
结合代码实践,全面学习前端工程化
点击上方 全栈前端精选,关注公众号
回复1,加入前端吐槽交流群
前言
前端工程化,简而言之就是软件工程 + 前端,以自动化的形式呈现。就个人理解而言:前端工程化,从开发阶段到代码发布生产环境,包含了以下几个内容:
开发 构建 测试 部署 性能 规范
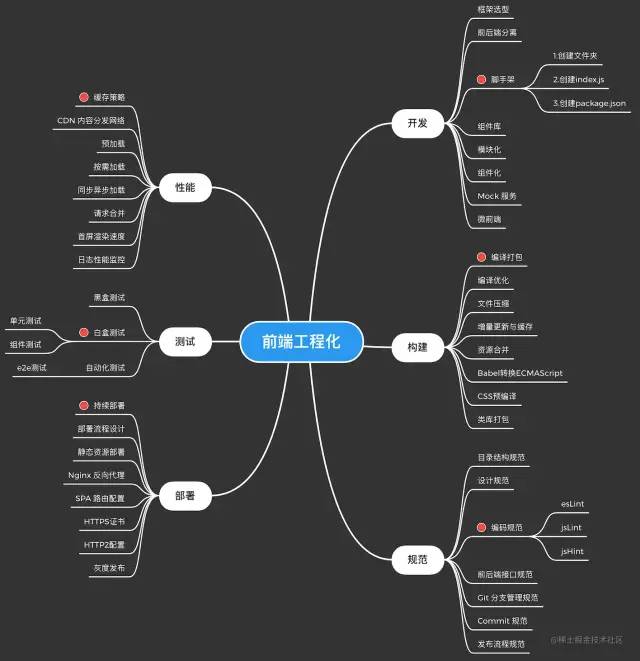 下面我们根据上述几个内容,选择有代表性的几个方面进行深入学习前端工程化。
下面我们根据上述几个内容,选择有代表性的几个方面进行深入学习前端工程化。
回顾:【青训营】- 了解前端工程化[2]
脚手架
脚手架是什么?(What)
现在流行的前端脚手架基本上都是基于NodeJs编写,比如我们常用的Vue-CLI,比较火的create-react-app,还有Dva-CLI等。
脚手架存在的意义?(Why)
随着前端工程化的概念越来越深入人心,脚手架的出现就是为减少重复性工作而引入的命令行工具,摆脱ctrl + c, ctrl + v,此话怎讲? 现在新建一个前端项目,已经不是在html头部引入css,尾部引入js那么简单的事了,css都是采用Sass或则Less编写,在js中引入,然后动态构建注入到html中;除了学习基本的js,css语法和热门框架,还需要学习构建工具webpack,babel这些怎么配置,怎么起前端服务,怎么热更新;为了在编写过程中让编辑器帮我们查错以及更加规范,我们还需要引入ESlint;甚至,有些项目还需要引入单元测试(Jest)。对于一个更入门的人来说,这无疑会让人望而却步。而前端脚手架的出现,就让事情简单化,一键命令,新建一个工程,再执行两个npm命令,跑起一个项目。在入门时,无需关注配置什么的,只需要开心的写代码就好。
如何实现一个新建项目脚手架(基于koa)?(How)
先梳理下实现思路
我们实现脚手架的核心思想就是自动化思维,将重复性的ctrl + c, ctrl + v创建项目,用程序来解决。解决步骤如下:
创建文件夹(项目名) 创建 index.js 创建 package.json 安装依赖
1. 创建文件夹
创建文件夹前,需要先删除清空:
// package.json
{
...
"scripts": {
"test": "rm -rf ./haha && node --experimental-modules index.js"
}
...
