
【Python】python批量模糊匹配技术解决用户-配变匹配问题
用户表中保存着用户公司名,例如:四川某某XX家具有限公司
配变表中保存着配变信息,例如:成都XX家具有限公司(专变)
现在的业务需求是在数以万计的配变表中,找到与用户最匹配的配变信息,生成匹配表。

整个业务逻辑可以提炼成以公司名称或地址为主的字符串的模糊匹配问题,我们用python完成。
使用编辑距离算法进行模糊匹配
进行模糊匹配的基本思路就是,计算每个字符串与目标字符串的相似度,取相似度最高的字符串作为与目标字符串的模糊匹配结果。
对于计算字符串之间的相似度,最常见的思路便是使用编辑距离算法。
编辑距离算法,是指两个字符串之间,由一个转成另一个所需的最少编辑操作次数。允许的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
一般来说,编辑距离越小,表示操作次数越少,两个字符串的相似度越大。
遍历每个被查找的名称,计算它与数据库所有客户名称的编辑距离,并取编辑距离最小的客户名称。
具体代码可参考:
https://leetcode.cn/problems/edit-distance/solution/bian-ji-ju-chi-by-leetcode-solution/
fuzzywuzzy
fuzzywuzzy库就是基于编辑距离算法开发的库,而且将数值量化为相似度评分,会比我们写的没有针对性优化的算法效果要好很多,可以通过pip install FuzzyWuzzy来安装。
Python提供fuzzywuzzy模块,不仅可用于计算两个字符串之间的相似度,而且还提供排序接口能从大量候选集中找到最相似的句子。
两个模块:fuzz, process,fuzz主要用于两字符串之间匹配,process主要用于搜索排序。
fuzz.ratio(S1,S2)直接计算S1和S2之间的相似度,返回值为0-100,100表示完全相同;
fuzz.partial_ratio(S1,S2)部分匹配,如果S1是S2的子串依然返回100;
fuzz.token_sort_ratio(S1,S2)只比较S1,S2单词是否相同,不考虑词语之间的顺序;
fuzz.token_set_ratio(S1,S2)相比fuzz.token_sort_ratio不考虑词语出现的次数;
process.extract(S1, ListS,limit=n),表示从列表ListS中找出Top n与S1最相似的句子;
process.extractOne(S1,ListS),返回最相似的一个
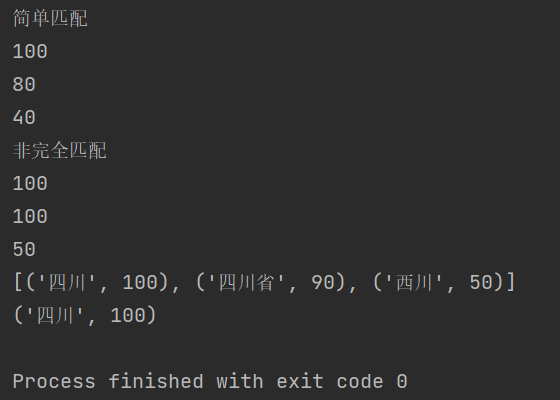
from fuzzywuzzy import fuzzfrom fuzzywuzzy import processprint("简单匹配")print(fuzz.ratio("四川省","四川省"))print(fuzz.ratio("四川省","四川"))print(fuzz.ratio("四川省","西川"))print("非完全匹配")print(fuzz.partial_ratio("四川省","四川省"))print(fuzz.partial_ratio("四川省","四川"))print(fuzz.partial_ratio("四川省","西川"))choices = ["四川省", "成都市", "西川", "四川"]print(process.extract("四川", choices, limit=3))print(process.extractOne("四川", choices))
from fuzzywuzzy import processimport pandas as pd# 通用模糊匹配函数def fuzzy_merge(df_1, df_2, key1, key2, threshold=90, limit=2):""":param df_1: the left table to join:param df_2: the right table to join:param key1: key column of the left table:param key2: key column of the right table:param threshold: how close the matches should be to return a match, based on Levenshtein distance:param limit: the amount of matches that will get returned, these are sorted high to low:return: dataframe with boths keys and matches"""# 匹配参考表s = df_2[key2].tolist()# 待匹配结果表m = df_1[key1].apply(lambda x: process.extract(x, s, limit=limit))# 把算出来的结果放到了df_1的matches列df_1['matches'] = m# 对extractOne方法的完善,提取到的最大匹配度的结果并不一定是我们需要的,所以需要设定一个阈值来评判,这个值可以是90# 第一个‘matches'字段返回的数据类型,参考一下这个格式:[('四川省', 90), ('成都市', 0)]m2 = df_1['matches'].apply(lambda x: [i[0] for i in x if i[1] >= threshold][0] if len([i[0] for i in x if i[1] >= threshold]) > 0 else '')# 把最佳的符合条件的匹配信息处理到df_1的matches列df_1['matches'] = m2return df_1user_values = pd.read_excel('用户名.xlsx')PB_values = pd.read_excel('配变.xls')df = fuzzy_merge(user_values, PB_values, 'user', 'PBname', threshold=80)df.to_excel('结果.xlsx')
