
【Recall】MIND:阿里多兴趣网络模型
本篇论文 Multi-Interest Network with Dynamic Routing(MIND)是阿里巴巴搜索推荐事业部在召回领域方面的工作,发表于 ACM 28th。其提出的一种向量召回的方法,通过构建多个和 item 向量在同一向量空间的用户兴趣向量来表示用户的多个兴趣,然后通过这些兴趣向量去检索出距离最近的 Item,最终得到 TopK 个用户感兴趣的商品。
值得注意的是,18 年的 EGES 算法也是来自这个团队。
1. Introduction
用一个 User Embedding 无法捕捉用户的不同兴趣,因为必须将所有与用户不同兴趣相关的信息压缩到一个表示向量中。这样一来,所有与用户多兴趣相关的信息就会混在一起,导致召回阶段的 Item 检索不准确。
为了解决这个问题,作者提出了基于动态路由(Dynamic Routing)的多兴趣网络(Multi-Interest Network)MIND,用于解决召回阶段用户兴趣多样性的需求。MIND 中的多兴趣提取层利用动态路由将用户的历史行为自适应地聚合成可以表示用户不同兴趣的多个 Embedding。这样一来,用户的不同兴趣会被分开考虑,使得各方面的兴趣都能得到更准确的 Item 检索。
动态路由是 Hinton 在 2017 年提出的胶囊网络(CapsNet)中的一种训练方式,简单来说就是底层的胶囊需要决定怎么把自己的输出分配给高层次胶囊(注意是低层次具有分配权)。
对应到 MIND 里就是将用户行为序列分成多个簇,底层的行为簇作为向量输入,经过多兴趣提取层后基于用户的多种兴趣来得到用户多个特征向量。
2. MIND
先来看下网络架构,从下往上看,网络输入用户的行为序列簇(对用户行为进行聚类)和其他特征,,Item 簇(Item id、Category id、Brand id)经过 Embedding 层得到特征向量,然后经过平均池化层得到 Item Embedding,经过多兴趣提取层产生兴趣胶囊。将兴趣胶囊与用户行为嵌入进行串联,并将串联后的胶囊经过 ReLU 层得到 User Embedding。训练过程中,会额外引入一个标签感知的注意力层(Label-aware Attention)来引导训练过程。线上服务时,通过近似最近邻查找的方法利用多个用户表示向量来检索 Item 作为召回结果。
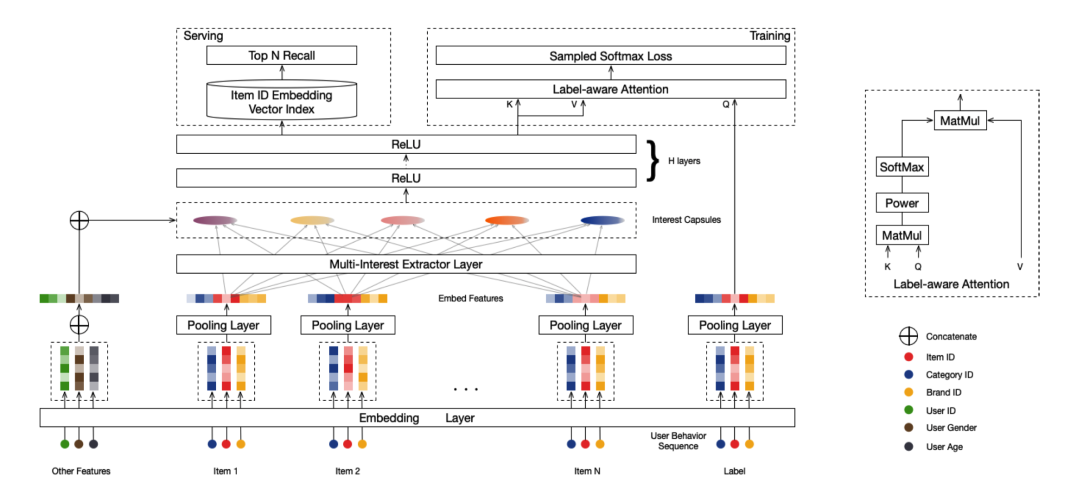
这里着重介绍下 Multi-Interest Extractor Layer 和 Label-aware Attention Layer。
2.1 Multi-Interest Extractor Layer
由于多兴趣提取层的设计受到胶囊网络中的动态路由的启发,我们在此重温一下基础知识。
2.1.1 Dynamic Routing
假设我们有两层胶囊网络,低级一层 ,高级一层。
动态路由的目标是以迭代的方式计算低层胶囊和高层胶囊之间的路由对数(logit) :
其中, 为需要学习转换矩阵。
计算出路由对数后,高层胶囊 j 的候选向量按所有低层胶囊的加权和来计算:
其中, 表示低层胶囊 i 到高层胶囊 j 的权重,计算方式如下:
最后,应用非线性压缩(squash)函数,得到高层胶囊的向量为:
的值初始化为零,路由过程通常需要重复三次才能收敛。当路由完成后,高层胶囊的值 是固定的,可以作为下一层的输入。
