动态加密?看我如何见招拆招爬取某点评全站内容!
↑ 关注 + 星标 ,每天学Python新技能
后台回复【大礼包】送你Python自学大礼包
大家好,我是早起。
在前几天的文章中,我针某点评商家搜索页面的字体反爬给出了解决方案,但是还有一个问题,那就是当时给出的方法是下载对应的woff字体文件,然后建立加密字体与编码之间的映射关系来进行破解。
但是有一个问题就是不同页面的字体文件,是动态加载的,换句话说就是你在这个页面建立的映射关系,换一个页面就不能用了。
那就没有解决办法了吗?其实也不难,或者说对方还是给了很清晰的思考方向,因为,虽然每一个页面的字体是动态加载的,但是这个动态仅针对字体解析后编码的变化,字体内部顺序是没有变化的,也就是如下图所示
每两个页面中,仅仅是字体编码发生了改变,而字体的位置顺讯并没有改变,所以我们只需要在解析每一页的数据之前,先提取页面中CSS样式,再从CSS内容中定位到字体文件存储链接,之后就是请求这一页对应的字体文件并解析构造匹配字典,后面的步骤就和上一篇文章一样了。
那我们开始,目标是爬取某城市指定美食的全部商家信息,比如定位广州搜索沙县小吃,之后爬取全部的搜索页面。
首先就是构造全部的URL,由于每一页的URL是有一定规律的,所以这一步很简单,从第一页中提取全部页数然后按照规律添加到url_list中即可,而这个数据没有被加密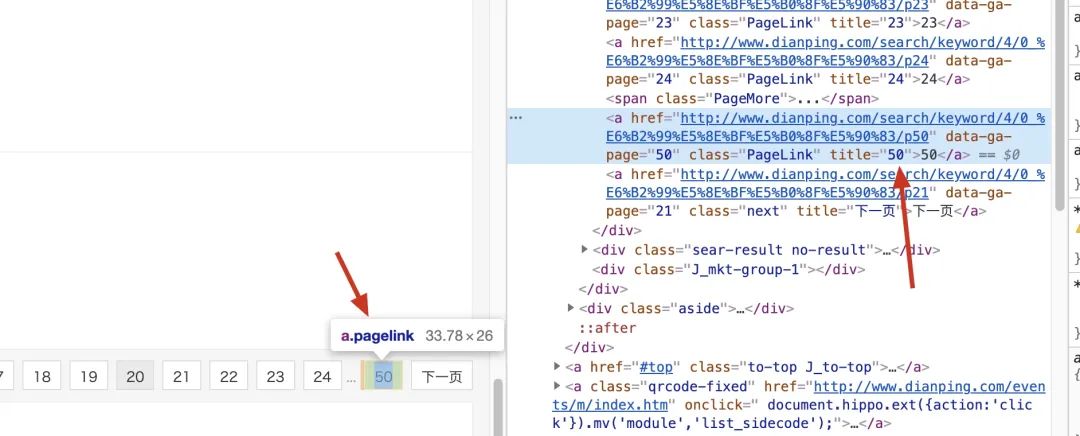
所以这部分代码可以这样写
def get_url(url):
headers = {
"Host": "www.dianping.com",
"Referer":f"{url}",
"User-Agent":ua.random,
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1"
}
r = requests.get(url = url,headers = headers,proxies = get_ip())
soup = BeautifulSoup(r.text)
page_num = int(soup.find_all('a',class_ = 'PageLink')[-1].text)
url_list = [url + f"/p{i+1}" for i in range(page_num)]
return url_list
这部分代码不难理解构造请求——解析页面——提取页数——模拟URL,其中get_ip()必须要返回一个可以使用的ip,不论你是用免费的还是付费的代理,在这里不做详细讲解。
搞定URL之后,我们来到最关键的步骤,写一个函数,传进来一个页面返回该页的文字匹配字典,那么第一步就是把字体拿下来,下面四行代码即可搞定
css_url = "http://" + re.search(r's3plus.meituan.net/(.*?)/svgtextcss/(.*?).css', page.text).group(0) #拿到css文件
css_value = requests.get(css_url).text
addr_font = "http:" + re.search(r'address(.*?).woff', css_value).group(0).split(',')[-1][5:]
price_font = "http:" + re.search(r'shopNum(.*?).woff', css_value).group(0).split(',')[-1][5:]
简单来看一下这段代码,我们传入一个请求后得到的page后
“第一行代码使用正则表达式提取字体所在的css链接
第二行代码使用requests请求css内容
最后两行代码使用正则提取woff字体文件所在URL
”
如果你传进去的页面是正常的,那么现在我们就有地址、均价字段的字体所在URL,下面就可以使用requests将这两个字体文件下载并保存在本地,代码如下
x = requests.get(addr_font).content
with open('addr.woff','wb+') as f:
f.write(x)
x = requests.get(price_font).content
with open('price.woff','wb+') as f:
f.write(x)
现在工作目录下就有两个字体文件,之后就按照上一篇文章介绍的字体加密破解方法操作即可。所以这部分完整代码如下:
def get_font(page):
'''
接收请求后的页面
返回该页url字体woff文件对应的两个字典文件
'''python
css_url = "http://" + re.search(r's3plus.meituan.net/(.*?)/svgtextcss/(.*?).css', page.text).group(0) #拿到css文件
css_value = requests.get(css_url).text
