
手把手写Demo系列之车道线检测
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文是一篇从零开始做车道线检测Demo的教学式文章,从场景的定义到模型微调的输出,描述车道线Demo式例程中在每个环节需要做的工作,以及中途可能会遇到的各种问题。
根据任务需求,需要对其进行维度划分以便后续数据采集和模型评估。如果我们做一个全场景的车道线检测任务,需要考虑:
时间维度:白天、晚上
天气维度:晴朗、阴天、下雨
应用场景:高速道路、城市道路、乡镇小路
目标类别:长实线、双黄线、虚线等等
难易情况:道路清晰、数据遮挡、车道线磨损等
数据采集之前必须明确任务需求,在什么场景下能够解决什么样的问题?做Demo不可能一个模型适用所有自然场景。
根据设定好的需求场景,以视频录制的方式采集,一般需要以下几个步骤:
视频录制
间隔抽帧
相似性过滤
数据分类
数据筛选
视频录制过程中,如果使用的是USB等免驱的摄像头,直接调用OpenCV的VideoCapture接口打开即可;如果使用的是车载相机需要购买配套的解串套件或者根据摄像头的串行编码,对应完成解串功能获取Raw Data数据。
间隔抽帧这一步考虑到视频如果按照30FPS的帧率录制,在每一帧之间的变化很小,特征差异不大,将这些图片全部进行后续的标注会增加很大的人力成本,所以通常以5s/帧的方式进行帧间采用,推荐使用ffmpeg指令,简单方便,对于画质、采样率、采用周期等均可以参数调节:
ffmpeg -i out.avi -r 5 -f image2 image-%05d.jpeg
相似性过滤用于解决车辆反复行驶在相同路段情况、车速在行驶过程中有快有慢,甚至遇到红绿灯时停车小一分钟的情况,间隔抽帧后的数据中仍然有很多重复或者相似的图片。
图像之间的相似性度量方法很多,传统算法一般采用特征提取+距离度量,根据阈值判断;深度学习方法把上述两步封装在端到端的网络中。考虑到这里仅是预处理的环节,采用类似直方图统计、感知哈希、结构相似性等类似算法即可,针对车道线检测的任务, 关注的区域在地面上,所以需要将感兴趣区域限定在图像下方(下图绿色直线下方):

数据分类是为了匹配场景维度的定义,将不同场景或者类型的图片数据放在定义好的文件夹中,观测数据量在类别之间的平衡,有利于后续有针对性的填充数据。比如将城市道路的数据和高速道路数据分开存放,白天和晚上的数据分开存放等。
数据筛选的细致与否会影响到后续网络模型的收敛以及精度优劣,虽然神经网络具有较强的特征提取能力,对场景有一定鲁棒性,但是在训练数据中添加太多的噪声也会提升网络学习难度(毕竟写Demo阶段,并没有海量数据能够把噪声淹没),训练的数据希望是如下车道线清晰,光照良好的数据:

但是实际上自然场景采集的图片数据存在很多噪声,比如拥堵路段的车道线遮挡严重,如果车道线网络模型采用像素级分类的思路搭建,对以下图片的标注就比较困难;如果车道线网络模型上升到抽象的语义空间,根据上下文的环境信息预测车道线空间位置,下图倒也可以使用。

除了车道线被遮挡的问题,在城市路况中存在施工或很久未翻修的老路,道路线条磨损严重,很多情况人肉眼都无法区分,建议删除这一部分训练数据:

当然也有很多本来就没有车道线的路况,此类数据需要根据数据转换的程序来决定去留,在数据转换时仅少数代码未加判断会导致程序崩溃:

检查数据时还会遇到在拱桥下,进出隧道等光照昏暗或者曝光严重的情况,造成车道线辨别率降低,如下图所示:

当然你要问实际工程上如何解决这些问题,无外乎从软件角度怎么增加算法模型的鲁棒性;从硬件角度如何定制传感器接受更多光子以及优化ISP算法。
本次车道线检测的历程,我们采用实例分割的方式做逐像素点的分类。可以采用开源的标注工具,比如labelme,标注精灵等。
第一步:根据模型的不同,输入数据的类型也存在差异,这里我们采用划线的方式进行标注,如下图所示,因为是实例分割,不同的车道标注不同的类别:

如果采用labelme进行标注,生成的是json格式的标签数据,如下图所示,标签中以折点的形式存储:

第二步:使用labelme自带的功能函数转换成实例图等信息,其中包括原始图片,实例图,可视化图等:
第三步:由于搭建的网络如果输入原始图像、语义图像、实例图像三种,所以需要将json转换后的数据通过脚本生成TuSimple数据集的形式,得到如下形式,三个文件夹分别存放二值图,原始图,示例图,train.txt用于存放训练数据列表,val.txt用于存放验证数据列表:

基于深度学习的方法造轮子的成本一般很高,需要经历大量的模型修改、参数调节的反复试错过程。不仅对服务器硬件平台有较高的要求,也考验算法工程师自身的知识积淀。
如何快速高效的写Demo呢?
现有网络模型
开源数据集
自己数据微调
之前有篇文章具体聊过车道线检测的网络,大多数是基于像素的分割模型,也有一些基于检测方法的车道线检测,常用的开源模型相关论文如下(可以找小编要或者等后续上传云盘):

车道线的开源数据集有很多,比如:
Caltech
VPGNet
TuSimple
CULane
BDD100k
ApolloScape
CurveLanes
TuSimple数据集位于高速场景,天气晴朗,车道线较为清晰,适用于高速,高架等应用场景的Demo制作:

CULane数据集包含拥挤,黑夜,暗影等八种难以检测的情况,适合补充TuSimple数据集提升难例的精度:
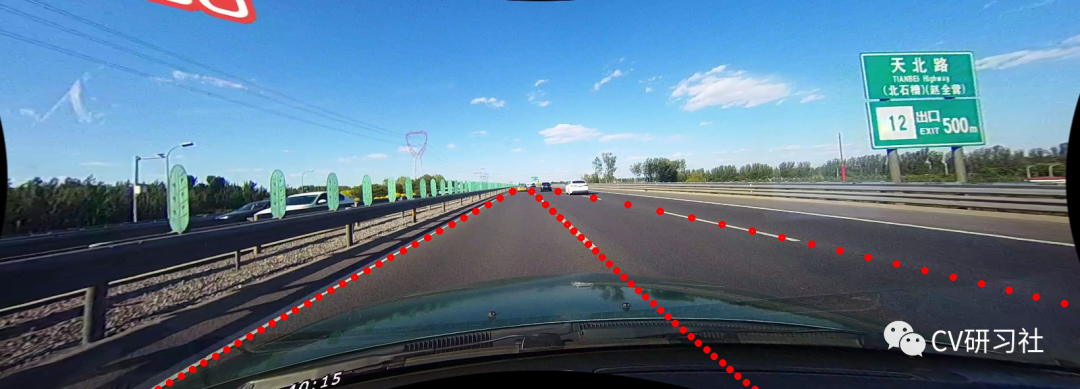
因为TuSimple和CULane数据量均不大,适合普通服务器或者本机上的预研式训练。推荐将两个数据集的数据统一进行模型训练,得到一份预训练的权重。
更为简单的方法即是下载开源模型提供的一些权重,省去了自己训练的环节,不过这样会大大降低模型修改的灵活度,现在的分割网络一般基于encoder-decoder的形式搭建,为了加速推理时间或者提供预测精度,通常会对开源网络做些修改:
采用轻量化模型替换特征提取网络;
减少上采样次数,替代掉全分辨率的输出;
增加ASPP或者Attention机制
模型结构变化后就无法使用源码中提供的预训练权重,所以后续微调的灵活度出发,自己用开源数据集做训练的方法最佳。
Fintune阶段一般就两步:
加载预训练模型
加载自己的数据继续训练
加载预训练模型时,可以考虑是否需要冻结encoder层或者只释放最后几层进行参数更新,当然也可以不冻结模型,全部进行微调。根据开源数据和自己数据的比例及差异而决定:
开源数据量远大于自己的数据并且类型差异不大,建议只释放网络后面的几层进行微调;
开源数据量仅比自己的数据多一个量级但是类型差异较大,建议参数全部参与训练;
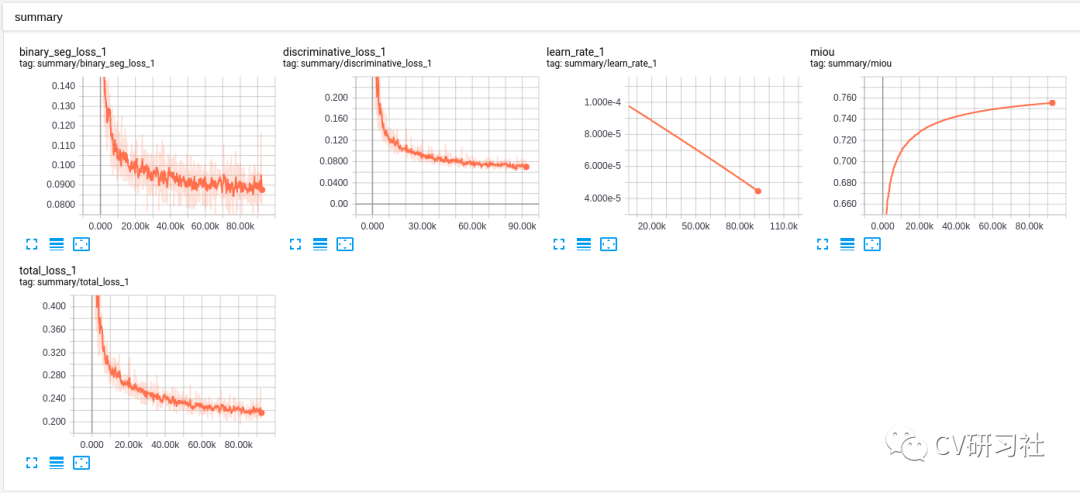
加载自己的数据训练,期望是损失不断下降最后收敛,不过大多数时候属于——期望很美好,现实很骨感。可能会遇到:
实例损失居高不下;
训练开始梯度爆炸;
模型震荡不收敛等;
可以尝试以10倍递减降低学习率;修改学习率衰减策略;修改网络实例分割部分的聚类参数;最最最重要的是检查数据和标签
由于选用的车道线检测网络的实例分割部分会根据点到不同车道线的距离来迭代拉近类内距离,放大类间距离,所以如果数据中的不同车道线在远处交织在一起,就很容易造成实例损失的异常,如下图所示:

通过进一步过滤标签数据,或者做截断,通过后处理的曲线拟合来弥补前方损失的一小段车道。
最后训练收敛后用验证集做评估,或者直接拉到路上进行测试,毕竟做Demo,针对实际场景不好的数据再收集回来做数据填充迭代。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~