
【工程化】前端场景下 CI/CD 的探索与实践
在互联网行业,前端项目的迭代非常迅速,这对基础设施提出了非常高的要求,同时,前端项目的特殊性,也决定了它对基础设施的需求与后端及算法类项目有所不同。另一方面,业界基础技术也在不断向前进化,内外复杂的需求及背景交织下,我们也不断的探索适合自己的前端研发最佳实践,同时也将业界的优秀生态进行融合。
2019 年前后 DevOps 的理念已经瓜熟蒂落,形成了大体上通行的行业标准。根据 2019 Accelerate State of DevOps Report,高效的 DevOps 效能在各处落地。类似于 Gatsby 和 Zeit 等各种 Serverless 架构的前端生成、托管平台们也实现了普及,托管运维对前端的友好度和对能力的扩充都发展了很多。
在字节跳动,前端的 CI/CD 也已经非常便捷:我们可以在每次代码提交后执行预置的任务,比如代码风格及质量检查,安全检查,构建产物检测,部署到集成环境,对部署后的环境跑各种测试(兼容性测试,真机测试,性能测试等),产出各种检测报告;我们也可以在几分钟内快速完成版本的上线,回滚,切换等操作。
这些便利性有力的保障了字节跳动多个产品的快速迭代,为用户提供更为安全稳定的服务。
但是,时间往回退几年,那时的体验非常糟糕:开发完 feature 后,需要把 MR 链接发给同事,请他们帮忙 Code Review;接着再去编译平台发起编译;编译完成后,再去云平台发起测试上线或者小流量上线,验证没问题后再发起正式上线......整个过程非常依赖人工,流程的推进基本靠点对点沟通,费时且易出错,刀耕火种不过如此。
作为整个演进的亲历者,笔者试着结合自身的经历来阐述在字节跳动,前端的工程化变革是如何发生的。
前端部署
曾几何时我们的服务变更之所以严重依赖人工没有流程化,一个原因是基础设施没到位,很难做工程化;另一个原因是业务多,差异大,节奏快,导致没有时间和资源来沉淀最佳实践。早期刀耕火种的操作引发了各种线上事故后,痛定思痛,我们决定放慢产品的迭代,先解决工具的问题。需求是做不完的,但是如果没有好的工具和手段,已完成的需求有可能变成隐患。
我们组织了覆盖面非常广泛的调研,收集了各个业务团队的情况和痛点,调研中发现各个团队也有意识的在做一些工程化的建设。考虑到技术的通用性,我们成了项目组专门来解决前端的工程化问题。
