
别再生成测试代码了!
业内有各种做接口测试的工具/平台,例如 Postman, Swagger, YApi, Rap 等,商业的和开源的都很多,用它们做接口测试普遍都要写 JavaScript 或 Python 脚本代码,对应的开发和维护工作量都很大。
也有 Eolinker 这种商业工具,号称不用写代码,其实就是把一堆的代码变成一屏一屏的表单。先加一项,左侧填一下 key 的路径,中间选一下大于等于或者 IN 等匹配方式,右侧再填一下对比的值。
但这种点点选选填填的过程只是降低了学习成本,并没有降低开发和维护成本,甚至可能因为表达能力不够反而增加了成本,往往对于一个熟悉代码的测试工程师来说还不如写 if-else 代码,写代码反而更快速和灵活。
关于这个测试的开发和维护成本高,业内一个普遍的做法是生成测试用例代码。
但生成代码其实是有很多的问题
第一是不够精准,不能直接生成一个完整的符合自己业务需求的测试用例代码,至少要把用来对比的期望值改掉才能用;
第二是逻辑固化,一旦要测的某个接口,后端因为需求变更等原因改了参数定义或内部实现,那对应的测试用例代码也要去进行相应的修改,不然跑测试用例不通过,但其实接口又没有问题,只是需求变化导致用例失效;
第三是基本只有第一次能用,就是说当你要测的一个接口还没有测试用例代码的时候,可以生成代码然后在它的基础上进行修改。但如果已经有了测试用例代码,现在是接口变了要跟着去改测试代码,一般有两种做法:直接修改和重新生成。如果重新生成代码,它又不能给你生成最终你要的逻辑,你还是得在它基础上进行二次开发,这又是个比较麻烦的过程。很多时候接口就加了或改了一两个字段,那还不如在原来基础上改还更快一点,所以基本上生成代码只有第一次才用,后面用的就很少了;
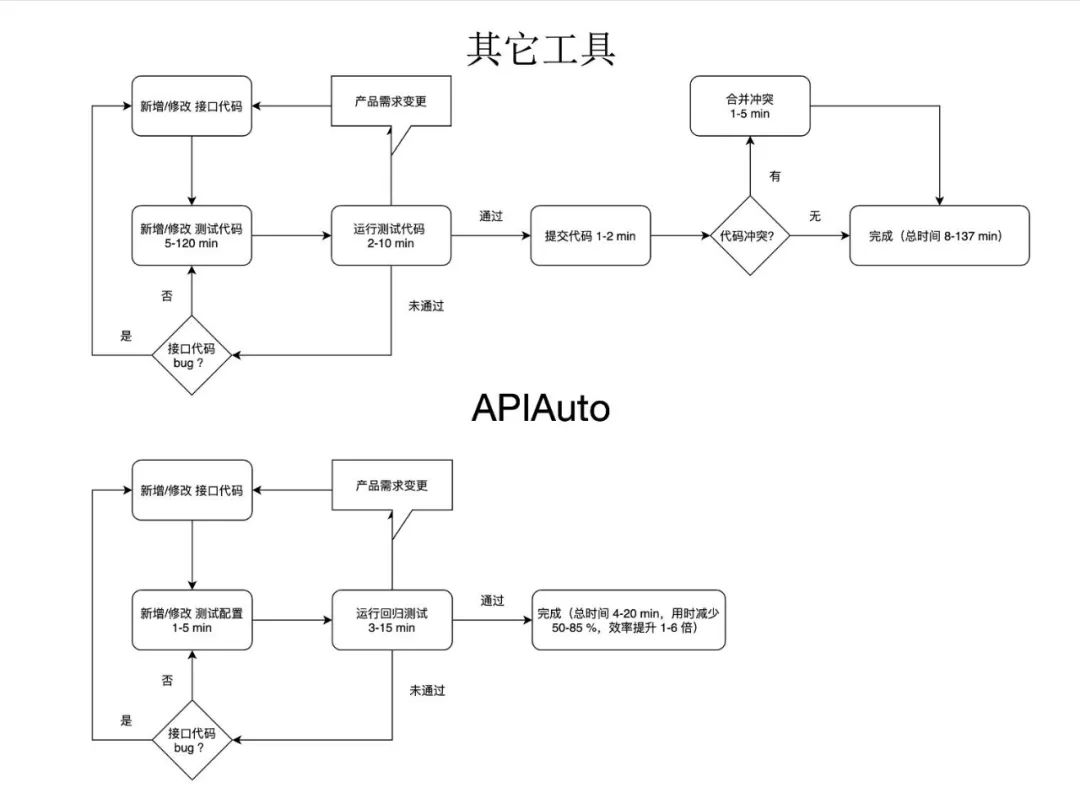
第四是仍然需要用 IDE 来管理、编译和运行测试用例代码,用 IDE 需要安装软件搭建环境,每次从启动到能用一般耗时在数分钟;
第五是仍然需要 Git 提交和推送测试用例代码,在多人协作的项目有时候还要解决代码冲突,短几分钟,长则半小时以上的都有,还不能每次都保证合并后没问题。
