
2021中国胡润百富榜揭晓:中国首富竟是他!!!
回复“书籍”即可获赠Python从入门到进阶共10本电子书
2021中国胡润百富榜
前几天看到一个有意思的榜单“中国胡润百富榜单”,今年是胡润研究院自1999年以来连续第23次发布“胡润百富榜”,上榜门槛连续第九年保持20亿元。今天带大家分析看看中国都有哪些大牛!
数据采集
数据来源:https://www.hurun.net/zh-CN/Rank/HsRankDetails?pagetype=rich
打开页面如下 我们需要采集前 2000 名榜单人员的基本信息,分析过程十分简单:
我们需要采集前 2000 名榜单人员的基本信息,分析过程十分简单:F12 打开开发者工具。CTRL + R 刷新页面,就可以看到抓到的数据包。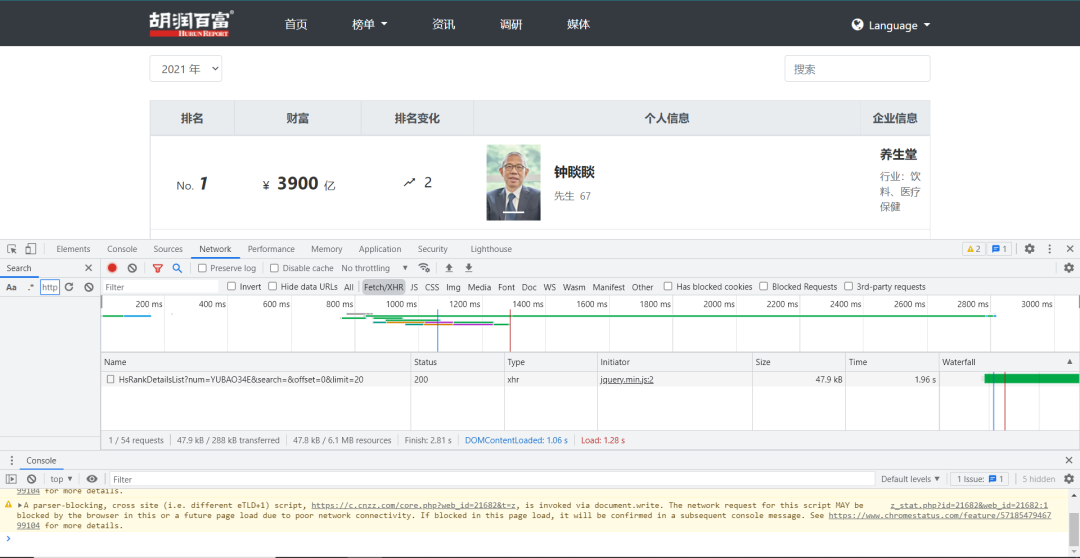
https://www.hurun.net/zh-CN/Rank/HsRankDetailsList?num=YUBAO34E&search=&offset=0&limit=20
采集的链接中包含两个主要参数,
offset:0,页码limit:20,限制数据量最多 20 条
代码抓取的的时候暴力点,直接设置 limit=2000,即一次请求 2000 条用户数据,不用分页请求,思路有了,开始撸代码!
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36'
}
params = {
'num': 'YUBAO34E',
'offset': 0,
'limit': 2000
}
url = 'https://www.hurun.net/zh-CN/Rank/HsRankDetailsList'
page_text = requests.get(url=url, headers=headers, params=params).json()
page_text
 有数据输出,并且数据量看起来也没问题,下一步开始解析需要的字段。代码较多这里就不展示了,
有数据输出,并且数据量看起来也没问题,下一步开始解析需要的字段。代码较多这里就不展示了,文末有完整源码获取方式!
由于数据包中的信息确实较多,我只提取了部分需要的字段,大致如下: 由于后面需要做地图,需要省份信息,所以对出生地字段切割一下,将省份提取出来,图片字段同样也要做一些处理,主要是由于我用
由于后面需要做地图,需要省份信息,所以对出生地字段切割一下,将省份提取出来,图片字段同样也要做一些处理,主要是由于我用 Tableau 做图的原因,如果大家可视化方式不同,完全可以跳过这一步!
