
KDD 2020首届时间检验应用科学奖公布,清华大学研究团队获奖

8月13日, SIGKDD 2020官方公布了2020年ACM SIGKDD创新奖、服务奖、论文奖、新星奖、时间检验研究奖、时间检验应用科学奖等六项大奖的获得者,这些奖项是针对数据科学、机器学习、大数据和计算机科学领域的杰出个人和研究团队而设立的。
值得一提的是,今年KDD颁发了首届时间检验应用科学奖(Test of Time Award for Applied Science)奖项,以表彰在数据科学的实际应用中具有影响力的研究。清华大学计算机科学与技术系唐杰、李涓子等人凭借他们在2008年发表的关于学术社交网络挖掘的研究成果获得了这一奖项。
获奖论文题目为ArnetMiner: Extraction And Mining Of Academic Social Networks,论文作者包括清华大学计算机科学与技术系的唐杰、张静、姚利敏、李涓子,以及来自 IBM 中国研究实验室的张莉和苏中。

http://keg.cs.tsinghua.edu.cn/jietang/publications/KDD08-Tang-et-al-ArnetMiner.pdf
研究背景
在作者开始这项研究之时,学术圈已有DBLP、CiteSeer、Google Scholar等学术搜索系统发布,但是往往存在以下两项不足之处:
1)缺乏语义信息。无论用户输入的个人资料或使用启发式方法提取的各类信息,语义存在不完整或不一致性,缺少有效获得大规模语义信息的方法;
2)缺乏异构对象的统一建模方法。以前,学术网络中不同类型的信息如学者、论文、会议期刊是单独建模的,因此无法准确捕捉它们之间的依赖关系。
为解决这两个问题,作者所在的研究团队开发了ArnetMiner(https://www.aminer.cn/ )系统。该系统旨在解决以下几个问题:
1)如何自动从互联网海量信息中提取研究人员的个人档案?
2)如何集成不同来源提取的学术相关信息(例如研究人员的个人档案和出版物)?
3)如何以统一的方法为不同类型的信息建模?
4)如何基于已构建的网络,提供强大的挖掘和搜索服务?
ArnetMiner系统(简称AMiner)
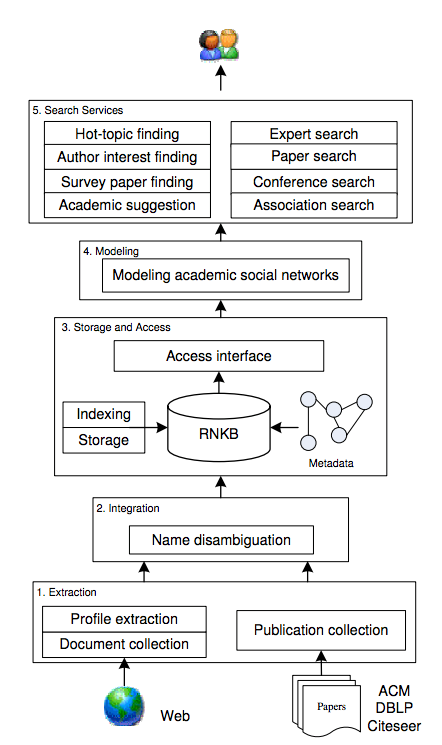
图1:AMiner系统框架图
1)研究者个人信息抽取(Extraction):即从网络上自动识别到研究者的个人主页,并训练一个统一的模型,从中抽取研究者的各种基本信息。同时,从不同来源的论文数据库抽取或收集作者所发表的论文信息;