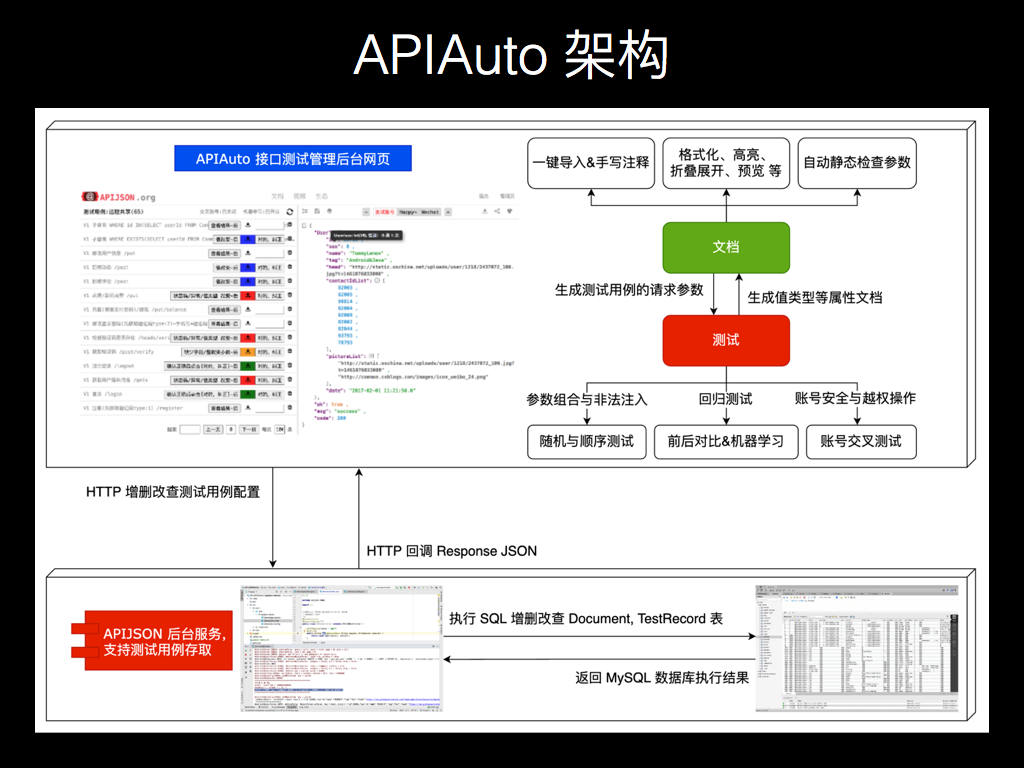
鉴于自己碰到各种痛点,加上业内各种工具的很多问题,让我感觉非常的不好用,然后我自己开发了 APIAuto-机器学习 HTTP 接口工具。
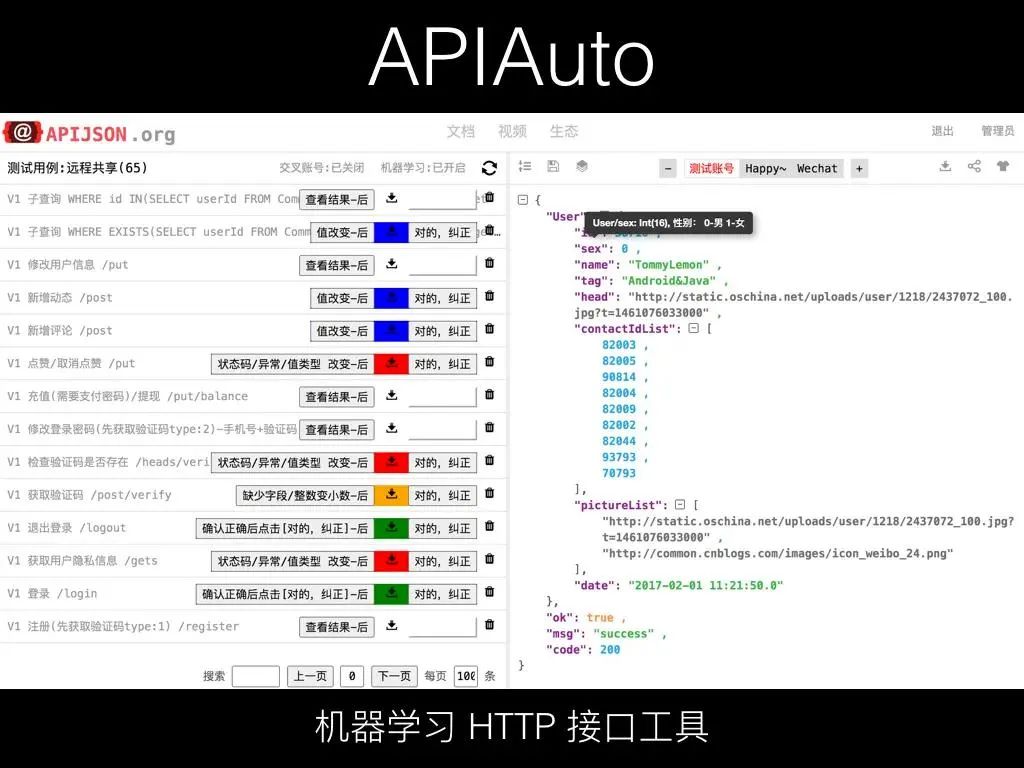



左侧有个测试用例列表,注意这里的测试用例的并不是代码,只是请求的方法、URL 和参数。然后点右上角类似循环的图标按钮,就是一个回归测试,跑出来每个用例的断言结果。
它是零代码断言,红黄蓝绿表示对应的不同严重程度的警告,左侧按钮显示错误分类,把光标放上去可以看到具体对应的错误详情,可以点这个按钮切换之前的正确结果和现在跑出来的结果。
这个前后对比测试是这样的,用同样的参数调用同一个接口,我之前调一次,跟我现在调一次,前后两次。假设调用一个查询的接口,它是幂等的,数据也没变,那它两次返回的 Response JSON 应该完全一样。如果对比后发现某一层某个键值对和上次的不一样,那是不是说明出了某种问题?
