
一个价值560万的经验教训感触
在软件工程中什么是我们的黄金生命线,是持续的业务增长,是不断的需求吞吐量,是高效的生产运维,还是健壮的代码质量亦或是超强的生产安全意识。其实什么都是,也什么都不是,因为这几个纬度不是割裂的,而是彼此之间相互关联或者说是相互影响的。

(图1 当前现状)
通过1022的这次生产事故,相信大家都会有一些反思,最近一直在埋头写长城的代码,一些事情还没来得及整理,借着这次机会将之前的一些生产安全经验做一个整理。
一、生产变更流程1.1 变更前
虽然我们现在的应用有级别划分,但是不具备任何意义(大部分都是P0)。对于不同级别的应用上线变更要有不同的制度。对于非核心链路上的应用变更应做到小组内评审,而核心链路的黄金应用最起码要做到C3级评审。变更前要做两件事:
准备好变更工单
通常变更工单主要描述本次变更意图和影响范围,同时会把变更执行过程和应急回滚操作进行描述。变更工单上的每一步操作都要可执行,写变更工单是一件很耗时的事情,如果我们不做好变更周期的把控,按照现在的上线节奏来说,变更工单太重了,并不适用,但是可以作为参考。(敏捷开发建议是两周一迭代,我们现在是一周两迭代)

checklist要把本次相关准备工作进行陈述并且要说明上线后的验证方案和具体操作步骤。变更步骤和回滚步骤都是要可执行,对于业务团队来说基本都是通过操作发布平台或者配置中心,相对简单一些,而对于基础团队来说可能要把操作脚本贴上去。最坏影响分析是最重要的,体现了对本次变更的认知程度。执行人一般一次变更不会交给同一人执行,即使是同一个人也要有对应的复核人对变更过程进行复核,审核人是对最终结果进行审核确认,这不是一个卡点流程,只是逻辑上的职责划分。备注部分的架构师主要对工程质量负责,组长将承担整个生产变更的责任。这两个角色是最贴近生产的直接负责岗位。
变更评审
变更评审是对变更工单内容进行评审,通常变更评审是跨团队甚至是跨部门的,参与方均是该变更的相关方,对变更工单进行最终确认。通常变更评审会问几个固定的问题:
1、比如新需求的影响范围是什么?一旦发生影响如果兜底处理?
2、是否达到了生产变更的准入标准?(单测是否达标、案例回归是否通过、组内是否完成代码评审等)
3、变更周期多久?如果做到版本兼容和生产灰度验证?
4、监控措施是否具备?
1.2 变更中
