
Redis系列(二): 连集合底层实现原理都不知道,你敢说Redis用的很溜?
★一枚用心坚持写原创的“无趣”程序猿,在自身受益的同时也让朋友们在技术上有所提升。
目录
SDS 的设计到底有多牛逼。 List、Set、Sorted Set、Hash 底层实现原理
SDS 的设计到底有多牛逼
Redis 使用 C 语言编写,但是并没有直接使用 C 语言自带的字符串,而是使用了 SDS 来管理字符串。接下来就来探讨下为什么 Redis 使用了 SDS 来管理字符串。
SDS 全称 Simple Dynamic String,即简单动态字符串。SDS 组成部分如下:
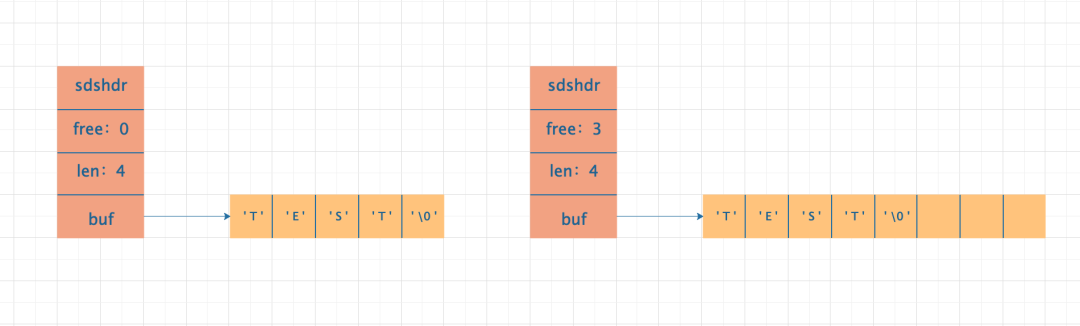
free:表示 buf 中的空闲的空间大小,图左空闲空间为 0,图右空闲空间为 3 len:表示 buf 中的内容长度,注意 len 的长度不包括 ' \0 '(字符串以\0 结尾是为了使用 C 语言中现成的库函数,而不需要重新造轮子) buf:一个 char 类型的数组,用于存储实际字符串的内容。
SDS 的优势
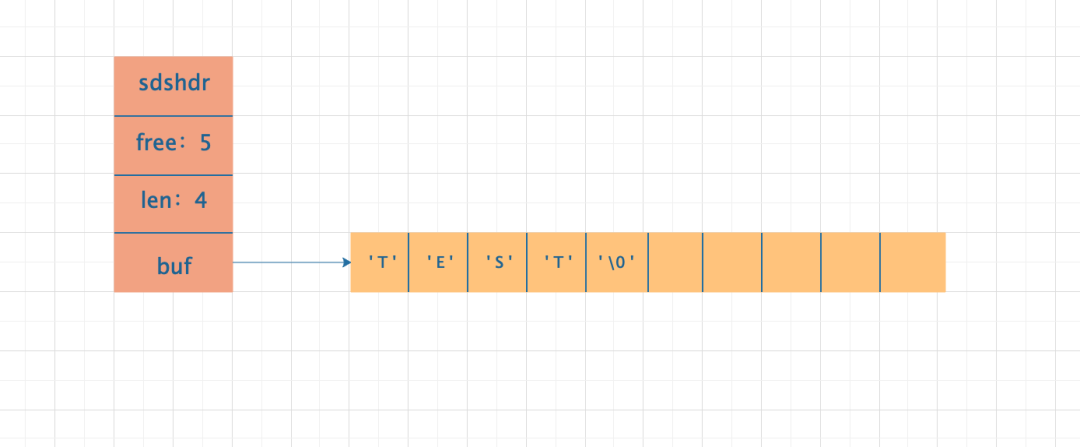
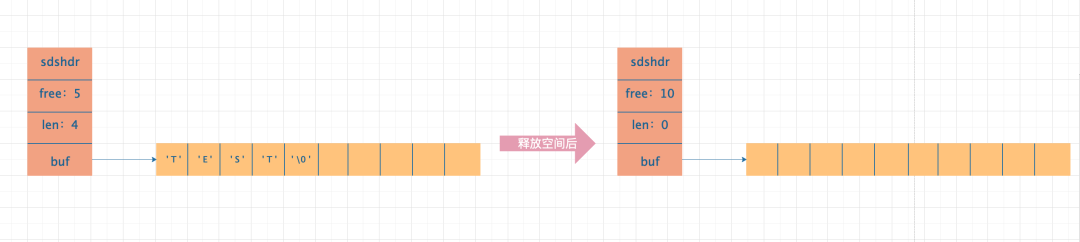
获取字符串长度的复杂度为 O(1);直接可通过 len 属性获得字符串的长度。 防止 buf 存储内容溢出的问题;每次增加字符串的长度的时候先检查 free 属性是否能存下要增加的字符串的长度,如果不够,则先对 buf 数组扩容,然后在将内容存入 buf 数组中。 空间预分配&空间惰性释放;SDS 会预先分配一部分空闲空间,当字符串内容添加时不需要做空间申请的工作,当字符串从 buf 数组中移除时,空闲出来的空间不会立马被内存回收,防止新增字符串的内容写入时空间不够而临时申请空间。
