
一文看懂 | 物理内存分配算法(伙伴系统)
内核分配物理内存时,是以内存页作为分配单位的。但有时候内核需要分配一些物理内存地址连续的内存页,所以,Linux内核使用了 伙伴系统分配算法 来管理系统中的物理内存页.
什么是 伙伴系统分配算法?下面将会进行详细的介绍。
什么是伙伴系统分配算法
在 Linux 内核中,要分配内存页可以使用 alloc_pages() 函数来完成。而 alloc_pages() 函数最后会调用 rmqueue() 函数来分配内存页, rmqueue() 函数原型如下:
static struct page * rmqueue(zone_t *zone, unsigned long order);
参数 zone 是内存管理区, 而 order 是要分配 2order 个内存页. 由于 rmqueue() 函数使用了伙伴系统算法, 所以下面先来介绍一下伙伴系统算法的原理.
伙伴系统算法 的核心是 伙伴,那什么是伙伴呢?在 Linux 内核中,把两个物理地址相邻的内存页当作成伙伴。
因为,Linux 是以页面号来管理内存页的。所以,就是说两个相邻页面号的页面是伙伴关系。但是并不是所有相邻页面号的页面都是伙伴关系, 例如 0 号和 1 号页面是伙伴关系,但是 1 号和 2 号就不是了。为什么呢? 这是因为如果把 1 号页面和 2 号页面当成伙伴关系,那么 0 号页面就没有伙伴从而变成孤岛了。
那么给定一个 i 号内存页,怎么找到他的伙伴内存页呢?通过观察我们可以发现,如果页面号是复数的,那么他的伙伴内存页要加 1。
如果页面号是单数的,那么他的伙伴内存页要减 1。所以,对于给定一个页面号为 i 的内存页,他的伙伴内存页号可以使用以下的代码获得:
if (i & 1) {
buddy = i - 1
} else {
buddy = i + 1
}
那么知道一个内存页的伙伴页面有什么用呢?答案是为了合并为更大的内存页,例如把两个单位为1的伙伴内存页合并成为一个单位为2的内存页(这时应该称为内存块),把两个单位为2的伙伴内存块合并为单位为4的内存块,以此类推。
所以,使用伙伴系统算法只能分配 2order (order为0,1,2,3...)个页面。那么order是不是无限大呢?当然不是,在Linux内核中,order的最大值是 10。也就是说在内核中,最大能够申请到一个 29 个页面的内存块。
Linux 内核将物理内存划分为 内存管理区 进行管理,内存管理区使用结构体 zone_struct 表示。
而在内存管理区数据结构中有个名为 free_area 类型为 free_area_t 的字段,他的作用就是用来管理内存管理区内的空闲物理内存页. 定义如下:
#define MAX_ORDER 10
typedef struct free_area_struct {
struct list_head free_list;
unsigned int *map;
} free_area_t;
typedef struct zone_struct {
...
free_area_t free_area[MAX_ORDER]; // 用于伙伴分配算法
...
} zone_t;
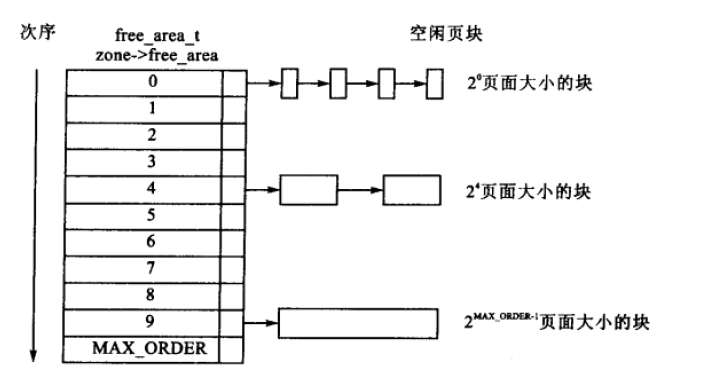
free_area 是伙伴系统算法的核心,可以看到 free_area 有10个元素。每个元素都是一个类型为 free_area_t 的结构体,free_area_t 结构的 free_list 字段用于连接有相同页面个数的内存块。map 字段是一个位图,用于记录伙伴内存块的使用情况。
Linux内核使用 free_area[i] 管理 2i 个内存页面大小的内存块列表,例如 free_area[0] 就是管理1个内存页面大小的内存块(20等于1);而 free_area[1] 则管理2个内存页面大小的内存块(21等于2)。如下图所示:
管理物理内存页的 struct page 结构中有个 list 的字段,内核就是通过这个字段把有着相同个数页面的内存块连成一个链表的:
typedef struct page {
struct list_head list;
...