例如我上次调这个请求结果是成功的,他返回的状态码是200,我再调一下,它变成了 500;例如有个字段之前是一个整数,然后这次跑出来居然是一个字符串,它的类型都变掉了。
这样的话就会给它一个对应的一些红黄蓝绿这种不同严重程度的警告,把光标放上去可以看到具体的说明。
这样的话确实是可以做到零代码测试了,但是它的前提是要返回数据完整、前后数据不变。如果你这次上传了一个正确的结果,返回字段不完整,跑回归测试很可能会显示绿色的警告告诉你比上次多了个字段。
如果要保证数据不变,需要精心的去准备一个单独的测试数据库,然后再构造数据,这样成本很高,数据量一大导出和导入记录也要很久。
但如果不这样而是直接复用现有的测试/开发/预发布/线上环境数据库,就容易产生误判,一些值随时可能被修改,上次 1 这是我在跑出来是 2,前后对比不一样,出现一个蓝色的警告提示值变了,但即便不一样,它很可能是没问题的,只是视频分类、用户名等字段值被人改了。
还有个就是不能准确的判断可空值,因为只和一次正确结果对比,根本不知道这些字段到底是不是可空(非必传)的。有些字段,上次有这次没有给你个黄色的警告,实际上可能本来就可有可无,有没有返回、是不是 null 都是正确的。
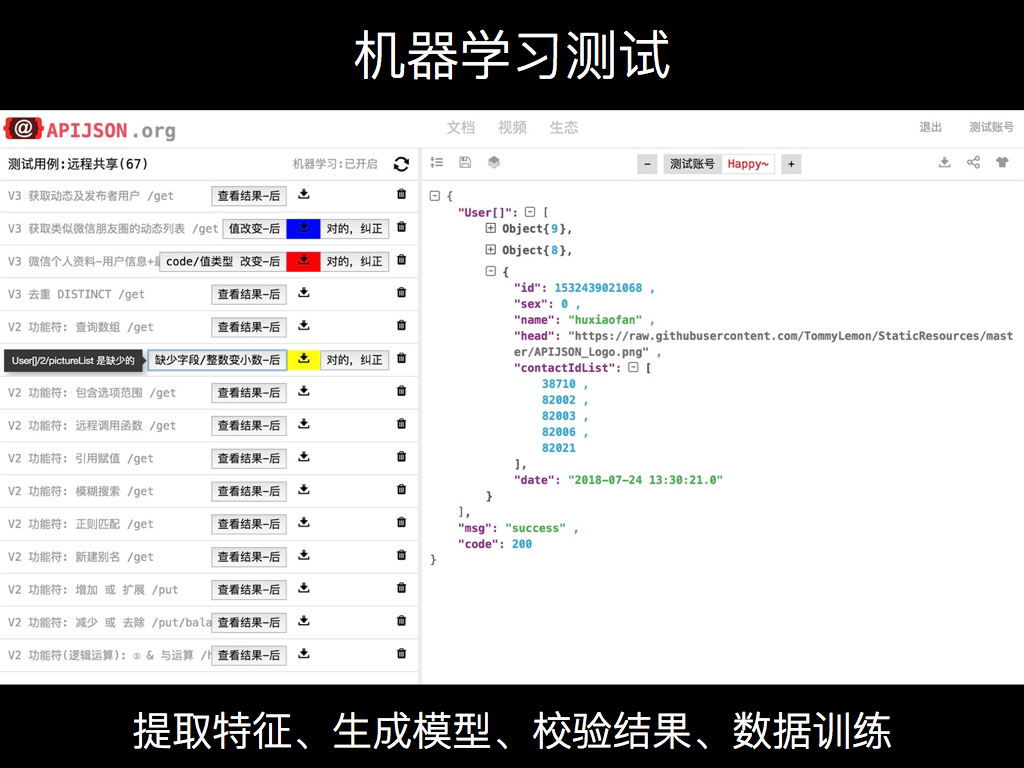
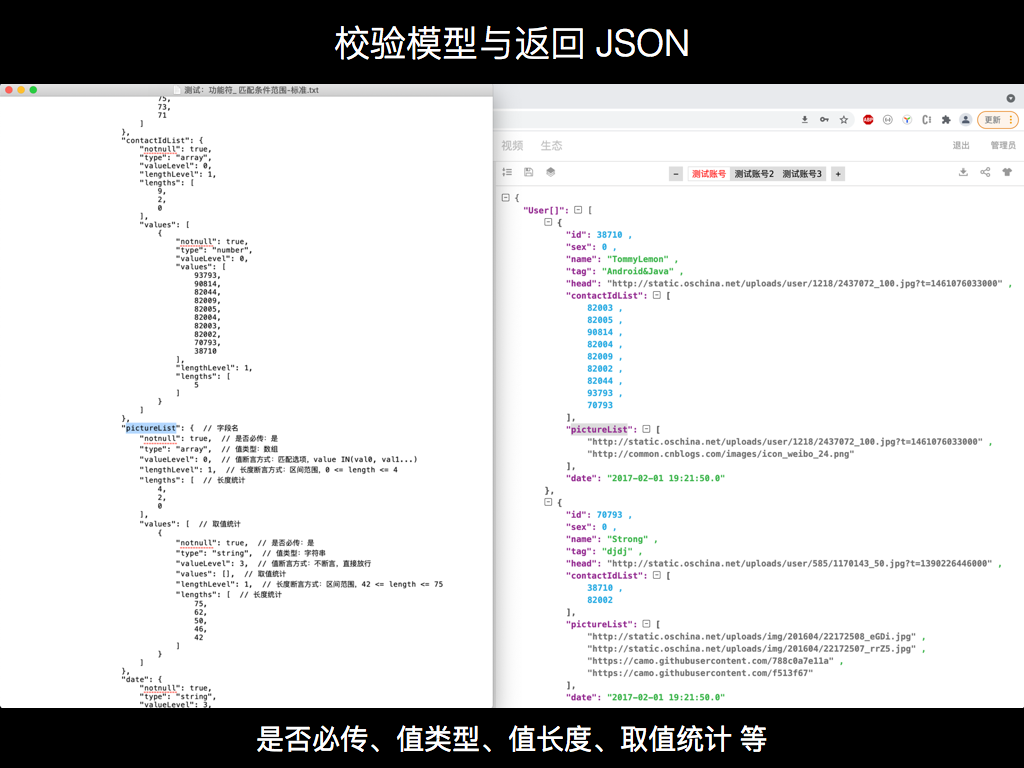