二级制安全性;由于字符串是存储在 char 类型的数组中,即内容是以二进制的形式存储的,所以 SDS 可以存储任何类型的二进制数据,同时也不需要担心数据格式转换的问题。
List 的实现原理
在 Redis3.2 之前,List 底层采用了 ZipList 和 LinkedList 实现的,在 3.2 之后,List 底层采用了 QuickList。
Redis3.2 之前,初始化的 List 使用的 ZipList,List 满足以下两个条件时则一直使用 ZipList 作为底层实现,当以下两个条件任一一个不满足时,则会被转换成 LinkedList。
List 中存储的每个元素的长度小于 64byte 元素个数小于 512
ZipList方式 的实现原理
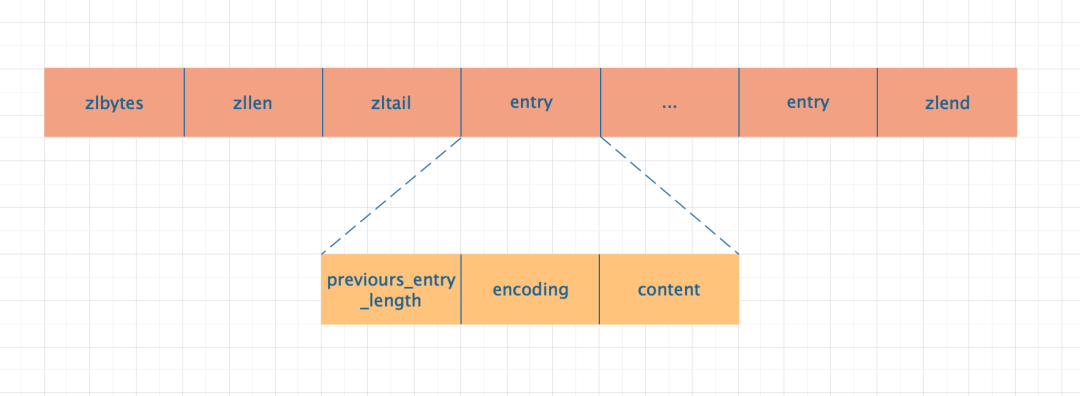
ZipList 是由一块连续的存储空间组成,从图中可以看出 ZipList 没有前后指针。
各部分作用说明:
zlbytes:表示当前 list 的存储元素的总长度。
zllen:表示当前 list 存储的元素的个数。
zltail:表示当前 list 的头结点的地址,通过 zltail 就是可以实现 list 的遍历。
zlend:表示当前 list 的结束标识。
entry:表示存储实际数据的节点,每个 entry 代表一个元素。
