
记 K8s 集群中 Flannel 遇到的两个问题

自建的 K8s 集群的坑不少, 尤其是到了 Node 数量越来越多之后, 问题也逐渐显露了出来, 博客主要介绍我们使用flannel之后遇到的两个问题以及解决方案, 问题其实不严重, 只是涉及到了底层的结构, 改动时候要小心.
问题 1 flannel 的 OOM 问题
官方给出的配置
下面这张图是官方的配置, 可以看到, 默认的资源设置仅给定了 50M 内存
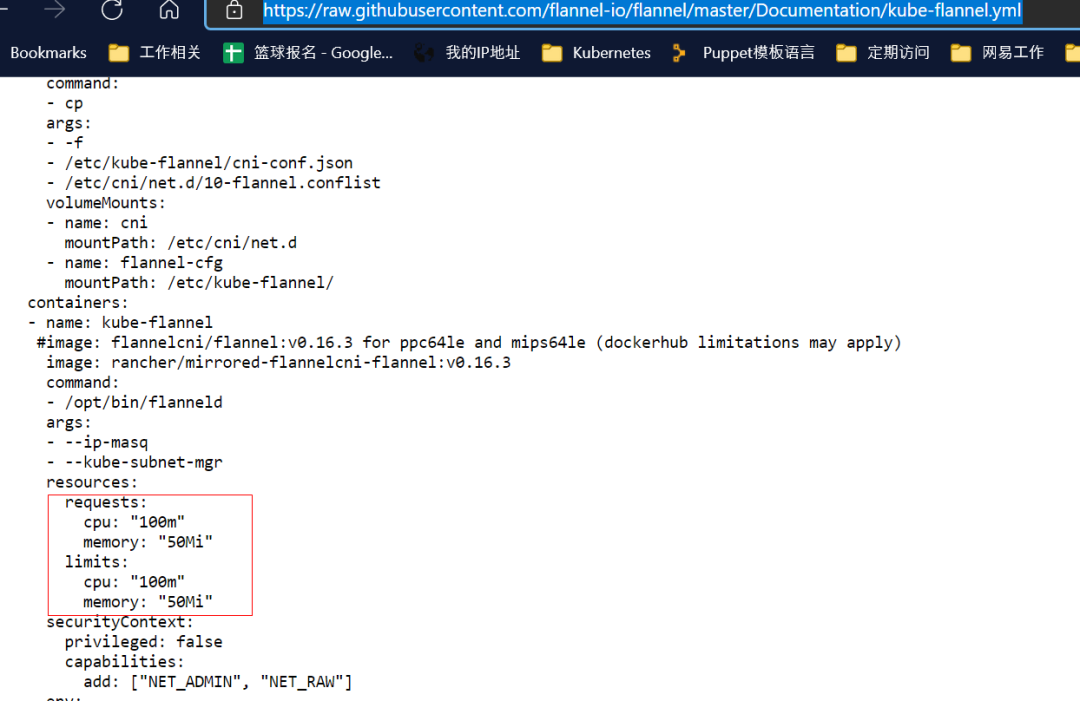
kubectl -n kube-system describe ds kube-flannel-ds-amd64
Limits:
cpu: 100m
memory: 50Mi
Requests:
cpu: 100m
memory: 50Mi
我们遇到的问题
当我们的机器数量超过 100 个以后, flannel 会以 OOM 的形式一直挂掉..
Feb 9 04:52:44 kernel: [37630249.323630] Memory cgroup out of memory: Kill process 33838 (flanneld) score 1653 or sacrifice child
通过Prometheus采集到的数据也可以看到, 容器的内存使用情况很不乐观:
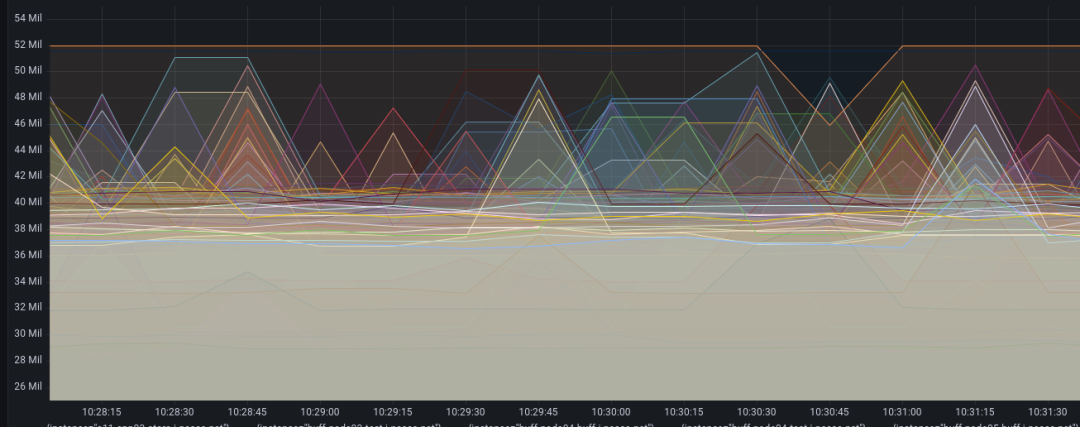
也没什么好的解决方案, 只能调整资源限制了.