首先需要解决的是部署问题。最开始,前端服务跟后端服务没有做区分,都是部署在字节跳动内部私有云上。行业里 Azure 和 Lambdas 等后端云巨头也刚刚步入验证和推广。在这个领域的前端,我们并没有明显的参考案例。事后发现当时即使最前卫的 zeit cloud 等 serverless 理念的践行者,也还在忙于推出基于镜像的无服务架构。但是前端服务跟后端服务有着本质区别。大部分前端项目(暂不考虑 BFF)都是静态资源的托管,不涉及到其他昂贵的计算资源,一个最简单的解决办法只需要一个 Nginx 就足够。但是云引擎需要考虑通用性,最开始的设计也是偏向后端的计算服务,所以服务的上线比较复杂,耗时也较长,完全不能满足前端业务快速上线的需求。
考虑在云引擎上单独搭建一个专门服务于前端的部署平台,最开始想到无非基于 nginx 来做。但是稍加发掘就会发现前端托管显然不是提供 HTTP 服务就足够的。后来我们考虑到需要实现比较复杂的路由匹配、小流量等逻辑,也需要兼顾可维护性,我们选择了基于 golang 实现这个服务。这个服务可以作为公共服务直接使用,考虑到某些业务的高访问量,也能够单独部署以免影响到其他业务的稳定性。
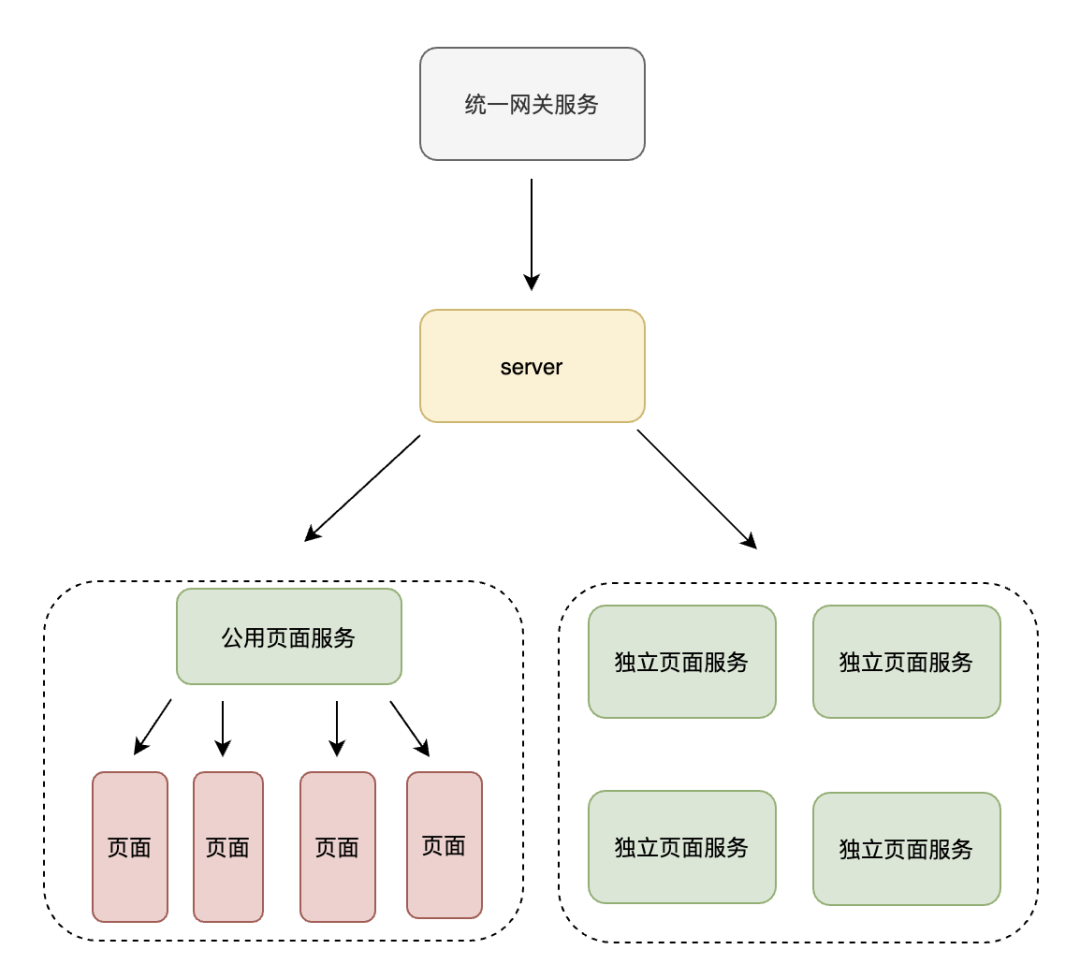
部署平台上线后,前端服务的上线时间由几分钟缩短到几秒钟,同时提供了小流量,路由管理,域名管理等功能,得到了各个业务线同事的深度使用。部署平台初期仅提供了静态页面的部署,后面又陆续增加了微前端部署、Node.js BFF 部署等功能。目前前端部署平台成为了公司内部前端方向最常用的基础服务之一。
流程化
部署问题解决了,每次上线还是需要在 gitlab 上完成合码,在编译平台完成打包,然后再在部署平台选择版本进行上线,整个流程仍然是割裂的,没有完成串联。在解决流程化的过程中,我们大概经历了两个阶段。恰逢在 DevOps 理念全面企业化的 2018 年前后,Jenkins 和 Gitlab runner 等工具快速普及,我们也根据自己的特长和行业演化引进和提出了覆盖全面的流程工具。
CLI 阶段
我们将研发活动抽象为不同的阶段(stage),比如CI 阶段,编译阶段,测试阶段,上线阶段等。然后将公司内部的基础服务按照 stage 进行划分,使得每个基础服务能够归属于某个 stage。
每个基础服务维护者不同,因此设计理念及接口都不一样,如果想要进行流程串联,应该具有相同的接口(interface),或者说设计一套接口规范,然后分别为每个服务开发一个适配器使得所有服务都能够被串联。我们将每个基础服务看做一个 job,每个 job 归属于一个确定的 stage。对于 job ,数据结构定义如下:
type job = string;
interface IJob {
name: job;
stage: IStage;
context: any;
}
多个 job 组成流水线(pipeline),流水线拥有所有的 stage,每个 stage 可能有 0 个或者多个 job,实际情况取决于用户如何组装流水线。pipeline 数据结构定义如下:
interface IPipeline {
[key: job]: IJob;
}
我们把流水线的组装完全交给用户来完成,期望提供更多的灵活性。因此开发了一个命令行工具,通过交互式的提问和回答来完成流水线的组装。这种形式比较类似前端领域常见的各种脚手架工具(比如 create-react-app, vue-cli 等),期望减少使用成本。
使用这个命令行工具时,用户需要配置触发器,选择需要串联的基础服务(job),为每个基础服务配置必要的上下文信息(context),如此一条流水线就组装完成了。

代码提交时会产生 git 事件,进而通知到触发器,流水线会按照前述 stage 定义的顺序运行配置好的 job。
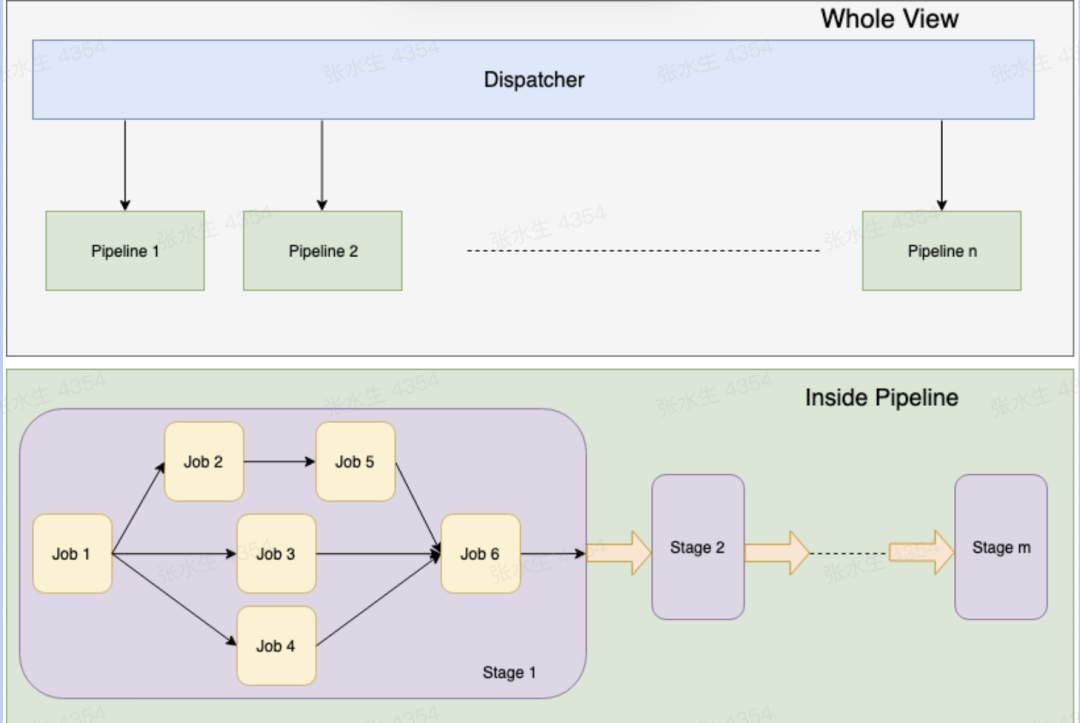
使用这个工具,可以将代码管理,编译服务,准入测试,部署等各个服务进行串联,减少了不必要的平台切换,大大提高了研发效率。
与此同时前端云已经逐步开始进入了 Serverless 的阶段,Vercel 和 Netlify 等新兴的开发模式层出不穷,我们内部的前端云也逐步积累了一定时间的经验。上述研发工具推出一段时间后,我们又组织了大规模的用户回访,收集了各个团队的使用情况。一方面,大家肯定了这个产品的努力,能确实解决业务团队的问题,另一方面,也提了很多建议。结合我们的调查积累与用研,我们根据反馈总结了接下来要重点解决的几个问题:
CLI 形式使用及信息展示不太方便,要提供 GUI 界面,降低使用门槛。 对于团队内部来说,流水线要能够复用,进一步沉淀最佳实践。 提供更多的质量工具,管控上线流程,提高上线质量。
GUI 阶段
前述方案在实际应用中遇到的问题,究其原因,类似 Lambda SAM 这类适配完全 Serverless 理念的开发模式,对流程与研发工具的整合提出了更高的要求,正如 DevOps 文化所推崇的研发与运维在方方面面都已经融合和重叠。为适应这个阶段我们逐步推出了更多更超前的发展策略。
我们调研了各种 DAG 的工作流引擎,同一时期公司内有团队自研了一套兼容 ASL 的流程引擎。沟通后觉得可以满足需求,因此决定基于这套流程引擎来打造全新的服务来解决前述回访收集的问题。
我们开发了全新的部署平台,使用自研的兼容 ASL 的流程引擎来驱动任务的进行。提供了易用的界面来编排流水线,用户可以在平台上直接拖拽完成流水线的组装。
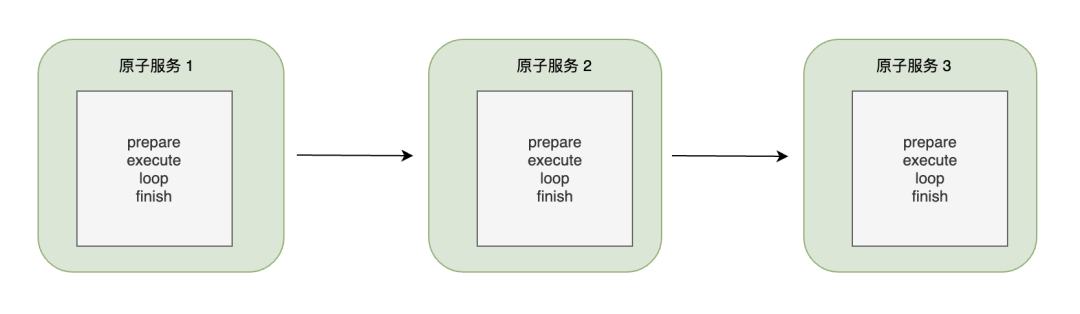
