
用 AI 斗地主,就问你秀不秀!
你永远无法知道,和你游戏对线的人是谁。

比如,玩斗地主。
你能想到,你的对手可能是一个人工智能算法吗?
最近,有个开源项目火了,DouZero 斗地主 AI 。
先看看它有多猛!
斗地主是个充满「运气」的游戏,所以不可能做到围棋象棋那样完胜人类。我们只能从很多对局中看出差距。
大量的实验结果表明,它比已有的斗地主AI都要强。我们尽可能的把DouZero与已知的所有斗地主AI进行了比较,发现DouZero都有明显优势。
其次,它可以达到人类玩家水平。在我们的在线演示中,人类玩家综合胜率不到40%。在斗地主这种运气成分比较高的游戏中,算是比较显著的。
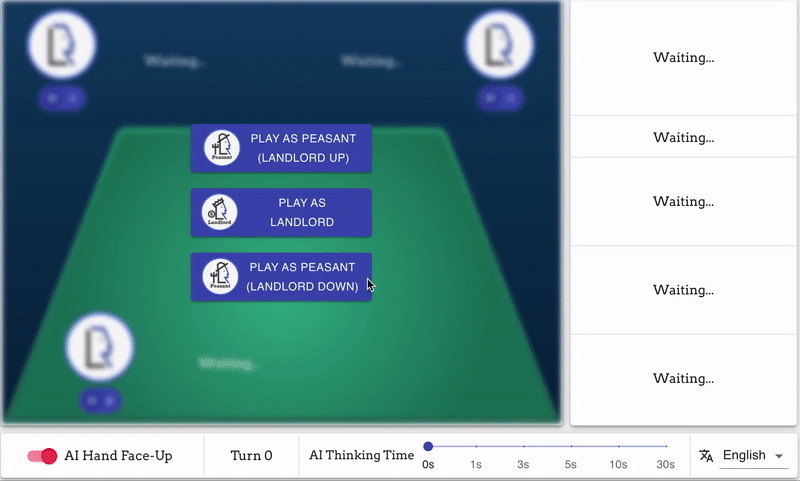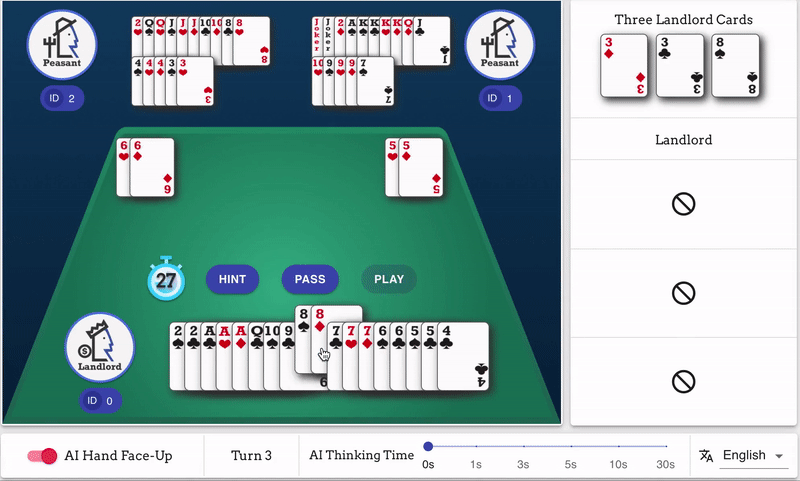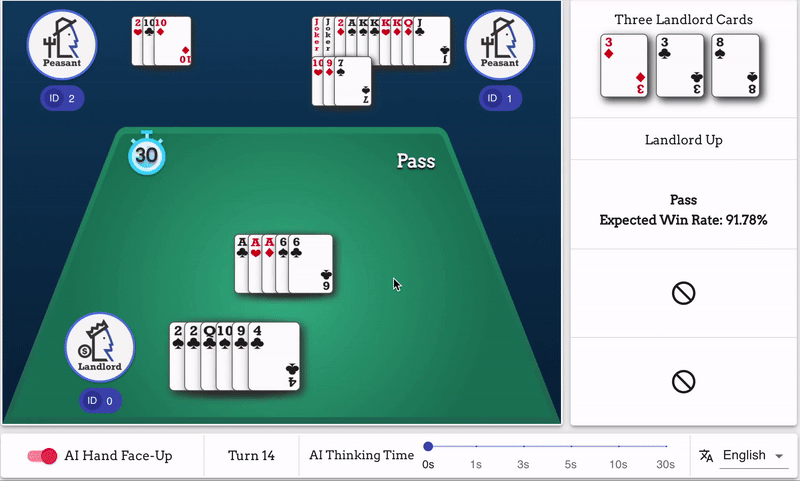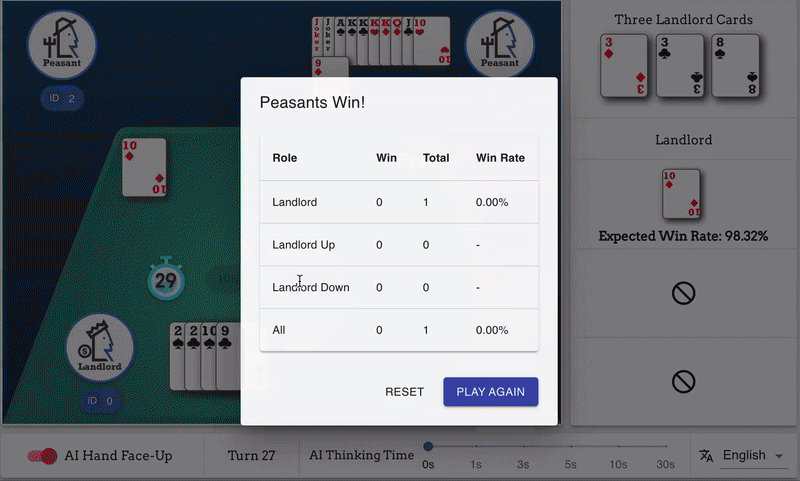
在这篇文章中,我将用通俗易懂的语言详细解析 DouZero 背后算法的原理,供大家参考。
之后我会介绍 RLCard ,一个专门为游戏 AI 设计的开源工具包。RLCard 也已经集成了 DouZero 中的算法,并且支持八种游戏实现(包括斗地主、麻将、德州扑克等)以及各种强化学习算法(比如 DouZero 中使用的算法 DMC、DQN、CFR 等)。
希望这篇文章能帮助到游戏 AI 的研究者和开发者们,也希望我们的研究和工具包能帮助到大家。
在线游戏:https://douzero.org/
开源地址:https://github.com/kwai/DouZero
背景
用强化学习打游戏对大家来说一定不陌生,常见的游戏AI,比如围棋、DOTA、星际争霸、王者荣耀等,都有强化学习的身影。
在这里,我们以斗地主为例,简单介绍下强化学习的输入是什么、输出是什么,是怎么学习的。对强化学习非常熟悉的的读者可以跳过本章。
