
Python 美国警察枪击案EDA分析

2014年在密苏里州一名叫做弗格森(Ferguson)的警察杀害了迈克尔·布朗(Michael Brown)后,美国开始了一场抗议警察暴力对待黑人的运动—Black Lives Matter(黑人的命也是命,简称BLM)。
2020年,在明尼阿波利斯警察Derek Chauvin杀害乔治·弗洛伊德(George Floyd)之后,BLM运动再次成为头条新闻,引起国际社会的进一步关注。
自2015年1月1日起,《华盛顿邮报》一直在整理一个数据库,其中记录了值班警员在美国发生的每起致命枪击事件。这个数据库里包含了死者的种族,年龄和性别,该人是否有武器,以及受害人是否正在遭受精神健康危机。
下面就让我们来使用这个数据集来进行数据分析。
1.准备
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
此外,推荐大家用VSCode编辑器,因为它可以在编辑器下方的终端运行命令安装依赖模块:Python 编程的最好搭档—VSCode 详细指南。
本文具备流程性,建议使用 VSCode 的 Jupiter Notebook 扩展,新建一个名为 test.ipynb 的文件,跟着教程一步步走下去。
Windows环境下打开 Cmd (开始-运行-CMD),苹果系统环境下请打开 Terminal (command+空格输入Terminal),输入命令安装依赖:
所需依赖:
pip install numpy
pip install pandas
pip install plotly
pip install seaborn本文译自:https://www.kaggle.com/edoardo10/fatal-police-shooting-eda-plotly-seaborn/data,如需数据请在公众号后台回复:警察枪击EDA。
2.代码与分析
首先,引入我们分析所需要使用的模块:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from datetime import datetime
import plotly.express as px
import plotly.graph_objects as go
import warnings
import plotly.offline as pyo
pyo.init_notebook_mode()
warnings.filterwarnings('ignore')
pd.set_option('display.max_columns', 500)
sns.set_style('white')
%matplotlib inline打开需要分析的数据集:
df = pd.read_csv('./PoliceKillingsUS.csv', encoding='cp1252')
df.head()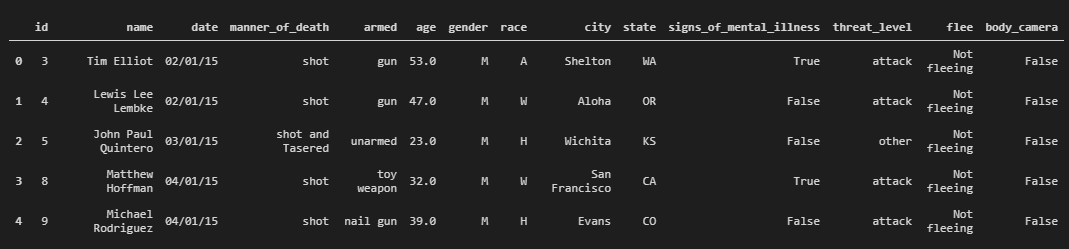
时间特征
从这6年的月度数据来看,我们可以看到,在2015年上半年、2018年初和2020年第一季度,我们达到了每月超过100起致命事故的高峰。从月度来看,这种现象不具备明显的季节性。
df['date'] = df['date'].apply(lambda x: pd.to_datetime(x))
df['date'].groupby(df.date.dt.to_period('M')).count().plot(kind='line')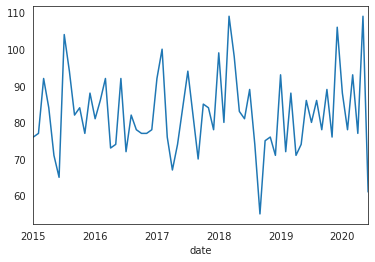
看看警察枪击案的事故是否具有周末特征:
count = df['date'].apply(lambda x: 'Weekday' if x.dayofweek < 5 else 'Weekend').value_counts(normalize=True)
f, ax = plt.subplots(1,1)
sns.barplot(x=count.index, y=count.values, ax=ax, palette='twilight')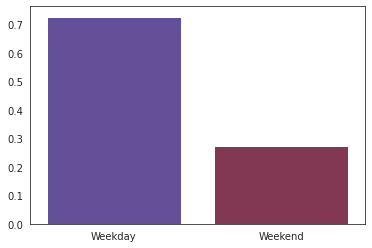
显然,我们没有证据表明周末会发生更多的案件。
不过,如果细化到星期里的每一天,我们会发现周中发生案件的概率较高:
count = df['date'].apply(lambda x: x.dayofweek).value_counts(normalize=True).sort_index()