df['birth_place_split'] = df['birth_place'].str.split('-')
df['birth_place_split'] = df['birth_place_split'].apply(lambda x:'' if len(x) == 1 else x[1])
df['photo_split'] = df['photo'].apply(lambda x:x.split('/')[-1])
df.head()
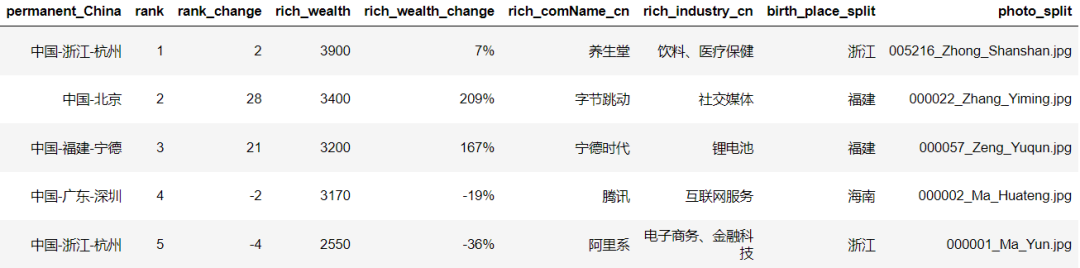 最后将处理好的数据集保存到本地。
最后将处理好的数据集保存到本地。
可视化
可视化工具:Tableau 2021.3。
百富榜TOP10
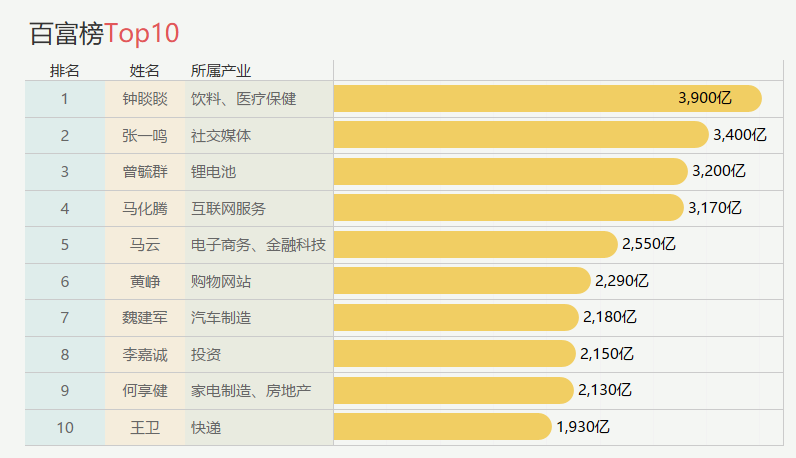 由于平时不怎么关注这些内容,第一次看这个结果竟发现前十的只认识 5、6 个。我一直还以为首富应该是“两马”中的一个,现在一看确实是我跟不少时代了。。饮料、医疗保健也这么赚钱的哇!