addr_font = "http:" + re.search(r'address(.*?).woff', css_value).group(0).split(',')[-1][5:]
price_font = "http:" + re.search(r'shopNum(.*?).woff', css_value).group(0).split(',')[-1][5:]
#下载字体保存到本地
x = requests.get(addr_font).content
with open('addr.woff','wb+') as f:
f.write(x)
x = requests.get(price_font).content
with open('price.woff','wb+') as f:
f.write(x)
#解析字体
font_addr = TTFont('addr.woff')
font1 = font_addr.getGlyphOrder()[2:]
font1 = [font1[i][-4:] for i in range(len(font1))]
font_price = TTFont('price.woff')
font2 = font_price.getGlyphOrder()[2:]
font2 = [font2[i][-4:] for i in range(len(font2))]
font3 = ['1', '2', '3', '4', '5', '6', '7', '8',
'9', '0', '店', '中', '美', '家', '馆', '小', '车', '大',
'市', '公', '酒', '行', '国', '品', '发', '电', '金', '心',
'业', '商', '司', '超', '生', '装', '园', '场', '食', '有',
'新', '限', '天', '面', '工', '服', '海', '华', '水', '房',
'饰', '城', '乐', '汽', '香', '部', '利', '子', '老', '艺',
'花', '专', '东', '肉', '菜', '学', '福', '饭', '人', '百',
'餐', '茶', '务', '通', '味', '所', '山', '区', '门', '药',
'银', '农', '龙', '停', '尚', '安', '广', '鑫', '一', '容',
'动', '南', '具', '源', '兴', '鲜', '记', '时', '机', '烤',
'文', '康', '信', '果', '阳', '理', '锅', '宝', '达', '地',
'儿', '衣', '特', '产', '西', '批', '坊', '州', '牛', '佳',
'化', '五', '米', '修', '爱', '北', '养', '卖', '建', '材',
'三', '会', '鸡', '室', '红', '站', '德', '王', '光', '名',
'丽', '油', '院', '堂', '烧', '江', '社', '合', '星', '货',
'型', '村', '自', '科', '快', '便', '日', '民', '营', '和',
'活', '童', '明', '器', '烟', '育', '宾', '精', '屋', '经',
'居', '庄', '石', '顺', '林', '尔', '县', '手', '厅', '销',
'用', '好', '客', '火', '雅', '盛', '体', '旅', '之', '鞋',
'辣', '作', '粉', '包', '楼', '校', '鱼', '平', '彩', '上',
'吧', '保', '永', '万', '物', '教', '吃', '设', '医', '正',
'造', '丰', '健', '点', '汤', '网', '庆', '技', '斯', '洗',
'料', '配', '汇', '木', '缘', '加', '麻', '联', '卫', '川',
'泰', '色', '世', '方', '寓', '风', '幼', '羊', '烫', '来',
'高', '厂', '兰', '阿', '贝', '皮', '全', '女', '拉', '成',
'云', '维', '贸', '道', '术', '运', '都', '口', '博', '河',
'瑞', '宏', '京', '际', '路', '祥', '青', '镇', '厨', '培',
'力', '惠', '连', '马', '鸿', '钢', '训', '影', '甲', '助',
'窗', '布', '富', '牌', '头', '四', '多', '妆', '吉', '苑',
'沙', '恒', '隆', '春', '干', '饼', '氏', '里', '二', '管',