count.index = ['Mon','Tue','Wed','Thu','Fri','Sat','Sun']
f, ax = plt.subplots(1,1)
sns.barplot(x=count.index, y=count.values, ax=ax, palette='twilight')
ax.set_title('Cases (%) for each day of the week');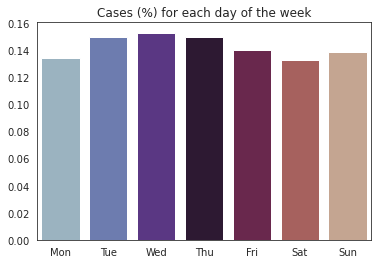
接下来看看以下4个特征的分布:
signs_of_mental_illness:是否精神不稳定
threat_level:威胁等级
body_camera:警察是否带了随身摄像头
manner_of_death:死亡方式
count_1 = df['signs_of_mental_illness'].value_counts(normalize=True)
count_2 = df['threat_level'].value_counts(normalize=True)
count_3 = df['body_camera'].value_counts(normalize=True)
count_4 = df['manner_of_death'].value_counts(normalize=True)
fig, axes = plt.subplots(2, 2, figsize=(8, 8), sharey=True)
sns.barplot(x=count_1.index, y=count_1.values, palette="rocket", ax=axes[0,0])
axes[0,0].set_title('Signs of mental illness (%)')
sns.barplot(x=count_2.index, y=count_2.values, palette="viridis", ax=axes[0,1])
axes[0,1].set_title('Threat level (%)')
sns.barplot(x=count_3.index, y=count_3.values, palette="nipy_spectral", ax=axes[1,0])
axes[1,0].set_title('Body camera (%)')
sns.barplot(x=count_4.index, y=count_4.values, palette="gist_heat", ax=axes[1,1])
axes[1,1].set_title('Manner of death (%)');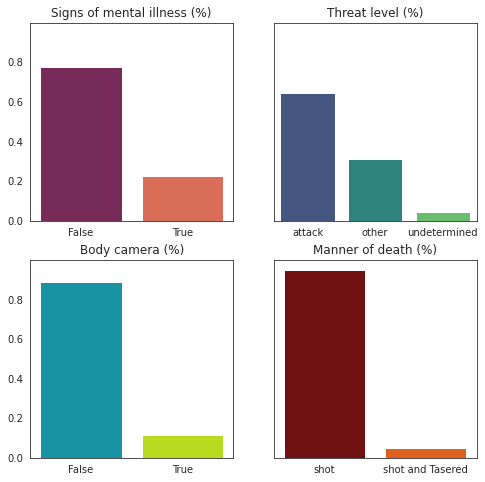
我们可以看到,只有20%的案例受害者有精神不稳定的迹象;
只有10%的警察有随身摄像头;
70%的情况被宣布为危险状况;
死亡方式似乎不是一个有趣的变量,因为大多数案件都是“枪毙”;
美国的警察是否具有种族主义倾向?
count = df.race.value_counts(normalize=True)
count.index = ['White', 'Black', 'Hispanic', 'Asian', 'Native American', 'Other']
f, ax = plt.subplots(1,1, figsize=(8,6))
sns.barplot(y=count.index, x=count.values, palette='Reds_r')
ax.set_title('Total cases for each race (%)');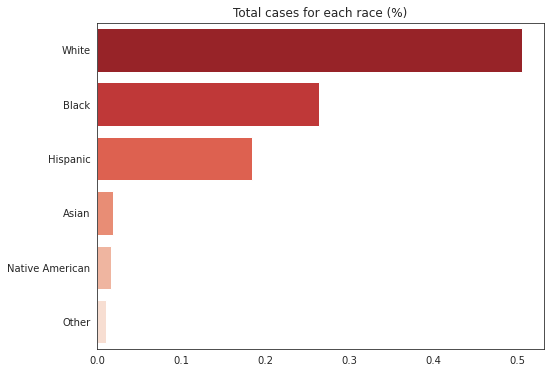
从上图我们知道,大部分致命的枪击事件中,涉及最多的是白人,其次是黑人和西班牙裔。
但这个图表并没有考虑人种比例。参考2019年美国的种族比例,我们可以看到,美国黑人受害者的比例更高:
数据来源:
https://data.census.gov/cedsci/table?q=Hispanic%20or%20Latino&tid=ACSDP1Y2019.DP05&hidePreview=false