强化学习的目标是针对一个特定的任务去学习一个策略来最大化奖励。放在斗地主的环境下,任务是学打斗地主,策略是指出牌策略(先不考虑叫牌),奖励是输赢(先不考虑炸弹加倍)。
那么什么是策略呢?这里我们引入强化学习中的两个概念,状态和动作。状态是指一个策略在某一时刻所能看到所有信息。在斗地主中,状态包括玩家当前的手牌、过去的出牌历史、地主的三张牌等等(注意,这里不包括其他玩家的手牌)。
动作是指在某一个状态下做出的一个行为。在斗地主中,动作指玩家打出的牌型,例如单张、对子、三带一、炸弹等等。那么策略其实就是一个由状态到动作的一个函数映射,也就是我们优化的目标。它可以是简单的规则,也可以是深度神经网络。我们接下来引入状态转移的概念。在斗地主中,状态是会改变的。
例如当玩家出了一张牌后,它的手牌会少一张并且出牌历史记录里会多了一张牌,这个过程我们称为状态转移。在强化学习中,我们假设下一个状态是由前一个状态和在上一个状态做的动作决定的,这也被称为马尔可夫决策过程。
根据以上定义,我们重新描述一下用强化学习学打斗地主这个任务。我们希望为每个位置(地主、地主上家和地主下家)分别学出一个策略来达到以下效果:当每个位置用其学到的策略来打牌时,经过多次状态转换直到一局游戏的结束最终得到的奖励(可以是输赢,也可以考虑炸弹算得分)的期望值达到最大。
当然这个描述中奖励还有一些瑕疵,因为输赢不仅取决于策略好不好,还取决于对手强不强。下一章我们详细分析这个问题。
那么强化学习是怎么学习的呢?强化学习的原理在于不断试错。例如在斗地主中,一开始我们并不能直接知道哪个动作是好的,但是当我们打完一局游戏后,我们可以根据输赢获取正反馈或者负反馈。
对于正反馈,强化学习算法会基于某种机制来增大未来在相同或者类似的状态做当前动作的概率。相反,对于负反馈,算法会减小未来在相同或者类似的状态做当前动作的概率。经过一次试错后,策略根据反馈进行了更新;在下一次试错中,算法会用新的策略去打牌产生新的数据。经过很多次迭代,算法最终学到一个比较强的策略。
斗地主难在哪里?