变更中最重要的是执行人的操作和对应的监控告警,很多时候生产故障都是由于执行人的操作失误造成的,所以会有复核人对每一步操作进行复核,现阶段我们存在较高操作风险应该是NG的流量上线下和发布操作分区不匹配的话会造成有损(收银台)。同时发布过程中要时刻观察生产监控,由于一些小业务量或者一些批处理操作在短期内不容易暴露问题,所以一般发版会采用灰度跨天发布的方式,拉长观察周期。
1.3、变更后
变更结束后要想完整闭环需要对上线工单中checklist上线检查部分进行全量验证,同时要得到产品经理(需求提出方)的最终确认才能关闭工单。
二、业务值班制度对于飞宇反馈的关于日常工作中开发时间被各种排查生产问题所支配,无法按照自身的计划完成开发(之前刘莲也反馈过)。对于这种场景需要先梳理我们的问题集中点,把共性问题找出来制定FAQ,让问题方自行解决。对于纯业务问题直接转到运营和产品经理处,进行解答。也就是问题边界划分要明确。总结如下:
1、FAQ:提供共性问题解答
2、边界划分:纯业务问题直接分配给一线人员(运营或产品经理)
3、工具开发:对于一些日常排查问题的执行手段,可以沉淀下一些小工具,辅助大家快速排查问题。
4、制定值班制度(轮岗值班):可以以天或者以周为单位统一分配给一名同事负责排查小组问题,值班同事不负责需求开发等任务,只负责组内问题解答。这种制度的好处是可以让整个小组人员互相了解彼此负责的项目,提高备份能力。难点在于前期需要很长时间的过度,因为想让一个人了解全组项目还是有一定的投入的,而且对于团队内不断加入的新人也是一种挑战。
这个话题太大了,只说最近了解的一些项目通病吧。
3.1、日志规范
目前很多项目的日志打印没有统一的规范,日志格式和日志级别管理混乱,甚至部分应用的日志输出到了tomcat的catalina.out文件中,规范的日志输出可以大大提升问题排查效率。建议规范如下:
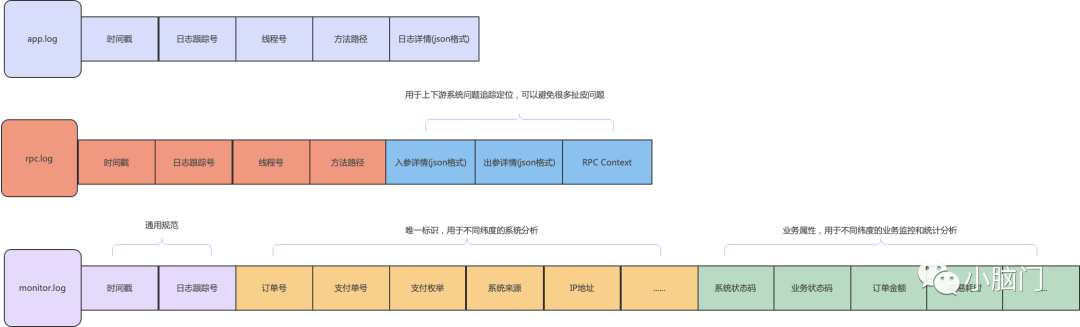
对于error日志可以单独分出一个文件,这点不强制。对于稳定的业务rpc.log可以设置为debug级别,降低生产资源浪费。
3.2、工程质量提升
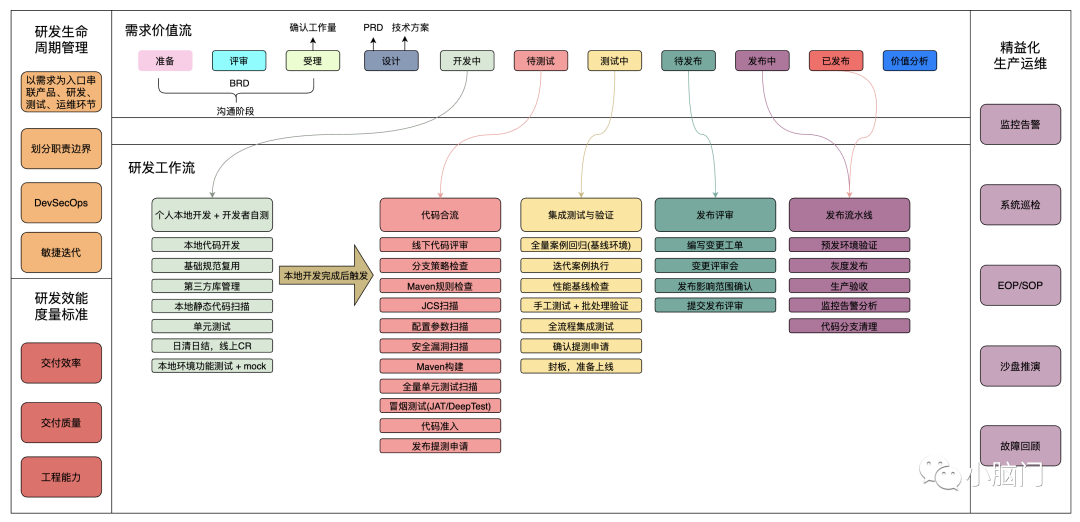
同业中的科技公司都在进行数据化转型,映射到我们软件工程部分其实还是在工程质量效能提升环节进行改革。也就是说在数字化的时代,研发效能已经成为一家科技公司的核心竞争力。这部分是一个巨大的、长期的投入工程。我们部门现在其实已经具备了工程效能提升的前置条件,也就是一些基础平台的支撑能力(行云、JDOS、SGM、Digger、EasyOne、DeepTest、JCI等等),但是我们现在最缺的是技术人员对效能的认知和决定攻坚这件事的勇气。