前后对比测试确实也存在很多不足,然后我基于它做了一个机器学习测试。提取回包 Response JSON 的特征,包含 JSON 结构、每一层每一个键值对的各种属性,是否必传 notnull、值类型 type、值的长度 lengths、具体取值 values 等,全都统计进去生成一个校验模型,然后再用这个校验模型对之后回归测试时跑出的结果进行断言并给出报告。
如果你看到一个黄色警告,标记出来数组第二项缺少 pictureList 字段,但你看一下这个字段本来也可以没有,那就点一下 [对的,纠正],它就会给校验模型纠错,把里面这个字段对应的 notnull 属性从 true 改为 false,下次不管有没有、是不是 null 都是断言通过。
如果某个字段值上次是 1,这次是 2,显示蓝色警告说明超出了原来所有值的统计范围,也就是没有匹配任何一个历史值,点一下 [对的,纠正] 就把 2 也统计进去了,下次不管是 1 还是 2 都是断言通过。这样的话一直统计到 10 个值后,如果你还点 [对的,纠正] ,APIAuto 会认为这肯定不是什么枚举值,就算是订单的状态都没这么多个,很可能就是个普通数字,就会把校验模型里的 valueLevel 从 0 改成 1,也就是原来是 IN 至少匹配一个,现在变成了从最小值到最大值这个区间范围任何一个整数都行。