}
复制代码
创建文件夹:我们通过引入 nodejs 的 fs 模块,使用 mkdirSync API来创建文件夹。
// index.js
import fs from 'fs';
function getRootPath() {
return "./haha";
}
// 生成文件夹
fs.mkdirSync(getRootPath());
复制代码
2. 创建 index.js
创建 index.js:使用 nodejs 的fs 模块的 writeFileSync API 创建 index.js 文件:
// index.js
fs.writeFileSync(getRootPath() + "/index.js", createIndexTemplate(inputConfig));
复制代码
接着我们来看看,动态模板如何生成?我们最理想的方式是通过配置来动态生成文件模板,那么具体来看看 createIndexTemplate 实现的逻辑吧。
// index.js
import fs from 'fs';
import { createIndexTemplate } from "./indexTemplate.js";
// input
// process
// output
const inputConfig = {
middleWare: {
router: true,
static: true
}
}
function getRootPath() {
return "./haha";
}
// 生成文件夹
fs.mkdirSync(getRootPath());
// 生成 index.js 文件
fs.writeFileSync(getRootPath() + "/index.js", createIndexTemplate(inputConfig));
复制代码
// indexTemplate.js
import ejs from "ejs";
import fs from "fs";
import prettier from "prettier";// 格式化代码
// 问题驱动
// 模板
// 开发思想 - 小步骤的开发思想
// 动态生成代码模板
export function createIndexTemplate(config) {
// 读取模板
const template = fs.readFileSync("./template/index.ejs", "utf-8");
// ejs渲染
const code = ejs.render(template, {
router: config.middleware.router,
static: config.middleware.static,
port: config.port,
});
// 返回模板
return prettier.format(code, {
parser: "babel",
});
}
复制代码
// template/index.ejs
const Koa = require("koa");
<% if (router) { %>
const Router = require("koa-router");
<% } %>
<% if (static) { %>
const serve = require("koa-static");
<% } %>
const app = new Koa();
<% if (router) { %>
const router = new Router();
router.get("/", (ctx) => {
ctx.body = "hello koa-setup-heihei";
});
app.use(router.routes());
<% } %>
<% if (static) { %>
app.use(serve(__dirname + "/static"));
<% } %>
app.listen(<%= port %>, () => {
console.log("open server localhost:<%= port %>");
});
复制代码
3. 创建 package.json
创建 package.json 文件,实质是和创建 index.js 类似,都是采用动态生成模板的思路来实现,我们来看下核心方法 createPackageJsonTemplate 的实现代码:
// packageJsonTemplate.js
function createPackageJsonTemplate(config) {
const template = fs.readFileSync("./template/package.ejs", "utf-8");
const code = ejs.render(template, {
packageName: config.packageName,
router: config.middleware.router,
static: config.middleware.static,
});
return prettier.format(code, {
parser: "json",
});
}
复制代码
// template/package.ejs
{
"name": "<%= packageName %>",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"koa": "^2.13.1"
<% if (router) { %>
,"koa-router": "^10.1.1"
<% } %>
<% if (static) { %>
,"koa-static": "^5.0.0"
}
<% } %>
}
复制代码
4. 安装依赖
要自动安装依赖,我们可以使用 nodejs 的 execa 库执行 yarn 安装命令:
execa("yarn", {
cwd: getRootPath(),
stdio: [2, 2, 2],
});
复制代码
至此,我们已经用 nodejs 实现了新建项目的脚手架了。最后我们可以重新梳理下可优化点将其升级完善。比如将程序配置升级成 GUI 用户配置(用户通过手动选择或是输入来传入配置参数,例如项目名)。
编译构建
编译构建是什么?