share_race_usa_2019 = pd.Series([60.0, 12.4, 0.9, 5.6, 18.4, 2.7], index=['White','Black','Native American','Asian','Hispanic','Other'])
count_races = count / share_race_usa_2019
count_races = count_races.sort_values(ascending=False)
f, ax = plt.subplots(1,1, figsize=(8,6))
sns.barplot(y=count_races.index, x=count_races.values, palette='Greens_r')
ax.set_title('Total cases for each race on total USA race percentage rate');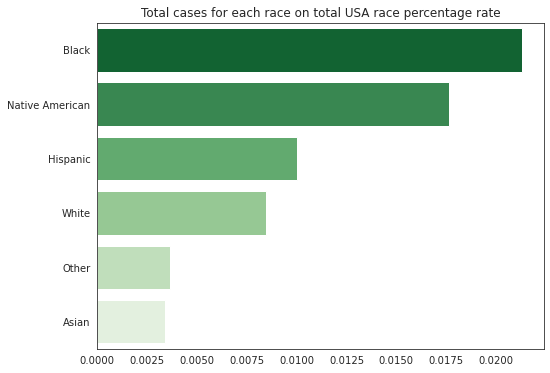
受害者的年龄
接下来看看受害者年龄的分布密度图:
sns.set_style('whitegrid')
fig, axes = plt.subplots(1, 1, figsize=(10, 8))
axes.xaxis.set_ticks(np.arange(0,100,10))
sns.kdeplot(df[df.race == 'N'].age, ax=axes, shade=True, color='#7FFFD4')
sns.kdeplot(df[df.race == 'O'].age, ax=axes, shade=True, color='#40E0D0')
sns.kdeplot(df[df.race == 'B'].age, ax=axes, shade=True, color='#00CED1')
sns.kdeplot(df[df.race == 'H'].age, ax=axes, shade=True, color='#6495ED')
sns.kdeplot(df[df.race == 'A'].age, ax=axes, shade=True, color='#4682B4')
sns.kdeplot(df[df.race == 'W'].age, ax=axes, shade=True, color='#008B8B')
legend = axes.legend_
legend.set_title("Race")
for t, l in zip(legend.texts,("Native", "Other", 'Black', 'Hispanic', 'Asian', 'White')):
t.set_text(l)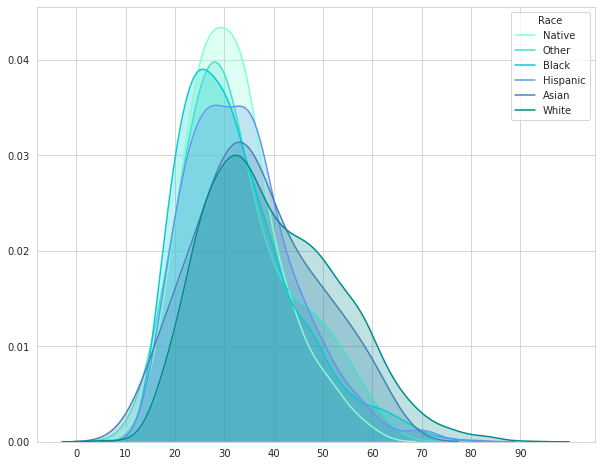
由这些叠加的密度图可以看出:
对于亚裔和白人来说,大多数案件的受害者年龄都在30岁左右。
对于其他和印第安人来说,在大多数案件中,受害者大约28岁。
对于西班牙裔和黑人来说,大多数案件的受害者年龄都在25岁左右。
所以我们可以说,西班牙裔和黑人的年轻人,是被警察开枪射击的高危群体。
受害者性别比例
按常理,这种暴力事件的受害者一般都为男性,看看是不是这样:
fig = px.pie(values = df.gender.value_counts(normalize=True).values, names=df.gender.value_counts(normalize=True).index, title='Total cases gender (%)')
fig.update(layout=dict(title=dict(x=0.5),autosize=False, width=400, height=400))
fig.show()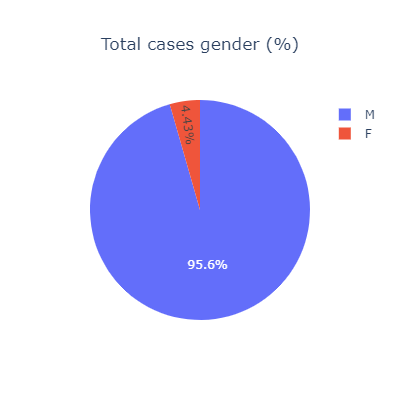
果然如此,超过95%的受害者都为男性。
简单的EDA分析就是这些,除此之外,作者还分享了许多深层次的分析,不过并没有将数据分享出来,这里就不展示了。
我们的文章到此就结束啦,如果你喜欢今天的Python 实战教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应红字验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
点击下方阅读原文可获得更好的阅读体验
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典