previours_entry_length: 表示当前节点元素的长度,通过其长度可以计算出下一个元素的位置。 encoding:表示元素的编码格式。 content:表示实际存储的元素内容。
ZipList 的优缺点比较
优点:内存地址连续,省去了每个元素的头尾节点指针占用的内存。 缺点:对于删除和插入操作比较可能会触发连锁更新反应,比如在 list 中间插入删除一个元素时,在插入或删除位置后面的元素可能都需要发生相应的移动操作。
LinkedList方式 的实现原理
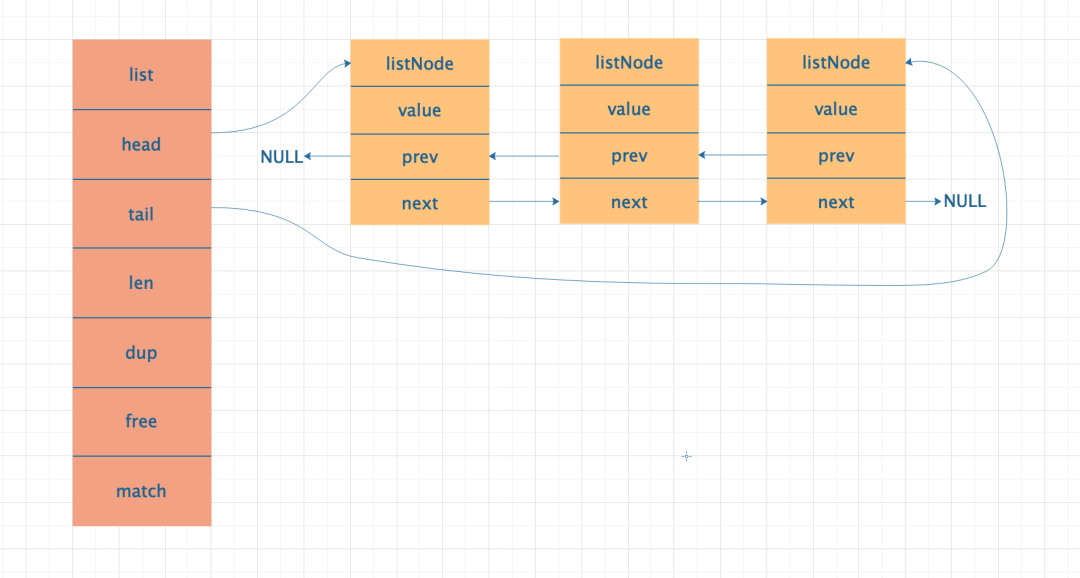
LinkedList 都比较熟悉了,是由一系列不连续的内存块通过指针连接起来的双向链表。
各部分作用说明:
head:表示 List 的头结点;通过其可以找到 List 的头节点。 tail:表示 List 的尾节点;通过其可以找到 List 的尾节点。 len:表示 List 存储的元素个数。 dup:表示用于复制元素的函数。 free:表示用于释放元素的函数。 match:表示用于对比元素的函数。
QuickList方式 的实现原理
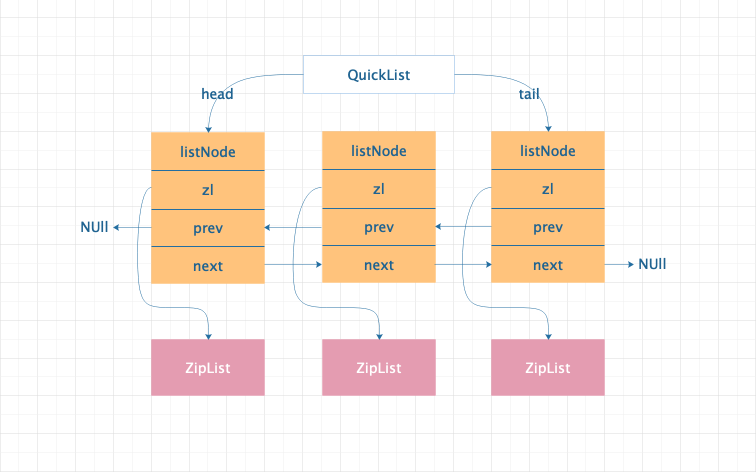
在 Redis3.2 版本之后,Redis 集合采用了 QuickList 作为 List 的底层实现,QuickList 其实就是结合了 ZipList 和 LinkedList 的优点设计出来的。
各部分作用说明:
每个 listNode 存储一个指向 ZipList 的指针,ZipList 用来真正存储元素的数据。 ZipList 中存储的元素数据总大小超过 8kb(默认大小,通过 list-max-ziplist-size 参数可以进行配置)的时候,就会重新创建出来一个 ListNode 和 ZipList,然后将其通过指针关联起来。