这样就实现了校验模型断言和人工反馈纠错,随着纠错次数越多,匹配范围也会越来越大,就会把一开始过拟合的断言方式给泛化去兼容很多种不同的情况。
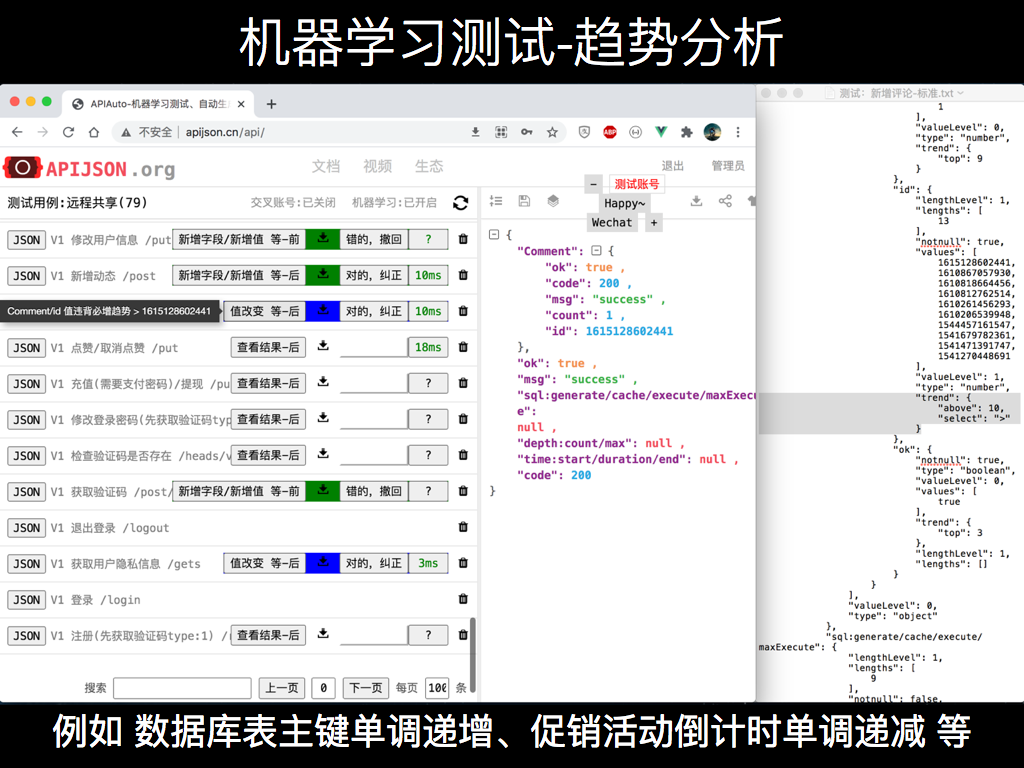
但如果是数据库自增表主键等,每次调用后值都不一样,这种情况下还是有问题。比如说创建了一个订单返回一个 orderId,新增了一条评论返回了一个 commentId,这些值它总是在变的,总是比原来所有值大,这样的话 APIAuto 总是会给一个蓝色的警告,说明字段值超出了原来匹配范围。
所以这里加了趋势分析,把已统计的所有值划分到 trend 下的 5 个所属区域,最大值落在 top,最小值落在 bottom,大于最大值为 above,小于最小值为 below,中间是 center。
如果对它纠错加进了一个新值,新值落在了哪个区域,哪个区域统计次数就加一。如果某个字段被统计 11 次,每一次它总是相对原来区间都是比原来最大值更大,那就只有 above 区域统计次数是 1 以上的,其它的都是 0 或没有统计。
这样就统计出来它的值有一个递增的趋势了,那我下次再跑一遍,比如说是一个新增一条评论,评论 id 要比原来最大的还要大才是对的,反而如果它没有大于已统计的最大值,APIAuto 会显示一个蓝色警告说明违背了之前的必增趋势。
这种情况什么时候可能出现呢?