上面描述了一般的强化学习设定。那么斗地主对于强化学习难在哪里呢?难点大致可以归纳为以下几点:
合作与竞争并存:斗地主中有三个角色,包括一个地主和两个农民。农民之间需要相互配合来共同对抗地主。这种多智能体的设定对强化学习来说是很难的。比如,地主最后得到的奖励(输赢)取决于两个农民策略的强度。如果两个农民很强,地主就很容易赢:如果两个农民都很弱,地主的策略即便很弱也很容易赢。对农民来说就更加复杂了,农民得到的奖励不仅关系到地主强不强,还取决于队友给不给力(毕竟遇到猪队友很难赢)。在这样一种奖励不明确的情况下,训练强化学习是很难的。 庞大而复杂的动作空间:斗地主中有复杂的牌型组合,比如单牌、对子、顺子、三带一等,一共有上万种可能的组合,在很大动作空间下训练强化学习是很难的。 非完美信息:有人可能会问,阿法狗还有它的后代AlphaZero连围棋这么难的游戏都能解决,可以来斗地主吗?还真没那么容易,原因在于斗地主是非完美信息游戏,每个玩家看到的信息是不对称的。具体来说,斗地主中的玩家不能看到其他玩家手牌,而围棋中双方玩家都能看到所有的棋子。如此,智能体只能靠「猜」来做决策,增加了很多变数,导致AlphaZero中的算法MCTS不能直接用得上。当然并不是说斗地主比围棋难,它们都很难,区别在于难的点不一样。围棋难在庞大的状态空间和很深的决策树,而斗地主难在合作与竞争并存的设定、巨大的动作空间和非完美信息。
核心算法
DouZero使用的强化学习算法非常简单。有多简单呢?我们数学课上学过「用频率估计概率」。当我们要知道某个事件发生的概率时,我们可以通过重复采样,根据事件发生的频率来估计概率。这种方法有个更高端的名字,叫做「蒙特卡罗方法」。蒙特卡罗方法很容易和强化学习联系起来,因为强化学习也是通过不断重复采样来做估计。几十年前在还没有深度学习的时候就有学者想到了这一点。
具体怎么做呢?首先,我们介绍价值的概念:价值是指当前情况下预期的奖励是多少;在这里,我们主要考虑 价值,指的是在某个状态去做某个动作预期的价值是多少。那么我们知道 值有什么用呢? 值可以用来做决策:在某个状态下,我们可以自然而然地选择Q值最大的动作,因为它预期能带来的奖励最大。在强化学习中,我们一般用 来表示在状态 和动作 下的 值。在非深度学习的时代, 一般都是离散的,用表格实现。
我们怎么样用「蒙特卡罗方法」学习出 表格呢?我们可以用重复采样的方法去迭代更新 表格中的值,直到收敛。首先,我们初始化 表格中的值(比如0)和一个随机的的策略 ( 会对于当前状态 输出一个动作)。然后,我们迭代执行以下步骤(以斗地主为例):
用当前的策略 去生成一场对局,得到奖励 。 对在当前对局中出现所有的 对,我们将对应 值更新为 (在其他任务中,同样的 对可能出现多次;一种可能的方法是取平均值)。 对在当前对局中所有的 ,。