构建,或者叫作编译,是前端工程化体系中功能最繁琐、最复杂的模块,承担着从源代码转化为宿主浏览器可执行的代码,其核心是资源的管理。前端的产出资源包括JS、CSS、HTML等,分别对应的源代码则是:
领先于浏览器实现的ECMAScript规范编写的JS代码(ES6/7/8...)。 LESS/SASS预编译语法编写的CSS代码。 Jade/EJS/Mustache等模板语法编写的HTML代码。
以上源代码是无法在浏览器环境下运行的,构建工作的核心便是将其转化为宿主可执行代码,分别对应:
ECMAScript规范的转译。 CSS预编译语法转译。 HTML模板渲染。
那么下面我们就一起学习下如今3大主流构建工具:Webpack、Rollup、Vite。
Webpack
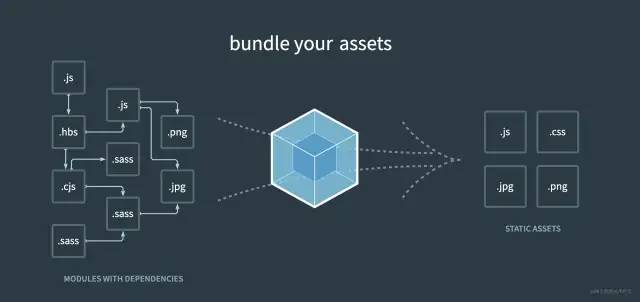
Webpack原理
想要真正用好 Webpack 编译构建工具,我们需要先来了解下它的工作原理。Webpack 编译项目的工作机制是,递归找出所有依赖模块,转换源码为浏览器可执行代码,并构建输出bundle。具体工作流程步骤如下:
初始化参数:取配置文件和shell脚本参数并合并 开始编译:用上一步得到的参数初始化 compiler对象,执行run方法开始编译确定入口:根据配置中的 entry,确定入口文件编译模块:从入口文件出发,递归遍历找出所有依赖模块的文件 完成模块编译:使用 loader转译所有模块,得到转译后的最终内容和依赖关系输出资源:根据入口和模块依赖关系,组装成一个个 chunk,加到输出列表输出完成:根据配置中的 output,确定输出路径和文件名,把文件内容写入输出目录(默认是dist)
Webpack实践
1. 基础配置
entry
入口配置,webpack 编译构建时能找到编译的入口文件,进而构建内部依赖图。
output
输出配置,告诉 webpack 在哪里输出它所创建的 bundle,以及如何命名这些文件。
loader
模块转换器,loader 可以处理浏览器无法直接运行的文件模块,转换为有效模块。比如:css-loader和style-loader处理样式;url-loader和file-loader处理图片。
plugin
插件,解决 loader 无法实现的问题,在 webpack 整个构建生命周期都可以扩展插件。比如:打包优化,资源管理,注入环境变量等。
下面是 webpack 基本配置的简单示例:
const path = require("path");
module.exports = {
mode: "development",
entry: "./src/index.js",
output: {
filename: "main.js",
path: path.resolve(__dirname, "dist"),
},
devServer: {
static: "./dist",
},
module: {
rules: [
{
// 匹配什么样子的文件
test: /\.css$/i,
// 使用loader , 从后到前执行
use: ["style-loader", "css-loader"],
}
],
},
};
复制代码
参考webpack官网:webpack.docschina.org/concepts/[3]
(注意:使用不同版本的 webpack 切换对应版本的文档哦)
2. 性能优化
编译速度优化
检测编译速度
寻找检测编译速度的工具,比如 speed-measure-webpack-plugin插件[4] ,用该插件分析每个loader和plugin执行耗时具体情况。
优化编译速度该怎么做呢?
减少搜索依赖的时间
配置 loader 匹配规则 test/include/exclue,缩小搜索范围,即可减少搜索时间
减少解析转换的时间
noParse配置,精准过滤不用解析的模块 loader性能消耗大的,开启多进程
减少构建输出的时间
压缩代码,开启多进程
合理使用缓存策略
babel-loader开启缓存 中间模块启用缓存,比如使用 hard-source-webpack-plugin 具体优化措施可参考:webpack性能优化的一段经历|项目复盘[5]
体积优化
检测包体积大小
寻找检测构建后包体积大小的工具,比如 webpack-bundle-analyzer插件[6] ,用该插件分析打包后生成Bundle的每个模块体积大小。
优化体积该怎么做呢?