现在有很多接口加了 Redis 之类的内存缓存来保证性能,在 Redis 写成功了就直接返回成功 Reponse JSON 了,然后再异步去写数据库。这中间是有时差的,可能出现了某种异常情况,Redis 写进去了但数据库没有写进去。APIAuto 之前已经统计了评论 id 的一些值,例如统计到了 102,然后数据库出现了某种异常,他实际上的值只增加到了 100,后面的几个没有写进去。再用 APIAuto 去跑的时候,跑出来一个 101 并断言未通过,给了蓝色警告提示违背了必增趋势,这样就发现了接口的缓存及数据库读写的问题。
另一个例子,如果我昨天看了一下页面某个促销活动倒计时显示还剩 1 天,今天看显示的还是 1。这不就很奇怪嘛,应该是 0,可能最近一天内服务出现了某些故障,并且没有及时地保存和恢复状态,所以就看到一个错误的数字,可能有不少用户就错过了 1 天促销日,商家也损失了很多订单。APIAuto 分析出来倒计时字段值是一个递减趋势,能够很好地及时发现这样的细微 bug,给出一个蓝色警告说明对应的值违背了递减趋势。

我在测试过程中还发现了一种情况:既然都不去准备单独的测试库构造数据了,接口返回的 状态码/错误码 可能都不稳定。
比如说腾讯 WeGame 有个置顶游戏组织的接口,先置顶成功了,再置顶它会返回一个错误码和错误信息提示这个组织已经置顶了。它是一种异常情况,虽然说返回的不是成功结果,但其实接口是没有问题的,它是符合业务需要的。如果说测试用例只是 assertEquals("调用失败", 0, err_code),那就产生了一个误判。
那这个怎么解决呢?有的人可能会说,那我只要把所有可能返回的错误码加上一个成功的状态码 0,断言代码改成 assertTrue("错误码不对", err_code in [0, 1, 2..]) 就兼容了。
但是这样会有两个问题:首先是这所有的错误码的集合怎么来,后端工程师会告诉你吗?我看到项目基本都没有,都是在一个地方统一的把所有接口可能返回的所有错误码汇总为一个文档。即便你跟他们扯皮一番,他们很不情愿的把每个接口可能返回的所有错误码都给你了,你写成 assert in 就对了吗?也不对,因为这样会导致测不出一些 bug,可能一个接口从来没有返回过成功的回包,测试用例也给放行了。如果一个接口调了很多次,从来没有返回一个成功的结果,那它有什么用呢?即便是你去删除一条记录,这个记录是在数据库有的,至少也得第一次成功吧?所以这也是不可行的。
那么 APIAuto 是怎么解决的?它把第一次上传的正确结果作为是成功的结果,对应错误码是 0,然后再跑出来回包中错误码是 1,会给显示一个红色的警告,错误码/状态码 改变。然后你看了一下,其实这个回包也是没问题的,点一下 [对的,纠正],APIAuto 就把 1 加到 exceptions 这个异常分支,下次再跑出 1,只是显示一个绿色提示说明接口没问题,只是结果是失败的,可以忽略。对于这种失败也可能符合业务需求的情况,作为异常分支来断言通过,就不会误判。
APIAuto 的机器学习测试使得接口回归测试不再需要编写测试用例代码、不再需要准备测试库构造数据,实现了在极低成本下达到一个很好的测试效果,相比业内各种需要 编写代码/填写表单/生成代码 的 工具/平台/框架/库 等,APIAuto 简化了测试流程并且大幅降低了测试的门槛和工作量。
APIAuto-领先的 HTTP 接口工具
机器学习零代码测试、生成代码与静态检查、生成文档与光标悬浮注释。欢迎 Star、Fork、反馈、贡献 ~
GitHub:https://github.com/TommyLemon/APIAuto
Gitee:https://gitee.com/TommyLemon/APIAuto
本文作者
周作彪
现任职腾讯开发工程师
曾任职传音开发Leader 兼项目经理
-------- THE END --------