
面试官问:C#的值类型和引用类型的存储结构?
.NET大牛之路 • 王亮@精致码农 • 2021.08.21
我们知道,程序运行时,它的数据是存储在内存中的。当我们的程序访问某个变量时,编译器负责把人们可以理解的变量名转换为处理器可以理解的内存地址,处理器通过内存地址找到内存中的存储单元,然后读取其中的数据。
运行中的 .NET 应用程序使用两个区域来存储数据:栈和托管堆,其中托管堆简称为堆。
我们也知道,C# 中的数据类型分为两种:值类型和引用类型。值类型包含所有的数字类型(如 byte、int、long、double 等)、布尔型(bool)、字符(char)、结构(struct)和枚举(enum),其它的都是引用类型(如类、接口、数组等)。
数据的类型不仅决定了数据存储需要的内存大小,还决定了对象在内存中存储的位置(栈或堆)。理解值类型和引用类型的特点和它们在内存中的存储结构,就能了解它们是如何以及何时进行内存分配和回收的,这有助于帮助我们编写更高性能的应用程序。
1栈与值类型
值类型变量的值是存储在栈中的。学过数据结构我们都知道,栈是一个后进先出(LIFO)的数据结构。这种数据结构的主要特征是,数据只能从栈的顶端插入和删除。把数据放入栈顶称为入栈,从栈顶删除数据称为出栈。用图表示如下:
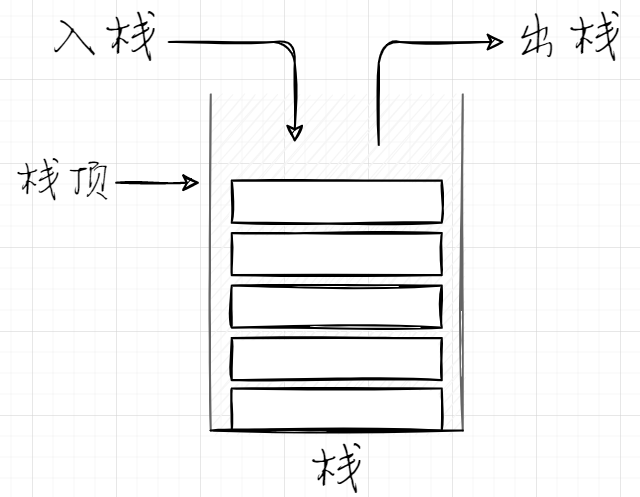
栈在内存中可以理解为上图所示的一个个连续的存储单元。栈除了存储值类型的变量,还存储传递给方法的值类型的参数,以及程序当前的执行环境等。
我们不需要显式地对栈做任何操作,栈中数据的生命周期由 CLR 根据其作用域直接处理的。
考虑如下代码:
{
int a = 1; // a 的作用域开始
// ...
{
int b = 2; // b 的作用域开始
// ...
} // b 的作用域结束
} // a 的作用域结束作用域的生命周期和栈的后进先出逻辑总是一致的。随着代码的执行,程序先进入变量 a 的作用域,再进入 b 的作用域。对应的,变量 a 的值先入栈,b 的值后入栈。b 的作用域先结束,它的值先出栈被销毁,其次是 a 的值出栈被销毁。
2堆与引用类型
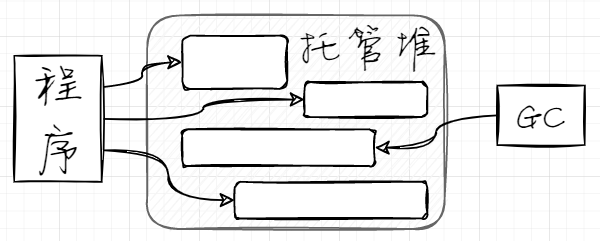
托管堆是一块内存区域,与栈不同的是,堆中的存储单元能能够以任意顺序存入和移除。
对于 .NET 程序,堆中的数据是由 CLR 托管。CLR 中的 GC(垃圾回收器)判断程序将不会再访问某数据项时,会自动销毁无主的堆对象。用图表示如下:
引用类型对象的数据存储在堆中,同时也会在栈中存储一个指向堆中实际数据的引用,用图表示如下:
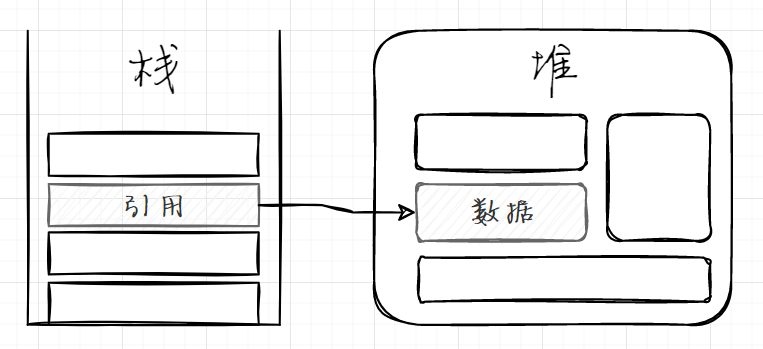
值得注意的是,对于引用类型的任何对象,其实例所有成员的数据都存放在堆中,无论它是值类型还是引用类型。
3小结
从数据存储结构的特点来总结一下值类型与引用类型的本质区别。
第一点不同是分配内存的时机及可变性。引用类型的对象从声明开始便分配内存,声明时它在内存中占用的存储单元就固定了,销毁前不会再发生增加或减少容量,赋值只是往已分配的存储单元中写入数据;引用类型是在真正赋值或初始化时才分配内存,而且所分配的内存大小后面可能会根据需要动态发生变化(字符串类型除外)。
第二点不同是它们的存储位置。值类型只存储在栈中,只在栈顶进行插入和删除,遵循后进先出原则;引用类型分两块存储,在堆中存储实际的数据,在栈中存储指向数据的引用。
加入我们,一起踏上.NET大牛成长之路↓