3.3、故障经验沉淀
近期发现我们的技术同事对于故障复盘不是很重视,其实每一次故障复盘都有很多值得我们学习的东西,说句不中听的话,我们是在消耗公司的资源在增长自己的经验。每一次的故障复盘都应该是深刻的,且能互相传播学习的。首先要有一份深刻的故障报告,建议可以参考以下模板:
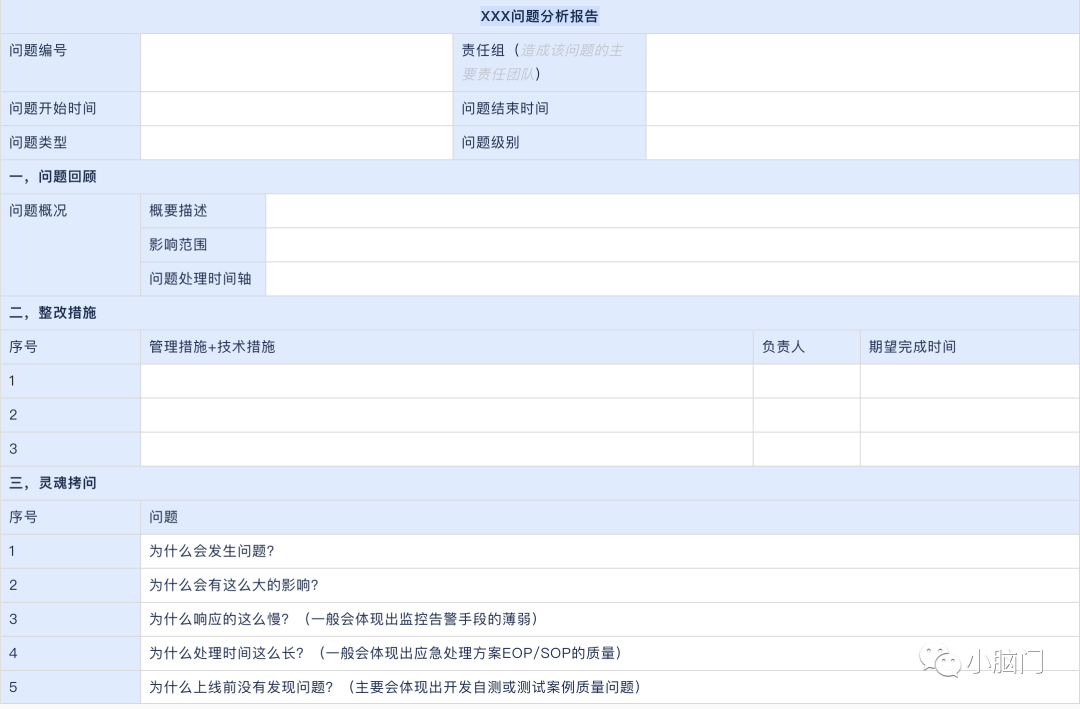
对于部门的生产故障要周期性的讨论分析,同时对沉淀下来的一些知识点要已问卷调查的形式,不定期做全员抽查考核,保证知识积累的传递。
3.4、监控告警梳理
目前很多有价值的监控告警都被淹没了,这块没有太多好说的,就是需要对现有的监控告警进行一遍梳理,然后划分级别,对于不同级别告警配置不同通知方式,每种异常都要有配套的应急处理手段,且团队成员都要具备执行能力。这块是大家都能够意识到的问题点,不做过多分析,后续排期整改就是。(将会放到工程效能项目中跟进)
四、单元化部署廊坊机房断电演练失败反思:由于前期没有深入参与,对于细节不甚了解,但是通过该事件的结果足以暴露出我们系统存在各种各样的问题,机房隔离这是金融机构尤其是一家金融科技公司,应具备的最基本的业务连续性保障能力之一。甚至科技司会对一些金融基础设施(比如网联、银行)周期性的抽查演练。
4.1、机房等比建设
机房等比建设是说每个IDC要具备同样的服务能力,一般是指基础资源要对等,应用服务要全面,但是很难做到每个机房完全一致,这里就要看具体的情况了。从SA的角度要保证每个机房的服务器资源最少满足统一的基线标准;网络带宽要足够且有固定的冗余,用于承接容灾能力;生产区域划划分面要保持强一致性,因为不同的生产环境规划实际上对业务部署和组件搭建是有影响的,所以环境划分要强一致,比如DMZ区域划分、生产区防火墙异构策略、IPS流量清洗、WAF/HIDS等安全策略、运管区到生产区访问策略等。
而对于应用来说每个机房都要提供同样的服务能力,且有一定的冗余可以保证跨机房容灾。直白点说,理论上每个机房都要部署自己的服务,并且规划出一定的冗余处理能力。
4.2、应用平等计划
平等计划需要从多个角度来理解,从应用部署角度来说:
每个应用单中心部署最少3个节点,多点多活。
多个中心部署应用数量应该相同,保证服务能力一致。
每个应用应该均匀离散在不同基础设施上(应用不能在同一个物理机、机柜、LEAF节点上,避免单点问题)