这个步骤重复做两件事:第一,用当前的策略去采样;第二,用采样的数据去估计 值。这个简单方法在学术界不怎么受重视,主要原因是蒙特卡罗方法的方差会比较大,导致采样效率比较低。以斗地主为例,假设智能体在某一个状态做一个动作,最后它赢了,得到+1的奖励;在另一局游戏中同样的状态下做同样的动作,因为队友不给力,最后输了,得到-1的奖励。那么在同样的情况下,一个是+1一个是-1,就会造成很大的方差。如此,智能体需要采集很多的样本才能得到一个相对准确的估计。为了提高效率,很多强化学习算法,比如DQN,会用boostraping的方法以提高bias(偏差)的代价来降低方差,以达到更好的采样效率。
注意,以上我们讨论的都是采样效率,即打了多少场斗地主。在实际操作中,当我们有比较好的模拟器时,我们更关心挂钟时间(wall-clock time),即学打斗地主花了多长时间。除了采样开销,算法本身也会有开销:比较复杂的强化学习算法,比如DQN,会用经验回放、TD学习等操作。经验回放会维护一个缓存区用来存放过去的数据,需要内存和计算开销;DQN的TD学习有一个取最大值的操作,需要做一次神经网络的推理,也需要不少的开销。与之相反,蒙特卡罗方法本身的开销几乎可以忽略不计。因此,蒙特卡罗方法虽然采样效率可能不高,但因为其极度简单,从计算量来看它很高效。
注意,DouZero虽然叫的是「Zero」,但用的不是Alpha系列的树搜索的模式。「Zero」的意思是不需要人类知识,从「零」开始。树搜索一般都要非常大的开销,比如上千块CPU。DouZero的蒙特卡罗方法不做搜索,因此只需要4块GPU训练。虽然个人一般没有这个计算资源,但对大多数做机器学习相关的实验室来说,这算是非常小的开销了。相信很多读者都能基于DouZero的代码快速实验。
加强蒙特卡罗算法
标准的蒙特卡罗算法只能处理离散的情况,但斗地主的状态和动作空间都非常大,普通的蒙特卡罗算法不能直接用。这里我们给它做些加强来应对斗地主:
把 表格换成神经网络,称作 网络。 用Mean-Square-Error(MSE) 的损失来更新 网络。 我们对斗地主中的动作也进行编码(后面会详细介绍)。 我们在采样中引入 greedy 机制来鼓励探索。
因为我们引入了深度神经网络。我们把这个方法称为深度蒙特卡罗(Deep Monte-Carlo)。这个方法也可以看作是只包含价值网络的AlphaZero(去掉搜索和策略网络;当然这个价值是 价值,而AlphaZero里是状态的价值)。这个方法有几个优点:
实现简单,效率高。简单并行处理后产生数据很快。 超参数很少,避免调参的麻烦。 因为没有用bootstrapping,所以不会有偏差的烦恼。 通用性很强。
这个方法可能的缺点就是方差很大。但因为算法本身简单,采样速度快,所以可以通过采集大量的样本来降低方法。在实际中(斗地主游戏),这种组合效果很好。
DouZero系统实现
接下来,我们介绍DouZero是怎么实现基于深度蒙特卡罗算法来打斗地主,主要包括牌型编码、神经网络和多演员(actor)的并行训练。
我们将牌型编码成15x4的矩阵,其中15表示非重复牌的种类(3到A加上大小王),4表示最多每种有四张牌。我们用0/1的矩阵来编码,例子如下:
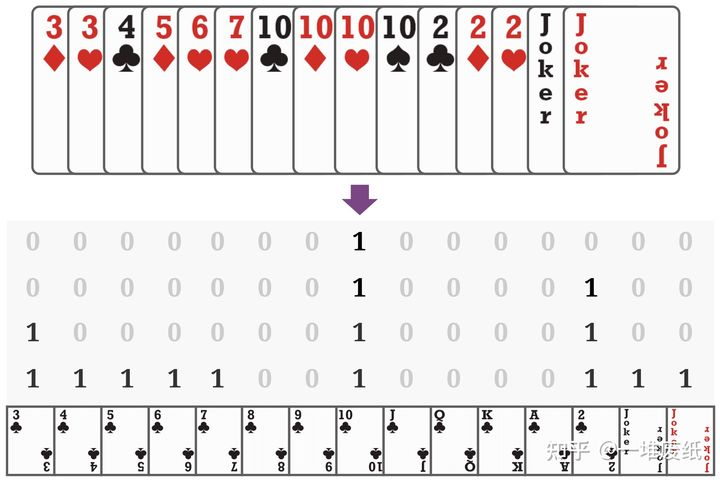