我们将各项基础服务抽象为原子服务,为原子服务定义了统一的规范和接口。对于一个原子服务来说,需要对外暴露四个生命周期函数,准备函数(prepare),执行函数(execute),轮询函数(loop),结束函数(finish)。对于一条流水线来说,平台会按照流水线的编排调用各个原子服务,只有前面的原子服务成功才能继续执行后续的原子服务;对于原子服务来说,平台会按照顺序依次调用这个四个函数,只有前一个函数成功才能继续调用后一个函数。
有了这样一个平台后,我们的主要任务是提供更多更优质的原子服务。最有效的手段当然是建立一个开发规范,让开发者自己去开发适合业务的原子服务,因此我们开发了原子服务开放平台。对于有需求的开发者来说,他可以在这个平台注册自己的原子服务,填入生命周期的 webhook,平台会自动生成符合规范的原子服务,然后就可以在流水线中使用了。
后来我们注意到 GitHub 推出了 GitHub Actions 服务,GitHub 里的工作流程叫做 workflow ,每个 workflow 由一个或者多个 job 组成,每个 job 有多个 step 构成,每个 step 依次执行一个或者多个 action。可以看到大家的理念非常相似,我们的流水线也是由多个 job 组成,每个 job 有固定的生命周期,每个生命周期函数可以进行自定义的操作。
前端研发平台
发展到最近,DevOps 理念对于行业内普遍的认知,已经逐步转为更完善的 SRE 观念了。我们探索的努力也一刻没有停歇,开始发展更融合、成体系并且更开放生态的稳定性建设。
前面提到的前端云部署平台解决了流程串联,项目部署等问题,同时也具备开放能力,开发者可以结合业务实际开发自己的原子服务补充平台缺失的能力,这样就够了吗?我们在思考这个问题。
随着前端项目的复杂性不断增加,前端研发活动涉及到的环节也越来越多,仅仅解决部署及流程化的问题并不够,一个完整的平台需要解决研发活动从立项,到需求管理,开发,测试,集成,构建,发布,验证,监控等各个环节的问题。因此建设这样一个覆盖项目全生命周期的研发平台势在必行。
需要解决的问题虽然很多,但是并不需要全部从零开始开发。字节跳动内部有很多基础服务,比如有不同的脚手架工具,多个接口管理平台,也有横跨 app 及 web 端的打点监控服务,不同的 Low-Code/No-Code 平台等等。我们需要设计统一的规范将不同的平台进行整合和打通,最终能够在一个统一的平台上为开发者提供服务。
正如一开始我们给这个项目起的代号“宇宙大系统”一样,前端研发平台期望做成一个兼具深度和广度,面向前端,信息聚焦,服务收敛的一站式开发平台。这个平台的建设还处于活跃的迭代期,欢迎有兴趣的同学来一起建设。
总结
