加到该 Watcher 集合中。
往 期 推 荐
1、致歉!抖音Semi Design承认参考阿里Ant Design
点分享
点收藏
点点赞
点在看