问题 2 flannel 指定网卡问题
问题背景
因为我们使用的机器比较混杂, 机器的网卡也各不相同, 在开始搭建集群时就遇到了下面的问题.
> 我们虚拟机中的网卡, 仅有`10`开头的内网地址
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: eth0: mtu 1400 qdisc pfifo_fast state UP group default qlen 1000
link/ether 52:xx:xx:xx:77:0c brd ff:ff:ff:ff:ff:ff
inet 10.xxx.xxx.xxx/26 brd 10.xxx.xxx.xxx scope global eth0
valid_lft forever preferred_lft forever
> 物理机中的网卡, 既有`59`开头的公网地址, 也有`10`开头的内网地址, 并且网卡名为eth1
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: eth0: mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 8c:xx:xx:xx:xx:xx brd ff:ff:ff:ff:ff:ff
inet 59.xxx.xxx.xxx/24 brd 59.xxx.xxx.xx scope global eth0
valid_lft forever preferred_lft forever
3: eth1: mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 8c:xx:xx:xx:xx:38 brd ff:ff:ff:ff:ff:ff
inet 10.xxx.xxx.xxx/24 brd 10.xxx.xxx.xxx scope global eth1
valid_lft forever preferred_lft forever
这样带来的问题就是 flannel 通信问题, 如果多个网卡, 且启动时未指定, flannel 会找一个缺省的网卡, 对于虚拟机来讲没有关系, 但是对于物理机, flannel 会找到 eth0 这个外网网卡, flannel 使用错误的网卡发送数据, 抓包的数据可以看出 flannel 使用了公网的网卡发送内网数据, 会被交换机丢弃, 具体图片就不贴了, IP 属于公司机密.
具体的修改方法是确保 flannel 使用了正确的网卡, 需要在启动时指定参数--iface与--iface-regex: 我们的虚拟机数量少, 物理机数量多. 除了eth1, 还有bond1这种网卡名, 因此针对虚拟机, 统一将其eth0改名变成eth1, 而后指定了-iface-regex=eth1|bond1这样的配置, 对于后续增加物理机更友好.
问题到这里似乎就结束了, 但是随着 flannel 经常发生 OOM 重启, 暴露了我们的设置问题.
我们发现 flannel OOM 后无法正常重启
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-flannel-ds-amd64-54c5p 0/1 CrashLoopBackOff 1604 516d 10.xx.xx.xx xxxxx
kube-flannel-ds-amd64-cmczh 0/1 CrashLoopBackOff 89 388d 10.xx.xx.xx yyyyy
为什么一开始没出现, 但是重启又会发生呢, 问题出在了正则表达式上. K8s 在机器上启动容器时, 会创建虚拟的网卡. 这些网卡的名字类似veth17f90f70@if3, 这样网卡名称的也会被正则表达式匹配到, 导致 flannel 无法启动, 临时的解决方案就是把机器上的容器移走, vethxxx网卡会自动删除, flannel 也就自动恢复了.
当然根本的解决方案是修改正则配置: - -iface-regex="^(bond1|eth1)$" 使 flannel 更加精准的匹配网卡名称.
flannel 配置更新与验证
更新准备
因为不太了解 flannel 是否处理流量, 更新 flannel 时有点害怕, 直到看到了这里的架构.