2.1.2 B2I Dynamic Routing
作者认为,原始的胶囊网络无法处理直接处理用户行为数据。因此,提出了从行为到兴趣(Behavior-toInterest,B2I)的动态路由来自适应地将用户的行为聚合到兴趣表示向量中,它与原始路由算法有三个不同之处:
「共享转换矩阵」:使用固定的转换矩阵而不是单独的转换矩阵。这样设计主要有两个原因:一方面用户行为长度可变,使用固定的转换矩阵具有泛化能力;另一方面,我们希望所有的兴趣胶囊都在同一个向量空间中。此时 计算如下:
「随机初始化路由对数」:由于共享了转换矩阵,所以路由对数初始化为 0 会增加收敛难度,所以作者利用高斯分布进行随机初始化; 「动态兴趣数量」:由于不同用户拥有的兴趣胶囊数量可能不同,所以作者引入了一种启发式规则来自适应调整不同用户的兴趣个数 K。这样做的好处就是减少计算和内存,K 值由以下计算:
其中 为与用户 u 交互的 Item 的集合。
整个算法流程如下:

2.2 Label-aware Attention Layer
多兴趣提取层的输出为多个兴趣胶囊,不同的兴趣胶囊代表用户兴趣的不同方面的兴趣偏好。然后作者便设计了基于标签感知的注意力层(Label-aware Attention Layer,图的右上图)使得 Item 可以自己选择不同胶囊的占比,这一块其实就是一个 Attention,Item 是 Q,兴趣胶囊既是 K 也是 V。基于 Item i 的用户 u 的输出向量为:
其中,p 为超参数可以调节 Attention 的分布。
2.3 Training & Serving
有了 User Embedding 和 Item Embedding,我们可以得到用户 u 和 item i 的交互概率:
所以 MIND 的目标函数为:
其中, 为 User 和 Item 的交互集合。
训练时采用 Adam 进行优化。
线上部署服务时会去掉 Label-aware Attention Layer,然后利用用户的历史序列与自身属性喂入到 MIND 中得到每个用户的多兴趣特征向量,然后用这些特征向量找出最近的物品。
3. Experiment
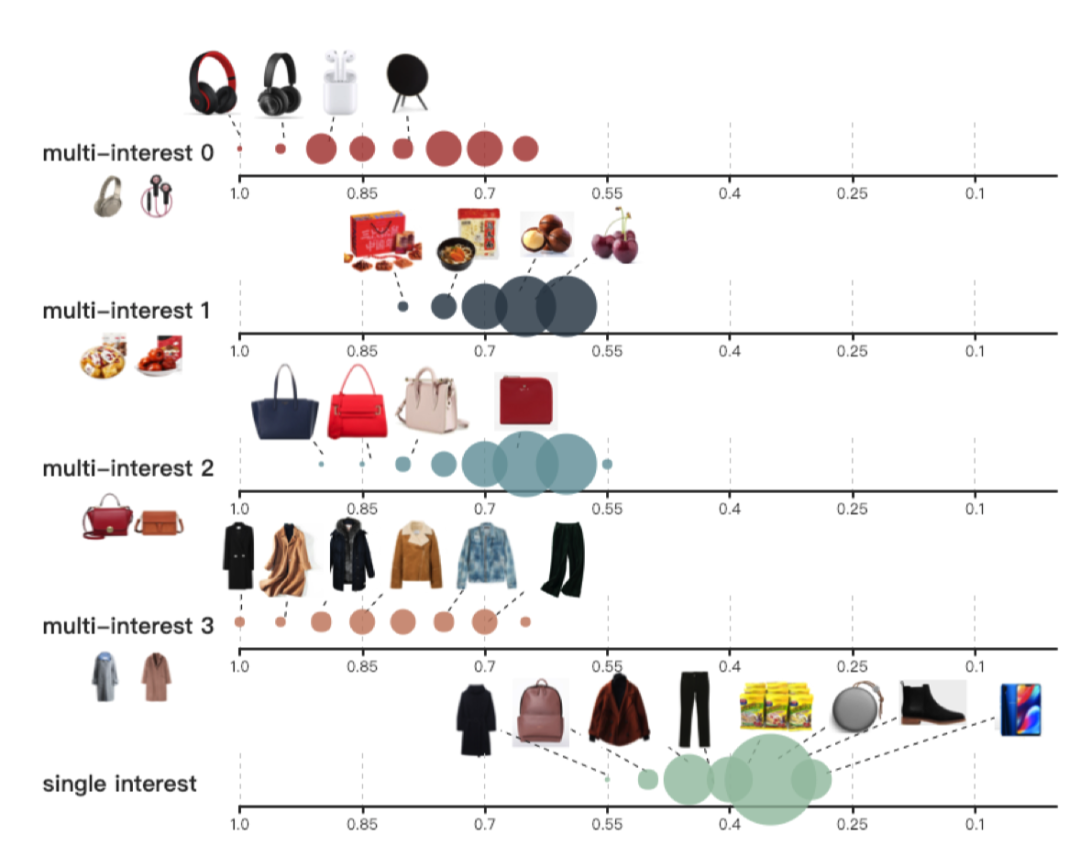
实验结果就不说了,放一些可视化的 Case。
这个是两个用户的兴趣和 Item 相关性的热力图:

这个图是多兴趣表示和表示的差别。每个兴趣由一个轴来展示,坐标是 Item 和兴趣之间的相似度。点的大小与具体相似度的 Item 数量成正比:
4. Conclusion
MIND 模型中最主要的创新是引入了胶囊网络的动态路由算法来捕捉用户的多个兴趣。
其中比较有意思的点可以借鉴一下:
自适应的兴趣数量设置:设置了 K 个兴趣上限,再根据用户行为数量来调整实际抽取出的兴趣数量; 使用 Label-aware Attention Layer:训练时,将用户下一个点击的 item 作为 query,而兴趣胶囊作为 key 和 value,做一个attention,并且可以通过超参 p 来对 attention 分布进行控制。在线上,直接使用每个兴趣向量分开进行召回。
5. Reference
当你打开天猫的那一刻,推荐系统做了哪些工作? Multi-Interest Network with Dynamic Routing