Set 的实现原理
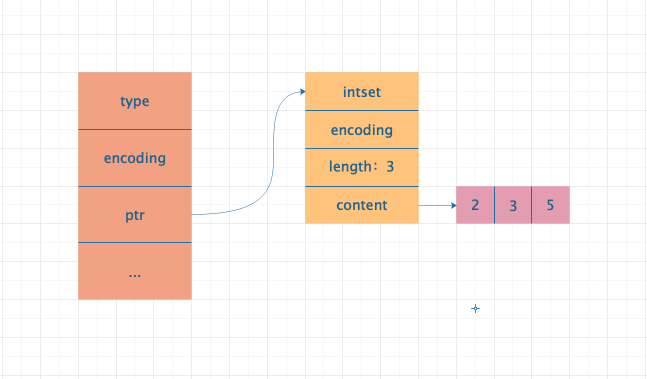
Set 集合采用了整数集合和字典两种方式来实现的,当满足如下两个条件的时候,采用整数集合实现;一旦有一个条件不满足时则采用字典来实现。
Set 集合中的所有元素都为整数 Set 集合中的元素个数不大于 512(默认 512,可以通过修改 set-max-intset-entries 配置调整集合大小)
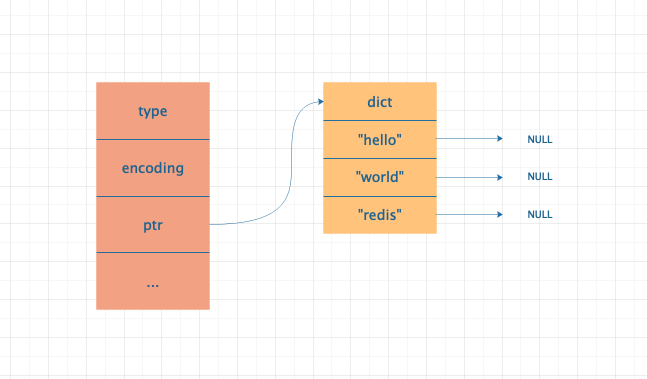
Zset 的实现原理
Zset 底层同样采用了两种方式来实现,分别是 ZipList 和 SkipList。当同时满足以下两个条件时,采用 ZipList 实现;反之采用 SkipList 实现。
Zset 中保存的元素个数小于 128。(通过修改 zset-max-ziplist-entries 配置来修改) Zset 中保存的所有元素长度小于 64byte。(通过修改 zset-max-ziplist-values 配置来修改)
采用 ZipList 的实现原理

和 List 的底层实现有些相似,对于 Zset 不同的是,其存储是以键值对的方式依次排列,键存储的是实际 value,值存储的是 value 对应的分值。
采用 SkipList 的实现原理
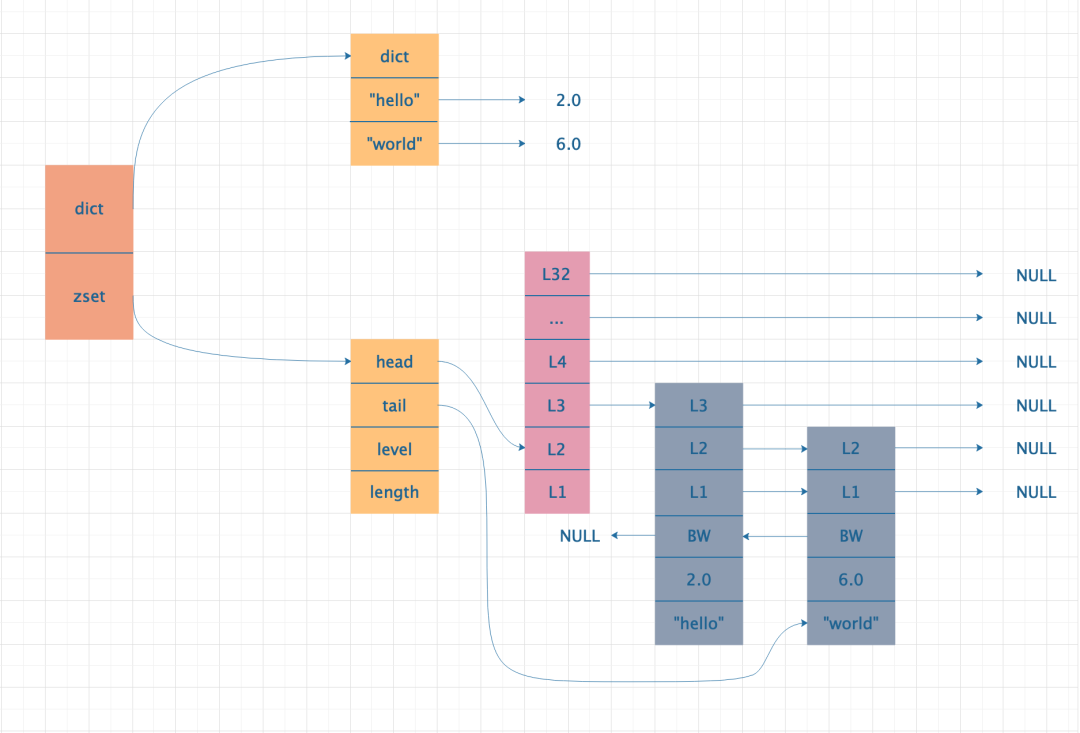