由于平时不怎么关注这些内容,第一次看这个结果竟发现前十的只认识 5、6 个。我一直还以为首富应该是“两马”中的一个,现在一看确实是我跟不少时代了。。饮料、医疗保健也这么赚钱的哇!
百富榜年龄分布
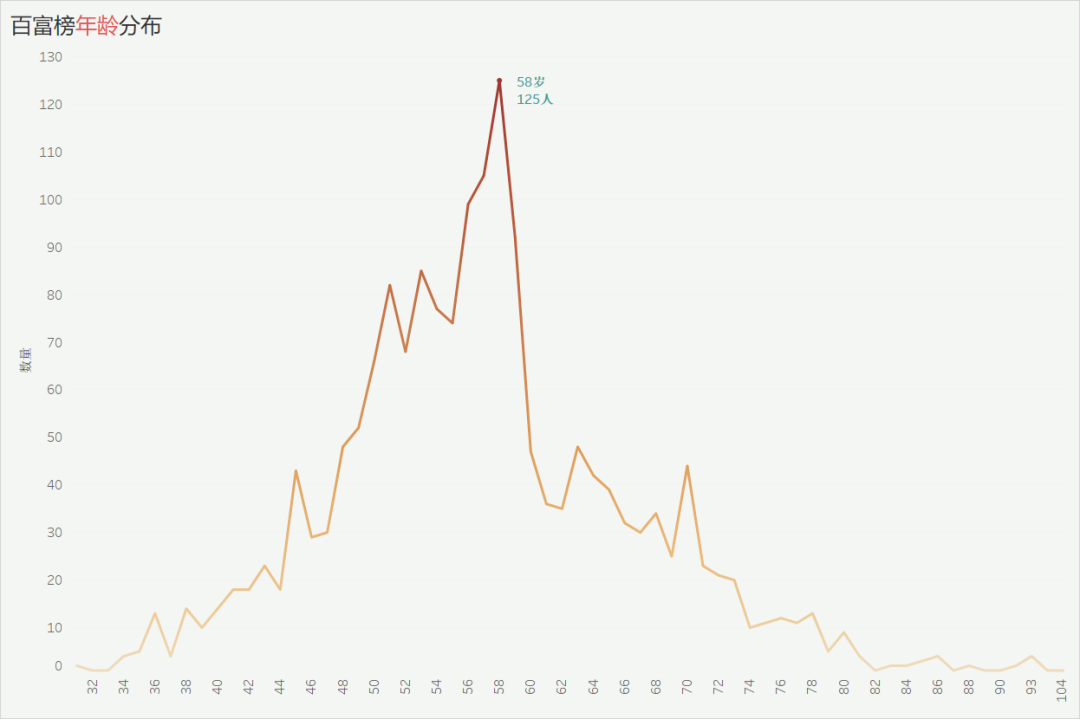 榜单上的 74% 大佬年龄分布在45~70岁之间,其中58岁的有125人,大部分都是中年。
榜单上的 74% 大佬年龄分布在45~70岁之间,其中58岁的有125人,大部分都是中年。
百富榜出生地分布
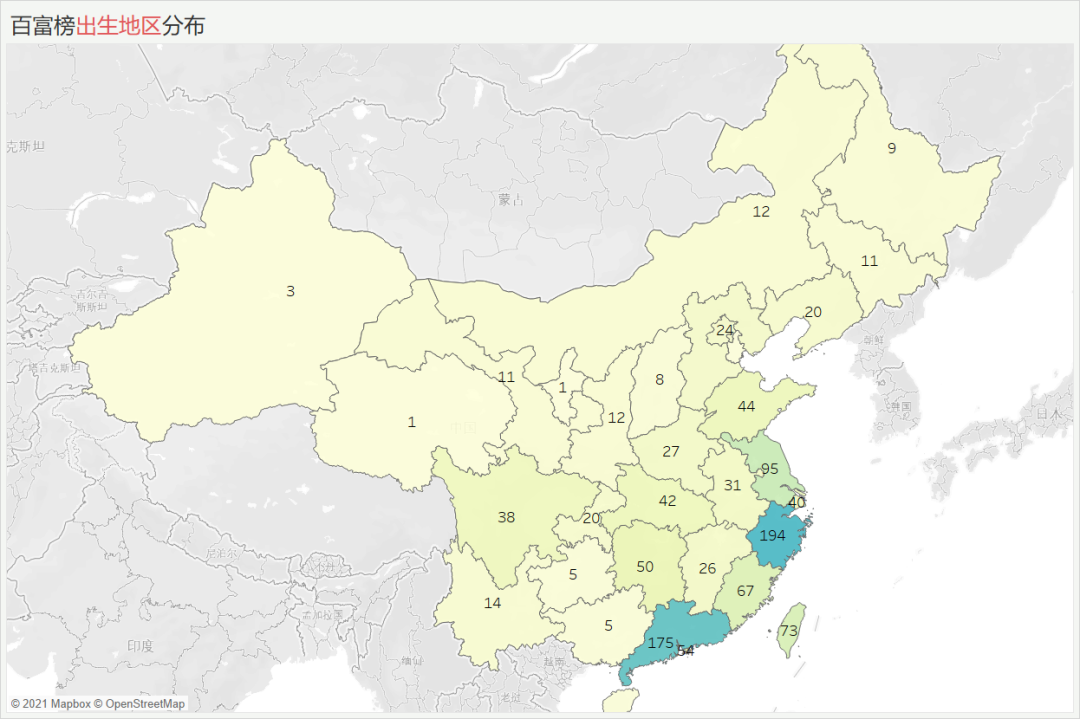 出生地分布前三名分别是:浙江、广州、江苏。
出生地分布前三名分别是:浙江、广州、江苏。
百富榜热门产业
 热门产业主要还是房地产、投资、医药、食品、化工等,确实都是大佬们玩的东西。
热门产业主要还是房地产、投资、医药、食品、化工等,确实都是大佬们玩的东西。
合成看板
最后做个汇总性的看板,加点联动效果。

时间比较赶,加上最近确实比较忙,排版什么的也没细做,大家看个乐就好,哈哈。

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~
