
ConcurrentHashMap源码分析

预备知识
安全失败(fail safe)和快速失败(fail quick)
快速失败
现象:在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了增加、删除、修改操作,则会抛出ConcurrentModificationException。
原理:迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个 modCount 变量。集合在被遍历期间如果内容发生变化,就会改变modCount的值。每当迭代器使用hashNext()/next()遍历下一个元素之前,都会检测modCount变量是否为expectedmodCount值,是的话就返回遍历;否则抛出ConcurrentModificationException异常,终止遍历。
安全失败
现象:采用失败安全机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。
原理:由于迭代时是对原集合的拷贝进行遍历,所以在遍历过程中对原集合所作的修改并不能被迭代器检测到,所以不会触发ConcurrentModificationException。
正是由于安全失败机制,使得HashTable无法防止null的元素,因为hashTable是线程安全的,当遍历元素的时候无法判断当前table中是否拥有元素,是不存在元素还是元素为null。
分析思路
hashmap实现线程安全的方式介绍
并发容器是如何实现线程安全的(底层的介绍)
hashmap和concurrenthashmap进行对比
如何实现实现线程安全
hashtable
colletions.synchronizedMap()方法
ConcurrentHashMap
其中上面两种是效率比较低,原因是使用粗粒度锁,所以在高并发环境下效率没有第三种高。
其中hashTable中使用了大量对Synchronized关键字保证线程安全。而Collections的方法则是将传入的形参作为一个参数,内部拥有一个mutex对象作为加锁对象。进行synchronized关键字的加锁。
ConcurrentHashmap实现线程安全的方法
主要看put和get扩容以及size方法
put方法流程
如果数组为空,初始化,初始化完成之后,走 2;
计算当前槽点有没有值,没有值的话,cas 创建,失败继续自旋(for 死循环),直到成功,
槽点有值的话,走 3;如果槽点是转移节点(正在扩容),就会一直自旋等待扩容完成之后再新增,不是转移节点走
4;槽点有值的,先锁定当前槽点,保证其余线程不能操作,如果是链表,新增值到链表的尾
部,如果是红黑树,使用红黑树新增的方法新增;新增完成之后 check 需不需要扩容,需要的话去扩容。
使用的流程主要是自旋+cas+锁来保证put方法为安全的。
其中方法1中初始化方法保证多个线程中只有一个线程进行初始化的主要操作是通过一个cas操作来保证只有一个线程能够初始化 ,当一个线程获取到这个sizeCtl后就将sizeCtl值设置为-1。在不断的while循环中若读取到sizeCtl的值为-1则调用yield()方法后,释放cpu再次进入自旋的过程。
private final Node[] initTable() {
Node[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node[] nt = (Node[])new Node[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
} 第三步:若当前的槽点为空的时候为了安全会进行cas进行添加元素,而不是直接添加安全性能更好。
第四步:若当前数组正在扩容就进行获取到当前最新的数组列表然后再次进入自旋。
第五步:对当前发生hash冲突的首节点进行上锁操作,这边的锁的粒度比jdk1.7中更加细,所以并发效果更加好
get方法原理:
在一次qq聊天讨论中,我们讨论为什么hashtable的get方法是使用syn关键字进行加锁而cchm(concurrenthashMap)get方法却没有添加锁等关键字 这个是为什么?是否会出现数据的脏读等问题?
get操作源码
首先计算hash值,定位到该table索引位置,如果是首节点符合就返回
如果遇到扩容的时候,会调用标志正在扩容节点ForwardingNode的find方法,查找该节点,匹配就返回
以上都不符合的话,就往下遍历节点,匹配就返回,否则最后就返回null
//会发现源码中没有一处加了锁
public V get(Object key) {
Node[] tab; Node e, p; int n, eh; K ek;
int h = spread(key.hashCode()); //计算hash
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {//读取首节点的Node元素
if ((eh = e.hash) == h) { //如果该节点就是首节点就返回
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
//hash值为负值表示正在扩容,这个时候查的是ForwardingNode的find方法来定位到nextTable来
//eh=-1,说明该节点是一个ForwardingNode,正在迁移,此时调用ForwardingNode的find方法去nextTable里找。
//eh=-2,说明该节点是一个TreeBin,此时调用TreeBin的find方法遍历红黑树,由于红黑树有可能正在旋转变色,所以find里会有读写锁。
//eh>=0,说明该节点下挂的是一个链表,直接遍历该链表即可。
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {//既不是首节点也不是ForwardingNode,那就往下遍历
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
} get没有加锁的话,ConcurrentHashMap是如何保证读到的数据不是脏数据的呢?