从服务采购层面来说:
网络专线提供商不能使用一家服务(移动、联通、电信应该都具备)
服务资源、网络设备采购最少需要俩家服务商(华为、思科等)
安全策略不能单一,需要多策略平等生效。比如防火墙要异构不能同构。
其他纬度忽略......
4.3、单元化部署
单元化部署是为了边界清晰管理,可以提升生产运维能力。对于复杂业务场景来说最难的是单元边界的划分和后续把控。该场景在腾讯(财付通)内部有比较成功的落地案例,财付通早期是按照支付渠道实现单元化部署的,从流量入口到核心业务处理程序按照接入渠道(银行渠道)划分成不同的Set单元,每个单元里部署着最小业务单元,通过管理每个Set实现灵活的生产运维。Set化的实现除了要做好单元边界划分之外还需要一些配套的基础工具支撑,比如一个好的网关服务、简洁的Set单元操作平台等。
以上说的这几点是要推行单元化部署的前置基础条件,需要做好提前分析再落实。
五、业务闭环业务闭环是业务连续性的重要体现,对于实时交易链路(一般是全链路RPC)来说通过处理异常失败是可以做到业务闭环的,但对于一些异步场景,或者依赖数据最终一致性的场景是需要有一套业务闭环程序负责检查和兜底处理的。比如差错系统,差错系统通常只有两大主要责任,第一是负责发现差错业务,也就是存在业务状态不一致、交易业务异常阻断等场景;第二是执行差错异常兜底方案,比如自动化的冲正、补偿查询、统一关单等。部分差错系统还会提供一些数据异常导出等能力。1022事件也暴露了我们缺少一个交易状态比对的系统,这点也得到了大家的共识,后续可以考虑补充这块缺失的能力。
业务闭环还有一个重要的考核指标,就是强依赖和应急处理措施。对于交易链路的强依赖项(阻断业务项)要有兜底方案,优先是系统兜底,如果系统无法实现自动化,需要人工兜底。人工兜底就要依靠应急处理措施的可执行和运维人员的操作时效性了。比如数据库挂了有缓存,缓存又分R2M和JIMDB主备,这就是一个很好的数据源弱依赖场景。比如配置中心DUCC,很多降级操作都是通过DUCC下发配置,如果DUCC挂了我们还有什么其他的手段下发配置吗?如果没有,那么我们就是强依赖DUCC,当然DUCC一般不作为交易链主链路的强依赖。
六、重保常态化未完待续...(一些经验会同步给洪潘,纳入他的项目中体现)
总结:最后希望我们大家对生产安全意识要有一定的提升,同时也应该下一些勇气去改变,不要再以需求多,每天都有问题排查来作为牺牲质量,降低生产安全的借口了。

(图2 健康状态)