当然我们也可以将相似度最高的n个匹配结果都加入结果列表中,后期再人工筛选。
from fuzzywuzzy import processimport pandas as pddata = pd.read_csv("配变.csv", encoding="gbk").astype(str)find = pd.read_csv("用户名.csv", encoding="gbk").astype(str)users = data.name.to_list()result = find.name.apply(lambda x: next(zip(*process.extract(x, users, limit=3)))).apply(pd.Series)result.rename(columns=lambda i: f"匹配{i + 1}", inplace=True)result = pd.concat([find, result], axis=1)result.to_excel('结果.xlsx')
此时就获得了我们要想的top3匹配数据。
使用Gensim进行批量模糊匹配
Gensim支持包括TF-IDF,LSA,LDA,和word2vec在内的多种主题模型算法,支持流式训练,并提供了诸如相似度计算,信息检索等一些常用任务的API接口。
如果数据库达到几万级别,如果依然采用编辑距离或fuzzywuzzy暴力遍历计算,预计几个小时也无法计算出结果,但使用NLP神器Gensim仅需几秒钟,即可计算出结果。
import pandas as pdimport jiebafrom gensim import corpora,similarities,modelsdata = pd.read_csv("配变.csv", encoding="gbk").astype(str)find = pd.read_csv("用户名.csv", encoding="gbk").astype(str)# 对原始的文本进行jieba分词,得到用户名称的特征列表data_split_word = data.name.apply(jieba.lcut)# 建立语料特征的索引字典,并将文本特征的原始表达转化成词袋模型对应的稀疏向量的表达# 这样得到了每一个用户名称对应的稀疏向量(这里是bow向量),向量的每一个元素代表了一个词在这个名称中出现的次数。dictionary = corpora.Dictionary(data_split_word.values)data_corpus = data_split_word.apply(dictionary.doc2bow)# 将被查找的数据统一由小写数字转换为大写数字(保持与数据库一致)后,作相同的处理,即可进行相似度批量匹配trantab = str.maketrans("0123456789", "零一二三四五六七八九")find_corpus = find.name.apply(lambda x: dictionary.doc2bow(jieba.lcut(x.translate(trantab))))# 构建相似度矩阵tfidf = models.TfidfModel(data_corpus.to_list())index = similarities.SparseMatrixSimilarity(tfidf[data_corpus], num_features=len(dictionary))# 同时获取最大的3个结果result = []for corpus in find_corpus.values:sim = pd.Series(index[corpus])result.append(data.name[sim.nlargest(3).index].values)result = pd.DataFrame(result)result.rename(columns=lambda i: f"匹配{i + 1}", inplace=True)result = pd.concat([find, result], axis=1)result.to_excel('结果.xlsx')
总结
本文介绍了三种可以模糊匹配用户和配变的方法,编辑距离以及基于编辑距离的fuzzwuzzy比较容易理解,但当数据库量级达到万条以上时,效率极度下降,特别是数据量达到10万级别以上时,跑一整天也出不了结果。通过Gensim计算分词后对应的tf-idf向量来计算相似度,计算时间由几小时降低到几秒,而且准确率也有了较大幅度提升,能应对大部分批量相似度模糊匹配问题。
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑
机器学习交流qq群955171419,加入微信群请扫码