bundle去除第三方依赖 擦除无用代码 Tree Shaking 具体优化措施参考:webpack性能优化的一段经历|项目复盘[7]
Rollup
Rollup概述
Rollup[8] 是一个 JavaScript 模块打包器,可以将小块代码编译成大块复杂的代码,例如 library 或应用程序。并且可以对代码模块使用新的标准化格式,比如CommonJS 和 es module。
Rollup原理
我们先来了解下 Rollup 原理,其主要工作机制是:
确定入口文件 使用 Acorn读取解析文件,获取抽象语法树 AST分析代码 生成代码,输出
Rollup 相对 Webpack 而言,打包出来的包会更加轻量化,更适用于类库打包,因为内置了 Tree Shaking 机制,在分析代码阶段就知晓哪些文件引入并未调用,打包时就会自动擦除未使用的代码。
Acorn 是一个 JavaScript 语法解析器,它将 JavaScript 字符串解析成语法抽象树 AST 如果想了解 AST 语法树可以点下这个网址astexplorer.net/[9]
Rollup实践
input
入口文件路径
output
输出文件、输出格式(amd/es6/iife/umd/cjs)、sourcemap启用等。
plugin
各种插件使用的配置
external
提取外部依赖
global
配置全局变量
下面是 Rollup 基础配置的简单示例:
import commonjs from "@rollup/plugin-commonjs";
import resolve from "@rollup/plugin-node-resolve";
// 解析json
import json from '@rollup/plugin-json'
// 压缩代码
import { terser } from 'rollup-plugin-terser';
export default {
input: "src/main.js",
output: [{
file: "dist/esmbundle.js",
format: "esm",
plugins: [terser()]
},{
file: "dist/cjsbundle.js",
format: "cjs",
}],
// commonjs 需要放到 transform 插件之前,
// 但是又个例外, 是需要放到 babel 之后的
plugins: [json(), resolve(), commonjs()],
external: ["vue"]
};
复制代码
Vite
Vite概述
Vite[10],相比 Webpack、Rollup 等工具,极大地改善了前端开发者的开发体验,编译速度极快。
Vite原理
为什么 Vite 开发编译速度极快?我们就先来探究下它的原理吧。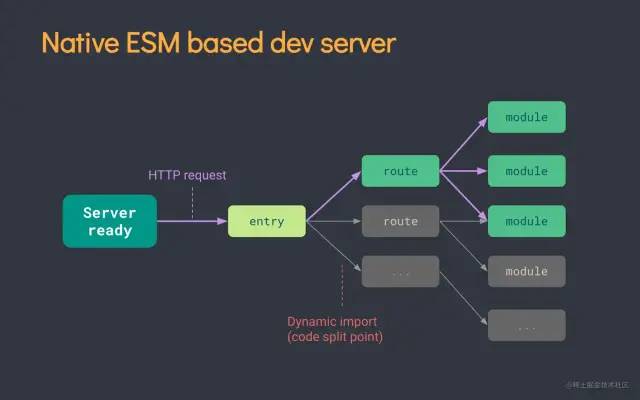 由上图可见,Vite 原理是利用现代主流浏览器支持原生的 ESM 规范,配合 server 做拦截,把代码编译成浏览器支持的。
由上图可见,Vite 原理是利用现代主流浏览器支持原生的 ESM 规范,配合 server 做拦截,把代码编译成浏览器支持的。
Vite实践体验
我们可以搭建一个Hello World版的Vite项目来感受下飞快的开发体验:
注意:Vite 需要 Node.js[11] 版本 >= 12.0.0。
使用 NPM:
$ npm init vite@latest
复制代码
使用 Yarn:
$ yarn create vite
复制代码
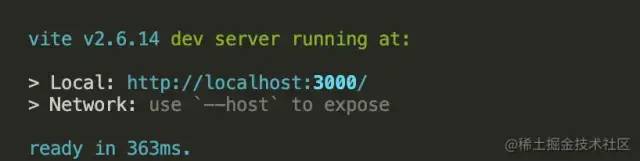 上图是Vite项目的编译时间,363ms,开发秒级编译的体验,真的是棒棒哒!