'诚', '制', '售', '嘉', '长', '轩', '杂', '副', '清', '计',
'黄', '讯', '太', '鸭', '号', '街', '交', '与', '叉', '附',
'近', '层', '旁', '对', '巷', '栋', '环', '省', '桥', '湖',
'段', '乡', '厦', '府', '铺', '内', '侧', '元', '购', '前',
'幢', '滨', '处', '向', '座', '下', '県', '凤', '港', '开',
'关', '景', '泉', '塘', '放', '昌', '线', '湾', '政', '步',
'宁', '解', '白', '田', '町', '溪', '十', '八', '古', '双',
'胜', '本', '单', '同', '九', '迎', '第', '台', '玉', '锦',
'底', '后', '七', '斜', '期', '武', '岭', '松', '角', '纪',
'朝', '峰', '六', '振', '珠', '局', '岗', '洲', '横', '边',
'济', '井', '办', '汉', '代', '临', '弄', '团', '外', '塔',
'杨', '铁', '浦', '字', '年', '岛', '陵', '原', '梅', '进',
'荣', '友', '虹', '央', '桂', '沿', '事', '津', '凯', '莲',
'丁', '秀', '柳', '集', '紫', '旗', '张', '谷', '的', '是',
'不', '了', '很', '还', '个', '也', '这', '我', '就', '在',
'以', '可', '到', '错', '没', '去', '过', '感', '次', '要',
'比', '觉', '看', '得', '说', '常', '真', '们', '但', '最',
'喜', '哈', '么', '别', '位', '能', '较', '境', '非', '为',
'欢', '然', '他', '挺', '着', '价', '那', '意', '种', '想',
'出', '员', '两', '推', '做', '排', '实', '分', '间', '甜',
'度', '起', '满', '给', '热', '完', '格', '荐', '喝', '等',
'其', '再', '几', '只', '现', '朋', '候', '样', '直', '而',
'买', '于', '般', '豆', '量', '选', '奶', '打', '每', '评',
'少', '算', '又', '因', '情', '找', '些', '份', '置', '适',
'什', '蛋', '师', '气', '你', '姐', '棒', '试', '总', '定',
'啊', '足', '级', '整', '带', '虾', '如', '态', '且', '尝',
'主', '话', '强', '当', '更', '板', '知', '己', '无', '酸',
'让', '入', '啦', '式', '笑', '赞', '片', '酱', '差', '像',
'提', '队', '走', '嫩', '才', '刚', '午', '接', '重', '串',
'回', '晚', '微', '周', '值', '费', '性', '桌', '拍', '跟',
'块', '调', '糕']
font_addr_data = dict(map(lambda x,y:[x,y],font1,font3))
font_price_data = dict(map(lambda x,y:[x,y],font2,font3))
return font_addr_data,font_price_data
唯一需要注意的就是,这里传进去的page,就是你直接请求当前页面返回的内容,比如
page = requests.get(url = url,headers = headers,proxies = get_ip()).text
你需要确保这里的page是正确包含内容的,如果是被403之后的页面或者是提示要输入验证码之类的页面是无法正确执行的。
那么到这里,我们就搞定了在每一页的字体文件都是动态加载的情况下如何爬取全部搜索页面的信息,之后只需要写一个循环爬去url_list中的全部URL,并使用pandas进行保存即可。
本文的分享就到这里,完整的代码我就不提供了,因为某点评网站的限制,大概率拿走也是不能用的,但是最关键的函数已经完整的发在文中了,复制粘贴就能使用。
如果你尝试去爬取过大众点评,会发现最难的不再是字体加密,而是捉摸不透的反爬机制,尤其是headers中参数的构造,cookie的破解,
推荐阅读
扫码回复「大礼包」后获取大礼
扫码加我微信备注「三剑客」送你上图三本电子书