
Doc2Vec 是一种无监督算法,可从可变长度的文本片段(例如句子、段落和文档)中学习嵌入。它最初出现在 Distributed Representations of Sentences and Documents 一文中。Word2Vec
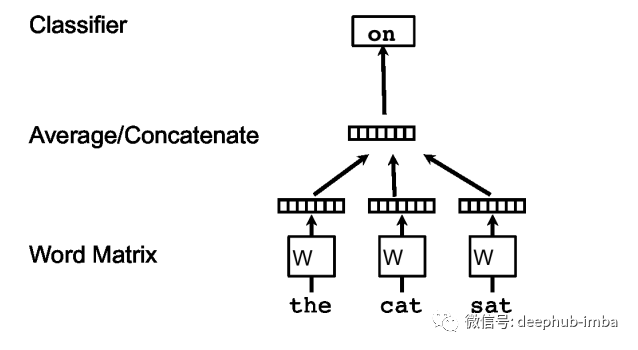
让我们先回顾一下 Word2Vec,因为它为 Doc2Vec 算法提供了灵感。Word2Vec 的连续词袋架构。图片来自论文 Distributed Representations of Sentences and Documents。
Word2Vec 通过使用上下文中的其他单词预测句子中的单词来学习单词向量。在这个框架中,每个词都映射到一个唯一的向量,由矩阵 W 中的一列表示。向量的串联或总和被用作预测句子中下一个词的特征。使用随机梯度下降训练词向量。训练收敛后,将意思相近的词映射到向量空间中相近的位置。所呈现的架构称为连续词袋 (CBOW) Word2Vec。还有一种称为 Skip-gram Word2Vec 的架构,其中通过从单个单词预测上下文来学习单词向量。Doc2Vec
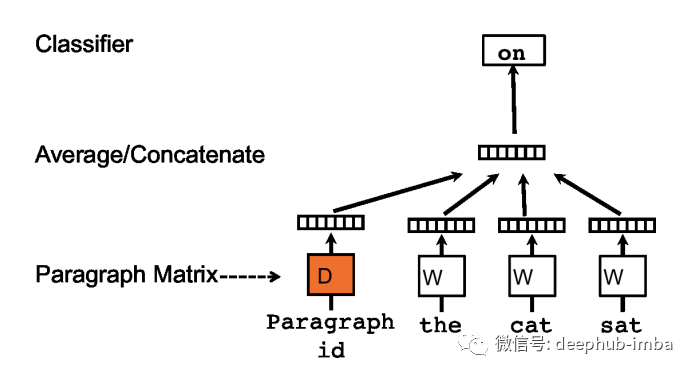
来自论文 Distributed Representations of Sentences and Documents 的 Doc2Vec 的分布式内存模型。
我们现在将看到如何学习段落的嵌入,但同样的方法也可用于学习整个文档的嵌入。在Doc2Vec中,训练集中的每个段落都映射到一个唯一的向量,用矩阵D中的一列表示,每个词也映射到一个唯一的向量,用矩阵W中的一列表示。段落向量和词向量分别为平均或连接以预测上下文中的下一个单词。段落向量在从同一段落生成的所有上下文中共享,但不会跨段落共享。词向量矩阵 W 是跨段落共享的。段落标记可以被认为是另一个词。它充当记忆,记住当前上下文中缺少的内容。所以这个模型被称为分布式内存 (DM) Doc2Vec。还有第二种架构称为分布式词袋 (DBOW) Doc2Vec,其灵感来自 Skip-gram Word2Vec。在预测时,需要通过梯度下降获得新段落的段落向量,保持模型其余部分的参数固定。
 下载APP
下载APP