} mem_map_t;
前面我们说过,在 free_area_t 结构中有个名为 map 的字段,map 字段是一个位图,每个位记录着一对伙伴内存块的使用情况。举个例子,如果一对伙伴内存块中的某一个内存块在使用,那么对应的位就为 1,如果两个伙伴内存块都是空闲或者使用,那么对应的位就为 0。如下图:
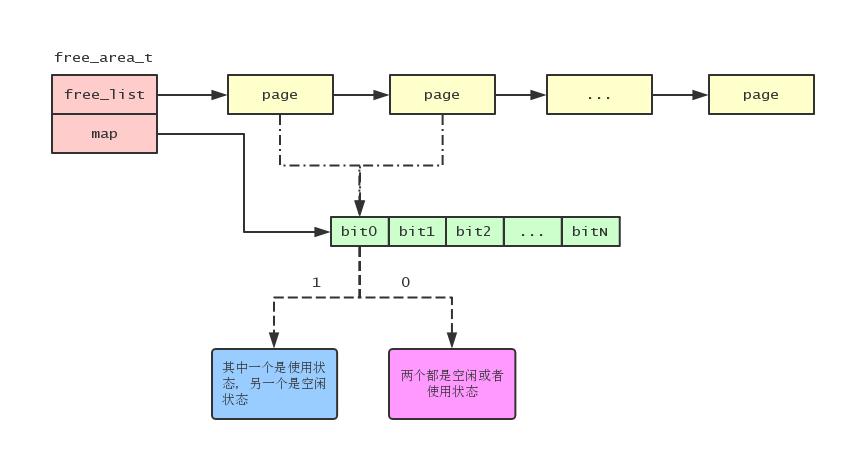
使用位图来标识伙伴内存块使用情况的原因是: 当释放内存块时, 如果对应的位是1的话, 那么说明另外一个伙伴内存块是空闲状态的, 所以释放当前内存块可以跟其伙伴内存块合并成一个更大的内存块了.
伙伴系统分配算法实现
我们来看看内核在初始化内存管理区时怎么初始化空闲内存块链表的,代码如下:
void __init free_area_init_core(int nid, pg_data_t *pgdat, struct page **gmap,
unsigned long *zones_size, unsigned long zone_start_paddr,
unsigned long *zholes_size, struct page *lmem_map)
{
...
for (j = 0; j < MAX_NR_ZONES; j++) {
zone_t *zone = pgdat->node_zones + j;
unsigned long mask;
unsigned long size, realsize;
...
mask = -1; // 32位系统这个值等于0xffffffff
for (i = 0; i < MAX_ORDER; i++) { // 初始化free_area
unsigned long bitmap_size;
memlist_init(&zone->free_area[i].free_list); // 初始化空闲链表
mask += mask; // 这里等于: mask = mask << 1;
size = (size + ~mask) & mask; // 用于向上对齐
bitmap_size = size >> i; // 内存块个数
bitmap_size = (bitmap_size + 7) >> 3; // 因为一个字节有8个位, 所以要除以8
bitmap_size = LONG_ALIGN(bitmap_size);
// 申请位图内存
zone->free_area[i].map =
(unsigned int *) alloc_bootmem_node(pgdat, bitmap_size);
}
...
}
...
}
上面的代码首先为每个管理不同大小空闲内存块的 free_area_t 结构初始化其 free_list 字段,然后根据其管理内存块的大小来计算需要多少个位来记录伙伴内存块的关系,并保存到 map 字段中。
说明一下,这里计算位图的大小时为每个内存块申请了一个位。但事实上每个位记录的是一对伙伴内存块的关系,所以需要除以 2。而现在明显浪费了一半的内存,在后面的 Linux 版本中改进了这个问题。
现在再回头看看物理内存分配 rmqueue() 函数的实现:
static struct page * rmqueue(zone_t *zone, unsigned long order)
{
free_area_t * area = zone->free_area + order; // 获取申请对应大小内存块的空闲列表
unsigned long curr_order = order;
struct list_head *head, *curr;
unsigned long flags;
struct page *page;
spin_lock_irqsave(&zone->lock, flags);
do {
head = &area->free_list; // 空闲内存块链表
curr = memlist_next(head);
if (curr != head) { // 如果链表不为空
unsigned int index;
page = memlist_entry(curr, struct page, list); // 当前内存块
if (BAD_RANGE(zone,page))
BUG();
memlist_del(curr);
index = (page - mem_map) - zone->offset; // 内存块所在内存管理区的索引
MARK_USED(index, curr_order, area); // 标记伙伴标志位为已用
zone->free_pages -= 1 << order; // 减去内存块所占用的内存页数
// 把更大的内存块分裂为申请大小的内存块
page = expand(zone, page, index, order, curr_order, area);
spin_unlock_irqrestore(&zone->lock, flags);
set_page_count(page, 1);
if (BAD_RANGE(zone,page))
BUG();
DEBUG_ADD_PAGE
return page;
}
// 如果在当前空闲链表中没有空闲的内存块, 那么向空间更大的的空闲内存块链表中申请
curr_order++;
area++;
} while (curr_order < MAX_ORDER);
spin_unlock_irqrestore(&zone->lock, flags);
return NULL;
}