对于可见性,Java提供了volatile关键字来保证可见性、有序性。但不保证原子性。普通的共享变量不能保证可见性,因为普通共享变量被修改之后,什么时候被写入主存是不确定的,当其他线程去读取时,此时内存中可能还是原来的旧值,因此无法保证可见性。
volatile关键字对于基本类型的修改可以在随后对多个线程的读保持一致,但是对于引用类型如数组,实体bean,仅仅保证引用的可见性,但并不保证引用内容的可见性。
禁止进行指令重排序。
背景:为了提高处理速度,处理器不直接和内存进行通信,而是先将系统内存的数据读到内部缓存(L1,L2或其他)后再进行操作,但操作完不知道何时会写到内存。
如果对声明了volatile的变量进行写操作,JVM就会向处理器发送一条指令,将这个变量所在缓存行的数据写回到系统内存。但是,就算写回到内存,如果其他处理器缓存的值还是旧的,再执行计算操作就会有问题。
在多处理器下,为了保证各个处理器的缓存是一致的,就会实现缓存一致性协议,当某个CPU在写数据时,如果发现操作的变量是共享变量,则会通知其他CPU告知该变量的缓存行是无效的,因此其他CPU在读取该变量时,发现其无效会重新从主存中加载数据。
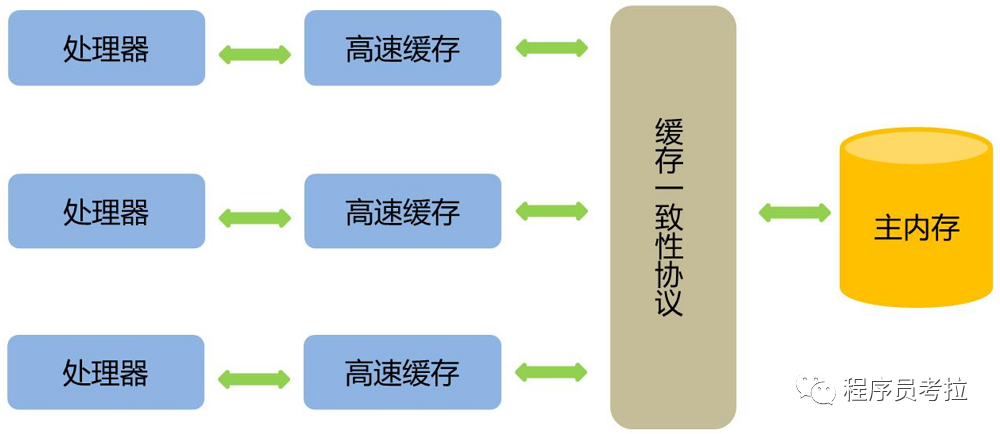
总结下来:
第一:使用volatile关键字会强制将修改的值立即写入主存;
第二:使用volatile关键字的话,当线程2进行修改时,会导致线程1的工作内存中缓存变量的缓存行无效(反映到硬件层的话,就是CPU的L1或者L2缓存中对应的缓存行无效);
第三:由于线程1的工作内存中缓存变量的缓存行无效,所以线程1再次读取变量的值时会去主存读取。
是加在数组上的volatile吗?
/**
* The array of bins. Lazily initialized upon first insertion.
* Size is always a power of two. Accessed directly by iterators.
*/
transient volatile Node[] table; 我们知道volatile可以修饰数组的,只是意思和它表面上看起来的样子不同。举个栗子,volatile int array[10]是指array的地址是volatile的而不是数组元素的值是volatile的.
用volatile修饰node
get操作可以无锁是由于Node的元素val和指针next是用volatile修饰的,在多线程环境下线程A修改结点的val或者新增节点的时候是对线程B可见的。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
//可以看到这些都用了volatile修饰
volatile V val;
volatile Node next;
Node(int hash, K key, V val, Node next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return val; }
public final int hashCode() { return key.hashCode() ^ val.hashCode(); }
public final String toString(){ return key + "=" + val; }
public final V setValue(V value) {
throw new UnsupportedOperationException();
}
public final boolean equals(Object o) {
Object k, v, u; Map.Entry e;
return ((o instanceof Map.Entry) &&
(k = (e = (Map.Entry)o).getKey()) != null &&
(v = e.getValue()) != null &&
(k == key || k.equals(key)) &&
(v == (u = val) || v.equals(u)));
}
/**
* Virtualized support for map.get(); overridden in subclasses.