2)个人信息融合(Integration):通过使用研究者姓名作为标识符,将提取的研究者的个人资料和提取的出版物信息进行整合。提出了马尔科夫随机场概率模型,以解决融合不同来源论文数据时面临的重名歧义问题;
3)存储和访问(Storage and Access):系统将集成的数据存储在研究者网络知识库(RNKB)中,利用MySQL作为存储数据库,并使用反向文件索引方法进行信息索引;
4)建模(Modeling):文章提出一个概率生成模型,通过对学术网络中的研究者、论文、会议等不同类型的信息进行综合分析,对每种信息进行主题分布估计;
5)搜索服务(Search Services):基于建模结果,提供多种搜索服务,包括专家搜索、关联关系搜索、论文推荐以及引用推荐等。
该系统重点解决三个技术难点:
1)学术网络中研究者个人信息自动抽取问题;
2)不同来源学术论文融合过程中的重名排歧问题;
3)学术网络中研究者、论文、会议等异质实体的统一建模问题。
个人自动信息抽取
研究者个人信息抽取分三步:相关页面识别、预处理和信息提取。
在相关的页面识别中,对于每个研究者,通过Google搜索引擎的API获得网页列表,并判断是否是研究者的主页或者包含了较多的研究者个人信息的介绍性网页。然后,使用支持向量机(SVM)作为分类模型对网页内容进行分类处理。
在预处理中,将文本进行标记处理,系统利用条件随机场(CRF)作为标记模型,来确定最可能的对应标记序列,每个标签对应一个定义的属性。
作者使用规则归纳模型算法和SVM模型方法作为概要文件提取的基准,通过研究每种特征类型在研究者档案提取中的作用,发现仅使用一种类型的功能无法获得准确的性能分析结果。
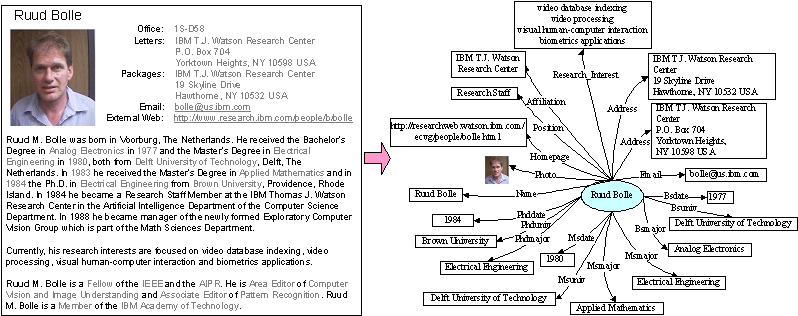
图2 :研究者个人主页和理想的标注结果
分析数据发现,个人信息的各个属性之间有依赖关系,而且有的属性之间有很强的依赖关系。
研究者重名排歧
之前的研究工作中,采用监督学习算法对每个排歧目标的数据进行学习和训练,这种方法可扩展性差;无监督学习方法受到可利用信息量的限制,排歧效果不太强。
针对这些问题,作者在文中提出了一个基于隐马尔可夫随机场(HMRF)的概率框架,该框架可以捕获每篇论文之间的依赖关系,从而更加灵活地将各种知识以约束的形式放到算法中,从而很好地利用各种指导和数据来提高重名排歧的精度。
具体而言,利用隐马尔可夫随机场理论构造目标函数,将整个问题转化为最小化目标函数问题。目标函数主要包含两个部分:
二是当前聚类结果所违背的所有约束的惩罚值之和。