SkipList 分为两部分,dict 部分是由字典实现,Zset 部分使用跳跃表实现,从图中可以看出,dict 和跳跃表都存储的数据,实际上 dict 和跳跃表最终使用指针都指向了同一份数据,即数据是被两部分共享的,为了方便表达将同一份数据展示在两个地方。
关于跳跃表和字典的具体实现,此处不详细介绍,想深入了解的朋友自行上网查阅。
Hash 的实现原理。
Hash 底层实现采用了 ZipList 和 HashTable 两种实现方式,相信看到这里大家都比较轻车熟路了,下面来看看。Hash 结构当同时满足如下两个条件时底层采用了 ZipList 实现,一旦有一个条件不满足时,就会被转码为 HashTable 进行存储。
Hash 中存储的所有元素的 key 和 value 的长度都小于 64byte。(通过修改 hash-max-ziplist-value 配置调节大小) Hash 中存储的元素个数小于 512。(通过修改 hash-max-ziplist-entries 配置调节大小)
ZipList方式 的实现原理

从图上看是不是很熟悉,其实和 Zset 的 ZipList 的实现逻辑几乎相同,就不多介绍了。
HashTable方式 的实现原理
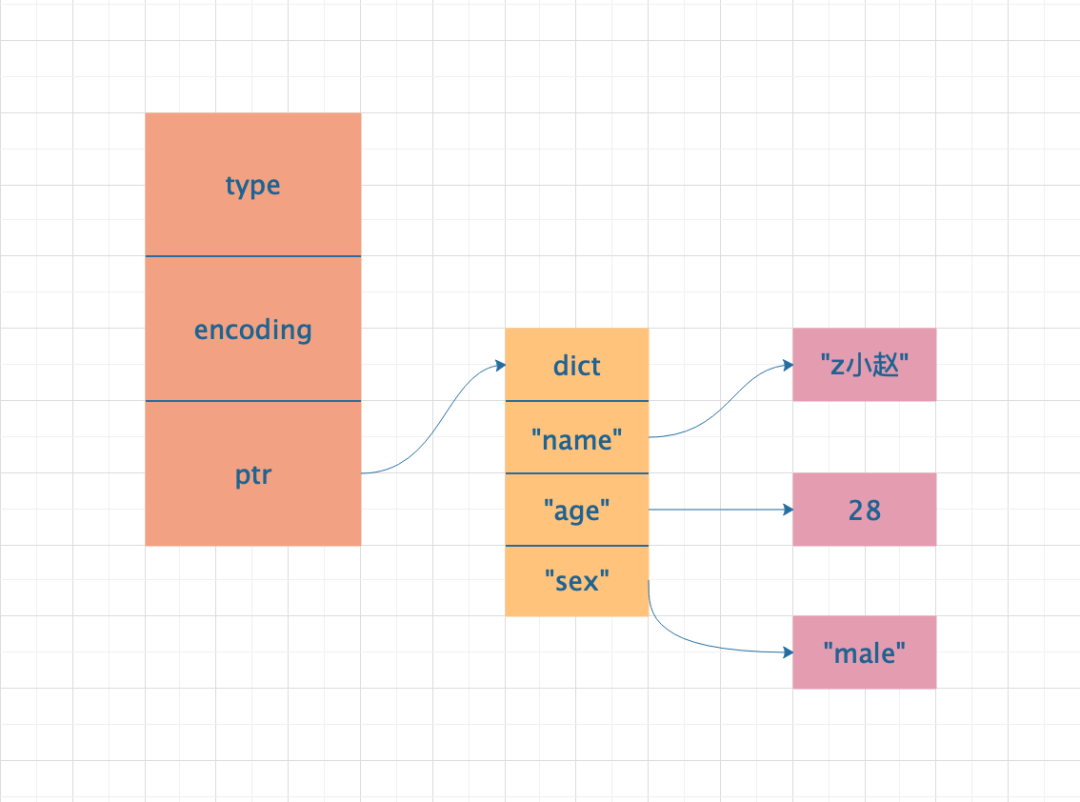
HashTable 实现底层采用了字段的方式实现,其中键存储的内容为 field,值存储的是 value 值。
总结
本文主要介绍了 5 种基础常用集合的底层实现原理,相信大家看完之后,在业务开发时对集合选用,同时结合业务使用的命令更加有自己的理解。
下篇文章我们来介绍 Redis 数据过期策略、AOF 及 RDB 文件等内容,尽情期待。