*/
Node find(int h, Object k) {
Node e = this;
if (k != null) {
do {
K ek;
if (e.hash == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
} while ((e = e.next) != null);
}
return null;
}
} 既然volatile修饰数组对get操作没有效果那加在数组上的volatile的目的是什么呢?
其实就是为了使得Node数组在扩容的时候对其他线程具有可见性而加的volatile
ConcurrentHashMap 1.7和1.8进行比较
| 区别 | 1.7 | 1.8 |
|---|---|---|
| 底层实现 | Segment数组+hashEntry数组实现 | 数组+链表+红黑树实现 |
| 如何实现线程安全 | Segment保证 | cas+Synchronized |
| 重要方法 | put size | put size |
底层数据结构
jdk1.7

其中Segment数组容量初始化为16,hashEntry数组的大小为2,两者扩容大小都为2的幂次。
put方法
1.7中put方法主要流程为:
1、线程A执行tryLock()方法成功获取锁,则把HashEntry对象插入到相应的位置;
2、线程B获取锁失败,则执行scanAndLockForPut()方法,在scanAndLockForPut方法中,会通过重复执行tryLock()方法尝试获取锁,在多处理器环境下,重复次数为64,单处理器重复次数为1,当执行tryLock()方法的次数超过上限时,则执行lock()方法挂起线程B;
3、当线程A执行完插入操作时,会通过unlock()方法释放锁,接着唤醒线程B继续执行;
多次获取锁的过程有点类似自旋。
size方法主要流程为:
先采用不加锁的方式,连续计算元素的个数,最多计算3次:
1、如果前后两次计算结果相同,则说明计算出来的元素个数是准确的;
2、如果前后两次计算结果都不同,则给每个Segment进行加锁,再计算一次元素的个数;
jdk1.8
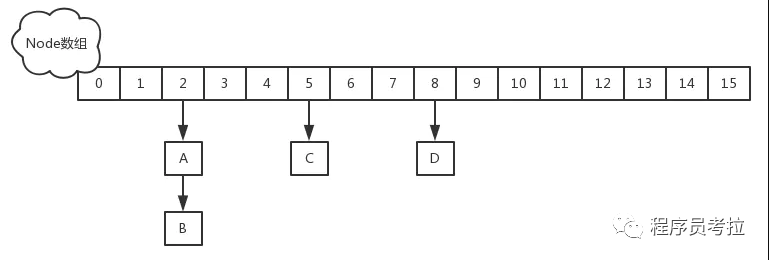
put方法
若插入位置元素为null 则通过cas进行插入元素
若插入元素不为空则对头节点元素进行加锁操作,进行插入元素操作
第二步需要判断头结点类型若为链表使用链表方式进行插入否则使用树节点形式进行插入
size方法
实现原理是通过baseCount和cell数组来计数保证数组元素的大小不会改变
初始化时counterCells为空,在并发量很高时,如果存在两个线程同时执行CAS修改baseCount值,则失败的线程会继续执行方法体中的逻辑,使用CounterCell记录元素个数的变化;
如果CounterCell数组counterCells为空,调用fullAddCount()方法进行初始化,并插入对应的记录数,通过CAS设置cellsBusy字段,只有设置成功的线程才能初始化CounterCell数组。
如果通过CAS设置cellsBusy字段失败的话,则继续尝试通过CAS修改baseCount字段,如果修改baseCount字段成功的话,就退出循环,否则继续循环插入CounterCell对象;
简单总结就是如果多个线程如果同时要修改元素的数量,一个元素成功修改basecount的同时,另一个元素会进行修改countCell数组内元素的大小,若多个线程同时修改则启动cas。
总结
在1.7中多线程的并发修改容量跟segment数组的容量大小有关,而在1.8中进行修改后,锁的粒度更加小,使得多线程环境下效率更高。同时Synchronized锁在之后也进行了升级,由无锁到偏向所再到轻量级锁到最后的重量级锁。这样一个不同的过程。
作者:Deciscive
链接:juejin.im/post/6844904146462572557