上图是Vite项目的编译时间,363ms,开发秒级编译的体验,真的是棒棒哒!
3种构建工具综合对比
| Webpack | Rollup | Vite | |
|---|---|---|---|
| 编译速度 | 一般 | 较快 | 最快 |
| HMR热更新 | 支持 | 需要额外引入插件 | 支持 |
| Tree Shaking | 需要额外配置 | 支持 | 支持 |
| 适用范围 | 项目打包 | 类库打包 | 不考虑兼容性的项目 |
测试
当我们前端项目越来越庞大时,开发迭代维护成本就会越来越高,数十个模块相互调用错综复杂,为了提高代码质量和可维护性,就需要写测试了。下面就给大家具体介绍下前端工程经常做的3类测试。
单元测试
单元测试,是对最小可测试单元(一般为单个函数、类或组件)进行检查和验证。
做单元测试的框架有很多,比如 Mocha[12]、断言库Chai[13]、Sinon[14]、Jest[15]等。我们可以先选择 jest 来学习,因为它集成了 Mocha,chai,jsdom,sinon 等功能。接下来,我们一起看看 jest 怎么写单元测试吧?
根据正确性写测试,即正确的输入应该有正常的结果。 根据错误性写测试,即错误的输入应该是错误的结果。
以验证求和函数为例:
// add函数
module.exports = (a,b) => {
return a+b;
}
复制代码
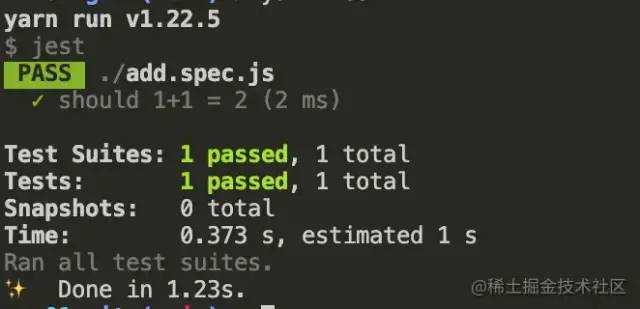
// 正确性测试验证
const add = require('./add.js');
test('should 1+1 = 2', ()=> {
// 准备测试数据 -> given
const a = 1;
const b = 1;
// 触发测试动作 -> when
const r = add(a,b);
// 验证 -> then
expect(r).toBe(2);
})
复制代码
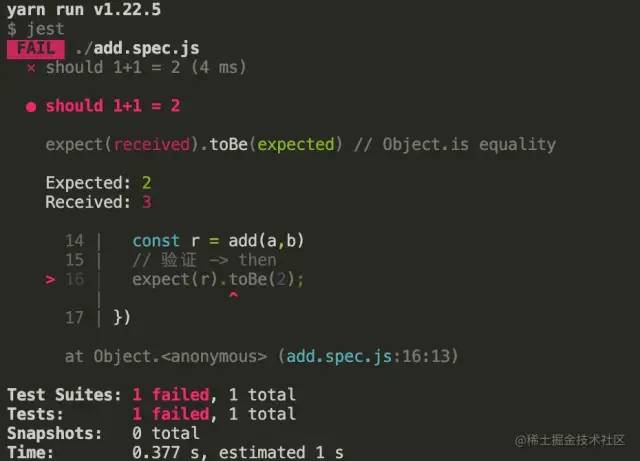
// 错误性测试验证
test('should 1+1 = 2', ()=> {
// 准备测试数据 -> given
const a = 1;
const b = 2;
// 触发测试动作 -> when
const r = add(a,b)
// 验证 -> then
expect(r).toBe(2);
})
复制代码
组件测试
组件测试,主要是针对某个组件功能进行测试,这就相对困难些,因为很多组件涉及了DOM操作。组件测试,我们可以借助组件测试框架来做,比如使用 Cypress[16](它可以做组件测试,也可以做 e2e 测试)。我们就先来看看组件测试怎么做?