整个算法的目标是找到内部紧密而且尽量少违背约束的聚类结果,来作为同名排歧的结果。作者在文中通过大量的实验数据,证明这一方法在消除重名方面明显优于传统方法。
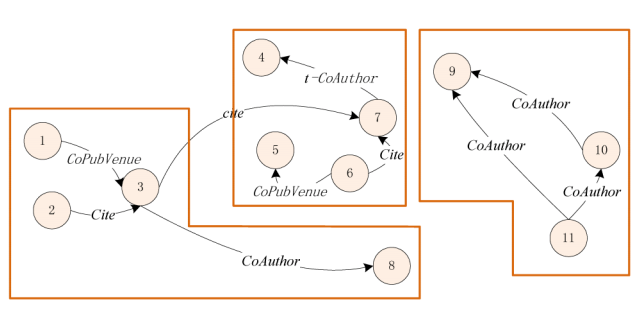
图3 :一个重名排岐的实例
从图中可以非常直观地看出,仅根据内容相似度不能取得很好的聚类效果,但是不同类型的关系对于区分不同的作者非常有效。例如,根据节点3和8之间的合作关系,很容易将它们分配到同一个类别。
异质网络建模
AMiner 提供的核心服务是专家搜索,即根据用户查询的话题找出在相关领域的权威专家。因此,仅仅依靠关键词进行专家匹配,几乎无法返回有效的结果。而如果我们知道自然语言处理领域的权威会议是“ACL”等,根据研究者发表的会议信息,就可以很容易判断出他是否是该领域的权威专家。
因此,作者提出了一个统一的主题模型ACT,同时对研究者论文、作者和会议的主题进行分布建模,设计了一种可以有效地利用学术网络的异质实体与关联信息,来发现领域内专家方法。
文章提出主题模型ACT对研究者异质信息网络统一进行建模,从中估计出不同类型的实体,包括研究者、会议、关键词以及论文在不同隐含话题上的概率分布。
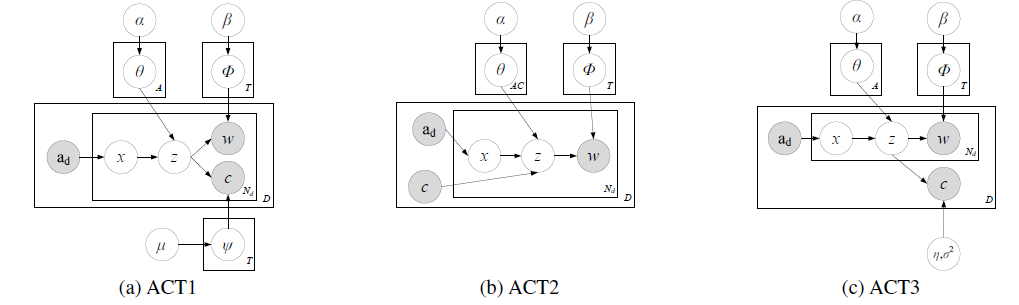
图4 构建话题模型生成研究者异构信息网络
ACT2模型:每个“作者-会议”对都与主题上的多项式分布相关联,然后从采样的主题中生成每个单词。
ACT3模型:每位作者都与一个主题分布相关联,并且在为论文中的所有单词标记采样主题之后,生成会议标记。
学术搜索服务
表1给出六种基线搜索方法的性能比较(%)
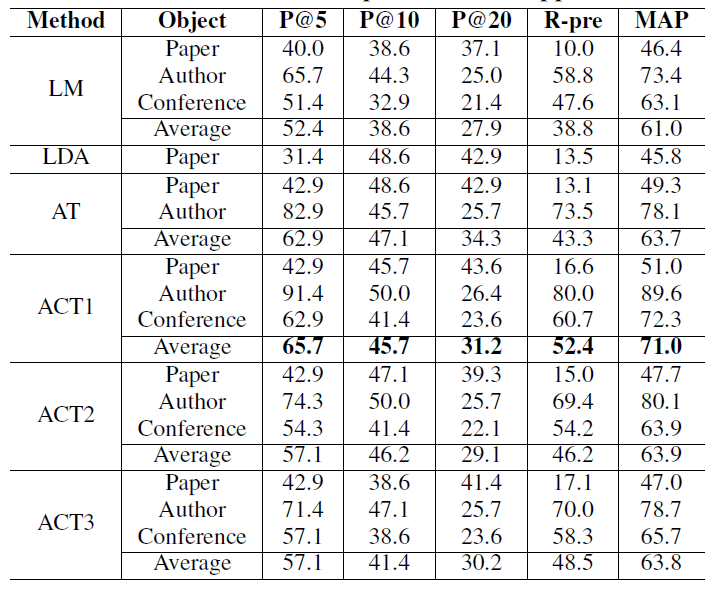
在研究者关系路径搜索的实验中,论文中提出的方法可以在一个由研究人员组成的网络上,在不到3秒的时间,找到链接两个研究者的最短的路径。
另外,作者所提出的模型还可以支持许多其他应用,如作者兴趣发现和学术建议。
https://www.aminer.cn/

免!费!
阿里大数据训练营重磅开启!
贾扬清亲自出品,阿里技术专家亲自授课
3天get阿里大数据独门绝学!
入门Flink、Spark等开源技术知识
更有实战讲解!
扫码get你的专属训练营!
实习/全职编辑记者招聘ing
加入我们,亲身体验一家专业科技媒体采写的每个细节,在最有前景的行业,和一群遍布全球最优秀的人一起成长。坐标北京·清华东门,在大数据文摘主页对话页回复“招聘”了解详情。简历请直接发送至zz@bigdatadigest.cn
评论