互联网业务的快速发展催生了 DevOps,DevOps 能够推进业务的快速迭代,但是当业务发展到一定程度时更需要关心业务的稳定性和扩展性,而这是 SRE 更关心的。我们从最开始的前端部署工程化,到前端 CI/CD 流程化,最后到前端研发平台,实际上也是契合了从 DevOps 向 SRE 的推进之路,希望我们分享的经验能够对大家有所启发。
延伸阅读
2018: The Year Of Enterprise DevOps https://go.forrester.com/blogs/2018-the-year-of-enterprise-devops/ 2018 in Review: A year of innovation https://www.jenkins.io/blog/2018/12/25/year-in-review/ The 2019 Accelerate State of DevOps https://cloud.google.com/blog/products/devops-sre/the-2019-accelerate-state-of-devops-elite-performance-productivity-and-scaling How to autoscale continuous deployment with GitLab Runner on DigitalOcean https://about.gitlab.com/blog/2018/06/19/autoscale-continuous-deployment-gitlab-runner-digital-ocean/ Serverless computing wars: AWS Lambdas vs Azure Functions https://hub.packtpub.com/serverless-computing-aws-lambdas-azure-functions/ What is the AWS Serverless Application Model (AWS SAM)? https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/what-is-sam.html Application delivery network https://en.wikipedia.org/wiki/Application_delivery_network Love DevOps? Wait until you meet SRE https://www.atlassian.com/incident-management/devops/sre gatsbyjs.com http://gatsbyjs.com/ vercel.com https://vercel.com/