申请内存块时,首先会在大小一致的空闲链表中申请,如果大小一致的空闲链表没有空闲的内存块,那么只能向空间更大的空闲内存块链表中申请。
如果申请到的内存块比要申请的大小大,那么需要调用 expand() 函数来把内存块分裂成指定大小的内存块。
大内存块分裂为小内存块的过程也很简单,举个例子:
如果我们要申请 order 为 2 的内存块(也就是大小为 4 个内存页的内存块),但是 order 为 2 的空闲链表没有空闲的内存,那么只能向 order 为 3 的空闲内存块链表中申请。如果 order 为 3 的空闲链表有空闲内存块,那么就从 order 为 3 的链表中申请一块空闲内存块。并且把此内存块分裂为2块 order 为 2 的内存块,一块添加到 order 为 2 的空闲链表中,另外一块分配给用户。如果 order 为 3 的空闲链表也没有空闲内存块,那么只能向 order 为 4 的空闲链表中申请,如此类推。
expand() 函数的源码如下:
static inline struct page * expand (zone_t *zone, struct page *page,
unsigned long index, int low, int high, free_area_t * area)
{
unsigned long size = 1 << high;
while (high > low) {
if (BAD_RANGE(zone,page))
BUG();
area--;
high--;
size >>= 1;
memlist_add_head(&(page)->list, &(area)->free_list); // 把分裂出来的一块内存块添加到下一级空闲链表中
MARK_USED(index, high, area); // 标记伙伴标志位为已用
index += size;
page += size;
}
if (BAD_RANGE(zone,page))
BUG();
return page;
}
可以对照上面的思路来分析 expand() 函数。
我们接着来分析内存块的释放,内存块的释放是通过 free_pages() 函数来实现的。而 free_pages() 函数最终会调用 __free_pages_ok() 函数,__free_pages_ok() 函数代码如下:
static void __free_pages_ok (struct page *page, unsigned long order)
{
unsigned long index, page_idx, mask, flags;
free_area_t *area;
struct page *base;
zone_t *zone;
...
zone = page->zone;
mask = (~0UL) << order; // 获取一个后order个位为0的长整型数字
base = mem_map + zone->offset; // 获取内存管理区管理的开始内存页
page_idx = page - base; // 当前页面在内存管理区的索引
if (page_idx & ~mask)
BUG();
index = page_idx >> (1 + order); // 伙伴标记位索引
area = zone->free_area + order; // 内存块所在的空闲链表
spin_lock_irqsave(&zone->lock, flags);
zone->free_pages -= mask; // 添加释放的内存块所占用的内存页数
while (mask + (1 << (MAX_ORDER-1))) { // 遍历(MAX_ORDER-order-1, MAX_ORDER等于10)次, 也就是说最多循环9次
struct page *buddy1, *buddy2;
if (area >= zone->free_area + MAX_ORDER)
BUG();
if (!test_and_change_bit(index, area->map)) // 如果伙伴内存块在使用状态, 那么退出循环
break;
buddy1 = base + (page_idx ^ -mask); // 伙伴内存块(-mask 等于 1<<order)
buddy2 = base + page_idx; // 当前内存块
if (BAD_RANGE(zone,buddy1))
BUG();
if (BAD_RANGE(zone,buddy2))
BUG();
memlist_del(&buddy1->list); // 把伙伴内存块从空闲链表中删除(因为要合并为更大的内存块, 所以要从当前的空闲链表中删除)
mask <<= 1;
area++; // 向更大的空闲链表进行合并操作
index >>= 1;
page_idx &= mask;
}
memlist_add_head(&(base + page_idx)->list, &area->free_list);
spin_unlock_irqrestore(&zone->lock, flags);
if (memory_pressure > NR_CPUS)
memory_pressure--;
}
释放过程和分配过程是一对互逆的过程,释放内存块时首先看看伙伴内存块的状态。如果伙伴内存块是空闲状态,那么就与伙伴内存块合并为更大的内存块,并且一直尝试合并为更大的内存块。
直到伙伴内存块不是空闲状态或者达到内存块的最大限制(order为9)停止合并过程,根据上面代码的注释可以慢慢理解。