以 vue3 组件测试为例:
我们先建好 `vue3` + `vite` 项目,编写测试组件再安装 `cypress` 环境在 `cypress/component` 编写组件测试脚本文件执行 `cypress open-ct` 命令,启动 `cypress component testing` 的服务运行 `xx.spec.js` 测试脚本,便能直观看到单个组件自动执行操作逻辑
// Button.vue 组件
Button测试
复制代码
// cypress/plugin/index.js 配置
const { startDevServer } = require('@cypress/vite-dev-server')
// eslint-disable-next-line no-unused-vars
module.exports = (on, config) => {
// `on` is used to hook into various events Cypress emits
// `config` is the resolved Cypress config
on('dev-server:start', (options) => {
const viteConfig = {
// import or inline your vite configuration from vite.config.js
}
return startDevServer({ options, viteConfig })
})
return config;
}
复制代码
// cypress/component/Button.spec.js Button组件测试脚本
import { mount } from "@cypress/vue";
import Button from "../../src/components/Button.vue";
describe("Button", () => {
it("should show button", () => {
// 挂载button
mount(Button);
cy.contains("Button");
});
});
复制代码
e2e测试
e2e 测试,也叫端到端测试,主要是模拟用户对页面进行一系列操作并验证其是否符合预期。我们同样也可以使用 cypress 来做 e2e 测试,具体怎么做呢?
以 todo list 功能验证为例:
我们先建好 `vue3` + `vite` 项目,编写测试组件再安装 `cypress` 环境在 `cypress/integration` 编写组件测试脚本文件执行 `cypress open` 命令,启动 `cypress` 的服务,选择 `xx.spec.js` 测试脚本,便能直观看到模拟用户的操作流程
// cypress/integration/todo.spec.js todo功能测试脚本
describe('example to-do app', () => {
beforeEach(() => {
cy.visit('https://example.cypress.io/todo')
})
it('displays two todo items by default', () => {
cy.get('.todo-list li').first().should('have.text', 'Pay electric bill')
cy.get('.todo-list li').last().should('have.text', 'Walk the dog')
})
it('can add new todo items', () => {
const newItem = 'Feed the cat'
cy.get('[data-test=new-todo]').type(`${newItem}{enter}`)
cy.get('.todo-list li')
.should('have.length', 3)
.last()
.should('have.text', newItem)
})
it('can check off an item as completed', () => {
cy.contains('Pay electric bill')
.parent()
.find('input[type=checkbox]')
.check()
cy.contains('Pay electric bill')
.parents('li')
.should('have.class', 'completed')
})
context('with a checked task', () => {
beforeEach(() => {
cy.contains('Pay electric bill')
.parent()
.find('input[type=checkbox]')
.check()
})
it('can filter for uncompleted tasks', () => {
cy.contains('Active').click()
cy.get('.todo-list li')
.should('have.length', 1)
.first()
.should('have.text', 'Walk the dog')
cy.contains('Pay electric bill').should('not.exist')
})
it('can filter for completed tasks', () => {
// We can perform similar steps as the test above to ensure
// that only completed tasks are shown
cy.contains('Completed').click()
cy.get('.todo-list li')
.should('have.length', 1)
.first()
.should('have.text', 'Pay electric bill')
cy.contains('Walk the dog').should('not.exist')
})
it('can delete all completed tasks', () => {
cy.contains('Clear completed').click()
cy.get('.todo-list li')
.should('have.length', 1)
.should('not.have.text', 'Pay electric bill')
cy.contains('Clear completed').should('not.exist')
})
})
})
复制代码总结
本文前言部分通过开发、构建、性能、测试、部署、规范六个方面,较全面地梳理了前端工程化的知识点,正文则主要介绍了在实践项目中落地使用的前端工程化核心技术点。
希望本文能够帮助到正在学前端工程化的小伙伴构建完整的知识图谱~
关于本文
来源:小铭子
https://juejin.cn/post/7033355647521554446