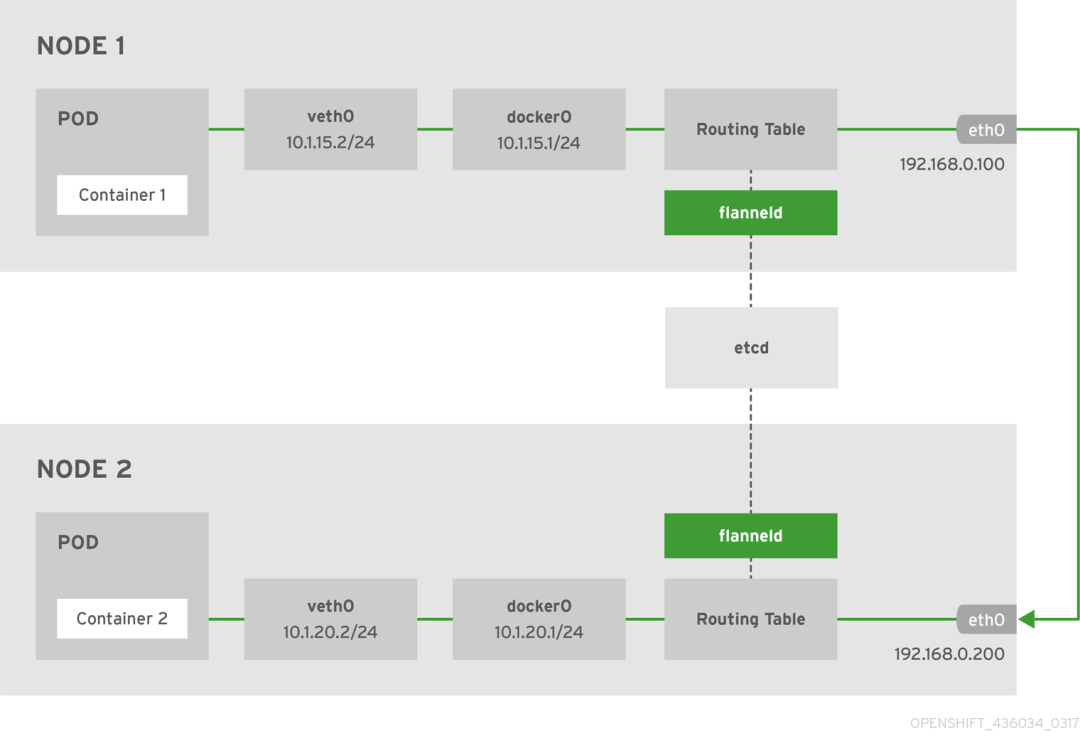
flannel 的功能主要是负责机器上路由表的修改, 也就是说, 只要不增删机器, flannel 挂掉也没关系, 因为路由表不需要修改.
更新
我们有 100 多台节点, 整个集群更新过程大概持续了 1 个多小时, 更新过程中服务完全正常.
验证可用性
内存使用情况:
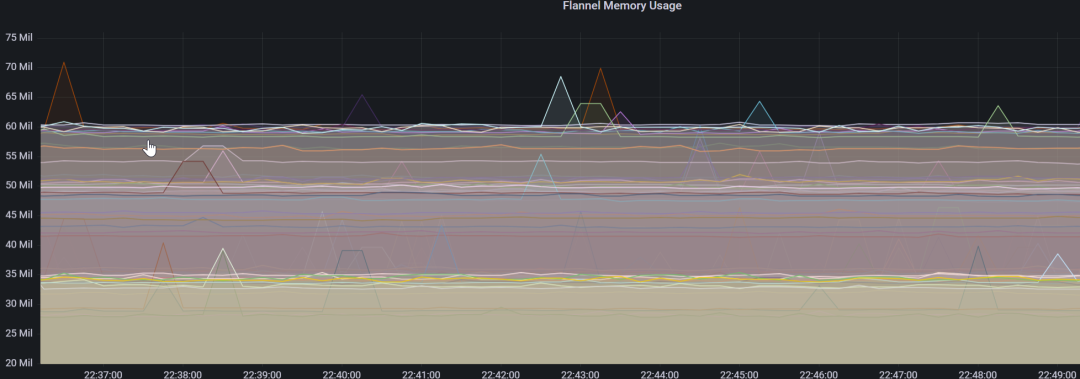
为了验证 flannel 是否可用, 我们将一台 node 删除, 观察到其他机器上的路由表也同步进行了修改.
总结
问题出现不可怕, 重要的是加好监控及时报警, 我们之前一直对 kube-system 的监控没有做到很好, flannel 一直启动不成功的问题是我检查时发现的, 使用别人提供的 yaml 文件前, 要注意下资源设置的, 类似 Prometheus 也有这种问题的, 它对内存的要求很高 预算充足就不要自建集群了, 有不少运维问题的, 万一出现一个解决不了的就很麻烦, 类似上次那篇文章: 记一次 Kubernetes 机器内核问题排查[1]
希望我们的经验能帮助到使用 K8s 的各位读者.
引用链接
记一次 Kubernetes 机器内核问题排查: https://corvo.myseu.cn/2021/03/21/2021-03-21-记一次kubernetes机器内核问题的排查/
原文链接:https://corvo.myseu.cn/2022/02/18/2022-02-18-%E8%AE%B0%E6%88%91%E4%BB%ACK8s%E9%9B%86%E7%BE%A4%E4%B8%ADflannel%E9%81%87%E5%88%B0%E7%9A%84%E4%B8%A4%E4%B8%AA%E9%97%AE%E9%A2%98/


你可能还喜欢
点击下方图片即可阅读

云原生是一种信仰 🤘
关注公众号
后台回复◉k8s◉获取史上最方便快捷的 Kubernetes 高可用部署工具,只需一条命令,连 ssh 都不需要!


点击 "阅读原文" 获取更好的阅读体验!
发现朋友圈变“安静”了吗?
