
为什么用了大牌工具后报表开发依然头痛
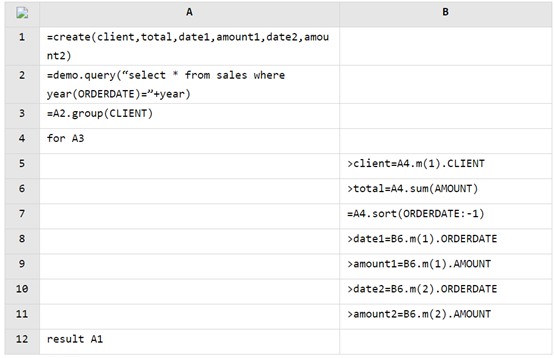
因为用错了报表工具,或者没有用对姿势。
没完没了的报表加剧头疼
集算器做数据准备写的快算的快

select code,max(risenum)-1 maxRiseDays from( select code,count(1) risenum from(select code,changeSign,sum(changeSign) over(partition by code order by ddate) unRiseDays from(selectcode,ddate,case when price>=lag(price) over(partition by code order by ddate)then 0 else 1 end changeSignfrom stock_record))group by code,unRiseDays)group by codehaving max(risenum) > 5
用开源的集算器去写则简单很多
| A | ||
| 1 | =connect@l("orcl").query@x("select * from stock_record order by ddate") | |
| 2 | =A1.group(code) | |
| 3 | =A2.new(code,~.group@i(price < price[-1]).max(~.len())-1:maxrisedays) | 计算每只股票的连续上涨天数 |
| 4 | =A3.select(maxrisedays>=5) | 选出符合条件的记录 |
2 列出每一个用户最近一次登录间隔
WITH TT AS(SELECT RANK() OVER(PARTITION BY uid ORDER BY logtime DESC) rk, T.* FROM t_loginT)SELECT uid,(SELECT TT.logtime FROM TT where TT.uid=TTT.uid and TT.rk=1)-(SELET TT.logtim FROM TT WHERE TT.uid=TTT.uid and TT.rk=2) intervalFROM t_loginTTTT GROUP BY uid
开源集算器的写法
| A | ||
| 1 | =t_login.groups(uid;top(2,-logtime)) | 最后2个登录记录 |
| 2 | =A1.new(uid,#2(1).logtime-#2(2).logtime:interval) | 计算间隔 |
一两个难的可能省不了多少时间,常年累月做项目,那么多复杂的计算场景如果都用开源的集算器,能省下多少时间呢
完全工具化应对没完没了
直接用润乾报表更便利
报表直接使用集算器结果做数据集,无缝对接

报表中还能使用集算器函数,提升开发效率
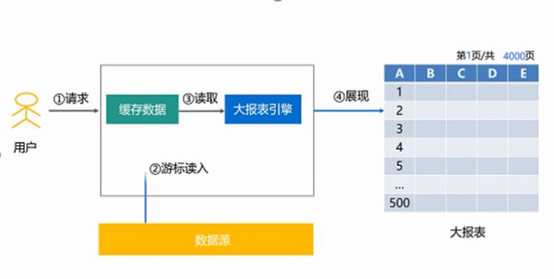
大报表功能,提升报表性能
感兴趣的小伙伴,请识别右侧二维码与我们联系
微信号|RUNQIAN_RAQSOFT
评论