这里我们忽略了花色。有人可能会说花色也有用(当考虑地主三张牌的时候),但这毕竟是很少数的情况,我们暂不考虑。这种编码方式是非常通用,我们可以用它去编码一种特定的牌型(例如单张、对子、三带一等),也可以编码手牌、其他玩家的手牌等。有了这种编码方式,我们接下来介绍神经网路,如下图所示:
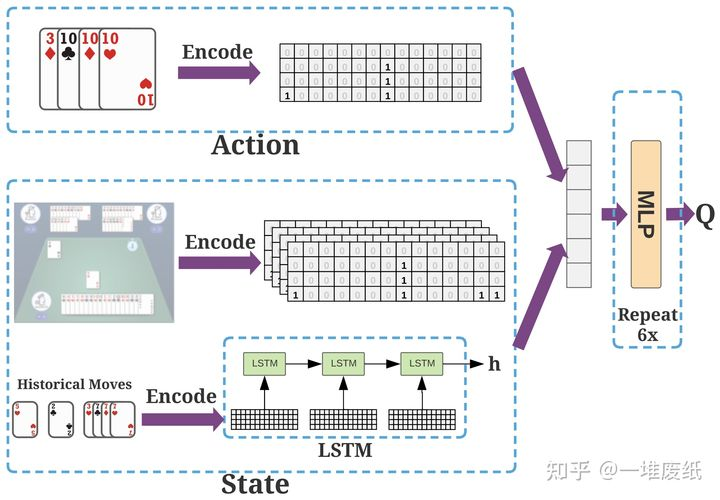
网络的输入是状态和动作,输出是 值。动作就是简单地用上面的方式进行编码。状态包括两部分:一部分是当前能看到的信息,包括手牌、其他玩家出的牌、上家的牌等特征矩阵以及其他玩家手牌数量和炸弹数量的0/1编码;另一部分是历史出牌信息,我们用LSTM网络进行编码。最后特征经过6层全连接网路得到 值。
有人或许会问为什么选择简单的全连接网络。原因是我们尝试全连接后,发现效果已经不错了。使用其他网络,比如卷积网络,或者增大网络容量,都有可能进一步提高模型的性能。
为了加快采样速度,我们采用多演员(actor)机制去模拟产生数据。每个演员进程的算法实现细节如下:

简而言之,每个演员进程不断产生数据并把数据不断地存入一个共享的缓冲器中。缓冲器里的数据会被学习器用来学习:

RLCard工具包
DouZero 是专门为斗地主设计的训练框架,但有些读者可能对别的游戏也感兴趣,或者想把深度蒙特卡罗算法迁移到别的问题中。RLCard 便可以满足这个需求。
RLCard 是一个纸牌类游戏的强化学习工具包,支持八种游戏实现(包括斗地主、麻将、德州扑克等)、各种强化学习算法(比如 DouZero 中使用的算法 DMC、DQN、CFR 等)以及分析可视化工具。DouZero 的在线演示也是基于 RLCard 开发的。RLCard 有简洁、可扩展的接口,非常适合游戏AI的开发,也可以扩展到其他单智能体或多智能体的问题,欢迎大家使用、反馈。

结语
DouZero对游戏AI的开发和强化学习的研究能带来哪些启发呢?首先,简单的蒙特卡罗算法经过一些加强效果可以很好。蒙特卡罗方法没有什么超参,实现简单,在实际应用中值得一试。从简单开始,可以更好地理解问题、设计特征、快速实验。其次,(我希望)蒙特卡罗方法能再次受到重视。蒙特卡罗方法自深度学习以来一直不受重视。大多数研究都基于DQN或者Actor-Critc,算法越来越复杂、超参越来越多。DouZero表明在有些时候,蒙特卡罗方法可能有惊人的效果。什么情况下蒙特卡罗方法适用,什么情况下不适用,还需要更多的研究。
作者:一堆废纸 | 编辑:Jack Cui
链接:https://zhuanlan.zhihu.com/p/383097277
想玩学习强化学习,用 AI 打游戏的小伙伴,不要错过~
在线游戏:https://douzero.org/
开源地址:https://github.com/kwai/DouZero
学习更多好玩的 AI 技术,记得星标关注我。
我是 Jack,我们下期见!

推荐阅读
• 好家伙,又火一个。。• 日入上万,Jack 年入百万?• AI算法,整新活!